Luku 6 — Koulutuksen määritykset
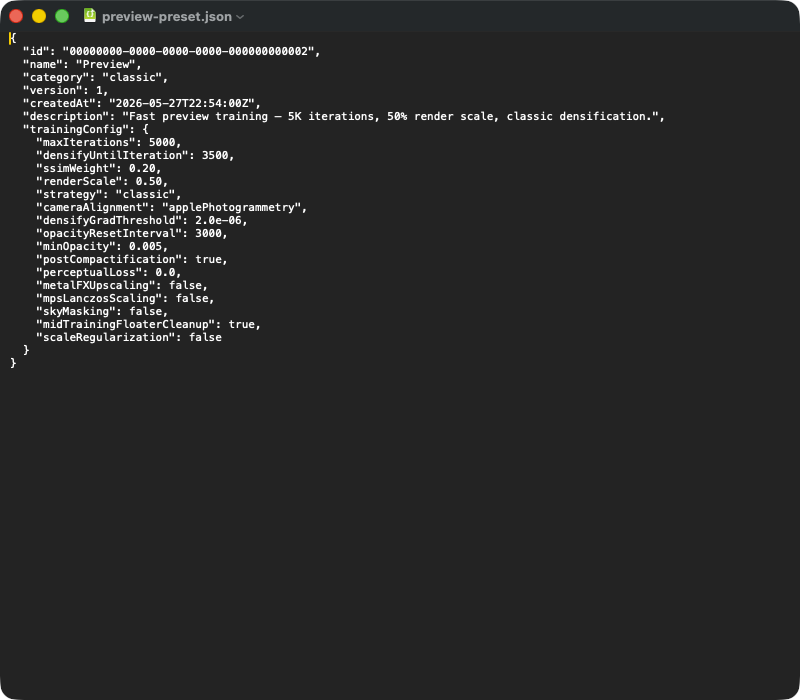
Tyypillinen esiasetuksen JSON-vienti. Ylätason kentät: id (UUID), name, (classic | mcmc | sceneClass | custom), (skeeman versio), (aikaleima), (vapaa teksti). Sisäkkäinen -objekti sisältää toistettavuuden kannalta kriittiset parametrit — tuonnin yhteydessä koko lohko deserialisoidaan TrainingConfig-rakenteeseen, ja sovelluksen version oletusarvot täyttävät JSON-tiedostosta puuttuvat kentät (esim. sovelluspäivityksen jälkeen). Jos haluat siirtää esiasetuksen toiselle Macille, lähetä vain tämä JSON-tiedosto.
TrainingConfig-rakenne on jokaisen RadianceKitin koulutusajon ydin. Se kokoaa yhteen kaikki koulutukseen vaikuttavat parametrit — maksimi-iteraatiomäärästä ja kahdeksasta oppimisnopeudesta aina MCMC:n, Mip-Splattingin, curriculumin ja scene-aware cap -logiikan erikoiskenttiin. Muokkaat sitä sivupalkin Koulutuksen määritykset -osiossa (asiantuntijatila), tallennat sen esiasetuksena tai siirrät sen JSON-vientinä toiselle Macille. Koulutuksen aikana juuri tämä objekti jäädytetään ja annetaan GPU-taustaohjelmalle.
Tämä luku on referenssimateriaalia tehokäyttäjille ja skriptien kirjoittajille. Se luettelee kaikki 81 julkista kenttää, 9 staattista esiasetusta ja yhden julkisen metodin. Lähdetiedosto on TrainingConfig.swift — epäselvissä tapauksissa siellä oleva dokumentaatiokommentti ja alustajan oletusarvo ovat totuuden lähde.
Sisällysluettelo:
+ Iteraatio (T1–T2) + Oppimisnopeudet (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH-asteen progressio (T21) + Suorituskyky (T22–T25) + Diagnoosi ja pistepilven valmistelu (T26–T30) + Regularisointi (T31–T37) + Hienosäätö (T38–T44) + Sky-Dome (T45–T48) + Adam + LR-aikataulu (T49–T55) + Jälkikäsittely + Apple AI (T56–T60) + MCMC-Densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptiivinen Densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Staattiset esiasetukset (TP1–TP9) + Metodi: + Mikä kenttä mihinkin? (Muistilista) + Vaaralliset kentät
Iteraatio (T1–T2)
T1maxIterations
TIEDOT
Oletus: 30 000 (alustaja), 35 000 (.full), 200 000 (.fullMCMC) Alue: 1 000 – 500 000 (käyttöliittymän liukusäädin), ei kovaa ylärajaa logiikassa Määritelty:
TEKNINEN
Koulutusiteraatioiden kokonaismäärä, jonka taustaohjelma suorittaa. Yksi iteraatio tarkoittaa yhden koulutuskameran forward-renderöintiä, backward-passia kaikkien loss-komponenttien yli (L1 + SSIM + valinnaiset regularisoinnit + Sky-Mask) ja yhtä Adam-optimoijan askelta. Tämä luku vaikuttaa suoraan muihin aikatauluihin: sijainnin oppimisnopeus noudattaa kosinin vaimennuskäyrää 0:sta joko T1:een itseensä tai T49 positionLRScheduleEndIteration:iin asti; Densification pysähtyy T2 densifyUntilIteration:iin; MCMC-kohinan vaimennus päättyy T69 mcmcNoiseDecayEnd:iin; SH-asteen päivitykset tapahtuvat kolmessa T21:ssä määritellyssä kohdassa. Klassisessa Densificationissa empiirisesti määritetty optimaalinen alue on 20 000–35 000 iteraatiota (sessiot 1–32, V546-testit), MCMC:ssä 60 000–200 000 (V534). Arvojen nostaminen merkittävästi esiasetuksissa määriteltyjen yläpuolelle tuo harvoin lisää laatua — Adam-momentum kyllästyy, ja ilman oppimisnopeuden vaimennuksen loppua loss pysähtyy. Toisaalta, alle ~5 000 iteraation jääminen johtaa epätäydellisesti konvergoituneisiin geometrioihin (Density-Controlilla ei ole tarpeeksi aikaa kloonata/jakaa).
T2densifyUntilIteration
TIEDOT
Oletus: 15 000 (alustaja), 5 000 (.full), 160 000 (.fullMCMC) Alue: 0 – Määritelty:
TEKNINEN
Iteraatio, josta alkaen Densification pysähtyy. Tähän asti Gaussianeja kloonataan, jaetaan ja karsitaan T11–T16 (Classic) tai T67–T70 (MCMC) parametrien mukaisesti; sen jälkeen Gaussianien määrä pysyy vakiona ja vain sijainteja, rotaatioita, skaaloja, opasiteetteja ja SH-kertoimia optimoidaan (hienosäätövaihe). Alkuperäisessä 3DGS-artikkelissa arvo on 50 % T1:stä, RadianceKitin .full-esiasetuksessa vain ~14 % (5 000 / 35 000) — tämä on seurausta V310/V338-kokeista, jotka osoittivat, että 5 000 iteraation jälkeen jatkuva tihentäminen pikemminkin heikentää tulosta (enemmän leijuvia partikkeleita, enemmän muistinkulutusta, ei laadun parannusta). MCMC sen sijaan suorittaa uudelleensijoituksen 80 %:iin T1:stä asti (V504b), koska MCMC ei tuota haitallisia leijuvia partikkeleita. Jos T2 valitaan liian pieneksi (< 1 000), syntyy liian vähän Gaussianeja; liian suuri arvo Classicissa (> 50 % T1:stä) johtaa ylikasvuun ja RGB-saturaation poikkeamiin (katso Outdoor-Overtraining-Findings).
Oppimisnopeudet (T3–T10)
T3positionLearningRate
TIEDOT
Oletus: 0.00016 Alue: 1e-7 – 1e-3 (suositeltu) Määritelty:
TEKNINEN
Adam-oppimisnopeus kunkin Gaussianin XYZ-sijainnille koulutuksen alussa (iteraatio 0). Noudattaa kosinin vaimennuskäyrää ja laskee koulutuksen aikana arvoon T4 positionLearningRateFinal. Oletusarvo 0.00016 on peräisin alkuperäisestä 3DGS-artikkelista (Kerbl et al.~2023) eikä sitä RadianceKitissä tule skaalata kuvan resoluution kasvaessa — sijainti liikkuu maailman koordinaatistossa, ei pikseliavaruudessa. Merkittävä nosto (> 0.0005) saa Gaussianit hyppimään pitkiä matkoja ja tekee lossista epävakaan; huomattavasti pienemmät arvot (< 0.00005) johtavat siihen, että väärin alustetut pistepilvet eivät koskaan löydä paikkaansa. V414 testasi alustusarvon tuplaamista → 16.8 % huonompi L1-loss; V544a-säädöt vahvistivat artikkelin oletusarvon optimaaliseksi. Huomaa: .fullMCMC:ssä pidämme tämän arvon tarkoituksella oletuksena — MCMC tarvitsee vakioita oppimisnopeuksia uudelleensijoituslogiikkaansa varten, joten tämän säätäminen ei hyödytä.
T4positionLearningRateFinal
TIEDOT
Oletus: 0.0000016 (alustaja + artikkeli), 0.000016 (.full, .fullMCMC — 10× korkeampi) Alue: 0 – Määritelty:
TEKNINEN
Sijainnin oppimisnopeuden kosinin vaimennuskäyrän loppuarvo. Se saavutetaan joko T1 maxIterations:ssa tai, jos asetettu, T49 positionLRScheduleEndIteration:ssa. RadianceKitin .full-esiasetus käyttää arvoa 0.000016 — eli 10× korkeampaa kuin artikkelin oletus 0.0000016. V420-kokeet osoittivat, että 0.5× loppuarvosta (0.000008) heikensi lossia 6.4 %; V414 osoitti, että 2× alustusarvo heikensi sitä 16.8 %. Korkea loppuarvo ei ole kompromissi, vaan tietoinen valinta: liian voimakas vaimennus saa Gaussianit menettämään kykynsä sopeutua uusiin tihennysehdotuksiin hienosäätövaiheen aikana. V431/V433-laajennuksen kautta aikatauluvaihetta voidaan lyhentää (T49 < T1), jolloin T4 saavutetaan jo ennen koulutuksen loppua ja loppu koulutus suoritetaan vakiolla mini-oppimisnopeudella — tyypillinen konfiguraatio: T49 = 20 000, T1 = 35 000, eli hienosäätö 0.000016:lla 15 000 iteraation ajan.
T5shDCLearningRate
TIEDOT
Oletus: 0.0025 (alustaja + artikkeli), 0.005 (.full ja kaikki MCMC-esiasetukset — 2×) Alue: 0.0001 – 0.05 Määritelty:
TEKNINEN
Adam-oppimisnopeus spherical-harmonic-värin DC-osuudelle (aste 0, eli vakio albedo). SH-DC vastaa Gaussianin suunnasta riippumatonta perussävyä, tavallaan "perusväriä". V176- ja V188-kokeissa havaittiin 2× korkeampi arvo artikkelin oletusta optimaalisemmaksi — nopeampi värin konvergenssi, erityisesti koska lyhyessä koulutuksessa (, 5 000 iteraatiota) SH-DC ei muuten ehdi muotoutua. Toisin kuin geometrisilla oppimisnopeuksilla, SH-DC:llä ei ole vaimennusta; oppimisnopeus pysyy vakiona kaikkien iteraatioiden ajan (tai noudattaa vain valinnaista T51:n laajennetun vaiheen vaimennusta). V416 testasi nelinkertaistamista 0.01:een → 6.4 % huonompi loss beta2=0.99-Adamilla.
T6shRestLearningRate
TIEDOT
Oletus: 0.000125 (alustaja + artikkeli), 0.00025 (.full ja MCMC — 2×) Alue: 0.000001 – 0.005 Määritelty:
TEKNINEN
Adam-oppimisnopeus korkeamman asteen SH-kertoimille (aste 1, 2, 3 — eli katselusuunnasta riippuvat värikomponentit, jotka vastaavat kiiltokohdista, heijastuksista ja pehmeästä varjostuksesta). 20× pienempi kuin T5 artikkelin käytännön mukaan, koska näiden kertoimien määrä kasvaa neliöllisesti (3 astetta 1 varten, 5 astetta 2 varten, 7 astetta 3 varten → yhteensä 15 float-arvoa per Gaussian) ja ilman pienempää oppimisnopeutta kuva ylikyllästyisi. Otetaan käyttöön kahdessa vaiheessa — ennen ensimmäistä T21 shDegreeUpgradeIterations:n merkkiä vain aste 0 on aktiivinen (eli vain T5), sen jälkeen 1, myöhemmin 2 ja lopulta 3. Matalat arvot tässä ovat erityisen tärkeitä näkymissä, joissa on paljon diffuusia valaistusta; erittäin kiiltävillä pinnoilla (auton maali, vesi) säätäminen ei kannata — SH-esitystapa itsessään on rajallinen.
T7opacityLearningRate
TIEDOT
Oletus: 0.05 (alustaja + artikkeli), 0.1 (.full, MCMC — 2×) Alue: 0.001 – 1.0 Määritelty:
TEKNINEN
Adam-oppimisnopeus kunkin Gaussianin logit-opasiteetille. Sovellus tallentaa opasiteetin rajoittamattomana float-arvona ja muuntaa sen sigmoidilla välille [0, 1]; oppimisnopeus vaikuttaa logit-avaruudessa. Artikkelin oletus 0.05 on palautettu V50-testien jälkeen (paras yksittäisajo L1 0.1664), V71 peruutti V67:n 0.025:n. V188:n tuplaus 0.1:een tekee karsinnasta tehokkaampaa — kuolleet Gaussianit putoavat nopeammin T14 pruneOpacityThreshold:n alle. V418 osoitti: 0.05 beta2=0.99-Adamilla on 7.1 % huonompi kuin 0.1 — vuorovaikutus Adam-konfiguraation kanssa ei ole triviaali. Matalat arvot (< 0.01) johtavat siihen, että "kuolleet" Gaussianit jäävät pyörimään ja kuluttavat muistia; liian korkeat arvot (> 0.5) voivat johtaa opasiteetin räjähdykseen, joten logit-arvo on rajoitettu optimoijassa välille [-15, 3] (katso huomautus "Opacity Explosion Prevention" CLAUDE.md:ssä).
T8opacityLearningRateFinal
TIEDOT
Oletus: 0.0 (= "ei vaimennusta") Alue: 0 tai 0.001 – Määritelty:
TEKNINEN
Valinnainen kosinin vaimennuksen loppuarvo opasiteetin oppimisnopeudelle (V427). Jos 0.0, vaimennus on pois päältä ja opasiteetin oppimisnopeus pysyy koko koulutuksen ajan vakiona arvossa T7. V427 testasi vaimennusta 0.1 → 0.01 — tulos 11.5 % huonompi loss; peruutettu, joten oletus on "pois päältä". Kentän taustalla oleva hypoteesi: hienosäätövaiheessa vakio opasiteetin oppimisnopeus voisi johtaa oskillointiin, jolloin splatit, jotka ovat jo saavuttaneet oikean läpinäkyvyyden, siirtyisivät uudelleen satunnaisten gradienttivaihteluiden vuoksi. Empiirisesti tämä ei vahvistu — logit-rajoituslogiikka hoitaa tämän jo. Kenttä pysyy saatavilla tulevia kokeita varten; myös erittäin pitkät MCMC-ajot (> 500K iteraatiota) voisivat hyötyä siitä.
T9scaleLearningRate
TIEDOT
Oletus: 0.005 (alustaja + artikkeli), 0.01 (.full, MCMC — 2×) Alue: 0.0001 – 0.1 Määritelty:
TEKNINEN
Adam-oppimisnopeus kunkin Gaussianin kolmelle skaalakomponentille log-avaruudessa (RadianceKit tallentaa log(scale), jotta skaalat pysyvät positiivisina). Artikkelin oletus 0.005, RadianceKitissä tuplattu 0.01:een paremman skaalan konvergenssin saavuttamiseksi optimoiduilla oppimisnopeuskonfiguraatioilla. V423-koe: 0.005 beta2=0.99-Adamilla → 18.7 % huonompi loss ja näkyvästi liian vähän Gaussianeja (Density-Control ei voinut kloonata, koska skaalapäivitykset olivat liian hitaita). Skaala kontrolloi kunkin Gaussianin laajuutta — liian nopea oppiminen johtaa "neula"-Gaussaneihin (erittäin pitkät ohuet splatit, katso T34 scaleRatioPruneThreshold), liian hidas oppiminen jättää splatit liian kompakteiksi ja Density-Controlin on jaettava liian usein.
T10rotationLearningRate
TIEDOT
Oletus: 0.001 (alustaja + artikkeli), 0.002 (.full, MCMC — 2×) Alue: 0.0001 – 0.05 Määritelty:
TEKNINEN
Adam-oppimisnopeus kunkin Gaussianin neljälle kvaternionikomponentille. Kvaternio normalisoidaan jokaisessa optimoijan vaiheessa Adam-päivityksen jälkeen (L2-normi = 1) — muuten kovarianssimatriisi degeneroituisi. RadianceKit tuplaa artikkelin oletuksen Quality-esiasetuksissa, koska rotaatiolla on skaalaan / sijaintiin verrattuna pienemmät absoluuttiset gradienttisuuruudet (yksikköpallolla jokainen askel pysyy lyhyenä) ja ilman 2×-kerrointa rotaatio olisi 35 000 iteraation ikkunassa selvästi ali-konvergoitunut. Dokumentoitu V188:ssa. NeRF-Blender-näkymissä (Lego, Chair) rotaatio vaikuttaa erityisen paljon — kohteiden reunat suuntautuvat oikein vasta 5 000–10 000 iteraation jälkeen.
Densification — Classic (T11–T16)
T11densifyGradThreshold
TIEDOT
Oletus: 0.000002 (alustaja, kalibroitu 0.5× resoluutiolle), 0.0000011 (.full, kalibroitu 1.0×:lle), 0.000004 (.quickTest, kalibroitu 0.25×:lle), 2e-7 (.fullClassicPaper) Alue: 1e-8 – 1e-3 (resoluutiosta riippuvainen) Määritelty:
TEKNINEN
Kynnysarvo näyttöavaruuteen projisoidun gradientin dMean2D L2-normille, jonka yläpuolella Gaussian merkitään kloonattavaksi tai jaettavaksi. Absoluuttinen arvo riippuu suoraan koulutusresoluutiosta — dMean2D skaalautuu suunnilleen kuten 1/resoluutio² (enemmän pikseleitä = pienemmät pikselikohtaiset gradientit). Siksi jokainen T22 trainingRenderScale -taso tarvitsee kalibroidun kynnysarvon: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). Artikkelin oletus 0.0002 on NDC-normalisoitu eikä ole suoraan verrattavissa RadianceKitin maailmanavaruuden putkeen. V440:ssä lisätyllä T52 adaptiveDensifyThreshold -lipulla arvo voidaan laskea ajon aikana nykyisen gradienttijakauman p98:sta — mutta V440 testasi tätä todellisilla näkymillä ja tuotti 63 K Gaussiania (katastrofaalinen karsintahäviö); lippu pysyy pois päältä. Q5 (T77–T79) tarjoaa vaihtoehtoisen adaptiivisen logiikan liukuvan mediaanin kautta. Tämä kenttä ei ole vaaraton — puolittaminen tuottaa 2–4× enemmän Gaussianeja (muistipaine, OOM-riski); tuplaaminen voi ali-tihentää näkymän.
T12densifyFromIteration
TIEDOT
Oletus: 500 Alue: 100 – 5 000 Määritelty:
TEKNINEN
Ensimmäinen iteraatio, josta alkaen Densification on aktiivinen. Sitä ennen tapahtuu vain "paljasta" oppimista alkuperäisellä SfM-pistepilvellä ilman, että uusia Gaussianeja luodaan. Oletus 500 on peräisin 3DGS-artikkelista ja antaa alustukselle aikaa vakautua — jos tihentäminen alkaa jo iteraatiosta 0, väärin sijoitetut SfM-pisteet kloonataan moneen kertaan, ennen kuin ne edes löytävät oikean paikkansa. V349 testasi 1000 → hieman huonompi loss; oletus on optimaalinen.
T13densifyInterval
TIEDOT
Oletus: 100 (alustaja, MCMC), 200 (.full) Alue: 50 – 1 000 Määritelty:
TEKNINEN
Kuinka monta iteraatiota on kahden tihennysaskeleen välillä. Artikkelin oletus on 100 — joka 100. iteraatiolla tihennysehdokkaiden lista arvioidaan, kloonataan/jaetaan ja samalla karsintaehdokkaiden lista (sigmoid(opacity) < T14 pruneOpacityThreshold) poistetaan. V112-testit havaitsivat 200 optimaaliseksi .full:lle — se keventää GPU:n kuormaa, koska vähemmän uudelleenjärjestelyajoja suoritetaan, ja antaa jokaiselle Gaussianille enemmän aikaa asettua kloonaustoiminnon jälkeen. V417 testasi 100 beta2=0.99:llä → 5.8 % huonompi (957 K Gaussiania, ylitihentyminen). MCMC:ssä samaa kenttää tulkitaan uudelleensijoitusvälinä; katso T67 mcmcRelocationInterval MCMC-spesifistä logiikkaa varten.
T14pruneOpacityThreshold
TIEDOT
Oletus: 0.005 (alustaja, artikkeli, MCMC), 0.001 (.full) Alue: 0.0001 – 0.1 Määritelty:
TEKNINEN
Sigmoid-opasiteetin kynnysarvo, jonka alapuolella oleva Gaussian poistetaan seuraavassa tihennysvaiheessa. Toimii yhdessä T7 opacityLearningRate:n ja optimoijan logit-rajoituslogiikan kanssa. V393 laski oletusarvon 0.005:stä 0.001:een .full:ssä — seuraus: splatit, jotka ovat tärkeitä vain eksoottisista katselukulmista, säilyvät pidempään ja edistävät SH-yksityiskohtia. V394 testasi 0.0001 → hieman huonompi (liian vähän karsittu, muistia tuhlattu). Tärkeää: Density-Controlin on AINA karsittava, vaikka puskurin kapasiteetti olisi jo täynnä muiden toimenpiteiden vuoksi (katso "Density Control Must Always Prune" CLAUDE.md:ssä) — muuten kuolleet Gaussianit kerääntyvät ja määrä jäätyy.
T15opacityResetInterval
TIEDOT
Oletus: 3 000 (alustaja + artikkeli), 100 000 (.full = tehokkaasti pois päältä), 200 000 (.fullMCMC = pois päältä) Alue: 1 000 – 100 000+ Määritelty:
TEKNINEN
Kuinka monen iteraation välein kaikkien Gaussianien opasiteetti nollataan matalaan arvoon (~0.01) — toimenpide 3DGS-artikkelista "jäätyneiden" splattien uudelleenarvioimiseksi. V194 osoitti, että RadianceKitin lämmittelyllä + stokastisella koulutusasetuksella + 2× oppimisnopeuksilla opasiteetin nollaus maksaa 5.5 % laatua ja logit-rajoitus kattaa jo nollaustoiminnon. Siksi .full:ssä käytännössä pois päältä (100 000 > 35 000 = ei koskaan laukea). V421 testasi nollausta joka 3 000 iteraatio beta2=0.99:llä → 4.9 % huonompi; peruutettu. .fullClassicPaper:ssä (Q1.5-A, artikkelille uskollinen testi) se on tarkoituksella asetettu takaisin 3 000:een — tämä oli yksi keinoista, joilla artikkelin suuruusluokan Gaussian-budjetit pyrittiin saavuttamaan.
T16maxScreenSize
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 (pois) tai > 0 Määritelty:
TEKNINEN
Maksimikoko näyttöavaruudessa (projisoiduissa pikseleissä), jonka Gaussian saa saavuttaa ennen kuin se pakotetaan jakamaan. Arvo on asetettu 0:aan (V48 testasi ja peruutti) — RadianceKitin Density-Control käyttää sen sijaan maailmanavaruuden skaalakynnysarvoa dMean2D-logiikasta. Pysyy kenttäluettelossa, koska tulevat kokeet Mip-Splattingilla (T74–T76) tai näkymäkohtaisilla splatting-strategioilla voisivat hyötyä siitä. Aktivointi (arvo > 0, esim. 20) pakottaisi erittäin suuriksi kasvaneet splatit näytöllä jakautumaan — relevanttia suurilla, sileillä seinäpinnoilla, joissa yksi jättisplat tarjoaa liian vähän yksityiskohtia.
Loss (T17–T20)
T17ssimWeight
TIEDOT
Oletus: 0.2 (alustaja + artikkeli + .full), 0.05 (kaikki MCMC-esiasetukset) Alue: 0.0 – 1.0 Määritelty:
TEKNINEN
D-SSIM-osuuden paino yhdistetyssä loss-funktiossa loss = (1 - λ) * L1 + λ * D-SSIM, jossa λ = T17. 3DGS-artikkelin oletus 0.2 on optimaalinen Classic-Densificationille — V383 testasi 0.3 → 28.9 % huonompi, V373b vahvisti 0.2:n optimaaliseksi. MCMC:lle todettiin V521b/V534:ssä itsenäisesti: 0.05 on optimaalinen, koska MCMC tarvitsee stokastisen etsintänsä vuoksi vahvemman L1-signaalin osuuden — korkeammat SSIM-painot laimentaisivat uudelleensijoituspäätöksiä. SSIM on huomattavasti kalliimpi laskea kuin L1 (paikalliset 11×11-ikkunat koko kuvan yli); RadianceKit käyttää MPS-kiihdytettyä toteutusta, joka pysyy alle 1 ms:ssa per 1080p-kuva. Q7-BayesOpt-pyyhkäisyt löysivät näkymäkohtaisia optimeja väliltä 0.05 (.outdoorPreset: 0.082) ja 0.171 (.indoorPreset).
T18ssimWeightRefinement
TIEDOT
Oletus: 0.0 (= "ei muutosta, säilytä ssimWeight") Alue: 0 tai 0 – 1.0 Määritelty:
TEKNINEN
Valinnainen SSIM-arvo hienosäätövaiheelle T2 densifyUntilIteration:n jälkeen. V428 testasi 0.2 → 0.3 hienosäädössä → 16 % huonompi loss (sekä L1 että SSIM heikkenivät); peruutettu, joten oletus 0.0. Kentän taustalla oleva hypoteesi oli, että tihentämisen jälkeen — kun uusia Gaussianeja ei enää synny — vahvempi SSIM-osuus maksimoisi rakenteellisen terävyyden. Empiirisesti väärin: SSIM-painon nostaminen tarkoittaa epäsuorasti L1-painon laskemista, ja L1 on huomattavasti merkityksellisempi signaali lopullisessa hienosäätövaiheessa. Kenttä pysyy saatavilla tulevia kokeita varten, joissa käytetään havainnollista lossia (T60) tai reuna-lossia (T19), joissa hienosäätökohtainen loss-koostumus voisi olla järkevä.
T19edgeLossWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.001 – 1.0 Määritelty:
TEKNINEN
V437-kokeellinen loss: Sobel-gradienttidomeenin L1-lossin paino, joka vertaa kuvan reunoja suoraan (Ground-Truth-Sobel vs Render-Sobel) L1+SSIM:n lisäksi. Hypoteesi: reunainformaatio on kuvanlaadun havainnollinen kulmakivi ja eksplisiittinen termi kannustaisi Gaussianeja osumaan reunoihin paremmin. Testitulokset: paino 0.1 → 11 % huonompi loss, 0.01 → laadullisesti neutraali mutta 10 % hitaampi. Sobel-ajo maksaa ylimääräisen MPS-forwardin Ground-Truthille ja renderöinnille. Siksi pysyvästi pois päältä. Tuleva käyttötapaus: näkymät, joissa on kovia keinotekoisia reunoja (arkkitehtuuri, huonekalut, renderöinnit) voisivat hyötyä — Q7-Scene-Class-esiasetukset eivät kuitenkaan valinneet tätä, vaan skaalasivat sen sijaan SSIM-painoa.
T20skyMaskingEnabled
TIEDOT
Oletus: false (alustaja ja kaikki esiasetukset) Alue: boolean Määritelty:
TEKNINEN
Kytkee Sky Maskingin päälle. Tällöin jokaisessa kuvassa Apple Vision Frameworkin (VNGenerateForegroundInstanceMaskRequest) avulla taivasalue maskataan pois, ja loss tällä alueella asetetaan nollaan. Tarkoitus: ulkokohtaukset kärsivät usein siitä, että siniset/harmaat/valkoiset taivaspikselit saavat sovelluksen sijoittamaan Gaussianeja juuri sinne — mikä havaitaan "leijuvina partikkeleina". Ilman Sky-Maskia loss tällä alueella ei olisi koskaan nolla, koska taivas kuvassa vaihtelee hieman ja sovellus yrittää ikuisesti mallintaa sitä splatilla. Vision-maski lasketaan kerran per kamera ennen koulutusta ja pidetään RAM-muistissa. Aktivoidaan tyypillisesti yhdessä T45 skyDomeEnabled:n kanssa (käyttöliittymälogiikka Asetukset-näkymässä). Sisätiloissa tai synteettisissä renderöinneissä jätettävä pois päältä — maski tunnistaisi siellä virheellisesti kattoja tai seiniä "taivaaksi".
SH-asteen progressio (T21)
T21shDegreeUpgradeIterations
TIEDOT
Oletus: [1_000, 2_000, 3_000] (alustaja), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — aste 3 ohitettu) Alue: [Int], jokainen arvo [0, maxIterations], monotonisesti nouseva Määritelty:
TEKNINEN
Iteraatiot, joissa aktiivinen SH-aste nostetaan 0→1, 1→2, 2→3. Ennen ensimmäistä merkkiä vain DC-komponentit ovat aktiivisia (eli T5 shDCLearningRate), ensimmäisen merkin jälkeen DC + 3 asteen 1 kerrointa, toisen merkin jälkeen + 5 asteen 2 kerrointa, kolmannen merkin jälkeen kaikki 15 kerrointa. Muistinkulutus per Gaussian kasvaa tällöin portaittain — 4 floatia → 16 floatia → 36 floatia → 64 floatia. Quality-esiasetukset viivästyttävät päivityksiä verrattuna alustajan oletuksiin (V228), koska geometrian on ensin vakauduttava, ennen kuin väriyksityiskohdat korkeammilla taajuuksillaan lisätään. V384 testasi [1K, 2K, 3K] .full:lle → 9.3 % huonompi — vahvistaa viiveen. .preview katkaisee asteen 2 kohdalla, koska aste 3 ei konvergoidu 5 000 iteraatiossa ja kuluttaa vain optimoijan kapasiteettia. Q6 (T80–T81) tarjoaa vaihtoehtoisen curriculum-logiikan, joka ylikirjoittaa tämän listan dynaamisesti.
Suorituskyky (T22–T25)
T22trainingRenderScale
TIEDOT
Oletus: 1.0 (alustaja, .full, MCMC, Scene-Class), 0.5 (.preview), 0.25 (.quickTest) Alue: 0.05 – 2.0 (tyypillisesti 0.25, 0.5, 1.0) Määritelty:
TEKNINEN
Renderöintiresoluutio koulutuksen aikana suhteessa koulutuskuvien alkuperäiseen resoluutioon. Arvolla 0.5 jokainen kuva pienennetään 50 % leveyteen × 50 % korkeuteen (eli 25 % pikseleistä) ja Gaussian-renderöinti tapahtuu tässä pienemmässä resoluutiossa. Vähentää sekä muistin- että laskentatarvetta neliöllisesti. Tärkeää: T11 densifyGradThreshold:n on vastattava valittua resoluutiota — gradienttisuuruudet skaalautuvat 1/resoluutio²:lla, joten .quickTest:llä (0.25×) on paljon korkeampi kynnysarvo (4e-6) kuin .full:llä (1.0×, 1.1e-6). RadianceKit varoittaa erittäin suurista kuvista ja säätää automaattisesti — 3 MP:n tavoiteresoluutio. Erittäin suurilla 4K-syötekuvilla 0.5 tai jopa 0.25 olisi järkevää, muuten mikä tahansa Mac joutuu CPU-tiivistykseen.
T23resolutionWarmupScale
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.1 – Määritelty:
TEKNINEN
V133-optimointi: Kouluta tihennysvaihe (iteraatiot 0 - T2) matalammalla resoluutiolla kuin hienosäätövaihe. V308 kytki sen pois päältä .full:lle, koska T22 = 1.0:lla ja kosinin vaimennuksella aikavoitto oli marginaalinen ja laatu kärsi minimaalisesti. Pysyy kenttäluettelossa, koska se voisi tulla jälleen hyödylliseksi 4K-syötteillä ja pitkillä koulutusajoilla — Q6 Curriculum (T80) on omaksunut samanlaisen logiikan, mutta siellä se on kytketty oppimisnopeuden aikatauluun. Jos tämä on aktivoitu ja T80 curriculumResolutionRamp on myös tosi, Q6 voittaa ja ylikirjoittaa tämän arvon.
T24tileSize
TIEDOT
Oletus: 16 Alue: 8, 16, 32 Määritelty:
TEKNINEN
Rasterointilaattojen koko pikseleinä. Gaussian-splatting-renderöinti on laattapohjaista: kuva jaetaan 16×16-pikselin laattoihin, jokainen laatta kerää sille relevantit Gaussianit, lajittelee ne syvyyden mukaan ja sekoittaa ne. 16 on käytännössä kaikkien 3DGS-toteutusten käyttämä standardi ja kovakoodattu RadianceKitin Metal-kerneleihin; tämän arvon muuttaminen vaatisi shaderien uudelleenkääntämistä eikä ole nykytilassa tehokasta. Pysyy kenttänä, jos tuleva moottoriversio tukee laatan kokoa dynaamisesti.
T25throttleDelayMs
TIEDOT
Oletus: 0 (alustaja, .full, MCMC, Scene-Class), 0 (.preview) Alue: 0 – 100 Määritelty:
TEKNINEN
Keinotekoinen viive koulutusiteraatioiden välillä millisekunneissa. 0 = täysi nopeus (vakio). Korkeammat arvot tekevät Macista "käytettävämmän" koulutuksen aikana antamalla GPU:lle/CPU:lle säännöllisiä hengähdystaukoja — muiden sovellusten käytettävyys paranee, mutta koulutusaika kasvaa lineaarisesti viiveen myötä. Tyypilliset arvot: 1–2 ms ("kevyt" kuristus, +5 % koulutusaika, Mac tuntuu responsiivisemmalta), 5 ms ("keskivaikea", +15 % koulutusaika), 10+ ms ("eko", mahdollisesti kaksinkertainen koulutusaika). Tarjotaan Tarkastajassa "Suorituskyky"-kohdassa, mutta ei ole vakionäkymässä — katso backlog dev_ux-backlog.md, joka ehdottaa sen poistamista asiantuntijanäkymästä, koska väärin ymmärrettynä se pidentää koulutusaikaa dramaattisesti.
Diagnoosi ja pistepilven valmistelu (T26–T30)
T26depthDistortionWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.0001 – 0.05 Määritelty:
TEKNINEN
V366-kokeellinen: syvyysvääristymän regularisointi-lossin paino. Rankaisee Gaussianeja, jotka ovat renderöintisädettä pitkin syvällä porrastettuja, mutta kuuluvat käsitteellisesti samaan pintaan — tämä kannustaa keskittyneisiin syvyysjakaumiin ja vähentää leijuvia partikkeleita. Testit: 0.01 → 4.5 % huonompi, 0.001 → 8.1 % huonompi. Teoreettinen etu — moninäkymäkonsistenssin parantaminen — ei näy L1-lossissa, koska hypoteesi olettaa implisiittisesti, että SfM-geometria on oikea ja Gaussianit on vain "pinottava". Käytännössä SfM-pistepilvi on usein heikoin komponentti, ei pinoaminen. Pysyy saatavilla moninäkymä-aineistoille, joissa on erityisen puhtaat asennot (synteettinen, Mip-NeRF 360 Ground Truthilla).
T27singleViewOverfit
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
Diagnoosilippu: jos tosi, jokaisessa koulutusiteraatiossa käytetään pakotetusti kameraindeksiä 0 satunnaisen kameran sijaan. Tarkoitus: Jos malli ei pysty edes ylisovittamaan yhtä näkymää (eli loss näkymässä 0 ei lähene nollaa edes 10 000 iteraation jälkeen), forward/backward-passissa on perustavanlaatuinen bugi. Tätä kytkintä käytettiin intensiivisesti Metal-shaderien ja differentioituvan rasteroijan kernelien kehityksen aikana — V42–V47 -vaihe. Nykyään saatavilla vain terveen järjen tarkistuksena, jos joku on muokannut taustaohjelman koodia ja haluaa tehdä regressiotestin. CLI:llä –single-view.
T28maxCameras
TIEDOT
Oletus: 0 (= "käytä kaikkia kameroita") Alue: 0 tai 1 – N Määritelty:
TEKNINEN
Diagnoosiraja V43:sta: kouluta vain ensimmäisillä N kameralla, jätä kaikki muut huomiotta. Alkuperäinen tarkoitus: testata hypoteesia, että liian monet kamerat aiheuttavat gradienttikonflikteja (liian monta ristiriitaista loss-signaalia samalle Gaussianille). Testitulos: ei systemaattista etua keinotekoisella rajoituksella — useammat kuvat tuovat käytännössä aina enemmän laatua. Pysyy CLI-lippuna (–max-cameras N) kohdennettuja kokeita varten, esim. "toimiiko koulutus 1 500 kuvan droonilennon ensimmäisillä 100 kuvalla?". Ei näkyvissä käyttöliittymässä.
T29maxInitialPoints
TIEDOT
Oletus: 0 (= "käytä kaikkia SfM-pisteitä") Alue: 0 tai 1 000 – 200 000+ Määritelty:
TEKNINEN
V54-varmistus: rajoittaa alkuperäisten SfM-pisteiden määrää, joilla koulutus alkaa. Tiheät COLMAP-rekonstruktiot voivat tuottaa > 60 000 pistettä, mikä suurilla alkuskaaloilla johtaa 200–300 Gaussianin päällekkäisyyteen pikseliä kohden — tämä luo "sumukentän", jossa koulutus ei konvergoidu. Alinäytteistys ~16 000 pisteeseen (kova rajoituslogiikka koulutusmoottorissa) tuo alkutiheyden tasolle, jota referenssi-3DGS käyttää, ja vähentää päällekkäisyyttä dramaattisesti. Asetetaan automaattisesti erittäin tiheillä SfM:illä; CLI:llä –max-points N.
T30cameraClusterOutlierMultiplier
TIEDOT
Oletus: 10.0 (kaikki esiasetukset — ei koskaan ylikirjoitettu) Alue: 1.0 – 100.0 Määritelty:
TEKNINEN
Kameraklusterin poikkeamien suodattimen kerroin, otettu käyttöön vaiheessa 3.10 A.1. Ennen koulutusta koulutusmoottori laskee kaikkien kameran sijaintien keskipisteen ja kameran maksimietäisyyden keskipisteestä. SfM-pisteet, joiden etäisyys keskipisteestä ylittää multiplier × maxCameraDistance, hylätään poikkeamina. Oletus 10× säilyttää käyttäytymisen ennen vaihetta 3.10. Hienovarainen bugi: tiiviimpi SfM (kamerat lähempänä toisiaan) → pienempi → pienempi kynnysarvo → enemmän pisteitä hylätään poikkeamina. Väljempä SfM → suurempi kynnysarvo → vähemmän pisteitä hylätään. Tämä on yksi syy vaiheen 3.9 suppilo- vs. koulutus-antikorrelaatioon: parempi SfM voi johtaa huonompaan koulutukseen, koska liian monta alkupistettä tapetaan. Kenttä on CLI-ylikirjoituksena (–camera-cluster-outlier-multiplier) A.3-pyyhkäisyjä varten; ei näkyvissä käyttöliittymässä. Arvot alle 5 ovat yleensä liian rajoittavia, yli 20 tehottomia.
Regularisointi (T31–T37)
T31coarseToFineBlurRadius
TIEDOT
Oletus: 0 (= pois päältä) Alue: 0 tai 1 – 10 Määritelty:
TEKNINEN
V369-kokeellinen: Box-blur-säde, jota sovelletaan Ground-Truth-kuvaan tihennysvaiheen alussa ja joka pienennetään lineaarisesti nollaan tihennyksen loppuun (T2) mennessä. Hypoteesi: karkeasta hienoon -koulutus — ensin karkeiden rakenteiden oppiminen, sitten yksityiskohtien — pitäisi tuottaa vakaampaa geometriaa. Testit: r=3 → 9.6 % huonompi, r=1 → 5.1 % huonompi. Epäonnistumisen syy: tihentäminen päättää kuvadomeenin gradienttien perusteella, ja sumennus vähentää juuri niitä signaaleja, jotka ovat tärkeitä "tässä on kloonattava" -päätökselle. Pysyy kenttäluettelossa tulevia testejä varten toisella tihennysmallilla.
T32scaleRegWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.0001 – 0.05 Määritelty:
TEKNINEN
V370-kokeellinen: L1-regularisointi maailmanavaruuden skaalalle. Rankaisee liian suuriksi kasvavia Gaussianeja — estää "megasplatit", jotka peittävät kokonaisia seinäpintoja yhdellä Gaussianilla. Testit: 0.01 → 200 % huonompi loss (2 M Gaussiania, täydellinen räjähdys), 0.001 → 214 % huonompi. Syy: skaalaregularisointi on ristiriidassa Density-Controlin kanssa — pienemmät skaalat tarkoittavat, että tarvitaan enemmän Gaussianeja, joten Density-Control jakaa useammin, mikä puolestaan vaatii enemmän gradienttityötä. Pois päältä, mutta dokumentoitu Mip-Splatting-kokeita (T74) varten: tässä yhteydessä skaalan alaraja voisi olla järkevä.
T33anisotropyRegWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.0001 – 0.05 Määritelty:
TEKNINEN
V445-kokeellinen: rangaistus max(scale)/min(scale)-suhteelle, tarkoituksena estää erittäin pitkänomaisia "neula"-Gaussaneja, jotka havaitaan leijuvina partikkeleina. Testit: 0.01 → 69 % huonompi, 0.001 → 15 % huonompi. Syy: regularisointi pakottaa splatit kohti "pyöreää" muotoa, mikä on tasaisella pinnalla (seinä, pöytä, lattia) täysin väärin — siellä litteä, leveä Gaussian on tehokkaampi kuin pallomainen. Pois päältä. V549f tarjosi T34 scaleRatioPruneThreshold:lla vaihtoehtoisen, kohdennetumman lähestymistavan, joka myös peruutettiin.
T34scaleRatioPruneThreshold
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 5.0 – 100.0 (tyypillisesti 10.0 – 30.0) Määritelty:
TEKNINEN
Kokeellinen koulutuksen jälkeinen karsinta, joka poistaa jokaisen Gaussianin, jonka max(scale)/min(scale)-suhde ylittää tässä asetetun lineaarisen kynnysarvon. Kohdistuu erittäin pitkänomaisiin "neula/levy"-leijuviin partikkeleihin, joita ei voida poistaa pelkällä regularisoinnilla. Testissä karsinta poisti leijuvat partikkelit odotetusti, mutta samalla myös hyödyllisiä litteitä splatteja seinillä ja lattioilla — kuvasta tuli reikäisempi. Siksi oletuksena pois päältä, CLI-lippu (–scale-ratio-prune N) pysyy saatavilla kohdennettuja kokeita varten. Suositellut arvot, jos haluat silti testata: 30 (erittäin konservatiivinen, poistaa vain äärimmäiset poikkeamat), 10 (aggressiivinen, maksaa yksityiskohtia).
T35opacityRegWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.0001 – 0.05 Määritelty:
TEKNINEN
V446-kokeellinen: binäärinen ristiin-entropia-rangaistus, joka vetää opasiteettia kohti 0:aa tai 1:tä (eli pois "puoliläpinäkyvästä"). Hypoteesi: terävämpi opasiteettijakauma parantaisi kuvan selkeyttä. Testattu yhdessä T33:n kanssa → regularisointi maksaa laatua, molemmat pois päältä. Pois päältä. Huomio: 1.4.3-beta-versiossa ilmeni bugi, jossa juuri tämä kenttä oli oletusarvon muutoksessa (alustaja = 0.01), mikä johti Gaussian-määrän massasukupuuttoon (460 K → 5 yhdessä iteraatiossa). Versiosta 1.4.4 lähtien kiinnitetty oletuksena 0.0:aan.
T36opacityDecayFactor
TIEDOT
Oletus: 0.0 (alustaja = pois päältä), 0.9995 (.full, .classicBalanced — HTGS-standardi) Alue: 0 (pois) tai 0.95 – 1.0 Määritelty:
TEKNINEN
V546-toteutus HTGS-mallista (Hierarchical Time-Gating, Eurographics 2025): joka T37 opacityDecayInterval iteraation välein kunkin Gaussianin sigmoid-opasiteetti kerrotaan tällä tekijällä. 0.9995 × 100 sovellusta antaa ~95 %:n jäännöksen per tihennysvaihe — kevyt mutta jatkuva alaspäin suuntautuva paine kaikille opasiteeteille, joka saa heikosti vaikuttavat Gaussianit luotettavasti laskemaan kohti T14 pruneOpacityThreshold:ia. Tulos: 14 % parempi L1-loss Horse Full -aineistolla (3 kokeen keskiarvo V546) verrattuna V438:aan ilman vaimennusta. Aktiivinen vain tihennysvaiheen aikana (T2:een asti), sen jälkeen koulutus jatkuu ilman vaimennusta, jotta hienosäädössä vakiintuneet opasiteetit pysyvät vakaina. Ei käytetä MCMC:ssä (MCMC:llä on omat mekanisminsa T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold kautta).
T37opacityDecayInterval
TIEDOT
Oletus: 50 Alue: 10 – 500 Määritelty:
TEKNINEN
Iteraatioväli, jolla T36 opacityDecayFactor sovelletaan. HTGS-artikkelin oletus 50, jätetty .full:iin. Pitkät välit (>200) kumoavat osittain vaikutuksen, koska kahden sovelluksen välillä tapahtuu tarpeeksi gradienttipäivityksiä, jotta opasiteetti nousee uudelleen. Lyhyemmät välit (<20) tekevät vaimennuksesta liian aggressiivisen. Aktiivinen vain tihennysvaiheessa.
Hienosäätö (T38–T44)
T38gradientAccumulationSteps
TIEDOT
Oletus: 1 (= "yksi näkymä per Adam-askel") Alue: 1 – 8 Määritelty:
TEKNINEN
V424-ominaisuus: näkymien määrä, joiden gradientit kerätään ennen Adam-päivityksen suorittamista. Jos > 1, sovellus käyttää erillistä, "yhdistämätöntä" backward-project-polkua, joka summaa gradientit erilliseen puskuriin; lopullinen sovellus skaalataan 1/N:llä suuruuden pitämiseksi vakiona. V424 testasi 2-näkymää → laadullisesti neutraali, mutta 10 % hitaampi (koska yhdistämätön polku on kalliimpi kuin yhdistetty polku). Peruutettu .full:lle, mutta käytetään tarkoituksella MCMC:ssä — .fullMCMC toimii, mutta V544a-testit osoittivat, että laatuero Classiciin kutistuu 5 %:iin (11 %:n sijaan). Alustajan oletus 1, nykyisessä esiasetuksessa 1, pysyy CLI-lippuna (–accum-steps N).
T39testViewIndices
TIEDOT
Oletus: [] (= tyhjä, kaikki näkymät käytetään koulutukseen) Alue: Set<Int>, mikä tahansa kameraindeksien osajoukko Määritelty:
TEKNINEN
V546-ominaisuus: kameraindeksien joukko, joita EI käytetä koulutukseen, vaan säästetään PSNR/SSIM/LPIPS-arviointia varten. Asetetaan automaattisesti, kun –benchmark-CLI-lippu on aktiivinen: tällöin joka kahdeksas näkymä, alkaen indeksistä 0 (LLFF-standardi, identtinen Mip-NeRF-360- ja 3DGS-artikkelin käytäntöjen kanssa). Ilman benchmarkia tyhjä — koulutus käyttää kaikkia näkymiä. Varoitus: tämän kentän manuaalinen asettaminen ilman indeksien ymmärtämistä voi tehdä benchmarkista käyttökelvottoman (esim. jos kaikki indeksit asetetaan > N, vaikka näkymiä on vain N-50 → ei testijoukkoa → ei arviointia). Omaa esiasetusta vietäessä testViewIndices ei tallennu, koska se on näkymäriippuvainen ja jättäisi muuten merkityksettömiä arvoja eri aineistojen välille.
T40refinementPruneInterval
TIEDOT
Oletus: 0 (= pois päältä) Alue: 0 tai 100 – 5 000 Määritelty:
TEKNINEN
V425-ominaisuus: joka N. iteraatiolla hienosäätövaiheen aikana ( T2:n jälkeen) suoritetaan ylimääräinen karsinta-ajo, joka poistaa Gaussianit, joiden sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Tarkoitus: tihennyksen aikana on säännöllisiä Density-Control-kutsuja, sen jälkeen ei enää — Gaussianit, joiden opasiteetti jatkaa laskuaan, jäävät kuitenkin puskuriin. V425 testasi ja peruutti: ylimääräinen karsinta korreloi V426:n kanssa (kaksivaiheinen tihennys, joka myös päättyi 0 Gaussianin kaskadivirheeseen). Pois päältä. CLI-lippu saatavilla kokeita varten; jos aktivoitu, 1 000 tai 2 000 ovat järkeviä arvoja.
T41refinementPruneOpacityThreshold
TIEDOT
Oletus: 0.0 (= "käytä T14") Alue: 0 tai 0.001 – 0.1 Määritelty:
TEKNINEN
V425b: erillinen opasiteettikynnysarvo hienosäädön karsinnalle. Tihennyksen jälkeen useimmilla Gaussianeilla on huomattavasti korkeampi opasiteetti (> 0.001), joten standardi-T14 pruneOpacityThreshold olisi liian löysä. Jos T40 on aktiivinen, tämä kenttä määrittää oman kynnysarvonsa. Arvolla 0.0 käytetään edelleen T14:ää. Relevantti vain, jos T40 > 0.
T42midTrainingCompactificationIterations
TIEDOT
Oletus: [] (= pois päältä) Alue: [Int], arvot (densifyUntilIteration, maxIterations) Määritelty:
TEKNINEN
V549-ominaisuus: eksplisiittiset iteraatiopisteet hienosäätövaiheen aikana, joissa suoritetaan tiivistysajo (poistaa sigmoid(opacity) < 0.01 + poikkeavat skaala-Gaussianit, sama logiikka kuin T56 postTrainingCompactification). Tarkoitus: pitkät hienosäätövaiheet voivat aiheuttaa konfetti-/leijuvien partikkelien kertymistä, joiden SH sitten ylisovittuu näkymäkohtaisiin artefakteihin. Tyypillinen konfiguraatio, jos aktivoitu: [10000, 20000, 30000] 40K Classicille. MUTTA: V549-A/B-testit Family-aineistolla osoittivat kaikissa konfiguraatioissa huonompaa L1:tä: [10K,20K,30K]\@0.01 → −48 % määrä mutta +36 % L1; [20K,30K]\@0.005 → −44 % määrä mutta +45 % L1; [20K,30K]\@0.001 → −17 % määrä mutta +87 % L1. Siksi pois päältä. CLI-lippu –mid-compact "10000,20000" saatavilla, jos visuaalinen leijuvien partikkelien kompromissi (vähemmän konfettia näkymässä) on tärkeämpi kuin loss-regressio.
T43frustumCullEnabled
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
V549b-ominaisuus: koulutuksen jälkeen poistetaan kaikki Gaussianit, jotka ovat kaikkien koulutuskameroiden näkymäkartioiden yhdistelmän ulkopuolella. Tällaisia Gaussianeja ei ole koskaan rajoitettu loss-signaalilla ja ne ovat aina leijuvia partikkeleita. Erityisen tehokas näkymissä, joissa uusi näkymä on kamerapolun takana tai vieressä (esim. lineaarisen droonilennon takapuoli) — leijuvat partikkelit siellä eivät ole koskaan näkyvissä koulutusvaiheessa, mutta myöhemmin 3D-katselimessa liikuttaessa kyllä. V549b A/B droonilennoilla positiivisia tuloksia, siksi saatavilla opt-in-ominaisuutena. Oletuksena false, koska esinekuvauksissa, joissa on täysi kiertoratapeitto, näkymäkartioiden yhdistelmä kattaa koko näkymän eikä ominaisuus poista mitään — tarjotaan Asetuksissa "Floater Reduction" -kohdassa ja testattu myös Q9 Outdoor-esiasetuksessa implisiittisesti T44 frustumCullExpansion:n kautta (Q7-BayesOpt ei kuitenkaan aktivoinut sitä, koska Outdoor-Sky-Dome ratkaisee saman ongelman paremmin).
T44frustumCullExpansion
TIEDOT
Oletus: 1.1 Alue: 1.0 – 2.0 Määritelty:
TEKNINEN
NDC-marginaali T43 frustumCullEnabled:lle. 1.0 leikkaisi tasan kuvan reunasta, mikä karsisi heiluvia splatteja kuvan reunalla liikaa. 1.1 = 10 % pehmuste tarkan kamerakehyksen yli — antaa hieman toleranssia reunapikseleille, jotka saattavat tulla näkyviin hieman siirtyneessä uudessa näkymässä. Arvot > 1.2 tekevät karsinnasta käytännössä tehottoman, koska laajennettu näkymäkartio kattaa paljon enemmän tilaa.
Sky-Dome (T45–T48)
T45skyDomeEnabled
TIEDOT
Oletus: false (alustaja + kaikki esiasetukset paitsi P9 Outdoor) Alue: boolean Määritelty:
TEKNINEN
V549e-ominaisuus: ennen koulutuksen alkua luodaan pallomainen pistepilvi (Fibonacci-pallo T46 näytepisteellä), sijoitetaan säteelle T47 skyDomeRadiusMultiplier × scene_extent näkymän keskipisteen ympärille ja alustetaan kaikkien koulutuskameroiden taivasmaskattujen pikselien väreillä (katso T20 skyMaskingEnabled). Nämä Sky-Dome-Gaussianit lisätään Gaussian-puskurin alkuun ja "jäädytetään" koulutuksen aikana (sijainti/skaala/rotaatio-gradientit = 0, vain SH ja opasiteetti pysyvät optimoitavissa). Vaikutus: mustien "konfetti"-alueiden sijaan kaukana käyttäjä näkee uusissa näkymissä todellisen taivaan. V549e-MVP toimii drooni- ja maisemanäkymissä erittäin hyvin; P9 Outdoor-esiasetuksessa oletuksena päällä. Sisätiloissa jätä pois päältä — pallo roikkuisi turhaan huoneen ulkopuolella.
T46skyDomeSampleCount
TIEDOT
Oletus: 5 000 Alue: 1 000 – 50 000 (tyypillisesti 2 000 – 10 000) Määritelty:
TEKNINEN
Fibonacci-pallon näytepisteiden määrä Sky-Dome-pallolla. Korkeammat arvot → tiheämpi Sky-Dome (parempi suurilla resoluutioilla ja paljon näkyvällä taivaalla), mutta enemmän muistintarvetta. 5 000 on optimaalinen 4K-renderöinneille; matalammilla resoluutioilla 2 000–3 000 riittää. Pisteet alustetaan kosinusetäisyyden mukaan jokaiseen koulutuskameran näkymävektoriin vastaavilla taivasmaskatuilla pikseleillä — näytepisteet, joiden näkymäkartio ei näe kameraa, jäävät taakse matalalla opasiteettialustusarvolla, mutta niitä ei muuteta koulutuksen aikana (jäädytetty).
T47skyDomeRadiusMultiplier
TIEDOT
Oletus: 30.0 (alustaja + useimmat esiasetukset), 59.0 (P9 Outdoor, Q7-BayesOpt-optimi) Alue: 5.0 – 200.0 Määritelty:
TEKNINEN
Sky-Dome-pallon säde suhteessa näkymän laajuuteen (= keskimääräinen etäisyys kameran sijaintien välillä). 30 = pallon halkaisija on 30-kertainen kamerapilveen verrattuna. Liian pieni (< 5) → Sky-Dome häiritsee itse näkymää (esim. Sky-Dome-splat päätyy etualalle); liian suuri (> 100) → float32-tarkkuuden menetys Sky-Dome-sijainneissa, mikä aiheuttaa renderöintivirheitä kaukana. Q7-BayesOpt Bicycle-aineistolla (Mip-NeRF 360) löysi 59.0:n näkymäkohtaiseksi optimiksi ulkotiloihin — tämä viittaa siihen, että standardi 30.0 on liian pieni syville maisemille ja Sky-Dome-pikselit renderöityvät näkyvästi "seinänä" kuvan reuna-alueilla.
T48frozenGaussianCount
TIEDOT
Oletus: 0 (= ei jäädytettyjä Gaussianeja) Alue: 0 tai 1 – T46 Määritelty:
TEKNINEN
Gaussianien määrä puskurin alussa, joiden sijainti/skaala/rotaatio-gradientit asetetaan nollaan optimoijassa — ne pysyvät koko koulutuksen ajan avaruudellisesti jäykkinä. Density-Control ei saa kloonata, jakaa tai karsia niitä. Käytetään Sky-Dome-injektiota varten (katso T45): kun Sky-Dome on päällä, tämä kenttä asetetaan automaattisesti arvoon T46 skyDomeSampleCount. Manuaalinen asettaminen on mahdollista (esim. ennalta sijoitetun pistepilven jäädyttämiseksi LiDAR-skannauksesta), mutta ei suoraan käytettävissä käyttöliittymässä. Tärkeää: ensimmäiset N Gaussiania puskurissa ovat aina jäädytettyjä — järjestys puskurissa ratkaisee, ei eksplisiittinen indeksi.
Adam + LR-aikataulu (T49–T55)
T49adamResetIteration
TIEDOT
Oletus: 0 (= pois päältä) Alue: 0 tai 100 – Määritelty:
TEKNINEN
V430-ominaisuus: iteraatio, jossa Adam-optimoijan momentum-akut (m1, m2) nollataan. Bias-korjaus sen jälkeen käyttää (iter - adamResetIteration) iter:n sijaan. V430 testasi nollausta 5 000:ssa (tihennyksen päätyttyä) → 12.8 % huonompi loss. Syy: Adam-momentum, joka on kertynyt tihennyksen aikana, sisältää tietoa tyypillisistä gradienttisuuruuksista ja nopeuttaa hienosäätövaihetta. Sen pois heittäminen maksaa ensimmäiset ~500 hienosäätöiteraatiota konvergenssissa. Pois päältä. Pysyy CLI-lippuna tutkimuskokeita varten.
T50positionLRScheduleEndIteration
TIEDOT
Oletus: 0 (alustaja = "käytä maxIterations"), 20 000 (.full — kosini päättyy 20K:ssa vaikka maxIter=35K), 30 000 (.fullClassicPaper) Alue: 0 tai 1 000 – Määritelty:
TEKNINEN
V431-ominaisuus: iteraatio, jossa kosinin vaimennuskäyrä sijainnin oppimisnopeudelle saavuttaa miniminsä. Jos 0, se on identtinen T1 maxIterations:n kanssa. Jos > 0, aikataulu jatkuu tähän arvoon asti ja pysyy sen jälkeen vakiona arvossa T4 positionLearningRateFinal. Tämä mahdollistaa "laajennetun hienosäätövaiheen" minimaalisella mutta vakiona pysyvällä oppimisnopeudella — hienosäätää sijainteja hitaasti ilman uutta vaimennusta. .full tekee tämän (aikataulun loppu 20K:ssa, koulutus jatkuu 35K:hon), V434c/V434d vahvistivat: 15K ja 25K molemmat suunnilleen samanlaisia, 20K minimaalisesti optimaalinen. Käytetään yhdessä T51:n kanssa muokkaamaan myös ei-sijainti-oppimisnopeuksia laajennetussa vaiheessa.
T51extendedPhaseLRDecay
TIEDOT
Oletus: 0.0 (= pois päältä, vakiot oppimisnopeudet) Alue: 0 tai 0.01 – 1.0 Määritelty:
TEKNINEN
V433-ominaisuus: minimaalinen kerroin ei-sijainti-oppimisnopeuksille (skaala, rotaatio, opasiteetti, SH) "laajennetussa vaiheessa" — eli sen jälkeen, kun T50 on saavutettu ja sijainnin oppimisnopeus on jo T4:ssä. Jos 0.1, skaala/rotaatio/opasiteetti/SH vaimennetaan kosinilla 1.0:sta (= niiden standardi-oppimisnopeus) 0.1× niiden standardiin. Jos 0.0 (oletus), ne pysyvät vakioina. V457 testasi täyttä vaimennusta (0.0 = vaimennus nollaan) vastaan ei-vaimennusta ja havaitsi: keskimäärin 0.0400 (2 ajoa) = sama loss kuin V438:lla ilman vaimennusta. Käyttäytyminen siistimpää vaimennuksella, mutta ei mitattavasti parempi. Siksi pois päältä. Pysyy CLI:ssä –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
V440-kokeellinen: jos tosi, sovellus laskee jokaisessa tihennysvaiheessa nykyisen gradienttijakauman p98:n ja käyttää sitä dynaamisena kynnysarvona (rajoitettu vähintään 0.5× konfiguroituun arvoon T11:stä, jotta se ei poikkea liikaa). Hypoteesi: automaattinen sopeutuminen nykyiseen näkymävaiheeseen tekisi Density-Controlista robustimman — esim. alussa tiukempi karsinta, myöhemmin löysempi, tai päinvastoin. V440 testasi ja peruutti: katastrofaalinen pudotus 63 K Gaussianiin (massakarsinta, koska p98 on ensimmäisissä iteraatioissa erittäin korkea ja sitten melkein mikään ei ylitä kynnysarvoa). Kiinteä kynnysarvo on jo hyvin kalibroitu, dynaaminen säätö vahingoittaa enemmän kuin hyödyttää. Q5 (T77) tarjoaa vaihtoehtoisen adaptiivisen logiikan liukuvan mediaanin kautta, joka kiertää ongelman.
T53mergeAfterDensification
TIEDOT
Oletus: false (alustaja), true (.full, .classicBalanced, .fullClassicPaper) Alue: boolean Määritelty:
TEKNINEN
V438-ominaisuus: tihennysvaiheen lopussa (iteraatio T2) suoritetaan kertaluonteinen yhdistämisajo, joka yhdistää lähellä toisiaan olevat Gaussianit, joilla on samanlainen skaala ja väri. Vähentää Gaussianien määrää tyypillisesti 5–15 % ilman näkyvää laadunmenetystä. Tarkoitus: intensiivisen kloonauksen jälkeen syntyy klustereita lähes identtisistä Gaussianeista, jotka eivät tuo mitään uutta — yhdistäminen vapauttaa optimoijan kapasiteettia muille alueille. Standardi Classic-Quality-esiasetuksissa. Ei käytetä MCMC:ssä, koska MCMC ei uudelleensijoituslogiikallaan edes anna tällaisia klustereita syntyä.
T54densifyPhase2FromIteration
TIEDOT
Oletus: 0 (= pois päältä) Alue: 0 tai T2 – T1 Määritelty:
TEKNINEN
V426-kokeellinen: mahdollistaa toisen tihennysvaiheen, joka alkaa hienosäätötauon jälkeen tässä iteraatiossa ja jatkuu T55:een asti. Hypoteesi: hienosäätövaiheen jälkeen gradienttiakuilla on vakaammat suuruudet ja ne voivat tarkemmin sanoa, mitkä alueet tarvitsevat vielä lisää Gaussianeja. V426 testasi ja peruutti: kaksivaiheinen tihennys päätyi 0-Gaussianin kaskadivirheeseen (yhdistettynä V425:n hienosäätökarsintaan se tuhosi puskurin). Pois päältä. CLI-lippu saatavilla kokeita varten.
T55densifyPhase2UntilIteration
TIEDOT
Oletus: 0 Alue: 0 tai T54 – T1 Määritelty :
TEKNINEN
V426:n kaksivaiheisen tihennyksen loppu. Relevantti vain, jos T54 > 0. Molemmat kentät pois päältä.
Jälkikäsittely + Apple AI (T56–T60)
T56postTrainingCompactification
TIEDOT
Oletus: true (kaikissa tuotantoesiasetuksissa), false (.quickTest, .preview) Alue: boolean Määritelty:
TEKNINEN
V443-ominaisuus: koulutuksen päätyttyä Gaussianit, joiden sigmoid(opacity) < 0.01, poistetaan kovakoodatusti (ne eivät käytännössä enää vaikuta kuvaan). Vähentää Gaussian-määrää tyypillisesti 58 % ja vientitiedoston kokoa 55 % ilman näkyvää laadunmenetystä. Oletuksena aktiivinen tuotantoesiasetuksissa — lopputulos on tarkoitus toimittaa mahdollisimman kompaktina. .quickTest:ssä pois päältä, koska diagnoosiajoa ei joka tapauksessa viedä. Toisin kuin T42 midTrainingCompactificationIterations (V549), tiivistys tapahtuu vasta lopussa — hienosäätö voi siihen asti käyttää kaikkia Gaussianeja.
T57metalFXUpscaling
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
V444-ominaisuus: aktivoi Applen MetalFX Spatial Upscalerin bilineaarisen interpolaation sijaan 3D-katselimen ulostulossa. Jos koulutusresoluutio < näkymäikkunan koko (esim. koulutus 0.5×, näkymäikkunan näyttö täydellä resoluutiolla), MetalFX voi tuottaa huomattavasti terävämmän kuvan. Muuttuu livenä näkymäikkunassa, ei vaadi uudelleenkoulutusta. Sulkee pois T58 mpsLanczosScaling:n — MetalFX:llä on etusija. Suositus: kytke päälle, jos kuva näkymäikkunassa näyttää "suttuiselta" odotettuun yksityiskohtaan verrattuna.
T58mpsLanczosScaling
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
V444-ominaisuus: MPSImageLanczosScale näkymäikkunan skaalaukseen bilineaarisen interpolaation sijaan. Lanczos on klassinen Sinc-pohjainen uudelleennäytteistysmenetelmä, joka tuottaa huomattavasti terävämpiä tuloksia kuin bilineaarinen minimaalisella ylikuormalla. Live-kytkin. T57 ylikirjoittaa tämän, jos molemmat ovat päällä.
T59livePreviewInterval
TIEDOT
Oletus: 50 (alustaja ja useimmat esiasetukset) Alue: 0 (pois) tai 10 – 5 000 Määritelty:
TEKNINEN
Kuinka usein koulutuksen aikana 3D-katselin päivitetään nykyisillä Gaussianeilla. 50 = joka 50. iteraatiolla uusi renderöinti katselimessa — riittävän hyvä edistymisen seuraamiseen hidastamatta koulutusta. 0 = katselinta ei päivitetä lainkaan (taustakoulutus, maksiminopeus). Tyypillinen säätö: .quickTest:ssä lasketaan 10:een (halutaan nähdä jokainen askel), pitkissä MCMC-ajoissa nostetaan 500–2000:een (päivityksen ylikuorma on summassa tuntuva).
T60perceptualLossWeight
TIEDOT
Oletus: 0.0 (= pois päältä) Alue: 0 tai 0.001 – 0.5 Määritelty:
TEKNINEN
V444-tulevaisuuden ominaisuus: havainnollisen loss-termin paino MPSGraphin kautta (VGG:n kaltainen pieni verkko). Tunnistaisi rakenteellisen ja tekstuurillisen samankaltaisuuden korkeammalla semanttisella tasolla kuin L1+SSIM — tyypillistä tutkimusputkissa, joissa "pikselintarkka" on vähemmän tärkeää kuin "näyttää realistiselta". Toteutus vielä kesken (koodipohja olemassa, mutta forward-passia ei ole toteutettu). Oletus 0.0. Pysyy kenttäluettelossa tulevaa aktivointia varten; CLI-lippu –percep-weight F varattu.
MCMC-Densification (T61–T73)
T61densificationStrategy
TIEDOT
Oletus: .classic (alustaja + Classic-esiasetukset), .mcmc (kaikki MCMC-esiasetukset + Scene-Class) Alue: .classic tai .mcmc Määritelty:
TEKNINEN
Valitsee Classic-Densificationin (kloonaus/jako/karsinta, Kerbl et al.~2023) ja MCMC-Densificationin (Stochastic Gradient Langevin Dynamics uudelleensijoituksella, Kheradmand et al.~NeurIPS 2024) välillä. .classic:ssa arvioidaan T11–T16, .mcmc:ssä T62–T73. Huomio vaihtaessa: Classic-oletukset ja MCMC-oletukset on kalibroitu täysin eri tavalla — jos valitsinta asiantuntijanäkymässä kääntää lataamatta sopivaa esiasetusta, on riski 1.4.3-bugin kaltaisesta massasukupuutosta (460 K → 5 yhdessä iteraatiossa, koska MCMC-OpacityReg 0.01:llä tappaa Classic-opasiteetit). Siksi MCMC-alustus-oletukset on tarkoituksella "pehmennetty" (kaikki reg-arvot 0.0).
T62mcmcMaxGaussians
TIEDOT
Oletus: 150 000 (alustaja + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — Mip-Splatting-variantti 10× budjetilla), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) Alue: 0 (= "käytä puskurin kapasiteettia") tai 10 000 – 5 000 000 Määritelty :
TEKNINEN
Kova yläraja Gaussianien määrälle MCMC-strategiassa. Määrä kasvaa vähitellen T70 mcmcGrowthRate:n mukaisesti (tyypillisesti 5 %) per uudelleensijoitusaskel tähän rajaan asti. V473/V531 havaitsivat 150 K optimaaliseksi — yli 200 K laimentaa splat-laatua (liian monta pientä, redundanttia Gaussiania), alle 100 K jättää näkymän ali-tihennetyksi. Erittäin suurissa näkymissä (esim. 1 545 kuvan droonilento 158 K SfM-alustuksella) 150 K on liian matala — siksi 1.4.5-laajennus T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt löysi näkymäkohtaisia optimeja väliltä 670 K (sisätila) ja 1.25 M (ulkotila). Arvolla 0 moottori käyttää koko puskurin kapasiteettia rajana.
T63mcmcNoiseScale
TIEDOT
Oletus: 0.00005 (5e-5 = artikkelin oletus) Alue: 1e-6 – 1e-3 Määritelty:
TEKNINEN
Kerroin Gaussin kohinalle, joka lisätään jokaisen Gaussianin sijaintiin jokaisessa MCMC-iteraatiossa (SGLD-logiikka). Korkeampi = enemmän etsintää (Gaussianit vaeltavat enemmän, löytävät mahdollisesti parempia paikkoja), matalampi = enemmän hyödyntämistä (Gaussianit pysyvät siellä, missä ne ovat jo hyviä). V467 ja V536 vahvistivat 5e-5 optimaaliseksi — 1e-5/2e-5 liian vähän etsintää, 1e-4 liikaa (splatit hajoavat). Vaimennetaan kosinilla koulutusajan kuluessa T69 mcmcNoiseDecayEnd:iin asti — vaimennusalueen lopussa kohina on tehokkaasti 0 ja Gaussianit konvergoituvat.
T64mcmcOpacityRegWeight
TIEDOT
Oletus: 0.0 (= pois päältä RadianceKitin oletuksissa, artikkeli: 0.01) Alue: 0 tai 0.001 – 0.05 Määritelty:
TEKNINEN
MCMC-spesifinen L1-rangaistus opasiteetille. Artikkelin oletus 0.01 (painaa käyttämättömät Gaussianit nollaan, tekee ne saataville uudelleensijoitusta varten). V464b osoitti kuitenkin: ilman regularisointia tulos on RadianceKitissä mitattavasti parempi (sessio 28 vahvistaa). Syy: T68 mcmcDeadOpacityThreshold:lla määritelty karsintakriteeri riittää yksinään — ylimääräinen L1-rangaistus pakottaa myös arvokkaat, matalan opasiteetin Gaussianit kuolemaan. Siksi oletus 0. Huomio: 1.4.3-beta-versiossa alustajan oletus oli virheellisesti 0.01, mikä johti massasukupuutto-bugiin (katso T61-selitys); versiosta 1.4.4 lähtien kiinnitetty 0.0:aan.
T65mcmcScaleRegWeight
TIEDOT
Oletus: 0.0 (= pois päältä, artikkeli: 0.01) Alue: 0 tai 0.001 – 0.05 Määritelty:
TEKNINEN
MCMC-spesifinen L1-rangaistus skaala-ominaisarvoille. Artikkelin oletus 0.01. V464b: parempi ilman regularisointia, sama perustelu kuin T64:ssä. Pois päältä kaikissa RadianceKitin MCMC-esiasetuksissa. Huomio kuten T64:ssä: 1.4.3-bugi.
T66mcmcRelocationInterval
TIEDOT
Oletus: 100 (alustaja + kaikki MCMC-esiasetukset, artikkelin standardi), 155 (P9 Outdoor — Q7-BayesOpt-optimi) Alue: 50 – 500 Määritelty:
TEKNINEN
Iteraatioväli, jolla MCMC siirtää kuolleet Gaussianit (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) uusiin sijainteihin. V537 testasi 50 (liian häiritsevä, loss vaihtelee) ja 200 (marginaalisesti huonompi, MCMC menettää reaktiokykyään). 100 on optimaalinen. Q7-BayesOpt Bicycle-aineistolla löysi 155:n näkymäkohtaiseksi optimiksi ulkotiloihin — hieman pidemmät välit antavat Adamille enemmän aikaa integroida uudet sijoitetut Gaussianit, ennen kuin seuraava uudelleensijoitustapahtuma painostaa niitä.
T67mcmcWarmupIterations
TIEDOT
Oletus: 500 Alue: 100 – 5 000 Määritelty:
TEKNINEN
Alkuperäisten iteraatioiden määrä, joiden aikana MCMC-uudelleensijoitusta ei vielä tapahdu. Vasta tämän lämmittelyn jälkeen uudelleensijoituslogiikka alkaa. Tarkoitus: ensimmäisissä iteraatioissa opasiteettiarvot eivät ole vielä vakiintuneet — jos uudelleensijoitus aloitettaisiin heti, Gaussianit sijoitettaisiin vääriin paikkoihin ja ne olisi siirrettävä heti uudelleen, mikä tuhoaisi Adam-momentumin. Artikkelin oletus 500. RadianceKit ottaa tämän arvon, koska V464b osoitti sen olevan robusti.
T68mcmcDeadOpacityThreshold
TIEDOT
Oletus: 0.005 (alustaja, artikkelin standardi), 0.01 (.fullMCMC ja kaikki MCMC-esiasetukset — V535-optimi) Alue: 0.001 – 0.05 Määritelty:
TEKNINEN
sigmoid(Opacity)-kynnysarvo, jonka alapuolella oleva Gaussian katsotaan "kuolleeksi" ja tulee kyseeseen uudelleensijoitusta varten. V535 havaitsi 0.01 optimaaliseksi (0.005 marginaalinen, 0.02 huonompi). Korkeampi = aggressiivisempi uudelleensijoitus (enemmän Gaussaneja siirretään), matalampi = varovaisempi. 0.01 vastaa noin "0.5 % visuaalista näkyvyyttä". P10 Indoor käyttää Q7-BayesOptin kautta 0.0142:ta optimina.
T69mcmcNoiseDecayEnd
TIEDOT
Oletus: 0 (alustaja = "ei vaimennusta"), 160 000 (.fullMCMC = 80 % 200K:sta), 96 000 (.mcmcBalanced = 80 % 120K:sta), 40 000 (.mcmcPreview) Alue: 0 tai 1 000 – Määritelty:
TEKNINEN
Iteraatio, jossa T63 mcmcNoiseScale-kohina vaimennetaan kokonaan nollaan (kosinivaimennus iteraatiosta 0 tähän). V497c/V502 havaitsivat 80 % maksimi-iteraatioista optimaaliseksi — antaa MCMC:lle tarpeeksi etsintäaikaa, mutta jättää viimeiset 20 % konvergenssille ilman kohinaa. 0 = vakio kohina kaikkien iteraatioiden ajan (harvoin järkevää, MCMC ei voi silloin konvergoitua).
T70mcmcGrowthRate
TIEDOT
Oletus: 0.05 (artikkelin standardi = 5 %) Alue: 0.01 – 0.2 Määritelty:
TEKNINEN
MCMC-populaation tavoitteen kasvunopeus per uudelleensijoitusaskel. Logiikka: jokaisessa uudelleensijoitustapahtumassa tavoitepopulaation kokoa kasvatetaan (1 + growthRate):lla, kunnes T62 mcmcMaxGaussians (tai T72/T73:lla skaalattu variantti) saavutetaan. V512/V522 havaitsivat 0.05 optimaaliseksi — korkeammat arvot johtavat liian nopeaan kasvuun (Gaussaneja lisätään, ennen kuin Adam-momentum ehtii integroida ne), matalammat ali-tihennettyihin näkymiin lopussa.
T71mcmcSigmoidK
TIEDOT
Oletus: 100.0 Alue: 10.0 – 500.0 Määritelty :
TEKNINEN
Sigmoidin terävyysparametri MCMC-kohinan vaimennukselle. SGLD-askeleessa Gaussian-kohtainen kohina vaimennetaan :llä — korkean opasiteetin Gaussianit (joiden logit on positiivinen) saavat eksponentiaalisesti vähemmän kohinaa kuin matalan opasiteetin Gaussianit. K = 100 on terävä, eli siirtymä "täydestä kohinasta" "ei kohinaa" -tilaan tapahtuu hyvin nopeasti opasiteetin 0.5 ympärillä. V484–V487 havaitsivat K = 100 optimaaliseksi — pienemmät arvot (10–50) antavat myös korkean opasiteetin Gaussianien heilua mukana (tuhoaa konvergoituneet Gaussianit), suuremmat (> 500) tekevät siirtymästä keinotekoisen kovan eivätkä kuolleet Gaussianit enää liiku lainkaan.
T72mcmcCapMultiplier
TIEDOT
Oletus: 3.0 (alustaja + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Alue: 0 (= pois päältä) tai 1.0 – 10.0 Määritelty:
TEKNINEN
1.4.5-ominaisuus: näkymäkohtainen adaptiivinen rajan skaalaus. Jos T73 mcmcAutoScaleByScene on tosi, tehokas raja lasketaan :na (rajoitettu puskurin kapasiteettiin). Tausta: suurissa näkymissä (esim. 1 545 kuvan droonilento → 158 K SfM-alustus) T62 = 150 000 on liian matala — Density-Control ei voisi kasvaa lainkaan. Kertoimella 3.0 raja skaalataan tässä esimerkissä 474 K:hon (158 K × 3.0). Q7-BayesOpt löysi näkymäkohtaisia optimeja: Outdoor hyötyy korkeasta kertoimesta (5.32 → ~830 K raja 156 K bicycle-alustuksella), Indoor tyytyy 1.76:een (seinät kyllästävät nopeammin). Rajan täydellinen ratkaisu, katso -metodi.
T73mcmcAutoScaleByScene
TIEDOT
Oletus: true (alustaja + kaikki MCMC-esiasetukset) Alue: boolean Määritelty:
TEKNINEN
1.4.5-ominaisuus: pääkytkin näkymätietoiselle rajalogiikalle (katso T72 +). Jos false, käytetään yksinomaan T62 mcmcMaxGaussians:ia rajana (paluu 1.4.4-käyttäytymiseen). Oletuksena päällä, koska suurten näkymien massasukupuutto-ongelmat 1.4.3:sta palaisivat muuten. Manuaalisesti pois päältä vain, jos haluat eksplisiittisesti asettaa kovan rajan — esim. kouluttaaksesi 150 K-variantin, jonka loppukoko on ennustettavissa.
Mip-Splatting (Q1.5) (T74–T76)
Tila: Q1.5 hylättiin 25.5.2026 14 autonomisen iteraation + yön yli kestävän 1.5M-varmistustarkistuksen jälkeen "closed no-win" -päätöksellä (max Δ@2× = +0.27 dB, alkuperäinen portti vaati ≥ +1.5 dB keskiarvoa 0.5×/2×:n yli, FAIL 0/11 paritetulla näkymällä). Kentät pysyvät opt-in tutkimuskokeita varten; kaikissa tuotantoesiasetuksissa. Katso tuomio:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
TIEDOT
Oletus: false (kaikki tuotantoesiasetukset), true (.fullMCMCMip — tutkimussisar) Alue: boolean Määritelty:
TEKNINEN
Aktivoi Mip-Splattingin (Yu et al.~CVPR 2024): 3D-tasoitussuodatin + 2D-suodatin + α-kompensaatio, joka rajoittaa Gaussian-kohtaisen taajuuden tiheimmän koulutuskameran näytteenottotaajuuden Nyquist-rajaan. Teoreettinen tavoite: aliaksen poistaminen renderöitäessä koulutuksen ulkopuolisilla skaaloilla (0.5× tai 2× koulutusresoluutiosta). Aktivoitu esikäsittely- ja takaisinprojisointi-shadereissa, toiminnallisesti oikein varmennettu Q1.5-D-testissä. Mutta: alkuperäistä hyväksymisporttia (Δ@1× ≥ +0.3 dB JA avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) ei saavutettu yhdelläkään 11 paritetusta näkymästä. Maksimihavainto: family 750K classic Δ@2× = +0.270 dB. Ulkonäkymät (Truck, Flowers) osoittivat jopa heikkenemistä 1× ja 0.5×. Hypoteesi: 3D-tasoitus kilpailee MCMC-uudelleensijoituksen kanssa korkeilla Gs-arvoilla. Kenttä pysyy tulevaa moniskaalaista uudelleenarviointia varten oikealla Mip-NeRF-360-metodologialla (katso O3-backlog benchmark-polussa).
T75mipSmoothing3DScale
TIEDOT
Oletus: 0.2 (artikkelin oletus) Alue: 0.05 – 1.0 Määritelty:
TEKNINEN
3D-tasoituksen skaalaparametri (Yu et al.~§3.3, artikkelin oletus 0.2). Suurempi = enemmän maailmanavaruuden tasoitusta per Gaussian (= enemmän anti-aliasingia, mutta myös enemmän sumennusta oletusskaalassa), pienempi = terävämpi mutta alttiimpi aliakselle. Huomioidaan vain, jos T74 useMipSplatting = true. Ei optimoitu enempää Q1.5-testeissä — A/B-portti hävisi jo artikkelin oletuksella 0.2, lisäpyyhkäisyt olisivat olleet turhia.
T76mipFilter2DVariance
TIEDOT
Oletus: 0.3 (= täsmälleen V242-perintökäyttäytyminen) Alue: 0.1 – 1.0 Määritelty:
TEKNINEN
2D-Mip-suodattimen varianssi, joka lisätään Σ_2D-diagonaaliin (varianssi suoraan, ei neliöitynä). 0.3 on täsmälleen V242-perintöarvo, joka oli kovakoodattu kerneliin ennen Mip-Splattingia. Jos T74 useMipSplatting = false, kerneli jättää tämän arvon kokonaan huomiotta ja kirjoittaa kovakoodatun 0.3:n — jotta peruslinja ei voi regressoitua (Codex-Round-1-S3-1-takuu). Jos, käytetään tässä asetettua arvoa. Pysyy kenttäluettelossa Mip-pyyhkäisyjä varten.
Adaptiivinen Densification (Q5) (T77–T79)
T77adaptiveDensification
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
Q5-ominaisuus: liukuvan mediaanin seuranta vaihtoehtona kiinteälle T11 densifyGradThreshold:lle. Jos tosi, jokaisessa tihennysvaiheessa nykyinen kynnysarvo ylikirjoitetaan median(viimeiset N avgGrad-näytettä) × T79 adaptiveDensifyMultiplier:lla. N = T78 adaptiveWindow. Tiukempi kuin V440 p98 (katastrofaalinen 63 K-karsinta-ansa), mediaani + 2× on noin p70–p80:n kohdalla gradienttijakaumasta vakaassa tilassa. Q5-testit: yksinään FAIL 0/3 näkymää, mutta yhdessä Q6:n kanssa (katso T80/T81) PASS 1/3 näkymää — Q5+Q6-paketti hyväksyttiin 25.5.2026 opt-in-ominaisuutena ja on aktivoitavissa CLI:llä –adaptive-densify. Q6 on tässä "kantaja" laadun parannukselle, Q5 edistää pikemminkin vakautta.
T78adaptiveWindow
TIEDOT
Oletus: 1 000 Alue: 100 – 10 000 Määritelty :
TEKNINEN
Liukuvan mediaanin ikkuna tihennystapahtumissa (EI iteraatioissa — jokainen T13 densifyInterval-askel tuottaa yhden näytteen). Oletus 1 000 — tarkoittaa, että viimeiset 100 000 koulutusiteraatiota vaikuttavat mediaaniin, eli tyypillisesti koko koulutushistoria tähän asti. Varhainen vaihe (ennen T78 näytettä): seuranta palauttaa nil → paluu kiinteään kynnysarvoon T11. Relevantti vain, jos.
T79adaptiveDensifyMultiplier
TIEDOT
Oletus: 2.0 Alue: 1.0 – 4.0 Määritelty:
TEKNINEN
Kerroin liukuvalle mediaanille adaptiivista kynnysarvoa varten. Oletus 2.0 vastaa suunnilleen p70–p80:tä tyypillisestä gradienttijakaumasta. Matalampi = aggressiivisempi kasvu (enemmän klooneja), korkeampi = tiukempi (vähemmän klooneja). Q5-testit alueella 1.5–3.0 — 2.0 paras oletus. Relevantti vain, jos.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
Q6-ominaisuus: koulutusresoluutio alkaa 0.5×:stä ja vaihtuu T50 positionLRScheduleEndIteration / 2:ssa (tai T1 maxIterations / 2, jos T50 ei ole asetettu) arvoon T22 trainingRenderScale. Käyttää Q1.5.1:ssä kehitettyä resize/restoreImageBuffers-infrastruktuuria. Ylikirjoittaa T23 resolutionWarmupScale:n, jos aktivoitu. Q6 on hyväksytty "laadun parannuksen kantajana" Q5+Q6-paketissa (katso T77) — askelittainen resoluution nosto antaa sovellukselle aikaa löytää karkea geometria matalammalla resoluutiolla, ennen kuin se siirtyy hienoon yksityiskohtatyöhön. CLI:llä: –curriculum-resolution.
T81curriculumSHProgression
TIEDOT
Oletus: false Alue: boolean Määritelty:
TEKNINEN
Q6-ominaisuus: ylikirjoittaa T21 shDegreeUpgradeIterations:n arvolla [maxIter/4, maxIter/2, maxIter*3/4], eli jakaa SH-päivitykset tasaisesti koulutusajan yli sen sijaan, että ne painottuisivat alkuun. Hypoteesi: vakaa geometria vakiinnutetaan ennen väriyksityiskohtien räjähdystä, mikä sijoittaa katselusuunnasta riippuvat kiiltoefektit tarkemmin. Q5+Q6 yhdessä PASS 1/3 näkymää, Q6 kantajana parannukselle (Q5 yksin FAIL). CLI:llä: –curriculum-sh.
Staattiset esiasetukset (TP1–TP9)
Tässä vain rakenteelliset erot alustajan oletusarvoihin. Kymmenen käyttöliittymän esiasetuksen P1–P10 täydelliset markkinointikuvaukset löydät Luvusta 7.
TP1.preview
TIEDOT
Diagnoosi-/esikatseluesiasetus järjestelmille, joissa ≥ 10 Gt RAM. Ylikirjoitukset alustajaan verrattuna: - 30 000 → 5 000 - 15 000 → 3 500 (70 % maxIteristä) - 1.6e-6 → 1.6e-5 (10× korkeampi, vähemmän aggressiivinen vaimennus) -,,,, kukin 2× (V176) - 3 000 → 100 000 (tehokkaasti pois, V172: nollaus tuhoaa lyhyet koulutukset) - [1K, 2K, 3K] → [1K, 2K] (V182: aste 3 ei konvergoidu 2K iteraatiossa) - 1.0 → 0.5
TP2.full
TIEDOT
Tuotantolaatuinen Classic. Ylikirjoitukset: - 30 000 → 35 000 (V550: 40K-testit Truck-ylikoulutus +10.7 % Gs, -1.3 % L1) - 15 000 → 5 000 (V310 optimaalinen, V338 7K huonompi) - Kaikki oppimisnopeudet 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 pois päältä, V421 vahvisti) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 viivästetty) - 0.0 → 0.9995 (V546 HTGS, 14 % parannus) - 50 (muuttumaton, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, jo alustajan oletus .full:lle)
TP3.fullClassicPaper
TIEDOT
Q1.5-A-testisisar TP2:lle, artikkelille uskollinen Classic. Ylikirjoitukset TP2:een verrattuna: - 35 000 → 30 000 (artikkelin standardi) - 5 000 → 15 000 (artikkeli: 50 % maxIteristä) - 1.6e-5 → 1.6e-6 (artikkelin oletus) -,, takaisin artikkelin oletuksiin (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (kalibroitu ~1-2M Gs:lle Bicycle-aineistolla) - 200 → 100 (artikkeli) - 0.001 → 0.005 (artikkelin oletus) - 100 000 → 3 000 (artikkeli §5.2, riskialtis — voi laukaista V194-regression) - 0.9995 → 0.0 (artikkelissa ei ole vaimennusta) - 20 000 → 30 000 (kosini kattaa 100 % maxIteristä)
TP4.fullMCMC
TIEDOT
Tuotantolaatuinen MCMC. Ylikirjoitukset alustajaan verrattuna: - 30 000 → 200 000 (V534, MCMC tarvitsee 5× enemmän iteraatioita kuin Classic) - 15 000 → 160 000 (V504b 80 % maxIteristä) - 1.6e-6 → 1.6e-5 - LR-aikataulu kuten TP2 (kaikki 2×) - 0.2 → 0.05 (V521b/V534: MCMC tarvitsee vahvemman L1-signaalin) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (jo alustajassa, vahvistettu esiasetuksessa) - 5e-5 (V467/V536 optimaalinen) - 0.005 → 0.01 (V535 optimaalinen) - 0 → 160 000 (80 % maxIteristä, V497c/V502) - 3.0 (jo alustajassa) - true (jo alustajassa) - 3 000 → 200 000 (tehokkaasti pois, MCMC käyttää uudelleensijoitusta nollauksen sijaan)
TP5.fullMCMCMip
TIEDOT
Q1.5-D-testisisar TP4:lle, Mip-Splattingilla + artikkelin suuruusluokan MCMC-budjetilla. Ylikirjoitukset TP4:ään verrattuna: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, artikkelin suuruusluokka) - useMipSplatting false → true (Mip päällä)
TP6.classicBalanced
TIEDOT
Keskitason Classic. Ylikirjoitukset TP2:een verrattuna: - 35 000 → 20 000 (V149: 20K = 30K 33 % lyhyemmässä ajassa) - 20 000 → 0 (kosini kattaa maxIter = 20K, ei laajennettua vaihetta)
TP7.mcmcPreview
TIEDOT
MCMC-diagnoosi. Ylikirjoitukset TP4:ään verrattuna: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: Preview = kevyempi skaalaus)
TP8.mcmcBalanced
TIEDOT
Keskitason MCMC. Ylikirjoitukset TP4:ään verrattuna: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3.0 → 2.5 (Preview 2.0:n ja Full 3.0:n välissä)
TP9.quickTest
TIEDOT
Puhdas toiminnallisuustesti. Ylikirjoitukset alustajaan verrattuna: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (kalibroitu 0.25× resoluutiolle) - 100 → 50 - 3 000 → 100 000 (pois, koska liian lyhyt) - 1.0 → 0.25
Metodi:
Signatuuri: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Määritelty:
Ainoa totuuden lähde kysymykseen "kuinka monta Gaussiania MCMC saa enintään kasvattaa?". Lasketaan kolmesta syötteestä: konfiguroidusta T62 mcmcMaxGaussians:sta (massasukupuuton alaraja 150 000, jos 0), (SfM-alkupisteiden määrä) ja (ennalta varattu Gaussian-puskurin koko). Logiikka:
+ base = T62 > 0 ? T62: 150_000 (massasukupuuton alaraja suojaa alustajan oletusarvojen bugeilta, kuten 1.4.3:n massasukupuutto-tapaukselta) + Jos T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) muuten
+ Jos bufferCapacity > 0: return min(scaled, bufferCapacity) + Muuten return scaled
Esimerkki: Bicycle (Mip-NeRF 360, 194 valokuvaa) → SfM-alustus ~156 K pistettä, T62 = 150 000, T72 = 5.32,, puskurin kapasiteetti 8 M. Ratkaistu raja = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. Tämä on tehokas kasvun raja, jota MCMC-uudelleensijoituslogiikka noudattaa.
Laskee todellisen maksimimäärän splatteja MCMC:ssä. Ottaa asetuksesi, tarkistaa, kuinka monta pistettä näkymässäsi on aluksi, ja skaalaa Multiplier-kertoimella, jos automaattinen säätö on päällä. Näin raja sopeutuu näkymään sen sijaan, että pienelle ja jättimäiselle näkymälle pakotettaisiin sama arvo. Sinun ei tarvitse kutsua metodia itse — koulutus käyttää sitä sisäisesti.
Mikä kenttä mihinkin? (Muistilista)
| Tavoite | Muutettavat kentät |
|---|---|
| Lisää yksityiskohtia kauas | T62 mcmcMaxGaussians ylös, T72 mcmcCapMultiplier 5+ |
| Lisää yksityiskohtia yleisesti (Classic) | T1 maxIterations ylös (≤ 40K), T2 densifyUntilIteration ≤ 14 % T1:stä |
| Vähennä leijuvia partikkeleita droonilennoissa | T43 frustumCullEnabled päälle, T20 skyMaskingEnabled päälle, T45 skyDomeEnabled päälle |
| Kauniimpi taivas ulkokohtauksissa | T45 skyDomeEnabled päälle, T47 skyDomeRadiusMultiplier 30–60 |
| Pienempi vientitiedosto | Strategia .mcmc (T61), T56 postTrainingCompactification päälle, T62 mcmcMaxGaussians ≤ 200K |
| Nopeampi koulutus | T22 trainingRenderScale 0.5, T1 maxIterations puolitettuna — mutta ei molempia! |
| Paremmat kiiltokohdat | T21 shDegreeUpgradeIterations arvolla [2K, 5K, 8K] (ei varhaista painotusta alkuun), MCMC + 200K iteraatiota |
| Pidä Mac responsiivisena | T25 throttleDelayMs 5–10 (maksaa ~15 % koulutusaikaa) |
| Live-esikatselu useammin | T59 livePreviewInterval alas 10–20:een |
| Pehmeämmät siirtymät varjoissa | T17 ssimWeight hieman ylös (0.15–0.25), mutta ei yli 0.3:n |
| Pidä sisätilat kompakteina | P10 Indoor-esiasetus (, T72 = 1.76) |
Vaaralliset kentät
Nämä kentät voivat väärin konfiguroituina johtaa muistin loppumiseen, sovelluksen kaatumiseen, Gaussianien massasukupuuttoon tai käyttökelvottomiin benchmark-tietoihin. Käsiteltävä varoen:
- T11 densifyGradThreshold — puolittaminen voi tuottaa 2–4× niin monta Gaussiania, mikä täyttää nopeasti GPU-muistin. Huomioi myös: on vastattava T22 trainingRenderScale:a (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — suurissa näkymissä, joissa on > 200 K SfM-alkupistettä ja kerroin > 5, syntyy miljoonien Gaussianien ratkaistu raja. 36 Gt:n RAM-muistilla varustetuilla Maceilla muistin loppuminen on mahdollista. Outdoor-esiasetus 5.32 toimii vain, koska Mip-NeRF-360-Bicycle-aineistossa on 156 K alkupistettä → 830 K raja. - T39 testViewIndices — manuaalinen asettaminen voi tehdä benchmarkista käyttökelvottoman (kaikki indeksit > N → ei testijoukkoa). Anna –benchmark-lipun asettaa tämä. - T64 mcmcOpacityRegWeight ja T65 mcmcScaleRegWeight — Asetettiin 1.4.3-beta-versiossa 0.01:een, mikä johti massasukupuuttoon (460 K → 5 Gaussiania yhdessä iteraatiossa). Versiosta 1.4.4 lähtien kiinnitetty 0.0:aan, mutta manuaalinen nostaminen voi toistaa ongelman. - T15 opacityResetInterval — jos ei 100 000+ (tehokkaasti pois) ja koulutus on lyhyempi kuin 10 000 iteraatiota, nollaus tuhoaa konvergenssin. .preview:ssä se on siksi 100 000, vaikka maxIterations = 5 000. - T54/T55 densifyPhase2* — Kaksivaiheinen tihennys on testeissä päättynyt 0-Gaussianin kaskadiin. Jätä molemmat arvoon 0. - T74 useMipSplatting — Q1.5 closed-no-win 25.5.2026, voi joissakin ulkonäkymissä jopa heikentää PSNR:ää. Oletuksena pois päältä, opt-in vain tutkimusta varten.
Jos kenttä on tällä listalla ja haluat muuttaa sitä, tee ensin varmuuskopio nykyisestä esiasetuksestasi (vienti JSON-muodossa) ja harkitse, voitko mitata tuloksen toistettavasti — muuten et tiedä jälkikäteen, oletko saanut aikaan parannuksen vai heikennyksen.