Kapitel 6 — Trænings-konfiguration
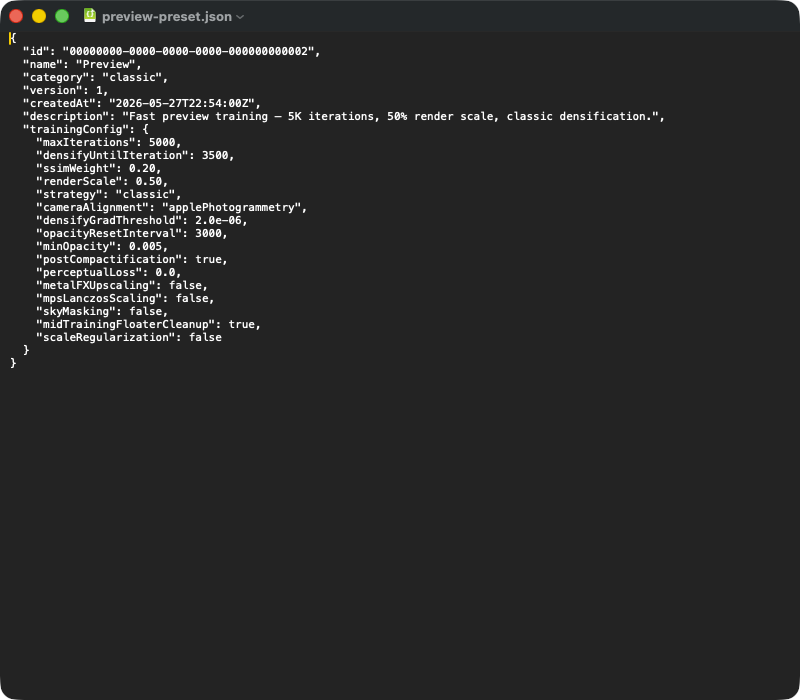
En typisk preset-JSON-eksport. Top-level-felter: id (UUID), name, (classic | mcmc | sceneClass | custom), (skema-version), (timestamp), (fri tekst). Det indlejrede -objekt indeholder de for reproducerbarhed kritiske parametre — ved import deserialiseres hele blokken til TrainingConfig-strukturen, og defaults fra app-versionen fylder de felter, der mangler i JSON'en (f.eks. efter app-opdatering). Den, der overdrager en preset til en anden Mac, sender simpelthen denne JSON-fil.
TrainingConfig-strukturen er hjertet i hver trænings-kørsel i RadianceKit. Den samler hver parameter, der påvirker træningen — fra max iterations-antallet over de otte læringsrater til specialfelter for MCMC, Mip-splatting, curriculum og scene-aware cap-logik. Du redigerer den i sidebaren under trænings-konfigurations-sektionen (Expert View), gemmer den som preset eller giver den videre som JSON-eksport til en anden Mac. Ved træning fryses præcis dette objekt og overgives til GPU-backend.
Dette kapitel er reference-materiale til power-users og script-forfattere. Det lister alle 81 offentlige felter, de 9 statiske presets og den ene offentlige metode. Kildefil er TrainingConfig.swift — ved tvivl gælder den dér gemte doc-comment og initializer-default'en som source-of-truth.
Indholdsfortegnelse:
+ Iteration (T1–T2) + Learning rates (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH-degree-progression (T21) + Performance (T22–T25) + Diagnose og punktsky-forberedelse (T26–T30) + Regularisering (T31–T37) + Refinement (T38–T44) + Sky-dome (T45–T48) + Adam + LR-schedule (T49–T55) + Post-processing + Apple AI (T56–T60) + MCMC-densification (T61–T73) + Mip-splatting (Q1.5) (T74–T76) + Adaptive densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Statiske presets (TP1–TP9) + Metoden: + Hvilket felt til hvad? (cheat sheet) + Farlige felter
Iteration (T1–T2)
T1maxIterations
DETALJER
Default: 30 000 (initializer), 35 000 (.full), 200 000 (.fullMCMC) Range: 1 000 – 500 000 (UI-slider), ingen hård øvre grænse i logikken Defined in:
TEKNISK
Samlet antal trænings-iterationer, som backend gennemløber. En iteration består af et forward-render af et enkelt trænings-kamera, et backward-pas over alle loss-komponenter (L1 + SSIM + valgfrie regulariseringer + sky-mask) og et Adam-optimizer-skridt. Dette tal virker direkte ind på andre schedules: position-læringsraten følger en cosine-annealing-kurve fra 0 til enten T1 selv eller til T49 positionLRScheduleEndIteration; densification stopper ved T2 densifyUntilIteration; MCMC-noise-decay slutter ved T69 mcmcNoiseDecayEnd; SH-degree-opgraderinger sker ved de tre i T21 definerede markeringer. Ved klassisk densification ligger det empirisk fundne sweet spot ved 20 000–35 000 iterationer (sessioner 1–32, V546-tests), ved MCMC ved 60 000–200 000 (V534). En drastisk forhøjelse ud over de i presets gemte værdier giver sjældent ekstra kvalitet — Adam-momentum mætter, og uden LR-decay-ende stagnerer loss'en. Omvendt fører underskridelse af ~5 000 til ufuldstændigt konvergerede geometrier (density-control har for lidt tid til klon/split).
T2densifyUntilIteration
DETALJER
Default: 15 000 (initializer), 5 000 (.full), 160 000 (.fullMCMC) Range: 0 – Defined in:
TEKNISK
Iteration, hvorfra densification holder op. Indtil da klones, splittes og prunes gaussians efter reglerne parametriseret i T11–T16 (Classic) eller T67–T70 (MCMC); derefter forbliver gaussian-antallet konstant, og kun positioner, rotationer, skaler, opaciteter og SH-koefficienter optimeres (refinement-fase). I 3DGS-originalpapiret ligger værdien ved 50 % af T1, i RadianceKits .full-preset ved kun ~14 % (5 000 af 35 000) — følge af V310/V338-eksperimenter, der viste, at videre densificering efter 5 000 iterationer snarere forværrer resultatet (flere floaters, mere lagerbehov, ingen kvalitetsgevinst). MCMC derimod lader relocation køre til 80 % af T1 (V504b), fordi MCMC ikke producerer skadelige floaters. Hvis T2 vælges for lille (< 1 000), opstår der for få gaussians; for stor ved Classic (> 50 % af T1) fører til overgrowth og RGB-saturation-outliers (se outdoor-overtraining-findings).
Learning rates (T3–T10)
T3positionLearningRate
DETALJER
Default: 0.00016 Range: 1e-7 – 1e-3 (anbefalet) Defined in:
TEKNISK
Adam-læringsrate for XYZ-positionen af hver gaussian ved trænings-start (iteration 0). Følger en cosine- annealing-kurve og synker i træningens forløb til T4 positionLearningRateFinal. Default 0.00016 stammer fra 3DGS-originalpapiret (Kerbl et al. 2023) og kan i RadianceKit ikke skaleres med billed-opløsningen — positionen bevæger sig i verdens-koordinatsystemet, ikke i pixel-rummet. En markant forhøjelse (> 0.0005) bevirker, at gaussians springer over lange distancer, og loss'en bliver ustabil; værdier markant under (< 0.00005) fører til, at fejl-initialiserede punktskyer aldrig finder deres plads. V414 testede en fordobling af init-værdien → 16.8 % dårligere L1-loss; V544a-tuning bekræftede paper-default'en som optimal. Bemærk: ved .fullMCMC lader vi denne værdi bevidst stå ved default — MCMC har brug for konstante læringsrater til sin relocation-logik, så tuning her giver intet.
T4positionLearningRateFinal
DETALJER
Default: 0.0000016 (initializer + paper), 0.000016 (.full, .fullMCMC — 10× højere) Range: 0 – Defined in:
TEKNISK
Slutværdi for position-LR-cosine-annealing-kurven. Nås enten ved T1 maxIterations eller, hvis sat, ved T49 positionLRScheduleEndIteration. RadianceKits .full-preset bruger 0.000016 — altså 10× højere end paper-default'en 0.0000016. V420-eksperimenter viste, at 0.5× af slutværdien (0.000008) forværrer loss'en med 6.4 %; V414 viste, at 2× init-værdi forværrer den med 16.8 %. Den høje slutværdi er ikke tradeoff, men bevidst valg: ved for stærk decay mister gaussians under refinement-fasen evnen til at tilpasse sig nytilkomne densification-kandidater. Via V431/V433-udvidelsen kan schedule-fasen forkortes (T49 < T1), så T4 allerede nås før trænings-slut, og resten af træningen kører ved konstant mini-LR — typisk konfiguration: T49 = 20 000, T1 = 35 000, refinement altså ved 0.000016 i 15 000 iterationer.
T5shDCLearningRate
DETALJER
Default: 0.0025 (initializer + paper), 0.005 (.full og alle MCMC-presets — 2×) Range: 0.0001 – 0.05 Defined in:
TEKNISK
Adam-læringsrate for DC-andelen (degree 0, altså konstant albedo) af spherical-harmonic-farven. SH-DC svarer til den retnings-uafhængige grundtone af en gaussian, så at sige „basisfarven". V176- og V188-eksperimenter fandt 2× højere end paper-default'en optimal — hurtigere farve-konvergens, særligt fordi SH-DC ved kort træning (5 000 iterationer) ellers ikke kommer i form. I modsætning til de geometriske LR'er har SH-DC ingen decay; læringsraten forbliver konstant over alle iterationer (eller følger kun den valgfri extended-phase-decay fra T51). V416 testede en firedobling til 0.01 → 6.4 % dårligere loss ved beta2=0.99-Adam.
T6shRestLearningRate
DETALJER
Default: 0.000125 (initializer + paper), 0.00025 (.full og MCMC — 2×) Range: 0.000001 – 0.005 Defined in:
TEKNISK
Adam-læringsrate for SH-koefficienterne af højere orden (degree 1, 2, 3 — altså de view-direction-afhængige farveandele, der sørger for højlys, refleksioner og blød skygning). 20× mindre end T5 ifølge paper-konvention, fordi disse koefficienter vokser kvadratisk i antal (3 for degree 1, 5 for degree 2, 7 for degree 3 → i alt 15 floats pr. gaussian) og uden mindre læringsrate ville overmættte billedet. Frigives i to trin — indtil første markering i T21 shDegreeUpgradeIterations er kun degree 0 aktiv (altså kun T5), derefter 1, senere 2, til sidst 3. Lave værdier her er særligt vigtige på scener med meget diffus belysning; ved meget blanke overflader (billak, vand) giver det ingen mening at dreje på det — SH- repræsentationen selv er begrænset.
T7opacityLearningRate
DETALJER
Default: 0.05 (initializer + paper), 0.1 (.full, MCMC — 2×) Range: 0.001 – 1.0 Defined in:
TEKNISK
Adam-læringsrate for logit-opaciteten af hver gaussian. Appen gemmer opacity som ubegrænset float-værdi og transformerer den med sigmoid til [0, 1]; LR'en virker i logit-space. Paper-default 0.05 er efter V50-tests (best single-run L1 0.1664) genoprettet, V71 reverterede V67's 0.025. V188-fordoblingen til 0.1 gør pruning mere effektiv — døde gaussians falder hurtigere under T14 pruneOpacityThreshold. V418 viste: 0.05 med beta2=0.99-Adam er 7.1 % dårligere end 0.1 — vekselvirkningen med Adam-konfigurationen er ikke triviel. Lave værdier (< 0.01) fører til, at „døde" gaussians ligger evigt rundt og bruger lager; for høje værdier (> 0.5) kan føre til opacity-explosion, derfor klampes logit-værdien i optimizeren til [-15, 3] (se note „Opacity Explosion Prevention" i CLAUDE.md).
T8opacityLearningRateFinal
DETALJER
Default: 0.0 (= „ingen decay") Range: 0 eller 0.001 – Defined in:
TEKNISK
Valgfri cosine-decay-slutværdi for opacity-LR'en (V427). Når 0.0, er decay deaktiveret, og opacity-LR'en forbliver konstant ved T7 over hele træningen. V427 testede en decay 0.1 → 0.01 — resultat 11.5 % dårligere loss; reverteret, deraf default'en „fra". Hypotesen bag feltet: i refinement-fasen kunne konstant opacity-LR føre til oscillation, så splats, der allerede har nået det rigtige mål for transparens, forskydes igen af tilfældige gradient-udsving. Empirisk bekræftes det ikke — logit-clamping-logikken fanger det alligevel. Feltet forbliver tilgængeligt for fremtidige eksperimenter; også meget lange MCMC-kørsler (> 500K iterationer) kunne drage nytte af det.
T9scaleLearningRate
DETALJER
Default: 0.005 (initializer + paper), 0.01 (.full, MCMC — 2×) Range: 0.0001 – 0.1 Defined in:
TEKNISK
Adam-læringsrate for de tre skala-komponenter af hver gaussian i log-space (RadianceKit gemmer log(scale), så skalaerne forbliver positive). Paper-default 0.005, i RadianceKit fordoblet til 0.01 for bedre skala-konvergens ved de optimerede læringsrate-konfigurationer. V423-eksperiment: 0.005 med beta2=0.99-Adam → 18.7 % dårligere loss og synligt for få gaussians (density-control kunne ikke klone, fordi skala- updates var for langsomme). Skala kontrollerer udstrækningen af hver gaussian — for hurtig læring fører til „needle"-gaussians (ekstremt lange tynde splats, se T34 scaleRatioPruneThreshold), for langsom læring lader splats forblive for kompakte, og density-control skal splitte for ofte.
T10rotationLearningRate
DETALJER
Default: 0.001 (initializer + paper), 0.002 (.full, MCMC — 2×) Range: 0.0001 – 0.05 Defined in:
TEKNISK
Adam-læringsrate for de fire quaternion-komponenter af hver gaussian. Quaternion'en normaliseres igen i hvert optimizer-skridt efter Adam-update'en (L2-norm = 1) — ellers ville kovariansmatricen blive degenereret. RadianceKit fordobler paper-default'en i quality-presets, fordi rotation har mindre absolutte gradient-magnituder end skala / position (på enhedssfæren forbliver hvert skridt kort), og uden 2× ville rotationen i 35 000-iterations-vinduet være markant under- konvergeret. V188 dokumenterer. På NeRF-Blender-scener (Lego, Chair) virker rotation særligt — objekternes kanter retter sig først korrekt ud efter 5 000–10 000 iterationer.
Densification — Classic (T11–T16)
T11densifyGradThreshold
DETALJER
Default: 0.000002 (initializer, kalibreret for 0.5× opløsning), 0.0000011 (.full, kalibreret for 1.0×), 0.000004 (.quickTest, kalibreret for 0.25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (opløsningsafhængig) Defined in:
TEKNISK
Tærskel for L2-normen af den skærmrums-projicerede gradient dMean2D, over hvilken en gaussian markeres til klon eller split. Den absolutte værdi afhænger direkte af trænings-opløsningen — dMean2D skalerer ca. som 1/opløsning² (flere pixel = mindre per-pixel-gradienter). Derfor kræver hvert T22 trainingRenderScale-trin en kalibreret tærskel: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). Paper-default 0.0002 er NDC-normaliseret og ikke direkte sammenlignelig i RadianceKits world-space-pipeline. Med V440 indkoblet T52 adaptiveDensifyThreshold-flag kan værdien beregnes i runtime ud fra p98 i den aktuelle gradient-fordeling — men V440 testede det på rigtige scener og producerede 63 K gaussians (katastrofalt pruning-tab); flaget forbliver fra. Q5 (T77–T79) leverer en alternativ adaptiv logik via rolling median. Dette felt er ikke ufarligt — halvering genererer 2–4× flere gaussians (lager-pres, OOM-risiko); fordobling kan under-densificere scenen.
T12densifyFromIteration
DETALJER
Default: 500 Range: 100 – 5 000 Defined in:
TEKNISK
Første iteration, fra hvilken densification bliver aktiv. Før det sker kun „nøgen" læring på den initiale SfM-punktsky, uden at nye gaussians genereres. Default 500 stammer fra 3DGS-papiret og giver initialiseringen tid til at stabilisere sig — hvis der allerede densificeres fra iteration 0, klones forkert positionerede SfM-punkter mange gange, før de overhovedet finder deres rigtige plads. V349 testede 1000 → let dårligere loss; default'en er optimal.
T13densifyInterval
DETALJER
Default: 100 (initializer, MCMC), 200 (.full) Range: 50 – 1 000 Defined in:
TEKNISK
Hvor mange iterationer der ligger mellem to densification-skridt. Ved paper-default 100 — hver 100 iterationer evalueres listen af densify-kandidater, klones/ splittes, og samtidig fjernes listen af prune-kandidater (sigmoid(opacity) < T14 pruneOpacityThreshold). V112-tests fandt 200 som optimal for .full — det aflaster GPU'en, fordi færre reorganisations-pas kører, og giver hver gaussian mere tid til at falde til ro efter en klon-handling. V417 testede 100 med beta2=0.99 → 5.8 % dårligere (957 K gaussians, overdensificering). Ved MCMC fortolkes samme felt som relocation-interval; se T67 mcmcRelocationInterval for den MCMC-specifikke logik.
T14pruneOpacityThreshold
DETALJER
Default: 0.005 (initializer, paper, MCMC), 0.001 (.full) Range: 0.0001 – 0.1 Defined in:
TEKNISK
Sigmoid-opacitets-tærskel, under hvilken en gaussian slettes ved næste densification-step. Virker sammen med T7 opacityLearningRate og logit-clamp-logikken i optimizeren. V393 sænkede default'en fra 0.005 til 0.001 i .full — følge: splats, som kun spiller en rolle under eksotiske kigge-vinkler, bevares længere og bidrager til SH-detalje. V394 testede 0.0001 → let dårligere (for lidt pruning, lager spildt). Vigtigt: density-control skal ALTID prune, selv hvis buffer-kapaciteten allerede er fuld af andre tiltag (se „Density Control Must Always Prune" i CLAUDE.md) — ellers akkumulerer døde gaussians, og count fryser fast.
T15opacityResetInterval
DETALJER
Default: 3 000 (initializer + paper), 100 000 (.full = reelt deaktiveret), 200 000 (.fullMCMC = deaktiveret) Range: 1 000 – 100 000+ Defined in:
TEKNISK
Hver hvor mange iterationer nulstilles opaciteten af alle gaussians til en lav værdi (~0.01) — en foranstaltning fra 3DGS-papiret for at vurdere „frosne" splats på ny. V194 viste, at med RadianceKits warmup + stochastic-trænings-setup + 2× læringsrater koster opacity-reset 5.5 % kvalitet, og logit-clamp dækker reset-funktionen allerede. Derfor i .full praktisk deaktiveret (100 000 > 35 000 = aldrig udløst). V421 testede reset hver 3 000 med beta2=0.99 → 4.9 % dårligere; reverteret. Ved .fullClassicPaper (Q1.5-A, paper-tro test) er det bevidst sat tilbage til 3 000 — det var en af de håndtag, hvormed paper-magnitude-gaussian-budgetterne skulle nås.
T16maxScreenSize
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 (off) eller > 0 Defined in:
TEKNISK
Maksimal skærmrums-størrelse (i projicerede pixel), som en gaussian må nå, før den tvunget splittes. Værdien er sat til 0 (V48 testede og reverterede) — RadianceKits density-control bruger i stedet world-space-skala-tærsklen fra dMean2D-logikken. Forbliver i feltkataloget, fordi fremtidige eksperimenter med Mip-splatting (T74–T76) eller scene-specifikke splatting-strategier kunne drage nytte af det. Aktivering (værdi > 0, f.eks. 20) ville tvinge splats, der er blevet meget store på skærmen, til at dele sig — relevant ved store, glatte vægoverflader, hvor et enkelt riesensplat tilbyder for lidt detalje.
Loss (T17–T20)
T17ssimWeight
DETALJER
Default: 0.2 (initializer + paper + .full), 0.05 (alle MCMC-presets) Range: 0.0 – 1.0 Defined in:
TEKNISK
Vægt af D-SSIM-andelen i den kombinerede loss-funktion loss = (1 - λ) * L1 + λ * D-SSIM, hvor λ = T17. 3DGS-paper-default 0.2 er optimal for Classic-densification — V383 testede 0.3 → 28.9 % dårligere, V373b bekræftede 0.2 som sweet spot. For MCMC blev det i V521b/V534 uafhængigt fastslået: 0.05 er optimal, fordi MCMC via sin stokastiske eksploration har brug for en stærkere L1-signal-andel — højere SSIM-vægte ville udvande relocation-beslutningerne. SSIM er markant dyrere at beregne end L1 (lokale 11×11-vinduer over hele billedet); RadianceKit bruger en MPS-accelereret implementering, der bliver under 1 ms pr. 1080p-billede. Q7-BayesOpt-sweeps fandt scene-specifikke optima mellem 0.05 (.outdoorPreset: 0.082) og 0.171 (.indoorPreset).
T18ssimWeightRefinement
DETALJER
Default: 0.0 (= „intet skift, behold ssimWeight") Range: 0 eller 0 – 1.0 Defined in:
TEKNISK
Valgfri SSIM-værdi for refinement-fasen efter T2 densifyUntilIteration. V428 testede 0.2 → 0.3 i refinement → 16 % dårligere loss (både L1 og SSIM forværredes); reverteret, deraf default 0.0. Hypotesen bag feltet var, at efter densification — når der ikke længere opstår nye gaussians — en stærkere SSIM-andel ville maksimere den strukturelle skarphed. Empirisk forkert: at hæve SSIM-vægten betyder indirekte at sænke L1-vægten, og L1 er det markant mere sigende signal i final-refinement-fasen. Feltet forbliver tilgængeligt for fremtidige eksperimenter med perceptual loss (T60) eller edge- loss (T19), hvor en refinement-specifik loss-komposition kunne være meningsfuld.
T19edgeLossWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.001 – 1.0 Defined in:
TEKNISK
V437-eksperimental-loss: vægt af en Sobel-gradient-domæne-L1-loss, der sammenligner billedkanter direkte (ground-truth-Sobel vs render-Sobel) ud over L1+SSIM. Hypotese: kant-information er en perceptuel hjørnesten af billedkvalitet, og en eksplicit term burde opmuntre gaussians til bedre at træffe kanterne. Test-resultater: vægt 0.1 → 11 % dårligere loss, 0.01 → kvalitets-neutral, men 10 % langsommere. Sobel-passet koster et yderligere MPS-forward på ground-truth og render. Derfor permanent deaktiveret. Fremtidigt use-case: scener med hårde kunstige kanter (arkitektur, møbler, renderinger) kunne profitere — Q7-scene-class-presets pickede det dog ikke, men skalerede i stedet SSIM-vægten.
T20skyMaskingEnabled
DETALJER
Default: false (initializer og alle presets) Range: boolean Defined in:
TEKNISK
Slår sky masking til. Derved maskeres sky-regionen i hvert billede via Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest), og loss'en i dette område sættes til nul. Mening: outdoor-scener lider ofte under, at blå/grå/hvide sky-pixler får appen til at placere gaussians præcis dér — hvilket opfattes som „floater". Uden sky-mask ville loss'en i dette område aldrig blive nul, fordi himlen i billedet varierer let, og appen evigt forsøger at genskabe det med splats. Vision-masken beregnes en gang pr. kamera før træningen og holdes i RAM. Aktiveres typisk sammen med T45 skyDomeEnabled (UI-logik i settings-viewet). Ved indendørs-scener eller syntetiske renderinger lader man stå fra — masken ville dér fejlagtigt genkende lofter eller vægge som „sky".
SH-degree-progression (T21)
T21shDegreeUpgradeIterations
DETALJER
Default: [1_000, 2_000, 3_000] (initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — degree 3 sprunget over) Range: [Int], hver værdi i [0, maxIterations], monotont stigende Defined in:
TEKNISK
Iterationer, hvor den aktive SH-degree skiftes op fra 0→1, 1→2, 2→3. Før første markering er kun DC-komponenterne aktive (altså T5 shDCLearningRate), efter første markering DC + 3 degree-1-koefficienter, efter anden markering + 5 degree-2-koefficienter, efter tredje markering alle 15 koefficienter. Lager-behovet pr. gaussian vokser i trin — 4 floats → 16 floats → 36 floats → 64 floats. Quality-presets udskyder optrapningerne i forhold til initializer-defaults (V228), fordi geometrien skal stabilisere sig først, før farve- detaljerne med deres højere frekvens kommer på. V384 testede [1K, 2K, 3K] for .full → 9.3 % dårligere — bekræfter forsinkelsen. .preview kapper ved degree 2, fordi degree 3 ikke konvergerer i 5 000 iterationer og kun bruger optimizer-kapacitet. Q6 (T80–T81) tilbyder en alternativ curriculum-logik, der dynamisk overskriver denne liste.
Performance (T22–T25)
T22trainingRenderScale
DETALJER
Default: 1.0 (initializer, .full, MCMC, scene-class), 0.5 (.preview), 0.25 (.quickTest) Range: 0.05 – 2.0 (typisk 0.25, 0.5, 1.0) Defined in:
TEKNISK
Render-opløsning ved træning relativt til træningsbilledernes oprindelige opløsning. Ved 0.5 nedskaleres hvert billede til 50 % bredde × 50 % højde (altså 25 % af pixlerne), og gaussian-renderingen sker i denne mindre opløsning. Reducerer både lager- og regneindsats kvadratisk. Vigtigt: T11 densifyGradThreshold skal passe til den valgte opløsning — gradient-magnituderne skalerer med 1/opløsning², derfor har .quickTest (0.25×) en meget højere tærskel (4e-6) end .full (1.0×, 1.1e-6). RadianceKit advarer ved meget store billeder og tilpasser automatisk — 3-MP-mål-opløsning. Ved ekstreme 4K-input-billeder ville 0.5 eller endda 0.25 være meningsfuldt, ellers kører selv Mac'en kun i CPU-compaction.
T23resolutionWarmupScale
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.1 – Defined in:
TEKNISK
V133-optimering: træn densification-fasen (iter 0 til T2) i en lavere opløsning end refinement-fasen. V308 har deaktiveret den igen for .full, fordi tids-gevinsten ved T22 = 1.0 og cosine-annealing var marginal, og kvaliteten led minimalt. Forbliver i feltkataloget, fordi den kunne blive meningsfuld igen ved 4K-input og lange trænings-kørsler — Q6 curriculum (T80) har taget en lignende logik op, men dér er den koblet til LR-schedulen. Hvis aktiveret og T80 curriculumResolutionRamp ligeledes true, vinder Q6 og overskriver denne værdi.
T24tileSize
DETALJER
Default: 16 Range: 8, 16, 32 Defined in:
TEKNISK
Størrelse af rasteriserings-tiles i pixel. Gaussian-splatting-renderingen er tile-baseret: billedet opdeles i 16×16-pixel-fliser, hver flise samler de for den relevante gaussians, sorterer dem efter dybde og blender dem ind. 16 er standard, som praktisk talt alle 3DGS-implementeringer bruger, og er hardkodet i RadianceKits Metal-kerneler; en ændring af denne værdi ville kræve re-kompilering af shaderne og er ikke effektiv i den aktuelle stand. Forbliver som felt, hvis en fremtidig engine-version understøtter tile-size dynamisk.
T25throttleDelayMs
DETALJER
Default: 0 (initializer, .full, MCMC, scene-class), 0 (.preview) Range: 0 – 100 Defined in:
TEKNISK
Kunstig forsinkelse mellem trænings-iterationer i millisekunder. 0 = fuld hastighed (standard). Højere værdier gør Mac'en mere „brugelig" under træningen ved, at GPU/CPU regelmæssigt får pusterum — andre apps' brugervenlighed stiger, men træningstiden også lineært med forsinkelsen. Typiske værdier: 1–2 ms („let" throttling, +5 % træningstid, Mac føles mere responsive), 5 ms („mellem", +15 % træningstid), 10+ ms („Eco", potentielt fordoblet træningstid). Tilbydes i Inspectoren under „Performance", men er ikke i standard-visningen — se backlog dev_ux-backlog.md, der foreslår at fjerne den fra Expert View, fordi den misforstået forlænger træningstiden dramatisk.
Diagnose og punktsky-forberedelse (T26–T30)
T26depthDistortionWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.0001 – 0.05 Defined in:
TEKNISK
V366-eksperimental: vægt af en depth-distortion- regulariserings-loss. Straffer gaussians, der langs en render-stråle ganske vist er dybt stablede, men konceptuelt hører til samme overflade — det opmuntrer koncentrerede dybdefordelinger og reducerer floaters. Tests: 0.01 → 4.5 % dårligere, 0.001 → 8.1 % dårligere. Den teoretiske fordel — multi-view-konsistens forbedres — afspejler sig ikke i L1-loss'en, fordi hypotesen implicit antager, at SfM-geometrien er korrekt, og gaussians kun skal „stables". I praksis er SfM-punktskyen som regel den svageste komponent, ikke stablingen. Forbliver tilgængelig for multi-view-datasæt med særligt rene poser (synthetic, Mip-NeRF 360 med ground truth).
T27singleViewOverfit
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
Diagnose-flag: hvis true, bruges i hver trænings-iteration tvunget kamera-index 0 i stedet for en tilfældig fra camera-pool'en. Mening: hvis modellen ikke engang kan overfitte en enkelt view (altså loss'en på view 0 ikke går mod nul selv efter 10 000 iterationer), er der en fundamental bug i forward/backward-passet. Denne kontakt blev brugt intensivt under udviklingen af Metal-shaderne og differentiable- rasterizer-kernels — V42–V47-fasen. I dag kun tilgængelig som sanity-check, hvis nogen har modificeret backend-kode og vil lave en regression test. Via CLI med –single-view.
T28maxCameras
DETALJER
Default: 0 (= „brug alle kameraer") Range: 0 eller 1 – N Defined in:
TEKNISK
Diagnose-grænse fra V43: træn kun med de første N kameraer, ignorer alle yderligere. Mening oprindeligt: teste hypotese, at for mange kameraer skaber gradient-konflikter (for mange modstridende loss-signaler for samme gaussian). Test-resultat: ingen systematisk fordel ved kunstig begrænsning — flere frames bringer praktisk talt altid mere kvalitet. Forbliver som CLI-flag (–max-cameras N) til målrettede eksperimenter, f.eks. „fungerer træningen på de første 100 billeder af en 1 500-billed-droneflyvning?" Ikke eksponeret i UI.
T29maxInitialPoints
DETALJER
Default: 0 (= „brug alle SfM-punkter") Range: 0 eller 1 000 – 200 000+ Defined in:
TEKNISK
V54-sikring: begrænser antallet af initiale SfM-punkter, som træningen starter med. Tætte COLMAP- rekonstruktioner kan producere > 60 000 punkter, hvilket ved store initial-skalaer fører til 200–300 gaussians pr. pixel-overlap — det giver et „tågefelt", hvor træningen ikke konvergerer. Subsampling til ~16 000 punkter (hard-cap-logik i trænings-engine) bringer initial-densiteten på niveau med, hvad reference-3DGS bruger, og reducerer overlap dramatisk. Sættes automatisk ved meget tætte SfM'er; via CLI med –max-points N.
T30cameraClusterOutlierMultiplier
DETALJER
Default: 10.0 (alle presets — aldrig overskrevet) Range: 1.0 – 100.0 Defined in:
TEKNISK
Multiplikator for camera-cluster-outlier-filteret, indført i fase 3.10 A.1. Før træningen beregner trænings-engine centroidet for alle kamera-positioner og den maksimale distance for et kamera fra centroidet. SfM-punkter, hvis distance fra centroidet overskrider multiplier × maxCameraDistance, kasseres som outliers. Default 10× bevarer adfærden fra før fase 3.10. En subtil bug: tighter SfM (kameraer tættere sammen) → mindre → mindre tærskel → flere punkter kasseres som outliers. Looser SfM → større tærskel → færre punkter kasseres. Dette er en af årsagerne til fase-3.9-funnel-vs-training-anti- korrelationen: bedre SfM kan downstream føre til dårligere træning, fordi for mange initial-punkter dræbes. Feltet ligger som CLI-override (–camera-cluster-outlier-multiplier) til A.3-sweeps; ikke eksponeret i UI. Værdier under 5 er som regel for restriktive, over 20 virkningsløse.
Regularisering (T31–T37)
T31coarseToFineBlurRadius
DETALJER
Default: 0 (= deaktiveret) Range: 0 eller 1 – 10 Defined in:
TEKNISK
V369-eksperimental: box-blur-radius, der i starten af densification-fasen anvendes på ground-truth-billedet og lineært reduceres til slutningen af densification (T2) til 0. Hypotese: coarse-to-fine-træning — først lære grove strukturer, så detaljer — skulle give stabilere geometri. Tests: r=3 → 9.6 % dårligere, r=1 → 5.1 % dårligere. Grunden til mislykket: densification beslutter baseret på billed-domæne-gradienter, og blur reducerer netop de signaler, der er vigtige for „her skal klones". Forbliver i feltkataloget til fremtidige tests med andet density-control-skema.
T32scaleRegWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.0001 – 0.05 Defined in:
TEKNISK
V370-eksperimental: L1-regularisering på verdens-rumlig skala. Straffer gaussians, der bliver for store — forhindrer „mega-splats", der dækker hele vægoverflader med en gaussian. Tests: 0.01 → 200 % dårligere loss (2 M gaussians, total eksplosion), 0.001 → 214 % dårligere. Grunden: skala- regularisering kommer i konflikt med density-control — mindre skalaer betyder, at flere gaussians bruges, så density-control splitter oftere, hvilket igen betyder mere gradient-arbejde. Disabled, men dokumenteret til Mip-splatting-eksperimenter (T74): i denne kontekst kunne en skala-undergrænse være meningsfuld.
T33anisotropyRegWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.0001 – 0.05 Defined in:
TEKNISK
V445-eksperimental: penalty på max(scale)/min(scale)-forholdet, skal forhindre ekstremt langstrakte „needle"-gaussians, der opfattes som floaters. Tests: 0.01 → 69 % dårligere, 0.001 → 15 % dårligere. Grunden: regulariseringen tvinger splats mod „runde" former, hvilket på en flad overflade (væg, bord, gulv) er netop forkert — dér er en flad, bred gaussian mere effektiv end en kugleformet. Disabled. V549f tilbød med T34 scaleRatioPruneThreshold en alternativ, mere målrettet tilgang, som ligeledes blev reverteret.
T34scaleRatioPruneThreshold
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 5.0 – 100.0 (typisk 10.0 – 30.0) Defined in:
TEKNISK
Eksperimentel post-training-pruning, der sletter hver gaussian, hvis max(scale)/min(scale)-forhold overskrider den her satte lineære tærskel. Sigter på ekstremt langstrakte „needle/disc"-floaters, der ikke kan elimineres ved regularisering alene. I testen fjernede pruning floaters som håbet, men samtidig også fornuftige flade splats på vægge og gulve — billedet blev hullet. Derfor fra som default, CLI-flaget (–scale-ratio-prune N) forbliver tilgængeligt til målrettede eksperimenter. Anbefalede værdier, hvis man alligevel vil teste: 30 (meget konservativ, fjerner kun ekstreme outliers), 10 (aggressiv, koster detalje).
T35opacityRegWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.0001 – 0.05 Defined in:
TEKNISK
V446-eksperimental: binary-cross-entropy-penalty, der trækker opacity mod 0 eller 1 (altså væk fra „halv- transparent"). Hypotese: skarpere opacitetsfordeling ville forbedre billedklarhed. Test med T33 kombineret → regularisering koster kvalitet, begge deaktiveret. Disabled. Advarsel: i 1.4.3-beta dukkede en bug op, der havde præcis dette felt med en default-værdi-ændring (initializer = 0.01), hvilket førte til mass-extinction af gaussian-count (460 K → 5 på en iteration). Siden 1.4.4 fast på 0.0 som default.
T36opacityDecayFactor
DETALJER
Default: 0.0 (initializer = deaktiveret), 0.9995 (.full, .classicBalanced — HTGS-standard) Range: 0 (off) eller 0.95 – 1.0 Defined in:
TEKNISK
V546-implementering af HTGS-skemaet (Hierarchical Time-Gating, Eurographics 2025): hver T37 opacityDecayInterval iterationer multipliceres sigmoid-opaciteten af hver gaussian med denne faktor. 0.9995 × 100 anvendelser giver ~95 %-tilbage pr. densification-fase — et let, men stabilt nedadgående tryk på alle opacities, der pålideligt lader svagt bidragende gaussians synke mod T14 pruneOpacityThreshold. Resultat: 14 % bedre L1-loss på Horse Full (3-trial-avg V546) i forhold til V438 uden decay. Kun aktiv under densification-fasen (indtil T2), derefter kører træningen videre uden decay, så de i refinement etablerede opaciteter forbliver stabile. Bruges ikke ved MCMC (MCMC har egne mekanismer via T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETALJER
Default: 50 Range: 10 – 500 Defined in:
TEKNISK
Iterations-interval, hvor T36 opacityDecayFactor anvendes. HTGS-paper-default 50, beholdt i .full. Lange intervaller (>200) ophæver effekten delvist, fordi der mellem to anvendelser sker nok gradient-updates til, at opacity stiger igen. Korte intervaller (<20) gør decay for aggressiv. Kun aktiv i densification-fasen.
Refinement (T38–T44)
T38gradientAccumulationSteps
DETALJER
Default: 1 (= „en view pr. Adam-skridt") Range: 1 – 8 Defined in:
TEKNISK
V424-feature: antal views, hvis gradienter akkumuleres, før et Adam-update udføres. Ved > 1 kører appen på en separat, „unfused" backward-project-sti, der summerer gradienterne i en separat buffer; den endelige anvendelse skalerer med 1/N for at holde magnituden konstant. V424 testede 2-view → kvalitets-neutral, men 10 % langsommere (fordi unfused-stien er dyrere end fused-stien). Reverteret for .full, men bevidst brugt til MCMC — .fullMCMC kører med, men V544a-tests viste, at quality-gappet til Classic skrumper til 5 % (i stedet for 11 %). I initializer-default 1, i aktuelle preset 1, forbliver CLI-flag (–accum-steps N).
T39testViewIndices
DETALJER
Default: [] (= tom, alle views bruges til træning) Range: Set<Int>, vilkårlig delmængde af camera-indices Defined in:
TEKNISK
V546-feature: sæt af camera-indices, som IKKE bruges til træning, men gemmes som holdout til PSNR/SSIM/LPIPS- evaluering. Sættes automatisk, når –benchmark-CLI-flaget er aktivt: så hver ottende view fra index 0 (LLFF-standard, identisk med Mip-NeRF-360- og 3DGS-paper-konventioner). Uden benchmark tom — træningen bruger alle views. Forsigtighed: manuel indstilling af dette felt uden forståelse for indekserne kan gøre benchmarket ubrugeligt (f.eks. hvis alle indices over N sættes, mens der kun er N-50 views → ingen holdouts → ingen evaluering). Ved egen preset-eksport persisteres testViewIndices ikke, fordi det er scene-afhængigt og ellers ville efterlade meningsløse værdier mellem forskellige datasæt.
T40refinementPruneInterval
DETALJER
Default: 0 (= deaktiveret) Range: 0 eller 100 – 5 000 Defined in:
TEKNISK
V425-feature: hver N iterationer i refinement- fasen (efter T2) køres et yderligere prune-pas, der fjerner gaussians med sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Mening: under densification er der regelmæssige density-control-kald, derefter ikke længere — gaussians, hvis opacity fortsætter med at synke, forbliver dog i bufferen. V425 testede og reverterede: den ekstra pruning korrelerede med V426 (two-phase densification, ligeledes afsluttet i 0-gaussians-cascade failure). Disabled. CLI-flag tilgængelig til eksperimenter; hvis aktiveret, er 1 000 eller 2 000 fornuftige værdier.
T41refinementPruneOpacityThreshold
DETALJER
Default: 0.0 (= „brug T14") Range: 0 eller 0.001 – 0.1 Defined in:
TEKNISK
V425b: separat opacity-tærskel til refinement- pruning. Efter densification har de fleste gaussians nået en markant højere opacity (> 0.001), så standard- T14 pruneOpacityThreshold ville være for slap. Hvis T40 aktiv, bestemmer dette felt den egne tærskel. Ved 0.0 anvendes T14 fortsat. Kun relevant, hvis T40 > 0.
T42midTrainingCompactificationIterations
DETALJER
Default: [] (= deaktiveret) Range: [Int], værdier i (densifyUntilIteration, maxIterations) Defined in:
TEKNISK
V549-feature: eksplicitte iterations-punkter under refinement-fasen, hvor et compactification-pas køres (fjerner sigmoid(opacity) < 0.01 + outlier-skala-gaussians, samme logik som T56 postTrainingCompactification). Mening: lange refinement-faser kan vise confetti-/floater-akkumulation, hvis SH så overfitter på view-specifikke artefakter. Typisk konfiguration hvis aktiveret: [10000, 20000, 30000] for 40K Classic. MEN: V549-A/B-tests på Family-dataset viste i alle konfigurationer dårligere L1: [10K,20K,30K]@0.01 → −48 % count, men +36 % L1; [20K,30K]@0.005 → −44 % count, men +45 % L1; [20K,30K]@0.001 → −17 % count, men +87 % L1. Derfor disabled. CLI-flag –mid-compact "10000,20000" tilgængelig, hvis man foretrækker den visuelle floater-tradeoff (mindre confetti i viewporten) over loss-regressionen.
T43frustumCullEnabled
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
V549b-feature: efter træning fjernes alle gaussians, der ligger uden for foreningen af alle træningskamera-frusta. Sådanne gaussians blev aldrig begrænset af loss-signalet og er altid floaters. Særligt effektivt for scener, hvor novel-viewet ligger bag eller ved siden af kamerastien (f.eks. bagsiden af en lineær droneflyvning) — floaters dér bliver aldrig synlige i træningsfasen, men meget vel ved senere bevægelse i 3D-vieweren. V549b A/B på droneflyvninger positive resultater, derfor tilgængelig som opt-in. Default false, fordi ved object-captures med fuld orbit-coverage omfatter frustum-foreningen hele scenen, og featuren fjerner intet — tilbydes i settings under „Floater Reduction" og også i Q9 Outdoor-preset implicit testet over T44 frustumCullExpansion (Q7-BayesOpt aktiverede det dog ikke, fordi outdoor-sky-dome løser samme problem bedre).
T44frustumCullExpansion
DETALJER
Default: 1.1 Range: 1.0 – 2.0 Defined in:
TEKNISK
NDC-margin for T43 frustumCullEnabled. 1.0 ville skære præcis ved billedkanten, hvilket ville beskære vaklende splats ved billedkanten for meget. 1.1 = 10 % padding ud over den præcise kamera-framing — giver lidt tolerance for randpixler, der i en let forskudt novel-view alligevel kunne blive synlige. Værdier > 1.2 gør cullen praktisk talt virkningsløs, fordi det udvidede frustum omfatter meget mere rum.
Sky-dome (T45–T48)
T45skyDomeEnabled
DETALJER
Default: false (initializer + alle presets undtagen P9 Outdoor) Range: boolean Defined in:
TEKNISK
V549e-feature: før trænings-start genereres en kugleformet punktsky (Fibonacci-sphere med T46 sample-points), placeret i en radius af T47 skyDomeRadiusMultiplier × scene_extent omkring scenens midtpunkt og initialiseret med farverne fra de sky-maskerede pixler i alle træningskameraer (se T20 skyMaskingEnabled). Disse sky-dome-gaussians indsættes i begyndelsen af gaussian-bufferen og „fryses" under træningen (position/skala/rotation-gradienter = 0, kun SH og opacity forbliver optimerbare). Effekt: i stedet for sorte „confetti"-områder i det fjerne ser brugeren en rigtig himmel i novel-views. V549e-MVP fungerer meget godt på drone- og landskabsscener; i P9 Outdoor-preset default-on. Ved indendørs scener lad stå fra — sfæren ville hænge meningsløst uden for rummet.
T46skyDomeSampleCount
DETALJER
Default: 5 000 Range: 1 000 – 50 000 (typisk 2 000 – 10 000) Defined in:
TEKNISK
Antal Fibonacci-sphere-sample-punkter på sky-dome- sfæren. Højere værdier → tættere sky-dome (bedre ved store opløsninger og meget synlig himmel), men mere lagerbehov. 5 000 er sweet spot for 4K-renderinger; ved lavere opløsninger rækker 2 000–3 000. Punkterne initialiseres efter cosine-distance til hver træningskamera-view-vektor med de tilsvarende sky-maskerede pixler — sample-points, hvis view-cone ikke ser noget kamera, forbliver med lav opacitets-startværdi bagved, men ændres ikke i træningen (frosset).
T47skyDomeRadiusMultiplier
DETALJER
Default: 30.0 (initializer + de fleste presets), 59.0 (P9 Outdoor, Q7-BayesOpt-optimum) Range: 5.0 – 200.0 Defined in:
TEKNISK
Radius af sky-dome-sfæren relativt til scenens udstrækning (= middel-distance mellem kamera-positionerne). 30 = kuglen har 30 gange diameteren af kamera-skyen. For lille (< 5) → sky-dome interfererer med selve scenen (f.eks. lander et sky-dome-splat i forgrunden); for stor (> 100) → float32- præcisionstab på sky-dome-positionerne, hvilket udløser render- glitches i det fjerne. Q7-BayesOpt på Bicycle (Mip-NeRF 360) fandt 59.0 som scene-specifikt optimum for outdoor — det tyder på, at standard-30.0 er for lille til dybe landskaber, og sky- dome-pixlerne i billedkant-områder rendrer synligt som „væg".
T48frozenGaussianCount
DETALJER
Default: 0 (= ingen frosne gaussians) Range: 0 eller 1 – T46 Defined in:
TEKNISK
Antal gaussians i begyndelsen af bufferen, hvis position/skala/rotation-gradienter sættes til nul i optimizeren — de forbliver rumligt stive over hele træningen. Density- control må ikke klone, splitte eller prune dem. Bruges til sky- dome-injection (se T45): hvis sky-dome er tændt, sættes dette felt automatisk til T46 skyDomeSampleCount. Manuel indstilling er mulig (f.eks. for at fryse en forhåndsplaceret punktsky fra en LiDAR-scanning), men ikke direkte tilgængelig i UI. Vigtigt: de første N gaussians i bufferen er altid de frosne — rækkefølgen i bufferen afgør, ikke et eksplicit index.
Adam + LR-schedule (T49–T55)
T49adamResetIteration
DETALJER
Default: 0 (= deaktiveret) Range: 0 eller 100 – Defined in:
TEKNISK
V430-feature: iteration, hvor Adam-optimizer- momentum-akkumulatorerne (m1, m2) nulstilles. Bias-korrektion derefter kører med (iter - adamResetIteration) i stedet for med iter. V430 testede reset ved 5 000 (efter densification- slut) → 12.8 % dårligere loss. Grund: Adam-momentum, der har bygget sig op under densification, bærer information om de typiske gradient-magnituder og accelererer refinement-fasen. At kaste det væk koster de første ~500 iterationer refinement i konvergens. Disabled. Forbliver CLI-flag til forskningseksperimenter.
T50positionLRScheduleEndIteration
DETALJER
Default: 0 (initializer = „brug maxIterations"), 20 000 (.full — cosine slutter ved 20K trods maxIter=35K), 30 000 (.fullClassicPaper) Range: 0 eller 1 000 – Defined in:
TEKNISK
V431-feature: iteration, hvor cosine-annealing- kurven for position-LR når sit minimum. Hvis 0, er det identisk med T1 maxIterations. Hvis > 0, kører schedulen til denne værdi og forbliver derefter konstant ved T4 positionLearningRateFinal. Det tillader en „extended refinement phase" med minimal, men konstant læringsrate — forfiner positioner langsomt uden fornyet decay. .full gør det (schedule- slut ved 20K, træning kører til 35K), V434c/V434d bekræftede: 15K og 25K begge ca. lige gode, 20K minimalt optimal. Bruges i forbindelse med T51 videre for også at modificere ikke-position-LR'erne i extended phase.
T51extendedPhaseLRDecay
DETALJER
Default: 0.0 (= deaktiveret, konstante LR'er) Range: 0 eller 0.01 – 1.0 Defined in:
TEKNISK
V433-feature: minimal multiplikator for ikke- position-LR'erne (skala, rotation, opacity, SH) i „extended phase" — altså: efter T50 er nået, og position-LR er allerede ved T4. Hvis 0.1, cosine-decayes skala/rotation/ opacity/SH for deres del fra 1.0 (= deres standard-LR) til 0.1× af deres standard. Hvis 0.0 (default), forbliver de konstante. V457 testede fuldt decay (0.0 = decay-til-nul) mod intet-decay og fandt: avg 0.0400 (2 runs) = samme loss som V438 uden decay. Adfærd renere med decay, men ikke målbart bedre. Derfor disabled. Forbliver i CLI som –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
V440-eksperimental: hvis true, beregner appen i hvert densification-skridt p98 af den aktuelle gradient-fordeling og bruger det som dynamisk tærskel (klampet til mindst 0.5× af den konfigurerede værdi fra T11, så det ikke skejser for langt ud). Hypotese: automatisk tilpasning til aktuel scene-fase ville gøre density-control mere robust — f.eks. strengere pruning i starten, slappere senere, eller omvendt. V440 testede og reverterede: katastrofalt fald til 63 K gaussians (mass-pruning, fordi p98 i de første iterationer er ekstremt højt, og så overskrider næsten intet tærsklen). Den faste tærskel er allerede godt kalibreret, dynamisk tilpasning skader mere end den gavner. Q5 (T77) tilbyder en alternativ adaptiv logik via rolling median, der omgår problemet.
T53mergeAfterDensification
DETALJER
Default: false (initializer), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Defined in:
TEKNISK
V438-feature: ved slutningen af densification-fasen (iter T2) udføres et engangs-merge-pass, der sammenfatter nærtliggende gaussians med lignende skala og farve. Reducerer gaussian-antallet med typisk 5–15 % uden synligt kvalitetstab. Mening: efter intensiv kloning opstår klynger af kvasi- identiske gaussians, der ikke bidrager med noget nyt — merging frigør optimizer-kapacitet til andre områder. Standard i Classic-quality-presets. Bruges ikke ved MCMC, fordi MCMC via sin relocation-logik slet ikke lader sådanne klynger opstå.
T54densifyPhase2FromIteration
DETALJER
Default: 0 (= deaktiveret) Range: 0 eller T2 – T1 Defined in:
TEKNISK
V426-eksperimental: muliggør en anden densification-fase, der efter refinement-pausen starter ved denne iteration og kører til T55. Hypotese: efter en refinement-fase har gradient-akkumulatorerne stabilere magnitudes og kan mere præcist sige, hvilke områder der stadig har brug for yderligere gaussians. V426 testede og reverterede: two-phase densification faldt i 0-gaussians-cascade-failure (kombineret med V425 refinement-pruning ødelagde det bufferen). Disabled. CLI-flag tilgængelig til eksperimenter.
T55densifyPhase2UntilIteration
DETALJER
Default: 0 Range: 0 eller T54 – T1 Defined in:
TEKNISK
Slutning af V426-two-phase-densification. Kun relevant hvis T54 > 0. Begge felter sammen disabled.
Post-processing + Apple AI (T56–T60)
T56postTrainingCompactification
DETALJER
Default: true (i alle production-presets), false (.quickTest, .preview) Range: boolean Defined in:
TEKNISK
V443-feature: efter trænings-slut fjernes gaussians med sigmoid(opacity) < 0.01 hårdt (de bidrager praktisk talt ikke længere til billedet). Reducerer gaussian-count med typisk 58 % og eksport-filstørrelse med 55 % uden synligt kvalitetstab. Som standard aktiv i production-presets — slutresultatet skal kunne leveres så kompakt som muligt. I .quickTest fra, fordi en diagnose-kørsel alligevel ikke eksporteres. I modsætning til T42 midTrainingCompactificationIterations (V549) finder compactificationen først sted ved slutningen — refinement kan indtil da bruge alle gaussians.
T57metalFXUpscaling
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
V444-feature: aktiverer Apples MetalFX spatial upscaler i stedet for bilineær interpolation i 3D-viewer-output. Hvis træningsopløsning < viewport-størrelse (f.eks. træning på 0.5×, viewport-visning i fuld opløsning), kan MetalFX levere et markant skarpere billede. Ændrer sig live i viewporten, ingen genoptræning nødvendig. Udelukker T58 mpsLanczosScaling — MetalFX har forrang. Anbefaling: tænd, hvis billedet i vieweren virker „udvasket" sammenlignet med den forventede detalje.
T58mpsLanczosScaling
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
V444-feature: MPSImageLanczosScale til viewport- skalering i stedet for bilineær interpolation. Lanczos er en klassisk sinc-baseret resampling-metode, der leverer markant skarpere resultater end bilineær med minimal overhead. Live- toggle. Overskrives af T57, hvis begge er tændt.
T59livePreviewInterval
DETALJER
Default: 50 (initializer og de fleste presets) Range: 0 (off) eller 10 – 5 000 Defined in:
TEKNISK
Hvor ofte under træningen 3D-vieweren opdateres med de aktuelle gaussians. 50 = hver 50 iterationer et nyt render i vieweren — godt nok til at iagttage fremskridt uden at sinke træningen. 0 = vieweren opdateres slet ikke (baggrunds- træning, max hastighed). Typisk tilpasning: ved .quickTest ned til 10 (man vil se hvert skridt), ved lange MCMC-kørsler op til 500–2000 (update-overhead i sum mærkbar).
T60perceptualLossWeight
DETALJER
Default: 0.0 (= deaktiveret) Range: 0 eller 0.001 – 0.5 Defined in:
TEKNISK
V444-future-feature: vægt af en perceptuel loss-term via MPSGraph (VGG-lignende lille netværk). Ville fange strukturel og teksturel lighed på et højere semantisk niveau end L1+SSIM — typisk i forsknings-pipelines, hvor „pixel- perfect" er mindre vigtigt end „ser realistisk ud". Implementering stadig udestående (kode-stub findes, men forward- pass ikke implementeret). Default 0.0. Forbliver i feltkataloget til fremtidig aktivering; CLI-flag –percep-weight F reserveret.
MCMC-densification (T61–T73)
T61densificationStrategy
DETALJER
Default: .classic (initializer + Classic-presets), .mcmc (alle MCMC-presets + scene-class) Range: .classic eller .mcmc Defined in:
TEKNISK
Vælger mellem Classic-densification (klon/split/ prune, Kerbl et al. 2023) og MCMC-densification (stochastic gradient Langevin dynamics med relocation, Kheradmand et al. NeurIPS 2024). Ved .classic evalueres T11–T16, ved .mcmc T62–T73. Forsigtighed ved skift: Classic-defaults og MCMC- defaults er totalt anderledes kalibreret — den, der flipper vælgeren i Expert View uden at indlæse en passende preset, risikerer 1.4.3-bug-stil mass-extinction (460 K → 5 i en iteration, fordi MCMC-OpacityReg på 0.01 dræber Classic- opacities). Derfor er MCMC-init-defaults bevidst „blødgjorte" (alle reg-værdier 0.0).
T62mcmcMaxGaussians
DETALJER
Default: 150 000 (initializer + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — Mip-splatting-variant med 10× budget), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) Range: 0 (= „brug buffer-kapacitet") eller 10 000 – 5 000 000 Defined in:
TEKNISK
Hård overgrænse for antallet af gaussians ved MCMC-strategi. Antallet vokser gradvist med T70 mcmcGrowthRate (typisk 5 %) pr. relocation-step op til dette cap. V473/V531 fandt 150 K som sweet spot — over 200 K udvander splat- kvaliteten (for mange små, overflødige gaussians), under 100 K forbliver scenen under-densificeret. Ved meget store scener (f.eks. 1 545-foto-droneflyvning med 158 K SfM-init) er 150 K for lavt — derfor 1.4.5-udvidelsen T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt fandt scene-specifikke optima mellem 670 K (Indoor) og 1.25 M (Outdoor). Ved værdi 0 bruger engine den fulde buffer-kapacitet som cap.
T63mcmcNoiseScale
DETALJER
Default: 0.00005 (5e-5 = paper-default) Range: 1e-6 – 1e-3 Defined in:
TEKNISK
Multiplikator for det gaussiske støj, der i hver MCMC-iteration adderes til positionen af hver gaussian (SGLD- logik). Højere = mere eksploration (gaussians vandrer mere, finder potentielt bedre pladser), lavere = mere udnyttelse (gaussians forbliver, hvor de allerede er gode). V467 og V536 bekræftede 5e-5 som optimal — 1e-5/2e-5 for lidt eksploration, 1e-4 for meget (splats løber ud). Cosine-decayes over træningstiden til T69 mcmcNoiseDecayEnd — ved slutningen af decay-området er støj reelt 0, og gaussians konvergerer.
T64mcmcOpacityRegWeight
DETALJER
Default: 0.0 (= deaktiveret i RadianceKit defaults, paper: 0.01) Range: 0 eller 0.001 – 0.05 Defined in:
TEKNISK
MCMC-specifik L1-penalty på opacity. Paper-default 0.01 (trykker ubrugte gaussians mod nul, gør dem tilgængelige for relocation). V464b viste dog: uden reg er det målbart bedre i RadianceKit (session 28 bekræftet). Grund: pruning-kriteriet defineret med T68 mcmcDeadOpacityThreshold rækker alene — en yderligere L1-penalty tvinger også værdifulde, lav-opacity- gaussians til at dø. Derfor default 0. Advarsel: i 1.4.3-beta-build var initializer-default'en fejlagtigt 0.01, hvilket resulterede i mass-extinction-bug'en (se T61-forklaring); siden 1.4.4 fastsat på 0.0.
T65mcmcScaleRegWeight
DETALJER
Default: 0.0 (= deaktiveret, paper: 0.01) Range: 0 eller 0.001 – 0.05 Defined in:
TEKNISK
MCMC-specifik L1-penalty på skala-egenværdier. Paper-default 0.01. V464b: uden reg bedre, samme begrundelse som T64. Disabled i alle RadianceKit-MCMC-presets. Advarsel som ved T64: 1.4.3-bug.
T66mcmcRelocationInterval
DETALJER
Default: 100 (initializer + alle MCMC-presets, paper-standard), 155 (P9 Outdoor — Q7-BayesOpt-optimum) Range: 50 – 500 Defined in:
TEKNISK
Iterations-interval, hvor MCMC reloacerer døde gaussians (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) til nye positioner. V537 testede 50 (for forstyrrende, loss svinger) og 200 (marginalt dårligere, MCMC mister reaktionsevne). 100 er optimal. Q7-BayesOpt på Bicycle fandt 155 som scene- specifikt optimum for outdoor — de let længere intervaller giver Adam mere tid til at integrere nyplacerede gaussians, før næste reloc-event sætter dem under pres.
T67mcmcWarmupIterations
DETALJER
Default: 500 Range: 100 – 5 000 Defined in:
TEKNISK
Antal initial-iterationer, hvor ingen MCMC- relocation endnu sker. Først efter denne warmup begynder reloc- logikken. Mening: i de første iterationer er opacity-værdierne endnu ikke afbalancerede — hvis der startedes direkte med reloc, ville gaussians blive placeret de forkerte steder og straks skulle flyttes igen, hvilket ødelægger Adam-momentum. Paper-default 500. RadianceKit overtager denne værdi, fordi V464b viste, at den er robust.
T68mcmcDeadOpacityThreshold
DETALJER
Default: 0.005 (initializer, paper-standard), 0.01 (.fullMCMC og alle MCMC-presets — V535-optimum) Range: 0.001 – 0.05 Defined in:
TEKNISK
sigmoid(opacity)-tærskel, under hvilken en gaussian regnes som „død" og kommer i betragtning til relocation. V535 fandt 0.01 som optimal (0.005 marginal, 0.02 dårligere). Højere = mere aggressiv reloc (flere gaussians flyttes), lavere = mere forsigtig. 0.01 svarer ca. til „0.5 % visuel synlighed". P10 Indoor bruger via Q7-BayesOpt 0.0142 som optimum.
T69mcmcNoiseDecayEnd
DETALJER
Default: 0 (initializer = „ingen decay"), 160 000 (.fullMCMC = 80 % af 200K), 96 000 (.mcmcBalanced = 80 % af 120K), 40 000 (.mcmcPreview) Range: 0 eller 1 000 – Defined in:
TEKNISK
Iteration, hvor T63 mcmcNoiseScale-støj dæmpes fuldstændigt til nul (cosine-decay fra iter 0 til her). V497c/V502 fandt 80 % af maxIterations optimal — giver MCMC nok eksplorations-tid, men lader de sidste 20 % gå til konvergens uden støj. 0 = konstant støj over alle iterationer (sjældent meningsfuldt, MCMC kan så ikke konvergere).
T70mcmcGrowthRate
DETALJER
Default: 0.05 (paper-standard = 5 %) Range: 0.01 – 0.2 Defined in:
TEKNISK
Vækstrate af MCMC-populations-targetet pr. relocation-step. Logikken: ved hver reloc-event øges mål-populations-størrelsen med (1 + growthRate), indtil T62 mcmcMaxGaussians (eller den per T72/T73 skalerede variant) er nået. V512/V522 fandt 0.05 som optimal — højere værdier fører til for hurtig vækst (gaussians indsættes, før Adam-momentum kan integrere dem), lavere til under-densificerede scener til sidst.
T71mcmcSigmoidK
DETALJER
Default: 100.0 Range: 10.0 – 500.0 Defined in:
TEKNISK
Sigmoid-sharpness-parameter for MCMC-noise- attenuation. I SGLD-skridtet dæmpes per-gaussian-støjen med — højt-opake gaussians (hvis logit er positiv) får eksponentielt mindre støj end lavt-opake. K = 100 er skarp, sprich overgangen fra „fuld-noise" til „ingen-noise" sker meget hurtigt omkring opacity 0.5. V484–V487 fandt K = 100 optimal — mindre værdier (10–50) lader også højt-opake gaussians wackle med (ødelægger konvergerede gaussians), større (> 500) gør overgangen kunstigt hård, og døde gaussians flyttes slet ikke mere.
T72mcmcCapMultiplier
DETALJER
Default: 3.0 (initializer + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Range: 0 (= deaktiveret) eller 1.0 – 10.0 Defined in:
TEKNISK
1.4.5-feature: scene-adaptiv cap-skalering. Hvis T73 mcmcAutoScaleByScene true, beregnes det effektive cap som (klampet til buffer-kapacitet). Baggrund: ved store scener (f.eks. 1 545-foto-droneflyvning → 158 K SfM-init) er T62 = 150 000 for lavt — density-control ville slet ikke kunne vokse. Med multiplier 3.0 skaleres cap'et i dette eksempel til 474 K (158 K × 3.0). Q7-BayesOpt fandt scene- specifikke optima: outdoor profiterer af høj multiplier (5.32 → ~830 K cap ved 156 K bicycle-init), indoor nøjes med 1.76 (vægge mætter hurtigere). Fuld opløsning af cap'et se -metoden.
T73mcmcAutoScaleByScene
DETALJER
Default: true (initializer + alle MCMC-presets) Range: boolean Defined in:
TEKNISK
1.4.5-feature: master-switch for scene-aware cap- logikken (se T72 +). Hvis false, bruges udelukkende T62 mcmcMaxGaussians som cap (tilbage til 1.4.4-adfærd). Som standard tændt, fordi mass-extinction-problemerne ved store scener fra 1.4.3 ellers kommer tilbage. Manuelt deaktivere kun, hvis du eksplicit vil sætte et hårdt cap — f.eks. for at træne en 150 K-variant, hvis slutstørrelse kan planlægges.
Mip-splatting (Q1.5) (T74–T76)
Status: Q1.5 blev 2026-05-25 efter 14 autonome iterationer + overnight-1.5M-confidence-check kasseret som „closed no-win" (max Δ@2× = +0.27 dB, original-gate krævede ≥ +1.5 dB middelværdi over 0.5×/2×, FAILT på 0/11 pair-scenes). Felterne forbliver opt-in til forskningseksperimenter; alle production- presets har. Se verdict:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETALJER
Default: false (alle production-presets), true (.fullMCMCMip — forsknings-sibling) Range: boolean Defined in:
TEKNISK
Aktiverer Mip-splatting (Yu et al. CVPR 2024): 3D-smoothing-filter + 2D-filter + α-kompensation, der begrænser per-gaussian-frekvensen til Nyquist-grænsen af den tætteste træningskamera-samplingsrate. Teoretisk mål: eliminering af aliasing ved rendering i off-training-skalaer (0.5× eller 2× af træningsopløsningen). Aktiveret i preprocess- og backward- projection-shaderne, funktionelt korrekt verificeret i Q1.5-D- test. Men: det originale acceptance-gate (Δ@1× ≥ +0.3 dB OG avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) blev ikke nået på nogen af de 11 pair-scenes. Maksimalt observeret: family 750K classic Δ@2× = +0.270 dB. Outdoor-scener (Truck, Flowers) viste endda forværring 1× og 0.5×. Hypotese: 3D-smoothing konkurrerer med MCMC-relocation ved high-Gs. Feltet forbliver til fremtidig multi-scale-re-eval med korrekt Mip-NeRF-360-metodologi (se O3-backlog i benchmark-stien).
T75mipSmoothing3DScale
DETALJER
Default: 0.2 (paper-default) Range: 0.05 – 1.0 Defined in:
TEKNISK
3D-smoothing-skala-parameter (Yu et al. §3.3, paper- default 0.2). Større = mere world-space-udjævning pr. gaussian (= mere anti-aliasing, men også mere blur i default-skalaen), mindre = skarpere, men mere modtagelig for aliasing. Konsulteres kun, hvis T74 useMipSplatting = true. I Q1.5-tests ikke yderligere optimeret — A/B-gate'en havde allerede tabt med paper-default 0.2, yderligere sweeps ville være nytteløse.
T76mipFilter2DVariance
DETALJER
Default: 0.3 (= præcis V242-legacy-adfærd) Range: 0.1 – 1.0 Defined in:
TEKNISK
2D-Mip-filter-varians, der adderes til Σ_2D- diagonalen (varians direkte, ikke kvadreret). 0.3 er præcis V242-legacy-værdien, der før Mip-splatting var hardkodet i kerneler. Hvis T74 useMipSplatting = false, ignorerer kernel denne værdi fuldstændigt og skriver det hardkodede 0.3 — så baselinen ikke kan regredere (Codex-round-1-S3-1-garanti). Hvis, bruges den her satte værdi. Forbliver i feltkataloget til Mip-sweeps.
Adaptive densification (Q5) (T77–T79)
T77adaptiveDensification
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
Q5-feature: rolling-median-tracker som alternativ til faste T11 densifyGradThreshold. Hvis true, overskrives den aktuelle tærskel i hvert densify-step med median(seneste N avgGrad-samples) × T79 adaptiveDensifyMultiplier. N = T78 adaptiveWindow. Strengere end V440 p98 (den katastrofale 63 K-pruning-fælde), median + 2× sidder omtrent ved p70–p80 af gradient-fordelingen i steady state. Q5-tests: alenestående FAIL 0/3 scener, men sammen med Q6 (se T80/T81) PASS 1/3 scener — bundtet Q5+Q6 blev 2026-05-25 godkendt som opt-in og aktiveres via CLI –adaptive-densify. Q6 er her „carrier" af kvalitetsgevinsten, Q5 bidrager snarere til stabilitet.
T78adaptiveWindow
DETALJER
Default: 1 000 Range: 100 – 10 000 Defined in:
TEKNISK
Rolling-median-vindue i densification-events (IKKE iterationer — hvert T13 densifyInterval-step leverer et sample). Default 1 000 — betyder ved, at de seneste 100 000 trænings-iterationer bidrager til medianen, altså typisk hele træningshistorikken indtil her. Tidlig fase (før T78 samples): tracker returnerer nil → fallback på fast tærskel T11. Kun relevant hvis.
T79adaptiveDensifyMultiplier
DETALJER
Default: 2.0 Range: 1.0 – 4.0 Defined in:
TEKNISK
Multiplikator på rolling-median for den adaptive tærskel. Default 2.0 svarer ca. til p70–p80 af den typiske gradient-fordeling. Lavere = mere aggressiv vækst (flere kloner), højere = strengere (færre kloner). Q5-tests i range 1.5–3.0 — 2.0 bedste default. Kun relevant hvis.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
Q6-feature: trænings-opløsning starter ved 0.5× og skifter ved T50 positionLRScheduleEndIteration / 2 (eller T1 maxIterations / 2, hvis T50 ikke er sat) til T22 trainingRenderScale. Bruger den i Q1.5.1 udviklede resize/restoreImageBuffers-infrastruktur. Overskriver T23 resolutionWarmupScale, hvis aktiveret. Q6 er godkendt som „carrier af kvalitetsgevinsten" i Q5+Q6-bundtet (se T77) — den trinvise opløsningsforøgelse giver appen tid til at finde grov geometri på den lavere opløsning, før den går over til det fine detalje-arbejde. Via CLI: –curriculum-resolution.
T81curriculumSHProgression
DETALJER
Default: false Range: boolean Defined in:
TEKNISK
Q6-feature: overskriver T21 shDegreeUpgradeIterations med [maxIter/4, maxIter/2, maxIter*3/4], fordeler altså SH- optrapningerne jævnt over træningstiden i stedet for at front- loade dem. Hypotese: stabil geometri etableres før color-detail- eksplosion, hvilket positionerer view-direction-afhængige glans- effekter mere præcist. Q5+Q6 sammen PASS 1/3 scener, Q6 som carrier af gevinsten (Q5 alene FAIL). Via CLI: –curriculum-sh.
Statiske presets (TP1–TP9)
Her kun de strukturelle forskelle til initializer-default'en. Den fulde marketing-beskrivelse af de ti UI-presets P1–P10 finder du i kapitel 7.
TP1.preview
DETALJER
Diagnose-/forhåndsvisnings-preset til systemer ≥ 10 GB RAM. Overrides i forhold til initializer: - 30 000 → 5 000 - 15 000 → 3 500 (70 % af maxIter) - 1.6e-6 → 1.6e-5 (10× højere, mindre aggressiv decay) -,,,, hver 2× (V176) - 3 000 → 100 000 (reelt fra, V172: reset ødelægger korte træninger) - [1K, 2K, 3K] → [1K, 2K] (V182: degree 3 konvergerer ikke i 2K iter) - 1.0 → 0.5
TP2.full
DETALJER
Production-Quality Classic. Overrides: - 30 000 → 35 000 (V550: 40K-tests Truck-overtraining +10.7 % Gs ved -1.3 % L1) - 15 000 → 5 000 (V310 sweet spot, V338 7K worse) - Alle LR'er 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 disabled, V421 confirmed) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 delayed) - 0.0 → 0.9995 (V546 HTGS, 14 % forbedring) - 50 (uændret, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, allerede initializer-default for .full)
TP3.fullClassicPaper
DETALJER
Q1.5-A-test-sibling af TP2, paper-tro Classic. Overrides i forhold til TP2: - 35 000 → 30 000 (paper-standard) - 5 000 → 15 000 (paper: 50 % af maxIter) - 1.6e-5 → 1.6e-6 (paper-default) -,, tilbage til paper defaults (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (kalibreret for ~1-2M Gs på Bicycle) - 200 → 100 (paper) - 0.001 → 0.005 (paper-default) - 100 000 → 3 000 (paper §5.2, risikabelt — kan udløse V194- regression) - 0.9995 → 0.0 (paper har ingen decay) - 20 000 → 30 000 (cosine kører til 100 % af maxIter)
TP4.fullMCMC
DETALJER
Production-Quality MCMC. Overrides i forhold til initializer: - 30 000 → 200 000 (V534, MCMC har brug for 5× flere iter end Classic) - 15 000 → 160 000 (V504b 80 % af maxIter) - 1.6e-6 → 1.6e-5 - LR-schedule som TP2 (alle 2×) - 0.2 → 0.05 (V521b/V534: MCMC har brug for stærkere L1-signal) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (allerede i initializer, bekræftet i preset) - 5e-5 (V467/V536 optimal) - 0.005 → 0.01 (V535 optimal) - 0 → 160 000 (80 % af maxIter, V497c/V502) - 3.0 (allerede i initializer) - true (allerede i initializer) - 3 000 → 200 000 (reelt fra, MCMC bruger reloc i stedet for reset)
TP5.fullMCMCMip
DETALJER
Q1.5-D-test-sibling af TP4, med Mip-splatting + paper- magnitude-MCMC-budget. Overrides i forhold til TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, paper-magnitude) - useMipSplatting false → true (Mip-on)
TP6.classicBalanced
DETALJER
Mid-tier Classic. Overrides i forhold til TP2: - 35 000 → 20 000 (V149: 20K = 30K ved 33 % mindre tid) - 20 000 → 0 (cosine kører til maxIter = 20K, ingen extended phase)
TP7.mcmcPreview
DETALJER
MCMC-diagnose. Overrides i forhold til TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: preview = lighter scaling)
TP8.mcmcBalanced
DETALJER
Mid-tier MCMC. Overrides i forhold til TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3.0 → 2.5 (mellem Preview 2.0 og Full 3.0)
TP9.quickTest
DETALJER
Ren funktionstest. Overrides i forhold til initializer: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (kalibreret for 0.25× opløsning) - 100 → 50 - 3 000 → 100 000 (fra, da alt for kort) - 1.0 → 0.25
Metoden:
Signatur: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Defined in:
Eneste source-of-truth for spørgsmålet „hvor mange gaussians må MCMC maksimalt lade vokse?". Beregnes ud fra tre input: det konfigurerede T62 mcmcMaxGaussians (med mass-extinction-floor 150 000, hvis 0), (antal SfM- init-punkter) og (forhåndsallokeret gaussian- buffer-størrelse). Logik:
+ base = T62 > 0 ? T62: 150_000 (mass-extinction-floor beskytter mod initializer-default-bugs som 1.4.3-mass-extinction- hændelsen) + Hvis T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) ellers
+ Hvis bufferCapacity > 0: return min(scaled, bufferCapacity) + Ellers return scaled
Eksempel: Bicycle (Mip-NeRF 360, 194 foto-frames) → SfM-init ~156 K punkter, T62 = 150 000, T72 = 5.32, buffer-kapacitet 8 M. Resolved cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. Det er det effektive vækst-cap, som MCMC-relocation-logikken holder sig til.
Beregner det reelle maksimum-splat-antal ved MCMC. Tager din indstilling, ser, hvor mange punkter din scene har i starten, og skalerer med multipliceren, hvis automatisk tilpasning er tændt. Sådan tilpasser cap'et sig scenen i stedet for at tvinge samme værdi til en lille og en gigantisk scene. Du behøver ikke selv kalde metoden — træningen bruger den internt.
Hvilket felt til hvad? (cheat sheet)
| Mål | Felter at dreje på |
|---|---|
| Mere detalje i det fjerne | T62 mcmcMaxGaussians højt, T72 mcmcCapMultiplier 5+ |
| Mere detalje generelt (Classic) | T1 maxIterations højt (≤ 40K), T2 densifyUntilIteration ≤ 14 % af T1 |
| Reducere floaters i droneflyvninger | T43 frustumCullEnabled til, T20 skyMaskingEnabled til, T45 skyDomeEnabled til |
| Pæn himmel i udendørs scener | T45 skyDomeEnabled til, T47 skyDomeRadiusMultiplier 30–60 |
| Mindre eksport-fil | Strategi .mcmc (T61), T56 postTrainingCompactification til, T62 mcmcMaxGaussians ≤ 200K |
| Hurtigere træning | T22 trainingRenderScale 0.5, T1 maxIterations halvere — men ikke begge! |
| Bedre højlys | T21 shDegreeUpgradeIterations med [2K, 5K, 8K] (ingen early-front-load), MCMC + 200K iter |
| Holde Mac responsiv | T25 throttleDelayMs 5–10 (koster ~15 % træningstid) |
| Live-forhåndsvisning oftere | T59 livePreviewInterval ned til 10–20 |
| Blødere overgange ved skygger | T17 ssimWeight lidt højt (0.15–0.25), men ikke over 0.3 |
| Holde indendørs rum kompakt | P10 Indoor-preset (, T72 = 1.76) |
Farlige felter
Disse felter kan ved fejl-konfiguration føre til OOM, app-crash, mass-extinction af gaussians eller ubrugelige benchmark-data. Skal håndteres med forsigtighed:
- T11 densifyGradThreshold — en halvering kan generere 2–4× så mange gaussians, hvilket hurtigt sprænger GPU-lageret. Bemærk også: skal passe til T22 trainingRenderScale (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — ved store scener med > 200 K SfM-init-punkter og multiplier > 5 opstår et resolved-cap på millioner af gaussians. På 36-GB-RAM-Mac'er OOM muligt. Outdoor-preset 5.32 fungerer kun, fordi Mip-NeRF-360-Bicycle har 156 K init-punkter → 830 K cap. - T39 testViewIndices — manuel indstilling kan gøre benchmarket ubrugeligt (alle indekser > N → ingen holdouts). Lad –benchmark-flaget sætte det. - T64 mcmcOpacityRegWeight og T65 mcmcScaleRegWeight — i 1.4.3-beta sat til 0.01, hvilket førte til mass-extinction (460 K → 5 gaussians på en iteration). Siden 1.4.4 fastsat på 0.0, men manuel forhøjelse kan reproducere problemet. - T15 opacityResetInterval — hvis ikke 100 000+ (reelt fra) og træningen er kortere end 10 000 iterationer, ødelægger reset konvergensen. .preview har det derfor på 100 000 trods maxIterations = 5 000. - T54/T55 densifyPhase2* — two-phase densification er i tests afsluttet i 0-gaussians-cascade. Lad begge stå på 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, kan endda forværre PSNR på nogle outdoor-scener. Default off, opt-in kun til forskning.
Hvis et felt står på denne liste, og du vil ændre det, så lav først en sikkerhedskopi af din nuværende preset (eksport som JSON), og overvej, om du kan måle resultatet reproducerbart — ellers ved du bagefter ikke, om du har fremkaldt en forbedring eller forværring.