Hoofdstuk 6 — Trainingsconfiguratie
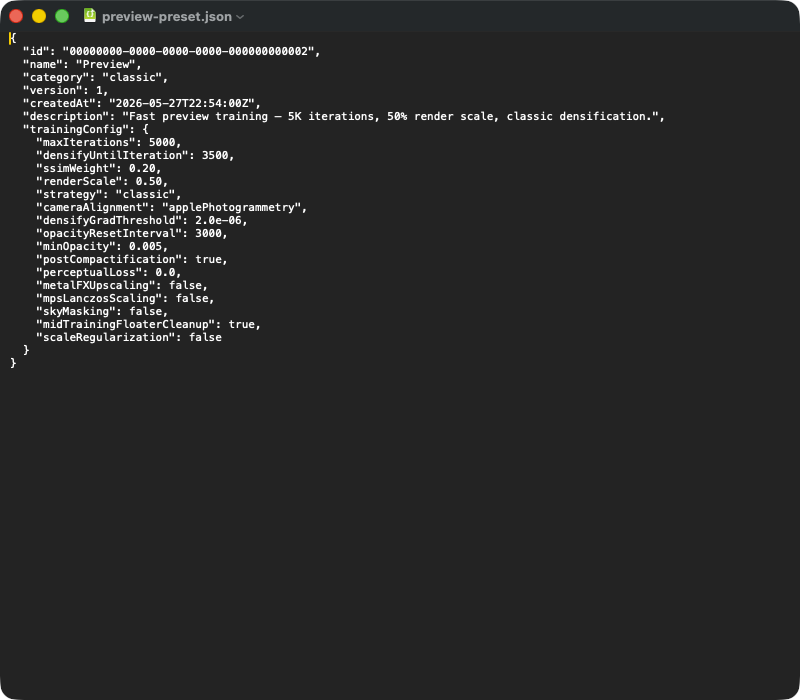
Een typische voorinstelling-JSON-export. Top-level-velden: id (UUID), name, (classic | mcmc | sceneClass | custom), (schemaversie), (timestamp), (vrije tekst). Geneste -object bevat de voor reproduceerbaarheid kritieke parameters — bij import wordt het gehele blok in de TrainingConfig-structuur gedeserialiseerd, en defaults uit de app-versie vullen de velden die in de JSON ontbreken (bijv. na app-update). Wie een voorinstelling aan een andere Mac doorgeeft, stuurt gewoon dit JSON-bestand over.
De TrainingConfig-structuur is het hart van elke trainingsrun in RadianceKit. Hij verzamelt elke parameter die de training beïnvloedt — van het maximale iteratie-aantal via de acht leerratio's tot aan de speciale velden voor MCMC, Mip-Splatting, het curriculum en de scene-aware cap-logica. Je bewerkt hem in de zijbalk in het gebied trainingsconfiguratie-sectie (Expert View), slaat hem op als voorinstelling of geeft hem als JSON-export aan een andere Mac door. Bij de training wordt precies dit object bevroren en aan het GPU-backend gegeven.
Dit hoofdstuk is referentiemateriaal voor power users en scriptauteurs. Het somt alle 81 publieke velden, de 9 statische voorinstellingen en de ene publieke methode op. Bronbestand is TrainingConfig.swift — bij twijfel geldt het daar opgeslagen doc-comment en de initializer-default als source-of-truth.
Inhoudsopgave:
+ Iteratie (T1–T2) + Learning Rates (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH-graad-progressie (T21) + Performance (T22–T25) + Diagnose en puntenwolk-voorbereiding (T26–T30) + Regularisatie (T31–T37) + Refinement (T38–T44) + Sky-Dome (T45–T48) + Adam + LR-schedule (T49–T55) + Post-processing + Apple AI (T56–T60) + MCMC-densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptive densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Statische voorinstellingen (TP1–TP9) + Methode: + Welk veld waarvoor? (cheatsheet) + Gevaarlijke velden
Iteratie (T1–T2)
T1maxIterations
DETAILS
Default: 30.000 (initializer), 35.000 (.full), 200.000 (.fullMCMC) Range: 1.000 – 500.000 (UI-slider), geen harde bovengrens in de logica Defined in:
TECHNISCH
Totaal aantal trainingsiteraties dat het backend doorloopt. Eén iteratie betekent een forward-render van een afzonderlijke trainingscamera, een backward-pass over alle loss-componenten (L1 + SSIM + optionele regularisaties + sky-mask) en een Adam-optimizer-stap. Dit getal werkt direct in op de andere schedules: position-leerratio volgt een cosine-annealing-curve van 0 tot ofwel T1 zelf ofwel tot T49 positionLRScheduleEndIteration; densification stopt bij T2 densifyUntilIteration; MCMC-noise-decay eindigt bij T69 mcmcNoiseDecayEnd; SH-graad-upgrades gebeuren op de drie in T21 gedefinieerde merken. Bij klassieke densification ligt de empirisch bepaalde sweet spot bij 20.000–35.000 iteraties (sessies 1–32, V546-tests), bij MCMC bij 60.000–200.000 (V534). Een drastische verhoging boven de in voorinstellingen opgeslagen waarden brengt zelden extra kwaliteit — Adam-momentum verzadigt, en zonder LR-decay-eind stagneert de loss. Omgekeerd leidt onderschrijding van ~5.000 tot onvolledig geconvergeerde geometrieën (density-control heeft te weinig tijd om te klonen/splitsen).
T2densifyUntilIteration
DETAILS
Default: 15.000 (initializer), 5.000 (.full), 160.000 (.fullMCMC) Range: 0 – Defined in:
TECHNISCH
Iteratie vanaf waar de densification stopt. Tot hier worden Gaussians via de in T11–T16 (Classic) of T67–T70 (MCMC) geparametriseerde regels geklond, gesplitst en gepruned; daarna blijft het Gaussian-aantal constant en worden alleen nog posities, rotaties, schalen, opacities en SH-coëfficiënten geoptimaliseerd (refinement-fase). In het originele 3DGS-paper ligt de waarde bij 50% van T1, in RadianceKits .full-voorinstelling bij slechts ~14% (5.000 van 35.000) — gevolg van de V310/V338-experimenten die aantoonden dat na 5.000 iteraties verdere densificatie het resultaat eerder verslechtert (meer floaters, meer geheugengebruik, geen kwaliteitswinst). MCMC daarentegen laat de relocation tot 80% van T1 lopen (V504b), omdat MCMC geen schadelijke floaters produceert. Wordt T2 te klein gekozen (< 1.000), ontstaan te weinig Gaussians; te groot bij Classic (> 50% van T1) leidt tot overgrowth en RGB-saturation-outliers (zie outdoor-overtraining-findings).
Learning Rates (T3–T10)
T3positionLearningRate
DETAILS
Default: 0,00016 Range: 1e-7 – 1e-3 (aanbevolen) Defined in:
TECHNISCH
Adam-leerratio voor de XYZ-positie van elke Gaussian aan het begin van de training (iteratie 0). Volgt een cosine-annealing-curve en daalt in de loop van de training tot T4 positionLearningRateFinal. De default 0,00016 komt uit het originele 3DGS-paper (Kerbl et al.~2023) en is in RadianceKit ook bij verhoging van de beeldresolutie niet te schalen — de positie beweegt zich in het wereldcoördinatensysteem, niet in pixelruimte. Een duidelijke verhoging (> 0,0005) bewerkt dat Gaussians over lange afstanden springen en de loss instabiel wordt; waarden duidelijk daaronder (< 0,00005) leiden ertoe dat verkeerd geïnitialiseerde puntenwolken nooit hun plek vinden. V414 testte een verdubbeling van de init-waarde → 16,8% slechtere L1-loss; de V544a-tunings bevestigden de paper-default als optimaal. Let op: bij .fullMCMC laten we deze waarde bewust op de default — MCMC heeft constante leerratio's nodig voor zijn relocation-logica, daarom brengt het tunen hier niets.
T4positionLearningRateFinal
DETAILS
Default: 0,0000016 (initializer + paper), 0,000016 (.full, .fullMCMC — 10× hoger) Range: 0 – Defined in:
TECHNISCH
Eindwaarde van de position-LR-cosine-annealing-curve. Bereikt wordt hij ofwel bij T1 maxIterations ofwel, indien gezet, bij T49 positionLRScheduleEndIteration. De RadianceKit-.full-voorinstelling gebruikt 0,000016 — dus 10× hoger dan de paper-default 0,0000016. V420-experimenten toonden dat 0,5× van de eindwaarde (0,000008) de loss met 6,4% verslechtert; V414 toonde dat 2× init-waarde hem met 16,8% verslechtert. De hoge eindwaarde is geen trade-off, maar bewuste keuze: bij te sterk verval verliezen de Gaussians tijdens de refinement-fase hun vermogen om zich op nieuw bijgekomen densification-kandidaten in te stellen. Via de V431/V433-uitbreiding kan de schedule-fase worden verkort (T49 < T1), zodat T4 al vóór het trainingseinde wordt bereikt en de rest van de training bij constante mini-LR loopt — typische configuratie: T49 = 20.000, T1 = 35.000, refinement dus op 0,000016 voor 15.000 iteraties.
T5shDCLearningRate
DETAILS
Default: 0,0025 (initializer + paper), 0,005 (.full en alle MCMC-voorinstellingen — 2×) Range: 0,0001 – 0,05 Defined in:
TECHNISCH
Adam-leerratio voor het DC-aandeel (degree 0, dus constante albedo) van de spherical-harmonic-kleur. SH-DC komt overeen met de richtingsonafhankelijke grondtoon van een Gaussian, in zekere zin de „basiskleur". De V176- en V188-experimenten vonden 2× hoger dan de paper-default optimaal — snellere kleur-convergentie, juist omdat bij korte training (, 5.000 iteraties) de SH-DC anders niet in vorm komt. Anders dan de geometrische LR's heeft SH-DC geen verval; de leerratio blijft over alle iteraties constant (of volgt slechts het optionele extended-phase-verval uit T51). V416 testte een verviervoudiging op 0,01 → 6,4% slechtere loss bij beta2=0,99-Adam.
T6shRestLearningRate
DETAILS
Default: 0,000125 (initializer + paper), 0,00025 (.full en MCMC — 2×) Range: 0,000001 – 0,005 Defined in:
TECHNISCH
Adam-leerratio voor de SH-coëfficiënten van hogere orde (degree 1, 2, 3 — dus de view-direction-afhankelijke kleurdelen die voor glanslichten, reflecties en zachte schaduw zorgen). 20× kleiner dan T5 per paper-conventie, omdat deze coëfficiënten kwadratisch in aantal groeien (3 voor degree 1, 5 voor degree 2, 7 voor degree 3 → in totaal 15 floats per Gaussian) en zonder kleinere leerratio het beeld zouden oververzadigen. Wordt in twee stappen vrijgegeven — tot het eerste merkpunt in T21 shDegreeUpgradeIterations is alleen degree 0 actief (dus alleen T5), daarna 1, later 2, ten slotte 3. Lage waarden hier zijn vooral belangrijk op scènes met veel diffuse belichting; bij zeer glanzende oppervlakken (autolak, water) loont draaien niet — de SH-representatie op zich is begrensd.
T7opacityLearningRate
DETAILS
Default: 0,05 (initializer + paper), 0,1 (.full, MCMC — 2×) Range: 0,001 – 1,0 Defined in:
TECHNISCH
Adam-leerratio voor de logit-opacity van elke Gaussian. De app slaat opacity op als onbegrensde float-waarde en transformeert hem met sigmoid in [0, 1]; de LR werkt in de logit-space. De paper-default 0,05 is na V50-tests (Best Single-Run L1 0,1664) hersteld, V71 revertete V67's 0,025. De V188-verdubbeling op 0,1 maakt het pruning efficiënter — dode Gaussians vallen sneller onder de T14 pruneOpacityThreshold. V418 toonde: 0,05 met beta2=0,99-Adam is 7,1% slechter dan 0,1 — de wisselwerking met de Adam-configuratie is niet triviaal. Lage waarden (< 0,01) leiden ertoe dat „dead" Gaussians eindeloos rondzwerven en geheugen verbruiken; te hoge waarden (> 0,5) kunnen tot opacity-explosion leiden, daarom wordt de logit-waarde in de optimizer op [-15, 3] geclampt (zie notitie „Opacity Explosion Prevention" in CLAUDE.md).
T8opacityLearningRateFinal
DETAILS
Default: 0,0 (= „geen verval") Range: 0 of 0,001 – Defined in:
TECHNISCH
Optioneel cosine-decay-eindwaarde voor de opacity-LR (V427). Wanneer 0,0, is decay gedeactiveerd en blijft de opacity-LR over de gehele training constant bij T7. V427 testte een decay 0,1 → 0,01 — resultaat 11,5% slechtere loss; reverted, vandaar de default „uit". De hypothese achter het veld: in de refinement-fase zou constante opacity-LR tot oscillatie kunnen leiden, zodat splats die al de juiste maat transparantie hebben bereikt, door willekeurige gradiënt-schommelingen weer worden verschoven. Empirisch bevestigt zich dat niet — de logit-clamping-logica vangt dat toch af. Het veld blijft beschikbaar voor toekomstige experimenten; ook zeer lange MCMC-runs (> 500K iteraties) zouden ervan kunnen profiteren.
T9scaleLearningRate
DETAILS
Default: 0,005 (initializer + paper), 0,01 (.full, MCMC — 2×) Range: 0,0001 – 0,1 Defined in:
TECHNISCH
Adam-leerratio voor de drie schaalcomponenten van elke Gaussian in de log-space (RadianceKit slaat log(scale) op, zodat schalen positief blijven). De paper-default 0,005, in RadianceKit verdubbeld op 0,01 voor betere scale-convergentie bij de geoptimaliseerde leerratio-configuraties. V423-experiment: 0,005 met beta2=0,99-Adam → 18,7% slechtere loss en zichtbaar te weinig Gaussians (density-control kon niet klonen, omdat de scale-updates te traag waren). Schaal stuurt de uitbreiding van elke Gaussian — te snel leren leidt tot „needle"-Gaussians (extreem lange dunne splats, zie T34 scaleRatioPruneThreshold), te traag leren laat splats te compact blijven en density-control moet te vaak splitsen.
T10rotationLearningRate
DETAILS
Default: 0,001 (initializer + paper), 0,002 (.full, MCMC — 2×) Range: 0,0001 – 0,05 Defined in:
TECHNISCH
Adam-leerratio voor de vier quaternion-componenten van elke Gaussian. De quaternion wordt in elke optimizer-stap na de Adam-update opnieuw genormaliseerd (L2-norm = 1) — anders zou de covariantiematrix gedegenereerd raken. RadianceKit verdubbelt de paper-default in de Quality-voorinstellingen, omdat rotation ten opzichte van scale / position kleinere absolute gradient-magnitudes heeft (op de eenheidssfeer blijft elke stap kort) en zonder 2× zou de rotation in het 35.000-iteratie-window duidelijk onder-geconvergeerd zijn. V188 gedocumenteerd. Op NeRF-Blender-scènes (Lego, Chair) werkt rotation bijzonder in — de randen van de objecten richten zich pas na 5.000–10.000 iteraties correct uit.
Densification — Classic (T11–T16)
T11densifyGradThreshold
DETAILS
Default: 0,000002 (initializer, gekalibreerd voor 0,5× resolutie), 0,0000011 (.full, gekalibreerd voor 1,0×), 0,000004 (.quickTest, gekalibreerd voor 0,25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (resolutie-afhankelijk) Defined in:
TECHNISCH
Drempelwaarde voor de L2-norm van de schermruimte-geprojecteerde gradiënt dMean2D, waarboven een Gaussian voor klonen of splitsen wordt gemarkeerd. De absolute waarde hangt direct af van de trainingsresolutie — dMean2D schaalt ongeveer als 1/resolutie² (meer pixels = kleinere per-pixel-gradiënten). Daarom heeft elke T22 trainingRenderScale-trap een gekalibreerde drempel nodig: 0,25× → 4e-6, 0,5× → 2e-6, 1,0× → 5e-8 … 1,1e-6 (.full). De paper-default 0,0002 is NDC-genormaliseerd en in RadianceKits wereld-ruimte-pipeline niet direct vergelijkbaar. Met de in V440 ingeschakelde T52 adaptiveDensifyThreshold-vlag kan de waarde tijdens runtime uit de p98 van de actuele gradiëntverdeling worden berekend — maar V440 testte dat op echte scènes en produceerde 63 K Gaussians (catastrofaal pruning-verlies); de vlag blijft uit. Q5 (T77–T79) levert een alternatieve adaptive-logica via rolling median. Gevaarloos is dit veld niet — halvering genereert 2–4× meer Gaussians (geheugendruk, OOM-risico); verdubbeling kan de scène onder-densificeren.
T12densifyFromIteration
DETAILS
Default: 500 Range: 100 – 5.000 Defined in:
TECHNISCH
Eerste iteratie vanaf waar densification actief wordt. Daarvoor gebeurt slechts „naakt" leren op de initiële SfM-puntenwolk, zonder dat nieuwe Gaussians worden gegenereerd. De default 500 komt uit het 3DGS-paper en geeft de initialisatie tijd om te stabiliseren — als al vanaf iteratie 0 wordt gedensificeerd, klonen verkeerd geplaatste SfM-punten zich veelvoudig voordat ze überhaupt hun juiste plek vinden. V349 testte 1000 → licht slechtere loss; de default is optimaal.
T13densifyInterval
DETAILS
Default: 100 (initializer, MCMC), 200 (.full) Range: 50 – 1.000 Defined in:
TECHNISCH
Hoeveel iteraties tussen twee densification-stappen liggen. In paper-default 100 — elke 100 iteraties wordt de lijst van densify-kandidaten geëvalueerd, geklond/gesplitst en tegelijk de lijst van prune-kandidaten (sigmoid(opacity) < T14 pruneOpacityThreshold) verwijderd. V112-tests vonden 200 als optimaal voor .full — dat ontlast de GPU, omdat minder reorganisatie-passes lopen, en geeft elke Gaussian meer tijd om zich na een kloon-actie te stabiliseren. V417 testte 100 met beta2=0,99 → 5,8% slechter (957 K Gaussians, overdensificatie). Bij MCMC wordt hetzelfde veld als relocation-interval geïnterpreteerd; zie T67 mcmcRelocationInterval voor de MCMC-specifieke logica.
T14pruneOpacityThreshold
DETAILS
Default: 0,005 (initializer, paper, MCMC), 0,001 (.full) Range: 0,0001 – 0,1 Defined in:
TECHNISCH
Sigmoid-opacity-drempel waaronder een Gaussian bij de volgende densification-step wordt verwijderd. Werkt samen met T7 opacityLearningRate en de logit-clamp-logica in de optimizer. V393 verlaagde de default van 0,005 naar 0,001 in .full — gevolg: splats die slechts onder exotische kijkhoeken een rol spelen, blijven langer behouden en dragen aan het SH-detail bij. V394 testte 0,0001 → licht slechter (te weinig geprunet, geheugen verspild). Belangrijk: density-control moet ALTIJD prunen, ook wanneer de buffer-capaciteit door andere maatregelen al vol is (zie „Density Control Must Always Prune" in CLAUDE.md) — anders accumuleren dode Gaussians en de count bevriest.
T15opacityResetInterval
DETAILS
Default: 3.000 (initializer + paper), 100.000 (.full = effectief gedeactiveerd), 200.000 (.fullMCMC = gedeactiveerd) Range: 1.000 – 100.000+ Defined in:
TECHNISCH
Elke hoeveel iteraties wordt de opacity van alle Gaussians teruggezet op een lage waarde (~0,01) — een maatregel uit het 3DGS-paper om „bevroren" splats opnieuw te beoordelen. V194 toonde dat met RadianceKits warmup + stochastic-trainings-setup + 2× leerratio's de opacity-reset 5,5% kwaliteit kost en de logit-clamp de reset-functie al afdekt. Vandaar in .full praktisch gedeactiveerd (100.000 > 35.000 = nooit getriggerd). V421 testte reset elke 3.000 met beta2=0,99 → 4,9% slechter; reverted. Bij .fullClassicPaper (Q1.5-A, paper-getrouwe test) is het bewust weer op 3.000 gezet — dat was een van de hefbomen waarmee de paper-magnitude-Gaussian-budgetten moesten worden bereikt.
T16maxScreenSize
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 (off) of > 0 Defined in:
TECHNISCH
Maximale schermruimte-grootte (in geprojecteerde pixels) die een Gaussian mag bereiken voordat ze gedwongen wordt gesplitst. De waarde is op 0 gezet (V48 testte en reverted) — RadianceKits density-control gebruikt in plaats daarvan de wereld-ruimte-schaal-drempel uit de dMean2D-logica. Blijft in de veldcatalogus opgenomen, omdat toekomstige experimenten met Mip-Splatting (T74–T76) of scènespecifieke splatting-strategieën ervan zouden kunnen profiteren. Activering (waarde > 0, bijv. 20) zou zeer groot geworden splats op het scherm dwingen zich te delen — relevant bij grote, gladde wandvlakken waar één enkel reuzensplat te weinig detail biedt.
Loss (T17–T20)
T17ssimWeight
DETAILS
Default: 0,2 (initializer + paper + .full), 0,05 (alle MCMC-voorinstellingen) Range: 0,0 – 1,0 Defined in:
TECHNISCH
Gewicht van het D-SSIM-aandeel in de gecombineerde loss-functie loss = (1 - λ) * L1 + λ * D-SSIM, waarbij λ = T17. De 3DGS-paper-default 0,2 is voor Classic-densification optimaal — V383 testte 0,3 → 28,9% slechter, V373b bevestigde 0,2 als sweet spot. Voor MCMC werd in V521b/V534 onafhankelijk vastgesteld: 0,05 is optimaal, omdat MCMC door zijn stochastische exploratie een sterker L1-signaal-aandeel nodig heeft — hogere SSIM-gewichten zouden de relocation-beslissingen verwateren. SSIM is duidelijk duurder te berekenen dan L1 (lokale 11×11-windows over het hele beeld); RadianceKit gebruikt een MPS-versnelde implementatie die onder 1 ms per 1080p-beeld blijft. Q7-BayesOpt-sweeps vonden scènespecifieke optima tussen 0,05 (.outdoorPreset: 0,082) en 0,171 (.indoorPreset).
T18ssimWeightRefinement
DETAILS
Default: 0,0 (= „geen wissel, behoud ssimWeight") Range: 0 of 0 – 1,0 Defined in:
TECHNISCH
Optionele SSIM-waarde voor de refinement-fase na T2 densifyUntilIteration. V428 testte 0,2 → 0,3 in refinement → 16% slechtere loss (zowel L1 als SSIM verslechterden); reverted, vandaar default 0,0. De hypothese achter het veld was dat na de densification — wanneer geen nieuwe Gaussians meer ontstaan — een sterker SSIM-aandeel de structurele scherpte zou maximaliseren. Empirisch onjuist: SSIM-gewicht verhogen betekent indirect L1-gewicht verlagen, en L1 is het duidelijk veelzeggendere signaal in de finale-refinement-fase. Het veld blijft beschikbaar voor toekomstige experimenten met perceptual loss (T60) of edge-loss (T19), waar een refinement-specifieke loss-compositie zinvol zou kunnen zijn.
T19edgeLossWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,001 – 1,0 Defined in:
TECHNISCH
V437-experimenteel-loss: gewicht van een Sobel-gradient-domain-L1-loss die de beeldranden direct vergelijkt (ground-truth-Sobel vs render-Sobel) aanvullend op L1+SSIM. Hypothese: randinformatie is een perceptuele hoeksteen van beeldkwaliteit en een expliciete term zou Gaussians moeten aanmoedigen om randen beter te treffen. Testresultaten: gewicht 0,1 → 11% slechtere loss, 0,01 → quality-neutraal maar 10% langzamer. De Sobel-pass kost een extra MPS-forward op ground-truth en render. Vandaar permanent gedeactiveerd. Toekomstige use-case: scènes met harde kunstmatige randen (architectuur, meubilair, renderings) zouden kunnen profiteren — Q7-scene-class-voorinstellingen hebben dat echter niet gepickt, maar in plaats daarvan het SSIM-gewicht geschaald.
T20skyMaskingEnabled
DETAILS
Default: false (initializer en alle voorinstellingen) Range: boolean Defined in:
TECHNISCH
Schakelt sky masking in. Daarbij wordt in elk beeld via Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest) de sky-regio uitgemaskeerd, en de loss in dit gebied op nul gezet. Doel: outdoor-scènes lijden vaak eraan dat blauwe/grijze/witte sky-pixels de app ertoe brengen Gaussians precies daar te plaatsen — wat als „floater" wordt waargenomen. Zonder sky-mask zou de loss in dit gebied nooit nul zijn, omdat de hemel in het beeld licht varieert en de app eindeloos probeert dat met splats na te bouwen. De vision-mask wordt eenmaal per camera vóór de training berekend en in RAM gehouden. Wordt typisch samen met T45 skyDomeEnabled geactiveerd (UI-logica in de settings-view). Bij binnenscènes of synthetische renderings gedeactiveerd laten — de mask zou daar ten onrechte plafonds of muren als „sky" herkennen.
SH-graad-progressie (T21)
T21shDegreeUpgradeIterations
DETAILS
Default: [1_000, 2_000, 3_000] (initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — degree 3 overgeslagen) Range: [Int], elke waarde in [0, maxIterations], monotoon stijgend Defined in:
TECHNISCH
Iteraties waarop de actieve SH-graad van 0→1, 1→2, 2→3 wordt opgeschakeld. Vóór het eerste merkpunt zijn alleen de DC-componenten actief (dus T5 shDCLearningRate), na het eerste merkpunt de DC + 3 degree-1-coëfficiënten, na het tweede merkpunt + 5 degree-2-coëfficiënten, na het derde merkpunt alle 15 coëfficiënten. De geheugenbehoefte per Gaussian groeit daarbij in stappen — 4 floats → 16 floats → 36 floats → 64 floats. De Quality-voorinstellingen vertragen de upgrades ten opzichte van initializer-defaults (V228), omdat de geometrie eerst moet stabiliseren voordat de kleurdetails met hun hogere frequentie erop komen. V384 testte [1K, 2K, 3K] voor .full → 9,3% slechter — bevestigt de vertraging. .preview kapt bij degree 2, omdat degree 3 in 5.000 iteraties niet convergeert en alleen optimizer-capaciteit verbruikt. Q6 (T80–T81) biedt een alternatieve curriculum-logica die deze lijst dynamisch overschrijft.
Performance (T22–T25)
T22trainingRenderScale
DETAILS
Default: 1,0 (initializer, .full, MCMC, scene-class), 0,5 (.preview), 0,25 (.quickTest) Range: 0,05 – 2,0 (typisch 0,25, 0,5, 1,0) Defined in:
TECHNISCH
Renderresolutie bij de training relatief aan de originele resolutie van de trainingsbeelden. Bij 0,5 wordt elk beeld op 50% breedte × 50% hoogte herrekend (dus 25% van de pixels) en de Gaussian-rendering vindt plaats in deze kleinere resolutie. Reduceert zowel geheugen- als rekenkosten kwadratisch. Belangrijk: T11 densifyGradThreshold moet bij de gekozen resolutie passen — de gradient-magnitudes schalen met 1/resolutie², daarom heeft .quickTest (0,25×) een veel hogere drempel (4e-6) dan .full (1,0×, 1,1e-6). RadianceKit waarschuwt bij zeer grote beelden en past automatisch aan — 3-MP-doelresolutie. Bij extreme 4K-invoerbeelden zou 0,5 of zelfs 0,25 zinvol zijn, anders loopt elke Mac ook alleen in CPU-compaction.
T23resolutionWarmupScale
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,1 – Defined in:
TECHNISCH
V133-optimalisatie: train de densification-fase (iter 0 tot T2) in een lagere resolutie dan de refinement-fase. V308 heeft hem voor .full weer uitgeschakeld, omdat bij T22 = 1,0 en cosine-annealing de time-win marginaal was en kwaliteit minimaal leed. Blijft in de veldcatalogus, omdat hij bij 4K-invoer en lange trainingsruns weer zinvol zou kunnen worden — Q6 Curriculum (T80) heeft een vergelijkbare logica overgenomen, daar is hij echter aan de LR-schedule gekoppeld. Wanneer geactiveerd en T80 curriculumResolutionRamp eveneens true, wint Q6 en overschrijft deze waarde.
T24tileSize
DETAILS
Default: 16 Range: 8, 16, 32 Defined in:
TECHNISCH
Grootte van de rasterisatie-tiles in pixels. De Gaussian-Splatting-rendering is tile-gebaseerd: het beeld wordt in 16×16-pixel-tegels opgedeeld, elke tegel verzamelt de voor haar relevante Gaussians, sorteert ze op diepte en blendt ze in. 16 is de door vrijwel alle 3DGS-implementaties gebruikte standaard en in de RadianceKit-Metal-kernels hardgecodeerd; een wijziging van deze waarde zou recompilatie van de shaders eisen en is in de huidige stand niet effectief. Blijft als veld, mocht een toekomstige engine-versie tile-size dynamisch ondersteunen.
T25throttleDelayMs
DETAILS
Default: 0 (initializer, .full, MCMC, scene-class), 0 (.preview) Range: 0 – 100 Defined in:
TECHNISCH
Kunstmatige vertraging tussen trainingsiteraties in milliseconden. 0 = volle snelheid (standaard). Hogere waarden maken de Mac tijdens de training „bruikbaarder", doordat GPU/CPU regelmatig ademruimte krijgen — de bedieningsgemak van andere apps stijgt, de trainingstijd echter lineair met de vertraging. Typische waarden: 1–2 ms („licht" throttling, +5% trainingstijd, Mac voelt responsiever aan), 5 ms („middelzwaar", +15% trainingstijd), 10+ ms („Eco", potentieel dubbele trainingstijd). Wordt in de Inspector onder „performance" geboden, is echter niet in de standaardweergave — zie backlog dev_ux-backlog.md die voorstelt hem uit de Expert View te verwijderen, omdat verkeerd begrepen hij de trainingstijd dramatisch verlengt.
Diagnose en puntenwolk-voorbereiding (T26–T30)
T26depthDistortionWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,0001 – 0,05 Defined in:
TECHNISCH
V366-experimenteel: gewicht van een depth-distortion-regularisatie-loss. Bestraft Gaussians die langs een render-straal weliswaar diep gestaffeld zijn, maar conceptueel tot hetzelfde oppervlak behoren — dat moedigt geconcentreerde diepteverdelingen aan en reduceert floaters. Tests: 0,01 → 4,5% slechter, 0,001 → 8,1% slechter. Het theoretische voordeel — multi-view-consistentie verbeteren — slaat zich niet in de L1-loss neer, omdat de hypothese impliciet aanneemt dat de SfM-geometrie correct is en de Gaussians alleen „gestapeld" moeten worden. In de praktijk is de SfM-puntenwolk meestal de zwakste component, niet de stapeling. Blijft beschikbaar voor multi-view-datasets met bijzonder schone poses (synthetic, Mip-NeRF 360 met ground truth).
T27singleViewOverfit
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Diagnose-vlag: wanneer true, wordt in elke trainingsiteratie verplicht camera-index 0 gebruikt in plaats van een willekeurig uit de camera-pool. Doel: wanneer het model niet eens één enkele view kan overfitten (sprich, de loss op view 0 ook na 10.000 iteraties niet tegen nul gaat), is in de forward/backward-pass een fundamentele bug. Deze schakelaar werd tijdens de ontwikkeling van de Metal-shaders en de differentiable-rasterizer-kernels intensief gebruikt — V42–V47-fase. Vandaag alleen nog als sanity check beschikbaar wanneer iemand backend-code heeft gewijzigd en een regression test wil doen. Via CLI met –single-view.
T28maxCameras
DETAILS
Default: 0 (= „alle camera's gebruiken") Range: 0 of 1 – N Defined in:
TECHNISCH
Diagnose-limiet uit V43: train alleen met de eerste N camera's, negeer alle andere. Doel oorspronkelijk: hypothese testen dat te veel camera's gradient-conflicten genereren (te veel tegenstrijdige loss-signalen voor dezelfde Gaussian). Testresultaat: geen systematisch voordeel bij kunstmatige beperking — meer-frames brengen praktisch altijd meer kwaliteit. Blijft als CLI-flag (–max-cameras N) voor gerichte experimenten, bijv. „werkt de training op de eerste 100 beelden van een 1.500-beelds-dronevlucht?" In de UI niet geëxposeerd.
T29maxInitialPoints
DETAILS
Default: 0 (= „alle SfM-punten gebruiken") Range: 0 of 1.000 – 200.000+ Defined in:
TECHNISCH
V54-beveiliging: limiteert het aantal initiële SfM-punten waarmee de training start. Dichte COLMAP-reconstructies kunnen > 60.000 punten produceren, wat bij grote initial-schalen tot 200–300 Gaussians per pixel-overlap leidt — dat maakt een „nevelveld" waarin de training niet convergeert. Subsampling op ~16.000 punten (hard-cap-logica in de trainings-engine) brengt de initial-dichtheid op het niveau dat het referentie-3DGS gebruikt, en reduceert overlap dramatisch. Wordt bij zeer dichte SfM's automatisch ingesteld; via CLI met –max-points N.
T30cameraClusterOutlierMultiplier
DETAILS
Default: 10,0 (alle voorinstellingen — nooit overschreven) Range: 1,0 – 100,0 Defined in:
TECHNISCH
Multiplicator voor het camera-cluster-outlier-filter, ingevoerd in fase 3.10 A.1. Vóór de training berekent de trainings-engine het centroid van alle cameraposities en de maximale afstand van een camera tot het centroid. SfM-punten waarvan de afstand tot het centroid multiplier × maxCameraDistance overschrijdt, worden als outlier verworpen. Default 10× bewaart het gedrag van vóór fase 3.10. Een subtiele bug: tighter SfM (camera's dichter bij elkaar) → kleiner → kleinere drempel → meer punten worden als outlier verworpen. Looser SfM → grotere drempel → minder punten verworpen. Dit is een van de oorzaken van de fase-3.9-funnel-vs-training-anti-correlatie: betere SfM kan downstream tot slechtere training leiden, omdat te veel initial-punten worden gekild. Het veld ligt als CLI-override (–camera-cluster-outlier-multiplier) voor de A.3-sweeps; in de UI niet geëxposeerd. Waarden onder 5 zijn over het algemeen te restrictief, boven 20 zonder effect.
Regularisatie (T31–T37)
T31coarseToFineBlurRadius
DETAILS
Default: 0 (= gedeactiveerd) Range: 0 of 1 – 10 Defined in:
TECHNISCH
V369-experimenteel: box-blur-radius die aan het begin van de densification-fase op het ground-truth-beeld wordt toegepast en lineair tot het einde van de densification (T2) op 0 wordt verminderd. Hypothese: coarse-to-fine-training — eerst grove structuren leren, dan details — zou stabielere geometrie moeten leveren. Tests: r=3 → 9,6% slechter, r=1 → 5,1% slechter. De reden voor het mislukken: de densification beslist op basis van beelddomein-gradiënten, en bluren reduceert juist de signalen die voor „hier moet geklond worden" belangrijk zijn. Blijft in de veldcatalogus voor toekomstige tests met ander density-control-schema.
T32scaleRegWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,0001 – 0,05 Defined in:
TECHNISCH
V370-experimenteel: L1-regularisatie op wereld-ruimtelijke schaal. Bestraft Gaussians die te groot worden — voorkomt „mega-splats" die hele wandvlakken met één Gaussian afdekken. Tests: 0,01 → 200% slechtere loss (2 M Gaussians, totale explosie), 0,001 → 214% slechter. De reden: scale-regularisatie komt met density-control in conflict — kleinere schalen betekenen, meer Gaussians worden nodig, dus splitst density-control vaker, wat op zijn beurt meer gradiëntinspanning betekent. Disabled, maar gedocumenteerd voor Mip-Splatting-experimenten (T74): in deze context zou een schaal-ondergrens zinvol kunnen zijn.
T33anisotropyRegWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,0001 – 0,05 Defined in:
TECHNISCH
V445-experimenteel: penalty op de max(scale)/min(scale)-verhouding, moet extreem langgerekte „needle"-Gaussians voorkomen die als floater worden waargenomen. Tests: 0,01 → 69% slechter, 0,001 → 15% slechter. De reden: regularisatie dwingt splats richting „ronde" vorm, wat op een vlak oppervlak (muur, tafel, vloer) precies verkeerd is — daar is een vlakke, brede Gaussian efficiënter dan een bolvormige. Disabled. V549f bood met T34 scaleRatioPruneThreshold een alternatieve, gerichtere benadering die eveneens werd reverted.
T34scaleRatioPruneThreshold
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 5,0 – 100,0 (typisch 10,0 – 30,0) Defined in:
TECHNISCH
Experimenteel post-training-pruning dat elke Gaussian verwijdert waarvan de max(scale)/min(scale)-verhouding de hier ingestelde lineaire drempel overschrijdt. Doelt op extreem langgerekte „needle/disc"-floaters die door regularisatie alleen niet kunnen worden geëlimineerd. In de test verwijderde het pruning floaters zoals gehoopt, maar tegelijk ook zinvolle vlakke splats op muren en vloeren — het beeld werd gatiger. Vandaar standaard uit, de CLI-flag (–scale-ratio-prune N) blijft voor gerichte experimenten beschikbaar. Aanbevolen waarden mocht men het toch willen testen: 30 (zeer conservatief, verwijdert alleen extreme outliers), 10 (agressief, kost detail).
T35opacityRegWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,0001 – 0,05 Defined in:
TECHNISCH
V446-experimenteel: binary-cross-entropy-penalty die opacity tegen 0 of 1 trekt (dus weg van „half-transparant"). Hypothese: scherpere opacity-verdeling zou beeldhelderheid verbeteren. Test met T33 gecombineerd → regularisatie kost kwaliteit, beide gedeactiveerd. Disabled. Let op: in 1.4.3-beta dook een bug op die juist dit veld in een default-waarde-wijziging (initializer = 0,01) had, wat tot mass-extinction van het Gaussian-aantal (460 K → 5 in één iteratie) leidde. Sinds 1.4.4 vast op 0,0 als default verankerd.
T36opacityDecayFactor
DETAILS
Default: 0,0 (initializer = gedeactiveerd), 0,9995 (.full, .classicBalanced — HTGS-standaard) Range: 0 (off) of 0,95 – 1,0 Defined in:
TECHNISCH
V546-implementatie van het HTGS-schema (hiërarchische time-gating, Eurographics 2025): elke T37 opacityDecayInterval iteraties wordt de sigmoid-opacity van elke Gaussian met deze factor vermenigvuldigd. 0,9995 × 100 toepassingen levert ~95%-verblijf per densification-fase — een lichte maar gestage neerwaartse druk op alle opacities, die zwak bijdragende Gaussians betrouwbaar tegen de T14 pruneOpacityThreshold laat zakken. Het resultaat: 14% betere L1-loss op Horse Full (3-trial-avg V546) ten opzichte van V438 zonder verval. Alleen tijdens densification-fase actief (tot T2), daarna loopt de training zonder verval verder, zodat de in refinement gevestigde opacities stabiel blijven. Bij MCMC niet gebruikt (MCMC heeft eigen mechanismen via T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETAILS
Default: 50 Range: 10 – 500 Defined in:
TECHNISCH
Iteratie-interval waarin T36 opacityDecayFactor wordt toegepast. HTGS-paper-default 50, in .full gelaten. Lange intervallen (>200) heffen het effect deels op, omdat tussen twee toepassingen genoeg gradient-updates plaatsvinden, dat opacity weer stijgt. Kortere intervallen (<20) maken decay te agressief. Alleen in densification-fase actief.
Refinement (T38–T44)
T38gradientAccumulationSteps
DETAILS
Default: 1 (= „één view per Adam-stap") Range: 1 – 8 Defined in:
TECHNISCH
V424-feature: aantal views waarvan de gradiënten worden geaccumuleerd voordat een Adam-update wordt uitgevoerd. Bij > 1 loopt de app op een apart, „unfused" backward-project-pad dat de gradiënten in een aparte buffer optelt; de finale toepassing schaalt met 1/N om de magnitude constant te houden. V424 testte 2-view → kwaliteit-neutraal, maar 10% langzamer (omdat unfused-pad duurder is dan fused-pad). Reverted voor .full, maar voor MCMC bewust gebruikt — .fullMCMC loopt met, maar V544a-tests toonden dat met de quality-gap tot Classic op 5% slinkt (in plaats van 11%). In initializer-default 1, in de actuele voorinstelling 1, blijft CLI-flag (–accum-steps N).
T39testViewIndices
DETAILS
Default: [] (= leeg, alle views worden voor training gebruikt) Range: Set<Int>, willekeurige deelverzameling van de camera-indices Defined in:
TECHNISCH
V546-feature: set van camera-indices die NIET voor training worden gebruikt, maar als holdout voor PSNR/SSIM/LPIPS-analyse worden gespaard. Wordt automatisch ingesteld wanneer de –benchmark-CLI-flag actief is: dan elke achtste view, beginnend bij index 0 (LLFF-standaard, identiek aan de Mip-NeRF-360- en 3DGS-paper-conventies). Zonder benchmark leeg — de training gebruikt alle views. Voorzichtig: het handmatig instellen van dit veld zonder begrip van de indices kan de benchmark onbruikbaar maken (bijv. wanneer alle indices boven N worden gezet, terwijl er slechts N-50 views zijn → geen holdouts → geen analyse). Bij eigen voorinstelling-export wordt testViewIndices niet gepersisteerd, omdat het scène-afhankelijk is en anders tussen verschillende datasets zinloze waarden zou achterlaten.
T40refinementPruneInterval
DETAILS
Default: 0 (= gedeactiveerd) Range: 0 of 100 – 5.000 Defined in:
TECHNISCH
V425-feature: elke N iteraties tijdens de refinement-fase (na T2) wordt een extra prune-pass laten lopen die Gaussians met sigmoid(opacity) < T41 refinementPruneOpacityThreshold verwijdert. Doel: tijdens densification zijn er regelmatige density-control-calls, daarna niet meer — Gaussians waarvan opacity verder zakt, blijven echter in de buffer. V425 testte en reverted: het extra pruning correleerde met V426 (two-phase densification, eveneens in 0-Gaussians-cascade-failure afgebroken). Disabled. CLI-flag beschikbaar voor experimenten; mocht geactiveerd, zijn 1.000 of 2.000 zinvolle waarden.
T41refinementPruneOpacityThreshold
DETAILS
Default: 0,0 (= „gebruik T14") Range: 0 of 0,001 – 0,1 Defined in:
TECHNISCH
V425b: aparte opacity-drempel voor refinement-pruning. Na densification hebben de meeste Gaussians een duidelijk hogere opacity bereikt (> 0,001), zodat de standaard-T14 pruneOpacityThreshold te slap zou zijn. Wanneer T40 actief, bepaalt dit veld de eigen drempel. Bij 0,0 wordt T14 verder gebruikt. Alleen relevant wanneer T40 > 0.
T42midTrainingCompactificationIterations
DETAILS
Default: [] (= gedeactiveerd) Range: [Int], waarden in (densifyUntilIteration, maxIterations) Defined in:
TECHNISCH
V549-feature: expliciete iteratie-punten tijdens de refinement-fase waarop een compactification-pass loopt (verwijdert sigmoid(opacity) < 0,01 + outlier-scale-Gaussians, dezelfde logica als T56 postTrainingCompactification). Doel: lange refinement-fasen kunnen confetti-/floater-accumulatie tonen waarvan SH dan op view-specifieke artefacten overfit. Typische configuratie mocht geactiveerd: [10000, 20000, 30000] voor 40K Classic. MAAR: V549-A/B-tests op family-dataset toonden in alle configuraties slechtere L1: [10K,20K,30K]@0.01 → −48% count maar +36% L1; [20K,30K]@0.005 → −44% count maar +45% L1; [20K,30K]@0.001 → −17% count maar +87% L1. Vandaar disabled. CLI-flag –mid-compact "10000,20000" beschikbaar mocht men de visuele floater-tradeoff (minder confetti in viewport) verkiezen boven de loss-regressie.
T43frustumCullEnabled
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V549b-feature: na training worden alle Gaussians verwijderd die buiten de vereniging van alle trainings-camera-frusta liggen. Zulke Gaussians werden nooit door het loss-signaal beperkt en zijn altijd floaters. Bijzonder effectief voor scènes waarin de novel-view achter of naast het camerapad ligt (bijv. achterzijde van een lineaire dronevlucht) — de floaters daar worden in de trainingsfase nooit zichtbaar, bij later bewegen in de 3D-viewer echter wel. V549b A/B op dronevluchten positieve resultaten, vandaar als opt-in beschikbaar. Default false, omdat bij object-captures met volle orbit-coverage de frustum-vereniging de hele scène omvat en de feature niets verwijdert — wordt in instellingen onder „floater reduction" geboden en ook in Q9 Outdoor-voorinstelling impliciet via T44 frustumCullExpansion getest (Q7-BayesOpt heeft het echter niet geactiveerd, omdat outdoor-sky-dome hetzelfde probleem beter oplost).
T44frustumCullExpansion
DETAILS
Default: 1,1 Range: 1,0 – 2,0 Defined in:
TECHNISCH
NDC-marge voor T43 frustumCullEnabled. 1,0 zou exact aan de beeldrand snijden, wat wankele splats aan de beeldrand te zeer zou kappen. 1,1 = 10% padding boven de exacte camera-framing uit — geeft wat tolerantie voor randpixels die in een licht verschoven novel-view toch zichtbaar zouden kunnen worden. Waarden > 1,2 maken de cull praktisch onwerkzaam, omdat het uitgebreide frustum veel meer ruimte omvat.
Sky-Dome (T45–T48)
T45skyDomeEnabled
DETAILS
Default: false (initializer + alle voorinstellingen behalve P9 Outdoor) Range: boolean Defined in:
TECHNISCH
V549e-feature: vóór trainingstart wordt een bolvormige puntenwolk gegenereerd (Fibonacci-sphere met T46 sample-points), in een radius van T47 skyDomeRadiusMultiplier × scene_extent om het scènecentrum geplaatst en met de kleuren uit de sky-gemaskeerde pixels van alle trainings-camera's (zie T20 skyMaskingEnabled) geïnitialiseerd. Deze sky-dome-Gaussians worden aan het begin van de Gaussian-buffer ingevoegd en tijdens training „bevroren" (positie/scale/rotation-gradiënten = 0, alleen SH en opacity blijven optimaliseerbaar). Effect: in plaats van zwarte „confetti"-gebieden in de verte ziet de gebruiker in novel-views een echte hemel. V549e-MVP werkt op drone- en landschapsscènes zeer goed; in P9 Outdoor-voorinstelling default-on. Bij binnenscènes uit laten — de sphere zou zinloos buiten de ruimte hangen.
T46skyDomeSampleCount
DETAILS
Default: 5.000 Range: 1.000 – 50.000 (typisch 2.000 – 10.000) Defined in:
TECHNISCH
Aantal Fibonacci-sphere-sample-punten op de sky-dome-sphere. Hogere waarden → dichtere sky-dome (beter bij grote resoluties en veel zichtbare hemel), maar meer geheugengebruik. 5.000 is sweet spot voor 4K-renderings; bij lagere resoluties volstaat 2.000–3.000. De punten worden op cosine-distance tot elke training-camera-view-vector met de respectieve sky-gemaskeerde pixels geïnitialiseerd — sample-points waarvan de view-cone geen camera ziet, blijven met lage opacity-initiële waarde achter, worden echter in de training niet gewijzigd (bevroren).
T47skyDomeRadiusMultiplier
DETAILS
Default: 30,0 (initializer + meeste voorinstellingen), 59,0 (P9 Outdoor, Q7-BayesOpt-optimum) Range: 5,0 – 200,0 Defined in:
TECHNISCH
Radius van de sky-dome-sphere relatief tot de scène-uitbreiding (= gemiddelde afstand tussen cameraposities). 30 = de bol heeft de 30-voudige diameter van de camera-wolk. Te klein (< 5) → sky-dome interfereert met de scène zelf (bijv. een sky-dome-splat landt in de voorgrond); te groot (> 100) → float32-precisieverlies op de sky-dome-posities, wat render-glitches in de verte uitlokt. Q7-BayesOpt op Bicycle (Mip-NeRF 360) vond 59,0 als scènespecifiek optimum voor outdoor — dat duidt erop dat de standaard 30,0 voor diepe landschappen te klein is en de sky-dome-pixels in de beeldrandgebieden zichtbaar als „muur" renderen.
T48frozenGaussianCount
DETAILS
Default: 0 (= geen bevroren Gaussians) Range: 0 of 1 – T46 Defined in:
TECHNISCH
Aantal Gaussians aan het begin van de buffer waarvan positie/scale/rotation-gradiënten in de optimizer op nul worden gezet — ze blijven over de gehele training ruimtelijk star. Density-control mag ze niet klonen, splitsen of prunen. Gebruikt voor sky-dome-injection (zie T45): wanneer sky-dome aan is, wordt dit veld automatisch op T46 skyDomeSampleCount ingesteld. Handmatig instellen is mogelijk (bijv. om een vooraf geplaatste puntenwolk uit een LiDAR-scan te bevriezen), maar in de UI niet direct toegankelijk. Belangrijk: de eerste N Gaussians in de buffer zijn altijd de bevroren — de volgorde in de buffer beslist, niet een expliciete index.
Adam + LR-schedule (T49–T55)
T49adamResetIteration
DETAILS
Default: 0 (= gedeactiveerd) Range: 0 of 100 – Defined in:
TECHNISCH
V430-feature: iteratie waarop de Adam-optimizer-momentum-accumulatoren (m1, m2) op nul worden teruggezet. Bias-correctie daarna loopt met (iter - adamResetIteration) in plaats van met iter. V430 testte reset bij 5.000 (na densification-einde) → 12,8% slechtere loss. Reden: het Adam-momentum dat zich tijdens densification heeft opgebouwd, draagt informatie over de typische gradient-magnitudes bij en versnelt de refinement-fase. Het weggooien kost de eerste ~500 iteraties refinement aan convergentie. Disabled. Blijft CLI-flag voor onderzoeksexperimenten.
T50positionLRScheduleEndIteration
DETAILS
Default: 0 (initializer = „gebruik maxIterations"), 20.000 (.full — cosine eindigt bij 20K ondanks maxIter=35K), 30.000 (.fullClassicPaper) Range: 0 of 1.000 – Defined in:
TECHNISCH
V431-feature: iteratie waarop de cosine-annealing-curve voor position-LR zijn minimum bereikt. Wanneer 0, is dat identiek aan T1 maxIterations. Wanneer > 0, loopt de schedule tot deze waarde en blijft daarna bij T4 positionLearningRateFinal constant. Dat staat een „extended refinement phase" met minimale maar constante leerratio toe — verfijnt posities langzaam zonder nieuw verval. .full doet dat (schedule-einde bij 20K, training loopt tot 35K), V434c/V434d bevestigden: 15K en 25K beide ongeveer gelijk, 20K minimaal optimaal. Wordt in combinatie met T51 verder gebruikt om ook de niet-position-LR's in de extended phase te wijzigen.
T51extendedPhaseLRDecay
DETAILS
Default: 0,0 (= gedeactiveerd, constante LR's) Range: 0 of 0,01 – 1,0 Defined in:
TECHNISCH
V433-feature: minimale multiplicator voor de niet-position-LR's (scale, rotation, opacity, SH) in de „extended phase" — d.w.z.: nadat T50 is bereikt en position-LR al bij T4 is. Wanneer 0,1, worden scale/rotation/opacity/SH op hun beurt cosine-decayed van 1,0 (= hun standaard-LR) naar 0,1× van hun standaard. Wanneer 0,0 (default), blijven ze constant. V457 testte volle verval (0,0 = decay-tot-nul) tegen geen-verval en vond: avg 0,0400 (2 runs) = zelfde loss als V438 zonder verval. Gedrag schoner met verval, maar niet meetbaar beter. Vandaar disabled. Blijft in de CLI als –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V440-experimenteel: wanneer true, berekent de app in elke densification-stap de p98 van de actuele gradiëntverdeling en gebruikt het als dynamische drempel (geclampt op minstens 0,5× van de geconfigureerde waarde uit T11, zodat het niet te veel uitwijkt). Hypothese: automatische aanpassing aan actuele scènefase zou density-control robuuster maken — bijv. aan het begin strenger pruning, later slapper, of omgekeerd. V440 testte en revertete: catastrofale drop tot 63 K Gaussians (mass-pruning, omdat de p98 in de eerste iteraties extreem hoog is en dan vrijwel niets de drempel overschrijdt). De vaste drempel is al goed gekalibreerd, dynamische aanpassing schaadt meer dan ze nut heeft. Q5 (T77) biedt een alternatieve adaptive-logica via rolling median die het probleem omzeilt.
T53mergeAfterDensification
DETAILS
Default: false (initializer), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Defined in:
TECHNISCH
V438-feature: aan het einde van de densification-fase (iter T2) wordt een eenmalige merge-pass uitgevoerd die dicht bij elkaar liggende Gaussians met vergelijkbare scale en kleur samenvoegt. Reduceert het Gaussian-aantal met typisch 5–15% zonder zichtbaar kwaliteitsverlies. Doel: na intensief klonen ontstaan clusters van quasi-identieke Gaussians die niets nieuws bijdragen — het merging geeft optimizer-capaciteit voor andere gebieden vrij. Standaard in Classic-Quality-voorinstellingen. Bij MCMC niet gebruikt, omdat MCMC door zijn relocation-logica zulke clusters helemaal niet laat ontstaan.
T54densifyPhase2FromIteration
DETAILS
Default: 0 (= gedeactiveerd) Range: 0 of T2 – T1 Defined in:
TECHNISCH
V426-experimenteel: maakt een tweede densification-fase mogelijk die na de refinement-pauze bij deze iteratie start en tot T55 loopt. Hypothese: na een refinement-fase hebben de gradient-accumulatoren stabielere magnitudes en kunnen preciezer zeggen welke gebieden nog extra Gaussians nodig hebben. V426 testte en revertete: two-phase densification viel in 0-Gaussians-cascade-failure (met V425 refinement-pruning gecombineerd vernietigde het de buffer). Disabled. CLI-flag beschikbaar voor experimenten.
T55densifyPhase2UntilIteration
DETAILS
Default: 0 Range: 0 of T54 – T1 Defined in:
TECHNISCH
Einde van de V426-two-phase-densification. Alleen relevant wanneer T54 > 0. Beide velden samen disabled.
Post-processing + Apple AI (T56–T60)
T56postTrainingCompactification
DETAILS
Default: true (in alle production-voorinstellingen), false (.quickTest, .preview) Range: boolean Defined in:
TECHNISCH
V443-feature: na trainingseinde worden Gaussians met sigmoid(opacity) < 0,01 hard verwijderd (ze dragen praktisch niet meer bij aan het beeld). Reduceert Gaussian-count met typisch 58% en export-bestandsgrootte met 55% zonder zichtbaar kwaliteitsverlies. Standaard in production-voorinstellingen actief — het eindresultaat moet zo compact mogelijk kunnen worden uitgeleverd. In .quickTest uit, omdat een diagnose-run sowieso niet wordt geëxporteerd. Anders dan T42 midTrainingCompactificationIterations (V549) vindt de compactification pas aan het einde plaats — refinement kan tot dan alle Gaussians gebruiken.
T57metalFXUpscaling
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V444-feature: activeert Apple's MetalFX Spatial Upscaler in plaats van bilineaire interpolatie in de 3D-viewer-output. Wanneer trainingsresolutie < viewport-grootte (bijv. training op 0,5×, viewport-weergave in volle resolutie), kan MetalFX een duidelijk scherper beeld leveren. Verandert live in het viewport, geen retraining nodig. Sluit zich met T58 mpsLanczosScaling uit — MetalFX heeft voorrang. Aanbeveling: inschakelen wanneer het beeld in de viewer „wazig" oogt ten opzichte van het verwachte detail.
T58mpsLanczosScaling
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V444-feature: MPSImageLanczosScale voor viewport-schaling in plaats van bilineaire interpolatie. Lanczos is een klassiek sinc-gebaseerd resampling-procedé dat duidelijk scherpere resultaten dan bilineair levert met minimale overhead. Live-toggle. Wordt door T57 overschreven wanneer beide aan.
T59livePreviewInterval
DETAILS
Default: 50 (initializer en meeste voorinstellingen) Range: 0 (off) of 10 – 5.000 Defined in:
TECHNISCH
Hoe vaak tijdens de training de 3D-viewer met de actuele Gaussians wordt geactualiseerd. 50 = elke 50 iteraties een nieuwe render in de viewer — goed genoeg om de voortgang te observeren zonder de training te vertragen. 0 = viewer wordt helemaal niet geactualiseerd (achtergrond-training, max snelheid). Typische aanpassing: bij .quickTest omlaag naar 10 (men wil elke stap zien), bij lange MCMC-runs hoog naar 500–2000 (update-overhead in totaal merkbaar).
T60perceptualLossWeight
DETAILS
Default: 0,0 (= gedeactiveerd) Range: 0 of 0,001 – 0,5 Defined in:
TECHNISCH
V444-future-feature: gewicht van een perceptueel loss-term via MPSGraph (VGG-achtig klein netwerk). Zou structurele en texturele gelijkenis op een hoger semantisch niveau dan L1+SSIM erkennen — typisch in onderzoekspipelines waar „pixel-perfect" minder belangrijk is dan „ziet er realistisch uit". Implementatie nog uitstaand (code-stub aanwezig, maar forward-pass niet geïmplementeerd). Default 0,0. Blijft in de veldcatalogus voor toekomstige activering; CLI-flag –percep-weight F gereserveerd.
MCMC-densification (T61–T73)
T61densificationStrategy
DETAILS
Default: .classic (initializer + Classic-voorinstellingen), .mcmc (alle MCMC-voorinstellingen + scene-class) Range: .classic of .mcmc Defined in:
TECHNISCH
Kiest tussen Classic-densification (klon/split/prune, Kerbl et al.~2023) en MCMC-densification (Stochastic Gradient Langevin Dynamics met relocation, Kheradmand et al.~NeurIPS 2024). Bij .classic worden T11–T16 geëvalueerd, bij .mcmc de T62–T73. Let op bij wissel: Classic defaults en MCMC defaults zijn totaal anders gekalibreerd — wie de picker in de Expert View flipt zonder een passende voorinstelling te laden, riskeert 1.4.3-bug-style mass-extinction (460 K → 5 in één iteratie, omdat MCMC-OpacityReg op 0,01 de Classic-opacities killt). Vandaar de MCMC-init defaults opzettelijk „weichgespoeld" (alle reg-waarden 0,0).
T62mcmcMaxGaussians
DETAILS
Default: 150.000 (initializer + .fullMCMC + .mcmcBalanced), 100.000 (.mcmcPreview), 1.500.000 (.fullMCMCMip — Mip-Splatting-variant met 10× budget), 1,19 M (.renderPreset), 1,25 M (.outdoorPreset), 670 K (.indoorPreset) Range: 0 (= „gebruik buffer-capaciteit") of 10.000 – 5.000.000 Defined in:
TECHNISCH
Harde bovengrens voor het aantal Gaussians bij MCMC-strategie. Het aantal groeit gestaag met T70 mcmcGrowthRate (typisch 5%) per relocation-stap tot dit cap. V473/V531 vonden 150 K als sweet spot — boven 200 K verdunt de splat-kwaliteit (te veel kleine, redundante Gaussians), onder 100 K blijft de scène onder-gedensificeerd. Bij zeer grote scènes (bijv. 1.545-foto-dronevlucht met 158 K SfM-init) is 150 K te laag — vandaar de 1.4.5-uitbreiding T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt vond scènespecifieke optima tussen 670 K (Indoor) en 1,25 M (Outdoor). Bij waarde 0 gebruikt de engine de volledige buffer-capaciteit als cap.
T63mcmcNoiseScale
DETAILS
Default: 0,00005 (5e-5 = paper-default) Range: 1e-6 – 1e-3 Defined in:
TECHNISCH
Multiplicator voor de Gauss'sche ruis die in elke MCMC-iteratie aan de positie van elke Gaussian wordt toegevoegd (SGLD-logica). Hoger = meer exploratie (Gaussians wandelen meer, vinden potentieel betere plekken), lager = meer exploitatie (Gaussians blijven waar ze al goed zijn). V467 en V536 bevestigden 5e-5 als optimaal — 1e-5/2e-5 te weinig exploratie, 1e-4 te veel (splats lopen uiteen). Wordt over de trainingstijd cosine-decayed tot T69 mcmcNoiseDecayEnd — aan het einde van het decay-bereik is ruis effectief 0 en de Gaussians convergeren.
T64mcmcOpacityRegWeight
DETAILS
Default: 0,0 (= gedeactiveerd in RadianceKit Defaults, paper: 0,01) Range: 0 of 0,001 – 0,05 Defined in:
TECHNISCH
MCMC-specifieke L1-penalty op opacity. Paper-default 0,01 (drukt ongebruikte Gaussians tegen nul, maakt ze voor relocation beschikbaar). V464b toonde echter: zonder reg is het in RadianceKit meetbaar beter (sessie 28 bevestigd). Reden: de met T68 mcmcDeadOpacityThreshold gedefinieerde pruning-criterium volstaat alleen — een extra L1-penalty dwingt ook waardevolle, lage-opacity-Gaussians te sterven. Vandaar default 0. Let op: in 1.4.3-beta-build was de initializer-default ten onrechte 0,01, wat in de mass-extinction-bug resulteerde (zie T61-uitleg); sinds 1.4.4 op 0,0 vastgezet.
T65mcmcScaleRegWeight
DETAILS
Default: 0,0 (= gedeactiveerd, paper: 0,01) Range: 0 of 0,001 – 0,05 Defined in:
TECHNISCH
MCMC-specifieke L1-penalty op de scale-eigenwaarden. Paper-default 0,01. V464b: zonder reg beter, zelfde motivering als T64. Disabled in alle RadianceKit-MCMC-voorinstellingen. Let op zoals bij T64: 1.4.3-bug.
T66mcmcRelocationInterval
DETAILS
Default: 100 (initializer + alle MCMC-voorinstellingen, paper-standaard), 155 (P9 Outdoor — Q7-BayesOpt-optimum) Range: 50 – 500 Defined in:
TECHNISCH
Iteratie-interval waarin MCMC dode Gaussians (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) naar nieuwe posities relociert. V537 testte 50 (te disruptief, loss schommelt) en 200 (marginaal slechter, MCMC verliest reactievermogen). 100 is optimaal. Q7-BayesOpt op Bicycle vond 155 als scènespecifiek optimum voor outdoor — de iets langere intervallen geven Adam meer tijd, nieuw geplaatste Gaussians te integreren, voordat de volgende reloc-event ze onder druk zet.
T67mcmcWarmupIterations
DETAILS
Default: 500 Range: 100 – 5.000 Defined in:
TECHNISCH
Aantal initial-iteraties waarin nog geen MCMC-relocation plaatsvindt. Pas na deze warmup begint de reloc-logica. Doel: in de eerste iteraties zijn de opacity-waarden nog niet ingeklemd — als direct met reloc gestart, zouden Gaussians op de verkeerde plekken geplaatst worden en moeten meteen weer worden bewogen, wat Adam-momentum vernietigt. Paper-default 500. RadianceKit neemt deze waarde over, omdat V464b toonde dat het robuust is.
T68mcmcDeadOpacityThreshold
DETAILS
Default: 0,005 (initializer, paper-standaard), 0,01 (.fullMCMC en alle MCMC-voorinstellingen — V535-optimum) Range: 0,001 – 0,05 Defined in:
TECHNISCH
sigmoid(opacity)-drempel waaronder een Gaussian als „dood" geldt en voor relocation in aanmerking komt. V535 vond 0,01 als optimaal (0,005 marginaal, 0,02 slechter). Hoger = agressievere reloc (meer Gaussians worden bewogen), lager = voorzichtiger. 0,01 komt ongeveer overeen met „0,5% visuele zichtbaarheid". P10 Indoor gebruikt via Q7-BayesOpt 0,0142 als optimum.
T69mcmcNoiseDecayEnd
DETAILS
Default: 0 (initializer = „geen verval"), 160.000 (.fullMCMC = 80% van 200K), 96.000 (.mcmcBalanced = 80% van 120K), 40.000 (.mcmcPreview) Range: 0 of 1.000 – Defined in:
TECHNISCH
Iteratie waarop het T63 mcmcNoiseScale-ruis volledig op nul wordt gedempt (cosine-verval van iter 0 tot hier). V497c/V502 vonden 80% van maxIterations optimaal — geeft MCMC genoeg exploratie-tijd, maar laat de laatste 20% ter convergentie zonder ruis. 0 = constante ruis over alle iteraties (zelden zinvol, MCMC kan dan niet convergeren).
T70mcmcGrowthRate
DETAILS
Default: 0,05 (paper-standaard = 5%) Range: 0,01 – 0,2 Defined in:
TECHNISCH
Groeisnelheid van het MCMC-populatie-target per relocation-stap. De logica: bij elke reloc-event wordt de doel-populatiegrootte met (1 + growthRate) verhoogd, tot T62 mcmcMaxGaussians (of de per T72/T73 geschaalde variant) is bereikt. V512/V522 vonden 0,05 als optimaal — hogere waarden leiden tot te snelle groei (Gaussians worden ingevoegd voordat het Adam-momentum ze kan integreren), lagere tot onder-gedensificeerde scènes aan het einde.
T71mcmcSigmoidK
DETAILS
Default: 100,0 Range: 10,0 – 500,0 Defined in:
TECHNISCH
Sigmoid-sharpness-parameter voor de MCMC-noise-attenuatie. In de SGLD-stap wordt de per-Gaussian-ruis gedempt — hoog-opake Gaussians (waarvan de logit positief is) krijgen exponentieel minder ruis dan laag-opake. K = 100 is scherp, d.w.z. de overgang van „vol-noise" naar „geen-noise" gebeurt zeer snel rond opacity 0,5. V484–V487 vonden K = 100 optimaal — kleinere waarden (10–50) laten ook hoog-opake Gaussians mee-wiebelen (vernietigt geconvergeerde Gaussians), grotere (> 500) maken de overgang kunstmatig hard en dode Gaussians worden helemaal niet meer bewogen.
T72mcmcCapMultiplier
DETAILS
Default: 3,0 (initializer + .fullMCMC), 2,0 (.mcmcPreview), 2,5 (.mcmcBalanced), 2,98 (P8 Render), 5,32 (P9 Outdoor), 1,76 (P10 Indoor) Range: 0 (= gedeactiveerd) of 1,0 – 10,0 Defined in:
TECHNISCH
1.4.5-feature: scène-adaptieve cap-schaling. Wanneer T73 mcmcAutoScaleByScene true is, wordt het effectieve cap als berekend (geclampt aan buffer-capaciteit). Achtergrond: bij grote scènes (bijv. 1.545-foto-dronevlucht → 158 K SfM-init) is T62 = 150.000 te laag — density-control zou helemaal niet kunnen groeien. Met multiplier 3,0 wordt de cap bij dit voorbeeld op 474 K geschaald (158 K × 3,0). Q7-BayesOpt vond scènespecifieke optima: Outdoor profiteert van hoge multiplier (5,32 → ~830 K cap bij 156 K bicycle-init), Indoor stelt zich tevreden met 1,76 (muren verzadigen sneller). Volledige resolutie van het cap zie -methode.
T73mcmcAutoScaleByScene
DETAILS
Default: true (initializer + alle MCMC-voorinstellingen) Range: boolean Defined in:
TECHNISCH
1.4.5-feature: master-switch voor de scene-aware cap-logica (zie T72 +). Wanneer false, wordt uitsluitend T62 mcmcMaxGaussians als cap gebruikt (terug naar 1.4.4-gedrag). Standaard aan, omdat de mass-extinction-problemen bij grote scènes uit 1.4.3 anders terugkeren. Handmatig deactiveren alleen wanneer je expliciet een hard cap wilt instellen — bijv. om een 150 K-variant te trainen waarvan de eindgrootte planbaar is.
Mip-Splatting (Q1.5) (T74–T76)
Status: Q1.5 werd op 2026-05-25 na 14 autonome iteraties + overnight-1,5M-confidence-check als „closed no-win" verworpen (max Δ@2× = +0,27 dB, originele gate eiste ≥ +1,5 dB gemiddelde over 0,5×/2×, FAILT op 0/11 pair-scenes). De velden blijven opt-in voor onderzoeksexperimenten; alle production-voorinstellingen hebben. Zie verdict:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETAILS
Default: false (alle production-voorinstellingen), true (.fullMCMCMip — onderzoeks-sibling) Range: boolean Defined in:
TECHNISCH
Activeert Mip-Splatting (Yu et al.~CVPR 2024): 3D-smoothing-filter + 2D-filter + α-compensatie die de per-Gaussian-frequentie op de Nyquist-grens van de dichtste trainings-camera-sampling-snelheid begrenst. Theoretisch doel: eliminatie van aliasing bij rendering in off-training-schalen (0,5× of 2× van de trainingsresolutie). In de preprocess- en backward-projection-shaders geactiveerd, functioneel correct geverifieerd in Q1.5-D-test. Maar: de originele acceptatie-gate (Δ@1× ≥ +0,3 dB EN avg(Δ@0,5×, Δ@2×) ≥ +1,5 dB) werd op geen van 11 pair-scenes bereikt. Maximaal waargenomen: family 750K classic Δ@2× = +0,270 dB. Outdoor-scènes (Truck, Flowers) toonden zelfs verslechtering 1× en 0,5×. Hypothese: 3D-smoothing concurreert met MCMC-relocation bij high-Gs. Veld blijft voor toekomstige multi-scale-re-eval met correcte Mip-NeRF-360-methodology (zie O3-backlog in benchmark-pad).
T75mipSmoothing3DScale
DETAILS
Default: 0,2 (paper-default) Range: 0,05 – 1,0 Defined in:
TECHNISCH
3D-smoothing-scale-parameter (Yu et al.~§3.3, paper-default 0,2). Groter = meer wereld-ruimte-gladmaak per Gaussian (= meer anti-aliasing, maar ook meer blur in de default-schaal), kleiner = scherper maar gevoeliger voor aliasing. Wordt alleen geraadpleegd wanneer T74 useMipSplatting = true. In Q1.5-tests niet verder geoptimaliseerd — de A/B-gate heeft al met paper-default 0,2 verloren, verdere sweeps zouden zinloos zijn.
T76mipFilter2DVariance
DETAILS
Default: 0,3 (= exact het V242-legacy-gedrag) Range: 0,1 – 1,0 Defined in:
TECHNISCH
2D-Mip-filter-variantie die aan de Σ_2D-diagonaal wordt toegevoegd (variantie direct, niet gekwadrateerd). 0,3 is exact de V242-legacy-waarde die vóór Mip-Splatting hardgecodeerd in de kernel zat. Wanneer T74 useMipSplatting = false, negeert de kernel deze waarde volledig en schrijft het hardgecodeerde 0,3 — zodat de baseline niet kan regrederen (Codex-round-1-S3-1-garantie). Wanneer, wordt de hier ingestelde waarde gebruikt. Blijft in de veldcatalogus voor Mip-sweeps.
Adaptive densification (Q5) (T77–T79)
T77adaptiveDensification
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q5-feature: rolling-median-tracker als alternatief voor de vaste T11 densifyGradThreshold. Wanneer true, wordt in elke densify-stap de actuele drempel met median(laatste N avgGrad-samples) × T79 adaptiveDensifyMultiplier overschreven. N = T78 adaptiveWindow. Strikter dan V440 p98 (de catastrofale 63 K-pruning-val), median + 2× zit ongeveer op het p70–p80 van de gradiëntverdeling in steady state. Q5-tests: alleenstaand FAIL 0/3 scènes, maar samen met Q6 (zie T80/T81) PASS 1/3 scènes — het bundel Q5+Q6 werd op 2026-05-25 als opt-in gepasseerd en is via CLI –adaptive-densify activeerbaar. Q6 is daarbij de „carrier" van de kwaliteitswinst, Q5 draagt eerder bij aan stabiliteit.
T78adaptiveWindow
DETAILS
Default: 1.000 Range: 100 – 10.000 Defined in:
TECHNISCH
Rolling-median-window in densification-events (NIET iteraties — elke T13 densifyInterval-stap levert een sample). Default 1.000 — bij betekent dat de laatste 100.000 trainingsiteraties bijdragen aan de median, dus typisch de gehele trainingshistorie tot hier. Vroege fase (vóór T78 samples): tracker returns nil → fallback naar vaste drempel T11. Alleen relevant wanneer.
T79adaptiveDensifyMultiplier
DETAILS
Default: 2,0 Range: 1,0 – 4,0 Defined in:
TECHNISCH
Multiplicator op de rolling-median voor de adaptieve drempel. Default 2,0 komt ongeveer overeen met p70–p80 van de typische gradiëntverdeling. Lager = agressievere groei (meer klones), hoger = strenger (minder klones). Q5-tests in range 1,5–3,0 — 2,0 beste default. Alleen relevant wanneer.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q6-feature: trainings-resolutie start bij 0,5× en wisselt bij T50 positionLRScheduleEndIteration / 2 (of T1 maxIterations / 2, mocht T50 niet ingesteld) naar T22 trainingRenderScale. Gebruikt de in Q1.5.1 ontwikkelde resize/restoreImageBuffers-infrastructuur. Overschrijft T23 resolutionWarmupScale wanneer geactiveerd. Q6 is als „carrier van de kwaliteitswinst" in het Q5+Q6-bundel gepasseerd (zie T77) — de stapsgewijze resolutie-verhoging geeft de app tijd om grove geometrie op de lagere resolutie te vinden voordat hij naar de fijne detailarbeid overgaat. Via CLI: –curriculum-resolution.
T81curriculumSHProgression
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q6-feature: overschrijft T21 shDegreeUpgradeIterations met [maxIter/4, maxIter/2, maxIter*3/4], verdeelt dus de SH-upgrades gelijkmatig over de trainingstijd in plaats van ze front-to-load. Hypothese: stabiele geometrie wordt vóór color-detail-explosie gevestigd, wat de view-direction-afhankelijke glans-effecten preciezer positioneert. Q5+Q6 samen PASS 1/3 scènes, Q6 als carrier van de winst (Q5 alone FAIL). Via CLI: –curriculum-sh.
Statische voorinstellingen (TP1–TP9)
Hier alleen de structurele verschillen met de initializer-default. De volle marketing-beschrijving van de tien UI-voorinstellingen P1–P10 vind je in hoofdstuk 7.
TP1.preview
DETAILS
Diagnose-/voorbeeld-voorinstelling voor systemen ≥ 10 GB RAM. Overrides ten opzichte van initializer: - 30.000 → 5.000 - 15.000 → 3.500 (70% van maxIter) - 1.6e-6 → 1.6e-5 (10× hoger, minder agressief verval) -,,,, elk 2× (V176) - 3.000 → 100.000 (effectief uit, V172: reset vernietigt korte trainingen) - [1K, 2K, 3K] → [1K, 2K] (V182: degree 3 convergeert in 2K iter niet) - 1,0 → 0,5
TP2.full
DETAILS
Production-Quality Classic. Overrides: - 30.000 → 35.000 (V550: 40K-tests Truck-overtraining +10,7% Gs bij -1,3% L1) - 15.000 → 5.000 (V310 sweet spot, V338 7K worse) - Alle LR's 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0,005 → 0,001 (V393) - 3.000 → 100.000 (V194 disabled, V421 confirmed) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 delayed) - 0,0 → 0,9995 (V546 HTGS, 14% verbetering) - 50 (ongewijzigd, V546) - false → true (V438) - 0 → 20.000 (V431) - true (V443, al initializer-default voor .full)
TP3.fullClassicPaper
DETAILS
Q1.5-A-test-sibling van TP2, paper-getrouwe Classic. Overrides ten opzichte van TP2: - 35.000 → 30.000 (paper-standaard) - 5.000 → 15.000 (paper: 50% van maxIter) - 1.6e-5 → 1.6e-6 (paper-default) -,, terug op paper defaults (0,05, 0,005, 0,001) - 1.1e-6 → 2e-7 (gekalibreerd voor ~1-2M Gs op Bicycle) - 200 → 100 (paper) - 0,001 → 0,005 (paper-default) - 100.000 → 3.000 (paper §5.2, risico — kan V194-regressie triggeren) - 0,9995 → 0,0 (paper heeft geen verval) - 20.000 → 30.000 (cosine loopt op 100% van maxIter)
TP4.fullMCMC
DETAILS
Production-Quality MCMC. Overrides ten opzichte van initializer: - 30.000 → 200.000 (V534, MCMC heeft 5× meer iter dan Classic nodig) - 15.000 → 160.000 (V504b 80% van maxIter) - 1.6e-6 → 1.6e-5 - LR-schedule zoals TP2 (alle 2×) - 0,2 → 0,05 (V521b/V534: MCMC heeft sterker L1-signaal nodig) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150.000 (in initializer al, in voorinstelling bevestigd) - 5e-5 (V467/V536 optimaal) - 0,005 → 0,01 (V535 optimaal) - 0 → 160.000 (80% van maxIter, V497c/V502) - 3,0 (in initializer al) - true (in initializer al) - 3.000 → 200.000 (effectief uit, MCMC gebruikt reloc in plaats van reset)
TP5.fullMCMCMip
DETAILS
Q1.5-D-test-sibling van TP4, met Mip-Splatting + paper-magnitude-MCMC-budget. Overrides ten opzichte van TP4: - mcmcMaxGaussians 150.000 → 1.500.000 (10×, paper-magnitude) - useMipSplatting false → true (Mip-on)
TP6.classicBalanced
DETAILS
Mid-Tier Classic. Overrides ten opzichte van TP2: - 35.000 → 20.000 (V149: 20K = 30K bij 33% minder tijd) - 20.000 → 0 (cosine loopt op maxIter = 20K, geen extended phase)
TP7.mcmcPreview
DETAILS
MCMC-diagnose. Overrides ten opzichte van TP4: - 200.000 → 60.000 (V494b) - 160.000 → 48.000 (80%) - 150.000 → 100.000 (V473b) - 160.000 → 40.000 (V494b) - 3,0 → 2,0 (1.4.5: preview = lighter scaling)
TP8.mcmcBalanced
DETAILS
Mid-Tier MCMC. Overrides ten opzichte van TP4: - 200.000 → 120.000 (V518) - 160.000 → 96.000 (80%) - 160.000 → 96.000 (80%) - 3,0 → 2,5 (tussen Preview 2,0 en Full 3,0)
TP9.quickTest
DETAILS
Pure functietest. Overrides ten opzichte van initializer: - 30.000 → 1.000 - 15.000 → 500 - 2e-6 → 4e-6 (gekalibreerd voor 0,25× resolutie) - 100 → 50 - 3.000 → 100.000 (uit, omdat veel te kort) - 1,0 → 0,25
Methode:
Signature: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Defined in:
Enige source-of-truth voor de vraag „hoeveel Gaussians mag MCMC maximaal laten groeien?". Berekent zich uit drie invoeren: de geconfigureerde T62 mcmcMaxGaussians (met mass-extinction-floor 150.000, mocht 0), de (aantal SfM-init-punten) en de (vooraf gealloceerde Gaussian-buffer-grootte). Logica:
+ base = T62 > 0 ? T62: 150_000 (de mass-extinction-floor beschermt tegen initializer-default-bugs zoals het 1.4.3-mass-extinction-incident) + Mocht T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) anders
+ Mocht bufferCapacity > 0: return min(scaled, bufferCapacity) + Anders return scaled
Voorbeeld: Bicycle (Mip-NeRF 360, 194 fotoframes) → SfM-init ~156 K punten, T62 = 150.000, T72 = 5,32,, buffer-capaciteit 8 M. Resolved cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. Dat is het effectieve groei-cap waaraan de MCMC-relocation-logica zich houdt.
Berekent het werkelijke maximale splat-aantal bij MCMC. Neemt je instelling, kijkt hoeveel punten je scène in het begin heeft, en schaalt met de multiplier, mocht de automatische aanpassing aan zijn. Zo past de cap zich aan de scène aan in plaats van voor een kleine en een gigantische scène dezelfde waarde af te dwingen. Je hoeft de methode niet zelf aan te roepen — de training gebruikt hem intern.
Welk veld waarvoor? (cheatsheet)
| Doel | Velden om aan te draaien |
|---|---|
| Meer detail in de verte | T62 mcmcMaxGaussians hoog, T72 mcmcCapMultiplier 5+ |
| Meer detail algemeen (Classic) | T1 maxIterations hoog (≤ 40K), T2 densifyUntilIteration ≤ 14% van T1 |
| Floaters in dronevluchten reduceren | T43 frustumCullEnabled aan, T20 skyMaskingEnabled aan, T45 skyDomeEnabled aan |
| Mooi hemel in buitenscènes | T45 skyDomeEnabled aan, T47 skyDomeRadiusMultiplier 30–60 |
| Kleiner exportbestand | Strategie .mcmc (T61), T56 postTrainingCompactification aan, T62 mcmcMaxGaussians ≤ 200K |
| Snellere training | T22 trainingRenderScale 0,5, T1 maxIterations halveren — maar niet beide! |
| Betere glanslichten | T21 shDegreeUpgradeIterations met [2K, 5K, 8K] (geen early-front-load), MCMC + 200K iter |
| Mac responsief houden | T25 throttleDelayMs 5–10 (kost ~15% trainingstijd) |
| Live-voorbeeld vaker | T59 livePreviewInterval omlaag naar 10–20 |
| Zachtere overgangen bij schaduwen | T17 ssimWeight wat hoger (0,15–0,25), maar niet boven 0,3 |
| Binnenruimtes compact houden | P10 Indoor-voorinstelling (, T72 = 1,76) |
Gevaarlijke velden
Deze velden kunnen bij verkeerde configuratie tot OOM, app-crash, mass-extinction van de Gaussians of onbruikbare benchmark-data leiden. Met voorzichtigheid behandelen:
- T11 densifyGradThreshold — een halvering kan 2–4× zoveel Gaussians genereren, wat snel het GPU-geheugen doet barsten. Ook te letten op: moet bij de T22 trainingRenderScale passen (1,0× → 1e-6, 0,5× → 2e-6, 0,25× → 4e-6). - T72 mcmcCapMultiplier — bij grote scènes met > 200 K SfM-init-punten en multiplier > 5 ontstaat een resolved-cap van miljoenen Gaussians. Op 36-GB-RAM-Macs OOM mogelijk. Outdoor-voorinstelling 5,32 werkt alleen omdat Mip-NeRF-360-Bicycle 156 K init-punten heeft → 830 K cap. - T39 testViewIndices — handmatig instellen kan de benchmark onbruikbaar maken (alle indices > N → geen holdouts). Laat de –benchmark-flag dat instellen. - T64 mcmcOpacityRegWeight en T65 mcmcScaleRegWeight — In 1.4.3-beta op 0,01 ingesteld, wat tot mass-extinction leidde (460 K → 5 Gaussians in één iteratie). Sinds 1.4.4 op 0,0 vastgezet, maar handmatig verhogen kan het probleem reproduceren. - T15 opacityResetInterval — wanneer niet 100.000+ (effectief uit) en de training korter dan 10.000 iteraties is, vernietigt de reset de convergentie. .preview heeft het daarom op 100.000 ondanks maxIterations = 5.000. - T54/T55 densifyPhase2* — two-phase densification is in tests in 0-Gaussians-cascade afgebroken. Laat beide op 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, kan op sommige outdoor-scènes zelfs PSNR verslechteren. Default off, opt-in alleen voor onderzoek.
Mocht een veld op deze lijst staan en je wilt het wijzigen, maak vooraf een back-up van je actuele voorinstelling (export als JSON) en overweeg of je het resultaat reproduceerbaar kunt meten — anders weet je achteraf niet of je een verbetering of verslechtering hebt teweeggebracht.