Kapitel 6 — Trainings-Konfiguration
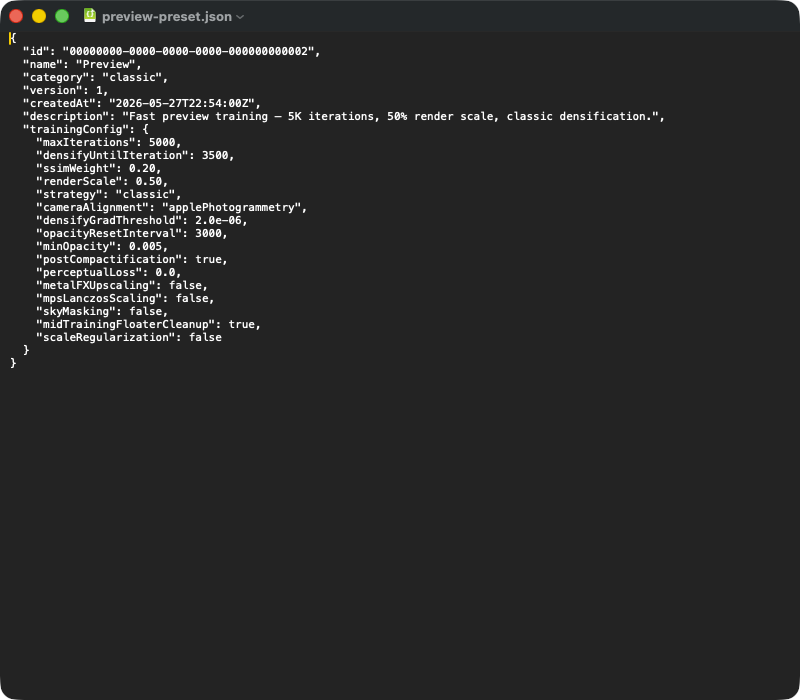
Ein typischer Preset-JSON-Export. Top-Level-Felder: id (UUID), name, (classic | mcmc | sceneClass | custom), (Schema-Version), (Timestamp), (Free-Text). Verschachteltes -Objekt enthält die für Reproduzierbarkeit kritischen Parameter — beim Import wird der gesamte Block in die TrainingConfig-Struktur deserialisiert, und Defaults aus der App-Version füllen die Felder, die in der JSON fehlen (z. B. nach App-Update). Wer ein Preset an einen anderen Mac übergibt, schickt einfach diese JSON-Datei rüber.
Die TrainingConfig-Struktur ist das Herzstück jedes Trainingslaufs in RadianceKit. Sie versammelt jeden Parameter, der das Training beeinflusst — von der maximalen Iterationszahl über die acht Lernraten bis hin zu den Spezialfeldern für MCMC, Mip-Splatting, das Curriculum und die scene-aware Cap-Logik. Du bearbeitest sie in der Sidebar im Bereich Trainings-Konfigurations-Sektion (Expert View), speicherst sie als Preset oder reichst sie als JSON-Export an einen anderen Mac weiter. Beim Training wird genau dieses Objekt eingefroren und ans GPU-Backend gegeben.
Dieses Kapitel ist Referenz-Material für Power-User und Skript-Autoren. Es listet alle 81 öffentlichen Felder, die 9 statischen Presets und die eine öffentliche Methode. Quelldatei ist TrainingConfig.swift — bei Zweifeln gilt der dort hinterlegte Doc-Comment und der Initializer-Default als Source-of-Truth.
Inhaltsverzeichnis:
+ Iteration (T1–T2) + Learning Rates (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH-Degree-Progression (T21) + Performance (T22–T25) + Diagnose und Punktwolken-Vorbereitung (T26–T30) + Regularisierung (T31–T37) + Refinement (T38–T44) + Sky-Dome (T45–T48) + Adam + LR-Schedule (T49–T55) + Post-Processing + Apple AI (T56–T60) + MCMC-Densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptive Densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Statische Presets (TP1–TP9) + Methode: + Welches Feld wofür? (Cheat-Sheet) + Gefährliche Felder
Iteration (T1–T2)
T1maxIterations
DETAILS
Default: 30 000 (Initializer), 35 000 (.full), 200 000 (.fullMCMC) Range: 1 000 – 500 000 (UI-Slider), keine harte obere Grenze in der Logik Defined in:
TECHNISCH
Gesamtzahl der Trainings-Iterationen, die das Backend durchläuft. Eine Iteration bezeichnet ein Forward-Render einer einzelnen Trainingskamera, einen Backward-Pass über alle Loss-Komponenten (L1 + SSIM + optionale Regularisierungen + Sky-Mask) und einen Adam-Optimizer-Schritt. Diese Zahl wirkt direkt auf die anderen Schedules: Position-Lernrate folgt einer Cosine-Annealing-Kurve von 0 bis entweder T1 selbst oder bis T49 positionLRScheduleEndIteration; Densification stoppt bei T2 densifyUntilIteration; MCMC-Noise-Decay endet bei T69 mcmcNoiseDecayEnd; SH-Degree-Upgrades passieren an den drei in T21 definierten Marken. Bei klassischer Densification liegt der empirisch ermittelte sweet spot bei 20 000–35 000 Iterationen (Sessions 1–32, V546-Tests), bei MCMC bei 60 000–200 000 (V534). Eine drastische Erhöhung über die in Preset hinterlegten Werte hinaus bringt selten zusätzliche Qualität — Adam-Momentum sättigt, und ohne LR-Decay-Ende stagniert der Loss. Umgekehrt führt Unterschreitung von ~5 000 zu unvollständig konvergierten Geometrien (Density-Control hat zu wenig Zeit zum Klonen/Splitten).
T2densifyUntilIteration
DETAILS
Default: 15 000 (Initializer), 5 000 (.full), 160 000 (.fullMCMC) Range: 0 – Defined in:
TECHNISCH
Iteration, ab der die Densification aufhört. Bis hierhin werden Gaussians über die in T11–T16 (Classic) oder T67–T70 (MCMC) parametrisierten Regeln geklont, gesplittet und geprunt; danach bleibt die Gaussian-Anzahl konstant und nur noch Positionen, Rotationen, Skalen, Opazitäten und SH-Koeffizienten werden optimiert (Refinement-Phase). Im 3DGS-Originalpaper liegt der Wert bei 50 % von T1, in RadianceKits .full-Preset bei nur ~14 % (5 000 von 35 000) — Folge der V310/V338-Experimente, die zeigten, dass nach 5 000 Iterationen weitere Densifizierung das Resultat eher verschlechtert (mehr Floaters, mehr Speicherbedarf, kein Qualitätsgewinn). MCMC dagegen läuft die Relocation bis 80 % von T1 (V504b), weil MCMC keine schädlichen Floaters produziert. Wird T2 zu klein gewählt (< 1 000), entstehen zu wenige Gaussians; zu groß bei Classic (> 50 % von T1) führt zu Overgrowth und RGB-Saturation-Outliers (siehe Outdoor-Overtraining-Findings).
Learning Rates (T3–T10)
T3positionLearningRate
DETAILS
Default: 0.00016 Range: 1e-7 – 1e-3 (empfohlen) Defined in:
TECHNISCH
Adam-Lernrate für die XYZ-Position jeder Gaussian zu Beginn des Trainings (Iteration 0). Folgt einer Cosine-Annealing-Kurve und sinkt im Laufe des Trainings auf T4 positionLearningRateFinal. Der Default 0.00016 stammt aus dem 3DGS-Originalpaper (Kerbl et al.~2023) und ist in RadianceKit auch bei Erhöhung der Bildauflösung nicht zu skalieren — die Position bewegt sich im Welt-Koordinatensystem, nicht im Pixelraum. Eine deutliche Erhöhung (> 0.0005) bewirkt, dass Gaussians über lange Distanzen springen und der Loss instabil wird; Werte deutlich darunter (< 0.00005) führen dazu, dass falsch initialisierte Punktwolken nie ihren Platz finden. V414 testete eine Verdopplung des Init-Werts → 16.8 % schlechterer L1-Loss; die V544a-Tunings bestätigten den Paper-Default als optimal. Beachte: bei .fullMCMC lassen wir diesen Wert bewusst beim Default — MCMC braucht konstante Lernraten für seine Relocation-Logik, daher bringt das Tunen hier nichts.
T4positionLearningRateFinal
DETAILS
Default: 0.0000016 (Initializer + Paper), 0.000016 (.full, .fullMCMC — 10× höher) Range: 0 – Defined in:
TECHNISCH
Endwert der Position-LR-Cosine-Annealing-Kurve. Erreicht wird er entweder bei T1 maxIterations oder, falls gesetzt, bei T49 positionLRScheduleEndIteration. Der RadianceKit-.full-Preset verwendet 0.000016 — also 10× höher als der Paper-Default 0.0000016. V420-Experimente zeigten, dass 0.5× des Final-Werts (0.000008) den Loss um 6.4 % verschlechtert; V414 zeigte, dass 2× Init-Wert ihn um 16.8 % verschlechtert. Der hohe Final-Wert ist nicht Trade-off, sondern bewusste Wahl: bei zu starkem Decay verlieren die Gaussians während der Refinement-Phase ihre Fähigkeit, sich auf neu hinzugekommene Densification-Kandidaten einzustellen. Über die V431/V433-Erweiterung kann die Schedule-Phase verkürzt werden (T49 < T1), sodass T4 bereits vor Trainingsende erreicht wird und der Rest des Trainings bei konstanter Mini-LR läuft — typische Konfiguration: T49 = 20 000, T1 = 35 000, Refinement also bei 0.000016 für 15 000 Iterationen.
T5shDCLearningRate
DETAILS
Default: 0.0025 (Initializer + Paper), 0.005 (.full und alle MCMC-Presets — 2×) Range: 0.0001 – 0.05 Defined in:
TECHNISCH
Adam-Lernrate für den DC-Anteil (degree 0, also konstantes Albedo) der spherical-harmonic-Farbe. SH-DC entspricht dem direktionsunabhängigen Grundton einer Gaussian, gewissermaßen die „Basisfarbe". Die V176- und V188-Experimente fanden 2× höher als der Paper-Default optimal — schnellere Farb-Konvergenz, gerade weil bei kurzem Training (, 5 000 Iterationen) die SH-DC sonst nicht in Form kommt. Anders als die geometrischen LRs hat SH-DC keinen Decay; die Lernrate bleibt über alle Iterationen konstant (oder folgt nur dem optionalen extended-phase-Decay aus T51). V416 testete eine Vervierfachung auf 0.01 → 6.4 % schlechterer Loss bei beta2=0.99-Adam.
T6shRestLearningRate
DETAILS
Default: 0.000125 (Initializer + Paper), 0.00025 (.full und MCMC — 2×) Range: 0.000001 – 0.005 Defined in:
TECHNISCH
Adam-Lernrate für die SH-Koeffizienten höherer Ordnung (Degree 1, 2, 3 — also die view-direction-abhängigen Farbanteile, die für Glanzlichter, Spiegelungen und sanfte Schattierung sorgen). 20× kleiner als T5 per Paper-Konvention, weil diese Koeffizienten quadratisch in Anzahl wachsen (3 für Degree 1, 5 für Degree 2, 7 für Degree 3 → insgesamt 15 Floats pro Gaussian) und ohne kleinere Lernrate das Bild übersättigen würden. Wird in zwei Schritten freigeschaltet — bis zur ersten Marke in T21 shDegreeUpgradeIterations ist nur Degree 0 aktiv (also nur T5), danach 1, später 2, schließlich 3. Niedrige Werte hier sind besonders wichtig auf Szenen mit viel diffuser Beleuchtung; bei sehr glänzenden Oberflächen (Auto-Lack, Wasser) lohnt sich kein Drehen — die SH-Repräsentation an sich ist begrenzt.
T7opacityLearningRate
DETAILS
Default: 0.05 (Initializer + Paper), 0.1 (.full, MCMC — 2×) Range: 0.001 – 1.0 Defined in:
TECHNISCH
Adam-Lernrate für die logit-Opazität jeder Gaussian. Die App speichert Opazität als unbeschränkten Float-Wert und transformiert ihn mit Sigmoid in [0, 1]; die LR wirkt im Logit-Space. Der Paper-Default 0.05 ist nach V50-Tests (Best Single-Run L1 0.1664) wiederhergestellt, V71 revertete V67s 0.025. Die V188-Verdopplung auf 0.1 macht das Pruning effizienter — tote Gaussians fallen schneller unter den T14 pruneOpacityThreshold ab. V418 zeigte: 0.05 mit beta2=0.99-Adam ist 7.1 % schlechter als 0.1 — die Wechselwirkung mit der Adam-Konfiguration ist nicht trivial. Niedrige Werte (< 0.01) führen dazu, dass „dead" Gaussians ewig herumliegen und Speicher verbrauchen; zu hohe Werte (> 0.5) können zu Opacity-Explosion führen, daher wird der Logit-Wert im Optimizer auf [-15, 3] geclampt (siehe Notiz „Opacity Explosion Prevention" in CLAUDE.md).
T8opacityLearningRateFinal
DETAILS
Default: 0.0 (= „kein Decay") Range: 0 oder 0.001 – Defined in:
TECHNISCH
Optionaler Cosine-Decay-Endwert für die Opacity-LR (V427). Wenn 0.0, ist Decay deaktiviert und die Opacity-LR bleibt über das gesamte Training konstant bei T7. V427 testete einen Decay 0.1 → 0.01 — Ergebnis 11.5 % schlechterer Loss; reverted, daher der Default „aus". Die Hypothese hinter dem Feld: in der Refinement-Phase könnte konstante Opacity-LR zu Oszillation führen, sodass Splats, die schon das richtige Maß an Transparenz erreicht haben, durch zufällige Gradient-Schwankungen wieder verschoben werden. Empirisch bestätigt sich das nicht — die Logit-Clamping-Logik fängt das ohnehin ab. Das Feld bleibt verfügbar für zukünftige Experimente; auch sehr lange MCMC-Läufe (> 500K Iterationen) könnten davon profitieren.
T9scaleLearningRate
DETAILS
Default: 0.005 (Initializer + Paper), 0.01 (.full, MCMC — 2×) Range: 0.0001 – 0.1 Defined in:
TECHNISCH
Adam-Lernrate für die drei Skalen-Komponenten jeder Gaussian im log-Space (RadianceKit speichert log(scale), damit Skalen positiv bleiben). Der Paper-Default 0.005, in RadianceKit verdoppelt auf 0.01 für besseren Scale-Konvergenz bei den optimierten Lernraten-Konfigurationen. V423-Experiment: 0.005 mit beta2=0.99-Adam → 18.7 % schlechterer Loss und sichtbar zu wenige Gaussians (Density-Control konnte nicht klonen, weil die Skalen-Updates zu lahm waren). Skala kontrolliert die Ausdehnung jeder Gaussian — zu schnelles Lernen führt zu „needle"-Gaussians (extrem lange dünne Splats, siehe T34 scaleRatioPruneThreshold), zu langsames Lernen lässt Splats zu kompakt bleiben und Density-Control muss zu oft splitten.
T10rotationLearningRate
DETAILS
Default: 0.001 (Initializer + Paper), 0.002 (.full, MCMC — 2×) Range: 0.0001 – 0.05 Defined in:
TECHNISCH
Adam-Lernrate für die vier Quaternion-Komponenten jeder Gaussian. Die Quaternion wird in jedem Optimizer-Schritt nach der Adam-Update wieder normalisiert (L2-Norm = 1) — andernfalls würde die Kovarianzmatrix entartet. RadianceKit verdoppelt den Paper-Default in den Quality-Presets, weil Rotation gegenüber Skala / Position kleinere absolute Gradient-Magnituden hat (auf der Einheitssphäre bleibt jeder Schritt kurz) und ohne 2× wäre die Rotation im 35 000-Iterations-Window deutlich unter-konvergiert. V188 dokumentiert. Auf NeRF-Blender-Szenen (Lego, Chair) wirkt sich Rotation besonders aus — die Kanten der Objekte richten sich erst nach 5 000–10 000 Iterationen richtig aus.
Densification — Classic (T11–T16)
T11densifyGradThreshold
DETAILS
Default: 0.000002 (Initializer, kalibriert für 0.5× Auflösung), 0.0000011 (.full, kalibriert für 1.0×), 0.000004 (.quickTest, kalibriert für 0.25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (auflösungsabhängig) Defined in:
TECHNISCH
Schwellwert für die L2-Norm des bildschirmraum-projizierten Gradienten dMean2D, oberhalb dessen eine Gaussian für Klonen oder Splitten markiert wird. Der absolute Wert hängt direkt von der Trainingsauflösung ab — dMean2D skaliert ungefähr wie 1/Auflösung² (mehr Pixel = kleinere Per-Pixel-Gradienten). Daher braucht jede T22 trainingRenderScale-Stufe einen kalibrierten Schwellwert: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). Der Paper-Default 0.0002 ist NDC-normalisiert und in RadianceKits Welt-Raum-Pipeline nicht direkt vergleichbar. Mit dem in V440 zugeschalteten T52 adaptiveDensifyThreshold-Flag lässt sich der Wert in Laufzeit aus dem p98 der aktuellen Gradient-Verteilung berechnen — aber V440 testete das auf realen Szenen und produzierte 63 K Gaussians (katastrophaler Pruning-Verlust); das Flag bleibt aus. Q5 (T77–T79) liefert eine alternative Adaptive-Logik via rolling median. Gefahrlos ist dieses Feld nicht — Halbierung erzeugt 2–4× mehr Gaussians (Speicher-Druck, OOM-Risiko); Verdopplung kann die Szene unter-densifizieren.
T12densifyFromIteration
DETAILS
Default: 500 Range: 100 – 5 000 Defined in:
TECHNISCH
Erste Iteration, ab der Densification aktiv wird. Vorher passiert nur „nacktes" Lernen auf der initialen SfM-Punktwolke, ohne dass neue Gaussians erzeugt werden. Der Default 500 stammt aus dem 3DGS-Paper und gibt der Initialisierung Zeit, sich zu stabilisieren — wenn schon ab Iteration 0 densifiziert wird, klonen sich falsch positionierte SfM-Punkte vielfach, bevor sie überhaupt ihren richtigen Platz finden. V349 testete 1000 → leicht schlechter Loss; der Default ist optimal.
T13densifyInterval
DETAILS
Default: 100 (Initializer, MCMC), 200 (.full) Range: 50 – 1 000 Defined in:
TECHNISCH
Wie viele Iterationen zwischen zwei Densification-Schritten liegen. Im Paper-Default 100 — alle 100 Iterationen wird die Liste der densify-Kandidaten ausgewertet, geklont/gesplittet und gleichzeitig die Liste der prune-Kandidaten (sigmoid(opacity) < T14 pruneOpacityThreshold) entfernt. V112-Tests fanden 200 als optimal für .full — das entlastet die GPU, weil weniger Reorganisations-Passes laufen, und gibt jeder Gaussian mehr Zeit, sich nach einer Klone-Aktion einzupendeln. V417 testete 100 mit beta2=0.99 → 5.8 % schlechter (957 K Gaussians, Überdensifizierung). Bei MCMC wird dasselbe Feld als Relocation-Interval interpretiert; siehe T67 mcmcRelocationInterval für die MCMC-spezifische Logik.
T14pruneOpacityThreshold
DETAILS
Default: 0.005 (Initializer, Paper, MCMC), 0.001 (.full) Range: 0.0001 – 0.1 Defined in:
TECHNISCH
Sigmoid-Opazitäts-Schwelle, unter der eine Gaussian beim nächsten Densification-Step gelöscht wird. Wirkt zusammen mit T7 opacityLearningRate und der Logit-Clamp-Logik im Optimizer. V393 senkte den Default von 0.005 auf 0.001 in .full — Folge: Splats die nur unter exotischen Blickwinkeln eine Rolle spielen, bleiben länger erhalten und tragen zur SH-Detail bei. V394 testete 0.0001 → leicht schlechter (zu wenig gepruntet, Speicher verschwendet). Wichtig: Density-Control muss IMMER prunen, auch wenn die Buffer-Kapazität durch andere Maßnahmen schon voll ist (siehe „Density Control Must Always Prune" in CLAUDE.md) — sonst akkumulieren tote Gaussians und der Count friert ein.
T15opacityResetInterval
DETAILS
Default: 3 000 (Initializer + Paper), 100 000 (.full = effektiv deaktiviert), 200 000 (.fullMCMC = deaktiviert) Range: 1 000 – 100 000+ Defined in:
TECHNISCH
Alle wie viele Iterationen wird die Opazität aller Gaussians auf einen niedrigen Wert (~0.01) zurückgesetzt — eine Maßnahme aus dem 3DGS-Paper, um „eingefrorene" Splats neu zu beurteilen. V194 zeigte, dass mit RadianceKits Warmup + Stochastic-Trainings-Setup + 2× Lernraten der Opacity-Reset 5.5 % Qualität kostet und der Logit-Clamp die Reset-Funktion bereits abdeckt. Daher in .full praktisch deaktiviert (100 000 > 35 000 = nie ausgelöst). V421 testete Reset alle 3 000 mit beta2=0.99 → 4.9 % schlechter; reverted. Bei .fullClassicPaper (Q1.5-A, Paper-treuer Test) ist es bewusst wieder auf 3 000 gesetzt — das war eines der Lever, mit denen die Paper-Magnitude-Gaussian-Budgets erreicht werden sollten.
T16maxScreenSize
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 (off) oder > 0 Defined in:
TECHNISCH
Maximale Bildschirmraum-Größe (in projizierten Pixeln), die eine Gaussian erreichen darf, bevor sie zwangsweise gesplittet wird. Der Wert ist auf 0 gesetzt (V48 testete und reverted) — RadianceKits Density-Control verwendet stattdessen den Welt-Raum-Skala-Schwellwert aus der dMean2D-Logik. Bleibt im Feldkatalog enthalten, weil künftige Experimente mit Mip-Splatting (T74–T76) oder szenenspezifischen Splatting-Strategien davon profitieren könnten. Aktivierung (Wert > 0, z.B. 20) würde sehr groß gewordene Splats im Bildschirm zwingen, sich aufzuteilen — relevant bei großen, glatten Wandflächen, wo ein einzelnes Riesensplat zu wenig Detail bietet.
Loss (T17–T20)
T17ssimWeight
DETAILS
Default: 0.2 (Initializer + Paper + .full), 0.05 (alle MCMC-Presets) Range: 0.0 – 1.0 Defined in:
TECHNISCH
Gewicht des D-SSIM-Anteils in der kombinierten Loss-Funktion loss = (1 - λ) * L1 + λ * D-SSIM, wobei λ = T17. Der 3DGS-Paper-Default 0.2 ist für Classic-Densification optimal — V383 testete 0.3 → 28.9 % schlechter, V373b bestätigte 0.2 als sweet spot. Für MCMC wurde in V521b/V534 unabhängig festgestellt: 0.05 ist optimal, weil MCMC durch seine stochastische Exploration einen stärkeren L1-Signal-Anteil braucht — höhere SSIM-Gewichte würden die Relocation-Entscheidungen verwässern. SSIM ist deutlich teurer zu rechnen als L1 (lokale 11×11-Fenster über das ganze Bild); RadianceKit nutzt eine MPS-beschleunigte Implementierung, die unter 1 ms pro 1080p-Bild bleibt. Q7-BayesOpt-Sweeps fanden szenenspezifische Optima zwischen 0.05 (.outdoorPreset: 0.082) und 0.171 (.indoorPreset).
T18ssimWeightRefinement
DETAILS
Default: 0.0 (= „kein Wechsel, behalte ssimWeight") Range: 0 oder 0 – 1.0 Defined in:
TECHNISCH
Optionaler SSIM-Wert für die Refinement-Phase nach T2 densifyUntilIteration. V428 testete 0.2 → 0.3 im Refinement → 16 % schlechterer Loss (sowohl L1 als auch SSIM verschlechterten sich); revertet, daher Default 0.0. Die Hypothese hinter dem Feld war, dass nach der Densification — wenn keine neuen Gaussians mehr entstehen — ein stärkerer SSIM-Anteil die strukturelle Schärfe maximieren würde. Empirisch falsch: SSIM-Gewicht zu erhöhen heißt indirekt L1-Gewicht zu senken, und L1 ist das deutlich aussagekräftigere Signal in der Final-Refinement-Phase. Das Feld bleibt verfügbar für künftige Experimente mit perceptueller Loss (T60) oder Edge-Loss (T19), wo eine Refinement-spezifische Loss-Komposition sinnvoll sein könnte.
T19edgeLossWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.001 – 1.0 Defined in:
TECHNISCH
V437-Experimental-Loss: Gewicht eines Sobel-Gradient-Domain-L1-Loss, der die Bildkanten direkt vergleicht (Ground-Truth-Sobel vs Render-Sobel) zusätzlich zu L1+SSIM. Hypothese: Kanten-Information ist ein perceptueller Eckpfeiler von Bildqualität und ein expliziter Term sollte Gaussians ermutigen, Kanten besser zu treffen. Test-Ergebnisse: Gewicht 0.1 → 11 % schlechterer Loss, 0.01 → quality-neutral aber 10 % langsamer. Der Sobel-Pass kostet einen zusätzlichen MPS-Forward auf Ground-Truth und Render. Daher dauerhaft deaktiviert. Künftiger Use-Case: Szenen mit harten künstlichen Kanten (Architektur, Möbel, Renderings) könnten profitieren — Q7-Scene-Class-Presets haben das aber nicht gepickt, sondern stattdessen das SSIM-Gewicht skaliert.
T20skyMaskingEnabled
DETAILS
Default: false (Initializer und alle Presets) Range: boolean Defined in:
TECHNISCH
Schaltet Sky Masking ein. Dabei wird in jedem Bild via Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest) die Sky-Region ausmaskiert, und der Loss in diesem Bereich auf null gesetzt. Sinn: Outdoor-Szenen leiden oft daran, dass blaue/graue/weiße Sky-Pixel die App dazu bringen, Gaussians genau dort zu plazieren — was als „floater" wahrgenommen wird. Ohne Sky-Mask wäre der Loss in diesem Bereich nie null, weil der Himmel im Bild leicht variiert und die App ewig versucht, das mit Splats nachzubauen. Die Vision-Maske wird einmal pro Kamera vor dem Training berechnet und im RAM gehalten. Wird typischerweise zusammen mit T45 skyDomeEnabled aktiviert (UI-Logik in der Settings-View). Bei Innen-Szenen oder synthetischen Renderings deaktiviert lassen — die Maske würde dort fälschlicherweise Decken oder Wände als „Sky" erkennen.
SH-Degree-Progression (T21)
T21shDegreeUpgradeIterations
DETAILS
Default: [1_000, 2_000, 3_000] (Initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — Degree 3 übersprungen) Range: [Int], jeder Wert in [0, maxIterations], monoton steigend Defined in:
TECHNISCH
Iterationen, an denen der aktive SH-Degree von 0→1, 1→2, 2→3 hochgeschaltet wird. Vor der ersten Marke sind nur die DC-Komponenten aktiv (also T5 shDCLearningRate), nach der ersten Marke die DC + 3 Degree-1-Koeffizienten, nach der zweiten Marke + 5 Degree-2-Koeffizienten, nach der dritten Marke alle 15 Koeffizienten. Der Speicherbedarf pro Gaussian wächst dabei in Stufen — 4 Floats → 16 Floats → 36 Floats → 64 Floats. Die Quality-Presets verzögern die Aufstufungen gegenüber Initializer Defaults (V228), weil die Geometrie zuerst stabilisieren soll, bevor die Farbdetails mit ihrer höheren Frequenz draufkommen. V384 testete [1K, 2K, 3K] für .full → 9.3 % schlechter — bestätigt das Delay. .preview kappt bei Degree 2, weil Degree 3 in 5 000 Iterationen nicht konvergiert und nur Optimizer-Kapazität verbraucht. Q6 (T80–T81) bietet eine alternative Curriculum-Logik, die diese Liste dynamisch überschreibt.
Performance (T22–T25)
T22trainingRenderScale
DETAILS
Default: 1.0 (Initializer, .full, MCMC, Scene-Class), 0.5 (.preview), 0.25 (.quickTest) Range: 0.05 – 2.0 (typisch 0.25, 0.5, 1.0) Defined in:
TECHNISCH
Render-Auflösung beim Training relativ zur Originalauflösung der Trainingsbilder. Bei 0.5 wird jedes Bild auf 50 % Breite × 50 % Höhe heruntergerechnet (also 25 % der Pixel) und das Gaussian-Rendering erfolgt in dieser kleineren Auflösung. Reduziert sowohl Speicher- als auch Rechenaufwand quadratisch. Wichtig: T11 densifyGradThreshold muss zur gewählten Auflösung passen — die Gradient-Magnituden skalieren mit 1/Auflösung², daher hat .quickTest (0.25×) einen viel höheren Threshold (4e-6) als .full (1.0×, 1.1e-6). RadianceKit warnt bei sehr großen Bildern und passt automatisch an — 3-MP-Ziel-Auflösung. Bei extremen 4K-Eingangsbildern wäre 0.5 oder sogar 0.25 sinnvoll, sonst läuft jeder Mac auch nur in CPU-Compaction.
T23resolutionWarmupScale
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.1 – Defined in:
TECHNISCH
V133-Optimierung: Trainiere die Densification-Phase (Iter 0 bis T2) in einer niedrigeren Auflösung als die Refinement-Phase. V308 hat sie für .full wieder ausgeschaltet, weil bei T22 = 1.0 und Cosine-Annealing der Time-Win marginal war und Qualität minimal litt. Bleibt im Feldkatalog, weil sie bei 4K-Eingaben und langen Trainingsläufen wieder sinnvoll werden könnte — Q6 Curriculum (T80) hat eine ähnliche Logik aufgegriffen, dort ist sie aber an die LR-Schedule gekoppelt. Wenn aktiviert und T80 curriculumResolutionRamp ebenfalls true, gewinnt Q6 und überschreibt diesen Wert.
T24tileSize
DETAILS
Default: 16 Range: 8, 16, 32 Defined in:
TECHNISCH
Größe der Rasterisierungs-Tiles in Pixeln. Das Gaussian-Splatting-Rendering ist tile-basiert: das Bild wird in 16×16-Pixel-Kacheln zerlegt, jede Kachel sammelt die für sie relevanten Gaussians, sortiert sie nach Tiefe und blendet sie ein. 16 ist der von praktisch allen 3DGS-Implementierungen verwendete Standard und in den RadianceKit-Metal-Kernels hartkodiert; eine Änderung dieses Werts würde Re-Compilation der Shader bedingen und ist im aktuellen Stand nicht effektiv. Bleibt als Feld, falls eine künftige Engine-Version Tile-Size dynamisch unterstützt.
T25throttleDelayMs
DETAILS
Default: 0 (Initializer, .full, MCMC, Scene-Class), 0 (.preview) Range: 0 – 100 Defined in:
TECHNISCH
Künstliche Verzögerung zwischen Trainings-Iterationen in Millisekunden. 0 = volle Geschwindigkeit (Standard). Höhere Werte machen den Mac während des Trainings „benutzbarer", indem GPU/CPU regelmäßig Atempausen bekommen — die Bedienfreundlichkeit anderer Apps steigt, die Trainingszeit aber linear mit dem Delay. Typische Werte: 1–2 ms („leichtes" Throttling, +5 % Trainingszeit, Mac fühlt sich responsiver an), 5 ms („Mittelschwer", +15 % Trainingszeit), 10+ ms („Eco", potentiell doppelte Trainingszeit). Wird im Inspector unter „Performance" geboten, ist aber nicht in der Standardansicht — siehe Backlog dev_ux-backlog.md, der vorschlägt, ihn aus dem Expert View zu entfernen, weil falsch verstanden er die Trainingszeit dramatisch verlängert.
Diagnose und Punktwolken-Vorbereitung (T26–T30)
T26depthDistortionWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.0001 – 0.05 Defined in:
TECHNISCH
V366-Experimental: Gewicht eines Depth-Distortion-Regularisierungs-Loss. Bestraft Gaussians, die entlang eines Render-Strahls zwar tief gestaffelt sind, aber konzeptuell zur selben Oberfläche gehören — das encouraged konzentrierte Tiefenverteilungen und reduziert Floaters. Tests: 0.01 → 4.5 % schlechter, 0.001 → 8.1 % schlechter. Der theoretische Vorteil — Multi-View-Konsistenz verbessern — schlägt sich nicht im L1-Loss nieder, weil die Hypothese implizit annimmt, dass die SfM-Geometrie korrekt ist und die Gaussians nur „gestapelt" werden müssen. In der Praxis ist die SfM-Punktwolke meist die schwächste Komponente, nicht die Stapelung. Bleibt verfügbar für Multi-View-Datensätze mit besonders sauberen Posen (Synthetic, Mip-NeRF 360 mit Ground Truth).
T27singleViewOverfit
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Diagnose-Flag: wenn true, wird in jeder Trainingsiteration zwingend Kamera-Index 0 verwendet statt einer zufällig aus dem Camera-Pool. Sinn: Wenn das Modell nicht mal eine einzige View überfitten kann (sprich, der Loss auf View 0 auch nach 10 000 Iterationen nicht gegen Null geht), ist im Forward/Backward-Pass ein fundamentaler Bug. Dieser Schalter wurde während der Entwicklung der Metal-Shader und der Differentiable-Rasterizer-Kernels intensiv genutzt — V42–V47 Phase. Heute nur noch als Sanity-Check verfügbar, wenn jemand Backend-Code modifiziert hat und ein Regression Test machen will. Per CLI mit –single-view.
T28maxCameras
DETAILS
Default: 0 (= „alle Kameras verwenden") Range: 0 oder 1 – N Defined in:
TECHNISCH
Diagnose-Limit aus V43: trainiere nur mit den ersten N Kameras, ignoriere alle weiteren. Sinn ursprünglich: Hypothese testen, dass zu viele Kameras Gradient-Konflikte erzeugen (zu viele widersprüchliche Loss-Signale für dieselbe Gaussian). Test-Ergebnis: kein systematischer Vorteil bei künstlicher Begrenzung — Mehr-Frames bringen praktisch immer mehr Qualität. Bleibt als CLI-Flag (–max-cameras N) für gezielte Experimente, z.B. „funktioniert das Training auf den ersten 100 Bildern eines 1 500-Bild-Drohnenflugs?" Im UI nicht exponiert.
T29maxInitialPoints
DETAILS
Default: 0 (= „alle SfM-Punkte verwenden") Range: 0 oder 1 000 – 200 000+ Defined in:
TECHNISCH
V54-Sicherung: limitiert die Anzahl der initialen SfM-Punkte, mit denen das Training startet. Dichte COLMAP-Rekonstruktionen können > 60 000 Punkte produzieren, was bei großen Initial-Skalen zu 200–300 Gaussians pro Pixel-Überlapp führt — das macht ein „Nebelfeld" aus, in dem das Training nicht konvergiert. Subsampling auf ~16 000 Punkte (Hard-cap-Logik in der Trainings-Engine) bringt die Initial-Dichte auf das Niveau, das das Referenz-3DGS verwendet, und reduziert Overlap dramatisch. Wird bei sehr dichten SfMs automatisch gesetzt; per CLI mit –max-points N.
T30cameraClusterOutlierMultiplier
DETAILS
Default: 10.0 (alle Presets — niemals überschrieben) Range: 1.0 – 100.0 Defined in:
TECHNISCH
Multiplikator für den Camera-Cluster-Outlier-Filter, eingeführt in Phase 3.10 A.1. Vor dem Training berechnet die Trainings-Engine das Centroid aller Kamera-Positionen und die maximale Distanz einer Kamera vom Centroid. SfM-Punkte, deren Distanz vom Centroid multiplier × maxCameraDistance überschreitet, werden als Outlier verworfen. Default 10× bewahrt das Verhalten vor Phase 3.10. Ein subtiler Bug: Tighter SfM (Kameras enger zusammen) → kleinerer → kleinerer Schwellwert → mehr Punkte werden als Outlier verworfen. Looser SfM → größerer Schwellwert → weniger Punkte verworfen. Dies ist eine der Ursachen für die Phase-3.9-Funnel-vs-Training-Anti-Korrelation: bessere SfM kann downstream zu schlechterem Training führen, weil zu viele Initialpunkte gekillt werden. Das Feld liegt als CLI-Override (–camera-cluster-outlier-multiplier) für die A.3-Sweeps; im UI nicht exponiert. Werte unter 5 sind in der Regel zu restriktiv, über 20 wirkungslos.
Regularisierung (T31–T37)
T31coarseToFineBlurRadius
DETAILS
Default: 0 (= deaktiviert) Range: 0 oder 1 – 10 Defined in:
TECHNISCH
V369-Experimental: Box-Blur-Radius, der zu Beginn der Densification-Phase auf das Ground-Truth-Bild angewendet und linear bis zum Ende der Densification (T2) auf 0 reduziert wird. Hypothese: Coarse-to-Fine-Training — erst grobe Strukturen lernen, dann Details — sollte stabilere Geometrie liefern. Tests: r=3 → 9.6 % schlechter, r=1 → 5.1 % schlechter. Der Grund für das Fehlschlagen: die Densification entscheidet basierend auf bilddomänen-Gradienten, und Bluren reduziert genau die Signale, die für „hier muss klone werden" wichtig sind. Bleibt im Feld-Katalog für künftige Tests mit anderem Density-Control-Schema.
T32scaleRegWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.0001 – 0.05 Defined in:
TECHNISCH
V370-Experimental: L1-Regularisierung auf welt-räumliche Skala. Bestraft Gaussians, die zu groß werden — verhindert „Mega-Splatts", die ganze Wandflächen mit einer Gaussian abdecken. Tests: 0.01 → 200 % schlechterer Loss (2 M Gaussians, totale Explosion), 0.001 → 214 % schlechter. Der Grund: Skala-Regularisierung kommt mit Density-Control in Konflikt — kleinere Skalen heißen, mehr Gaussians werden gebraucht, also splittet Density-Control häufiger, was wiederum mehr Gradient-Aufwand bedeutet. Disabled, aber dokumentiert für Mip-Splatting-Experimente (T74): in diesem Kontext könnte eine Skalen-Untergrenze sinnvoll sein.
T33anisotropyRegWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.0001 – 0.05 Defined in:
TECHNISCH
V445-Experimental: Penalty auf das max(scale)/min(scale)-Verhältnis, soll extrem langgezogene „Needle"-Gaussians verhindern, die als floater wahrgenommen werden. Tests: 0.01 → 69 % schlechter, 0.001 → 15 % schlechter. Der Grund: Regularisierung zwingt Splats in Richtung „runde" Form, was auf einer flachen Oberfläche (Wand, Tisch, Boden) genau falsch ist — dort ist eine flache, breite Gaussian effizienter als eine kugelförmige. Disabled. V549f bot mit T34 scaleRatioPruneThreshold einen alternativen, gezielteren Ansatz, der ebenfalls revertet wurde.
T34scaleRatioPruneThreshold
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 5.0 – 100.0 (typisch 10.0 – 30.0) Defined in:
TECHNISCH
Experimentelles post-Training-Pruning, das jede Gaussian löscht, deren max(scale)/min(scale)-Verhältnis den hier gesetzten linearen Schwellwert überschreitet. Zielt auf extrem langgezogene „Needle/Disc"-Floaters ab, die durch Regularisierung allein nicht eliminiert werden können. Im Test entfernte das Pruning Floaters wie erhofft, aber gleichzeitig auch sinnvolle flache Splats auf Wänden und Böden — das Bild wurde löchriger. Daher per Default aus, das CLI-Flag (–scale-ratio-prune N) bleibt für gezielte Experimente verfügbar. Empfohlene Werte falls man trotzdem testen will: 30 (sehr konservativ, entfernt nur extreme Outlier), 10 (aggressiv, kostet Detail).
T35opacityRegWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.0001 – 0.05 Defined in:
TECHNISCH
V446-Experimental: Binary-Cross-Entropy-Penalty, der Opazität gegen 0 oder 1 zieht (also weg von „halb-transparent"). Hypothese: scharfere Opazitätsverteilung würde Bildklarheit verbessern. Test mit T33 kombiniert → Regularisierung kostet Qualität, beide deaktiviert. Disabled. Achtung: in 1.4.3-Beta tauchte ein Bug auf, der genau dieses Feld in einer Default-Wert-Veränderung (Initializer = 0.01) hatte, was zu Mass-Extinction des Gaussian-Counts (460 K → 5 in einer Iteration) führte. Seit 1.4.4 fest auf 0.0 als Default verankert.
T36opacityDecayFactor
DETAILS
Default: 0.0 (Initializer = deaktiviert), 0.9995 (.full, .classicBalanced — HTGS-Standard) Range: 0 (off) oder 0.95 – 1.0 Defined in:
TECHNISCH
V546-Implementation des HTGS-Schemas (Hierarchical Time-Gating, Eurographics 2025): alle T37 opacityDecayInterval Iterationen wird die sigmoid-Opazität jeder Gaussian mit diesem Faktor multipliziert. 0.9995 × 100 Anwendungen ergibt ~95 %-Verbleib pro Densification-Phase — ein leichter aber stetiger Abwärts-Druck auf alle Opacities, der schwach beigetragende Gaussians verlässlich gegen den T14 pruneOpacityThreshold sinken lässt. Das Resultat: 14 % besserer L1-Loss auf Horse Full (3-Trial-Avg V546) gegenüber V438 ohne Decay. Nur während Densification-Phase aktiv (bis T2), danach läuft das Training ohne Decay weiter, damit die im Refinement etablierten Opacities stabil bleiben. Bei MCMC nicht verwendet (MCMC hat eigene Mechanismen via T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETAILS
Default: 50 Range: 10 – 500 Defined in:
TECHNISCH
Iterations-Intervall, in dem T36 opacityDecayFactor angewendet wird. HTGS-Paper-Default 50, in .full belassen. Lange Intervalle (>200) heben den Effekt teilweise auf, weil zwischen zwei Anwendungen genug Gradient-Updates passieren, dass Opacity wieder steigt. Kürzere Intervalle (<20) machen Decay zu aggressiv. Nur in Densification-Phase aktiv.
Refinement (T38–T44)
T38gradientAccumulationSteps
DETAILS
Default: 1 (= „eine View pro Adam-Schritt") Range: 1 – 8 Defined in:
TECHNISCH
V424-Feature: Anzahl der Views, deren Gradienten akkumuliert werden, bevor ein Adam-Update ausgeführt wird. Bei > 1 läuft die App auf einem separaten, „unfused" Backward-Project-Pfad, der die Gradienten in einem separaten Buffer summiert; die finale Anwendung skaliert mit 1/N, um die Magnitude konstant zu halten. V424 testete 2-View → quality-neutral, aber 10 % langsamer (weil unfused-Pfad teurer ist als fused-Pfad). Reverted für .full, aber für MCMC bewusst verwendet — .fullMCMC läuft mit, aber V544a-Tests zeigten, dass mit der Quality-Gap zu Classic auf 5 % schrumpft (statt 11 %). Im Initializer-Default 1, im aktuellen Preset 1, bleibt CLI-Flag (–accum-steps N).
T39testViewIndices
DETAILS
Default: [] (= leer, alle Views werden zum Training verwendet) Range: Set<Int>, beliebige Untermenge der Camera-Indices Defined in:
TECHNISCH
V546-Feature: Set von Camera-Indices, die NICHT zum Training verwendet, sondern als Holdout für PSNR/SSIM/LPIPS-Auswertung gespart werden. Wird automatisch gesetzt, wenn der –benchmark-CLI-Flag aktiv ist: dann jede achte View, beginnend bei Index 0 (LLFF-Standard, identisch mit den Mip-NeRF-360- und 3DGS-Paper-Konventionen). Ohne benchmark leer — das Training nutzt alle Views. Vorsicht: das manuelle Setzen dieses Feldes ohne Verständnis der Indizes kann den Benchmark unbrauchbar machen (z.B. wenn alle Indices über N gesetzt werden, während es nur N-50 Views gibt → keine Holdouts → keine Auswertung). Beim eigenen Preset-Export wird testViewIndices nicht persistiert, weil es szenenabhängig ist und sonst zwischen verschiedenen Datensätzen sinnlose Werte hinterlassen würde.
T40refinementPruneInterval
DETAILS
Default: 0 (= deaktiviert) Range: 0 oder 100 – 5 000 Defined in:
TECHNISCH
V425-Feature: alle N Iterationen während der Refinement-Phase (nach T2) wird ein zusätzlicher Prune-Pass laufen gelassen, der Gaussians mit sigmoid(opacity) < T41 refinementPruneOpacityThreshold entfernt. Sinn: während Densification gibt es regelmäßige Density-Control-Calls, danach nicht mehr — Gaussians, deren Opacity weiter sinkt, bleiben aber im Buffer. V425 testete und reverted: das zusätzliche Pruning korrelierte mit V426 (Two-Phase Densification, ebenfalls in 0 Gaussians cascade failure abgebrochen). Disabled. CLI-Flag verfügbar für Experimente; falls aktiviert, sind 1 000 oder 2 000 sinnvolle Werte.
T41refinementPruneOpacityThreshold
DETAILS
Default: 0.0 (= „verwende T14") Range: 0 oder 0.001 – 0.1 Defined in:
TECHNISCH
V425b: separater Opacity-Schwellwert für Refinement-Pruning. Nach Densification haben die meisten Gaussians eine deutlich höhere Opacity erreicht (> 0.001), sodass der Standard-T14 pruneOpacityThreshold zu lasch wäre. Wenn T40 aktiv, bestimmt dieses Feld den eigenen Schwellwert. Bei 0.0 wird T14 weiterverwendet. Nur relevant wenn T40 > 0.
T42midTrainingCompactificationIterations
DETAILS
Default: [] (= deaktiviert) Range: [Int], Werte in (densifyUntilIteration, maxIterations) Defined in:
TECHNISCH
V549-Feature: explizite Iteration-Punkte während der Refinement-Phase, an denen ein Compactification-Pass läuft (entfernt sigmoid(opacity) < 0.01 + Outlier-Scale-Gaussians, dieselbe Logik wie T56 postTrainingCompactification). Sinn: lange Refinement-Phasen können Confetti-/Floater-Akkumulation zeigen, deren SH dann auf view-spezifische Artefakte überfitten. Typische Konfiguration falls aktiviert: [10000, 20000, 30000] für 40K Classic. ABER: V549-A/B-Tests auf Family-Dataset zeigten in allen Konfigurationen schlechteres L1: [10K,20K,30K]@0.01 → −48 % Count aber +36 % L1; [20K,30K]@0.005 → −44 % Count aber +45 % L1; [20K,30K]@0.001 → −17 % Count aber +87 % L1. Daher disabled. CLI-Flag –mid-compact "10000,20000" verfügbar, falls man den visuellen Floater-Tradeoff (weniger Confetti im Viewport) gegenüber dem Loss-Regression bevorzugt.
T43frustumCullEnabled
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V549b-Feature: nach Training werden alle Gaussians entfernt, die außerhalb der Vereinigung aller Trainings-Kamera-Frusta liegen. Solche Gaussians wurden nie vom Loss-Signal eingeschränkt und sind immer Floater. Besonders effektiv für Szenen, in denen die Novel-View hinter oder neben dem Kamerapfad liegt (z.B. Rückseite eines linearen Drohnenflugs) — die Floater dort werden in der Trainingsphase nie sichtbar, beim späteren Bewegen im 3D-Viewer aber sehr wohl. V549b A/B auf Drohnenflügen positive Ergebnisse, daher als Opt-In verfügbar. Default false, weil bei Object-Captures mit voller Orbit-Coverage die Frustum-Union die ganze Szene umfasst und das Feature nichts entfernt — wird in Settings unter „Floater Reduction" angeboten und auch in Q9 Outdoor-Preset implizit über T44 frustumCullExpansion getestet (Q7-BayesOpt hat es aber nicht aktiviert, weil Outdoor-Sky-Dome dasselbe Problem besser löst).
T44frustumCullExpansion
DETAILS
Default: 1.1 Range: 1.0 – 2.0 Defined in:
TECHNISCH
NDC-Margin für T43 frustumCullEnabled. 1.0 würde exakt am Bildrand schneiden, was wackelige Splatts am Bildrand zu sehr kürzen würde. 1.1 = 10 % Padding über die exakte Kamera-Framing hinaus — gibt etwas Toleranz für Randpixel, die in einer leicht versetzten Novel-View doch sichtbar werden könnten. Werte > 1.2 machen den Cull praktisch unwirksam, weil das erweiterte Frustum sehr viel mehr Raum umfasst.
Sky-Dome (T45–T48)
T45skyDomeEnabled
DETAILS
Default: false (Initializer + alle Presets außer P9 Outdoor) Range: boolean Defined in:
TECHNISCH
V549e-Feature: vor Training-Start wird eine kugelförmige Punktwolke generiert (Fibonacci-sphere mit T46 Sample-Points), in einem Radius von T47 skyDomeRadiusMultiplier × scene_extent um den Szenen-Mittelpunkt platziert und mit den Farben aus den sky-maskierten Pixeln aller Trainings-Kameras (siehe T20 skyMaskingEnabled) initialisiert. Diese Sky-Dome-Gaussians werden am Anfang des Gaussian-Buffers eingefügt und während Training „eingefroren" (Position/Skala/Rotation-Gradienten = 0, nur SH und Opacity bleiben optimierbar). Effekt: statt schwarzer „Confetti"-Bereiche in der Ferne sieht der User in Novel-Views einen echten Himmel. V549e-MVP funktioniert auf Drohnen- und Landschaftsszenen sehr gut; in P9 Outdoor-Preset Default-on. Bei Innen-Szenen aus lassen — die Sphere würde sinnlos außerhalb des Raums hängen.
T46skyDomeSampleCount
DETAILS
Default: 5 000 Range: 1 000 – 50 000 (typisch 2 000 – 10 000) Defined in:
TECHNISCH
Anzahl der Fibonacci-Sphere-Sample-Punkte auf der Sky-Dome-Sphere. Höhere Werte → dichteres Sky-Dome (besser bei großen Auflösungen und viel sichtbarem Himmel), aber mehr Speicherbedarf. 5 000 ist sweet spot für 4K-Renderings; bei niedrigeren Auflösungen reicht 2 000–3 000. Die Punkte werden nach Cosine-Distance zu jedem Trainings-Kamera-View-Vektor mit den entsprechenden sky-maskierten Pixeln initialisiert — Sample-Points, deren View-Cone keine Kamera sieht, bleiben mit niedrigem Opazitäts-Initialwert hinten, werden aber im Training nicht verändert (eingefroren).
T47skyDomeRadiusMultiplier
DETAILS
Default: 30.0 (Initializer + meisten Presets), 59.0 (P9 Outdoor, Q7-BayesOpt-Optimum) Range: 5.0 – 200.0 Defined in:
TECHNISCH
Radius der Sky-Dome-Sphere relativ zur Szenen-Ausdehnung (= mittlere Distanz zwischen Kamera-Positionen). 30 = die Kugel hat den 30-fachen Durchmesser der Kamera-Wolke. Zu klein (< 5) → Sky-Dome interferiert mit der Szene selbst (z.B. ein Sky-Dome-Splatt landet im Vordergrund); zu groß (> 100) → float32-Präzisionsverlust an den Sky-Dome-Positionen, was Render-Glitches in der Ferne auslöst. Q7-BayesOpt auf Bicycle (Mip-NeRF 360) fand 59.0 als szenenspezifisches Optimum für outdoor — das deutet darauf hin, dass die Standard-30.0 für tiefe Landschaften zu klein ist und die Sky-Dome-Pixel in den Bildrand-Bereichen sichtbar als „Wand" rendern.
T48frozenGaussianCount
DETAILS
Default: 0 (= keine eingefrorenen Gaussians) Range: 0 oder 1 – T46 Defined in:
TECHNISCH
Anzahl der Gaussians am Anfang des Buffers, deren Position/Skala/Rotation-Gradienten im Optimizer auf null gesetzt werden — sie bleiben über das gesamte Training räumlich starr. Density-Control darf sie nicht klonen, splitten oder prunen. Genutzt für Sky-Dome-Injection (siehe T45): wenn Sky-Dome an ist, wird dieses Feld automatisch auf T46 skyDomeSampleCount gesetzt. Manuelles Setzen ist möglich (z.B. um eine vor-platzierte Punktwolke aus einem LiDAR-Scan einzufrieren), aber im UI nicht direkt zugänglich. Wichtig: die ersten N Gaussians im Buffer sind immer die frozen — die Reihenfolge im Buffer entscheidet, nicht ein expliziter Index.
Adam + LR-Schedule (T49–T55)
T49adamResetIteration
DETAILS
Default: 0 (= deaktiviert) Range: 0 oder 100 – Defined in:
TECHNISCH
V430-Feature: Iteration, an der die Adam-Optimizer-Momentum-Akkumulatoren (m1, m2) auf null zurückgesetzt werden. Bias-Korrektur danach läuft mit (iter - adamResetIteration) statt mit iter. V430 testete Reset bei 5 000 (nach Densification-Ende) → 12.8 % schlechter Loss. Grund: das Adam-Momentum, das sich während Densification aufgebaut hat, trägt Information über die typischen Gradient-Magnituden bei und beschleunigt die Refinement-Phase. Es wegzuwerfen kostet die ersten ~500 Iterationen Refinement an Konvergenz. Disabled. Bleibt CLI-Flag für Forschungsexperimente.
T50positionLRScheduleEndIteration
DETAILS
Default: 0 (Initializer = „verwende maxIterations"), 20 000 (.full — Cosine endet bei 20K trotz maxIter=35K), 30 000 (.fullClassicPaper) Range: 0 oder 1 000 – Defined in:
TECHNISCH
V431-Feature: Iteration, an der die Cosine-Annealing-Kurve für Position-LR ihr Minimum erreicht. Wenn 0, ist das identisch mit T1 maxIterations. Wenn > 0, läuft die Schedule bis zu diesem Wert und bleibt danach bei T4 positionLearningRateFinal konstant. Das erlaubt eine „extended refinement phase" mit minimaler aber konstanter Lernrate — verfeinert Positionen langsam ohne erneuten Decay. .full macht das (Schedule-Ende bei 20K, Training läuft bis 35K), V434c/V434d bestätigten: 15K und 25K beide etwa gleich, 20K minimal optimal. Wird in Verbindung mit T51 weiterverwendet, um auch die Nicht-Position-LRs in der extended phase zu modifizieren.
T51extendedPhaseLRDecay
DETAILS
Default: 0.0 (= deaktiviert, konstante LRs) Range: 0 oder 0.01 – 1.0 Defined in:
TECHNISCH
V433-Feature: minimaler Multiplikator für die Nicht-Position-LRs (Skala, Rotation, Opacity, SH) in der „extended phase" — sprich: nachdem T50 erreicht ist und Position-LR bereits bei T4 ist. Wenn 0.1, werden Skala/Rotation/Opacity/SH ihrerseits cosine-decayed von 1.0 (= ihr Standard-LR) auf 0.1× ihres Standards. Wenn 0.0 (Default), bleiben sie konstant. V457 testete vollen Decay (0.0 = decay-bis-null) gegen kein-Decay und fand: avg 0.0400 (2 Runs) = gleicher Loss wie V438 ohne Decay. Behavior cleaner mit Decay, aber nicht messbar besser. Daher disabled. Bleibt im CLI als –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V440-Experimental: wenn true, berechnet die App in jedem Densification-Schritt das p98 der aktuellen Gradient-Verteilung und nutzt es als dynamischen Schwellwert (geclamped auf mindestens 0.5× des konfigurierten Werts aus T11, damit es nicht zu sehr ausreißt). Hypothese: Automatische Anpassung an aktuelle Szenen-Phase würde Density-Control robuster machen — z.B. zu Anfang strenger pruning, später lasser, oder umgekehrt. V440 testete und revertete: katastrophaler Drop auf 63 K Gaussians (Mass-Pruning, weil das p98 in den ersten Iterationen extrem hoch ist und dann fast nichts den Threshold überschreitet). Der fixe Threshold ist bereits gut kalibriert, dynamische Anpassung schadet mehr als sie nutzt. Q5 (T77) bietet eine alternative Adaptive-Logik via rolling median, die das Problem umgeht.
T53mergeAfterDensification
DETAILS
Default: false (Initializer), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Defined in:
TECHNISCH
V438-Feature: am Ende der Densification-Phase (Iter T2) wird ein einmaliger Merge-Pass durchgeführt, der nahe beieinanderliegende Gaussians mit ähnlicher Skala und Farbe zusammenfasst. Reduziert die Gaussian-Anzahl um typisch 5–15 % ohne sichtbaren Qualitätsverlust. Sinn: nach intensivem Klonen entstehen Cluster von quasi-identischen Gaussians, die nichts Neues beitragen — das Merging gibt Optimizer-Kapazität für andere Bereiche frei. Standard in Classic-Quality-Presets. Bei MCMC nicht verwendet, weil MCMC durch seine Relocation-Logik solche Cluster gar nicht erst entstehen lässt.
T54densifyPhase2FromIteration
DETAILS
Default: 0 (= deaktiviert) Range: 0 oder T2 – T1 Defined in:
TECHNISCH
V426-Experimental: ermöglicht eine zweite Densification-Phase, die nach der Refinement-Pause bei dieser Iteration startet und bis T55 läuft. Hypothese: nach einer Refinement-Phase haben die Gradient-Akkumulatoren stabilere Magnitudes und können präziser sagen, welche Bereiche noch zusätzliche Gaussians brauchen. V426 testete und revertete: Two-Phase Densification fiel in 0-Gaussians-Cascade-Failure (mit V425 Refinement-Pruning kombiniert zerstörte es den Buffer). Disabled. CLI-Flag verfügbar für Experimente.
T55densifyPhase2UntilIteration
DETAILS
Default: 0 Range: 0 oder T54 – T1 Defined in:
TECHNISCH
Ende der V426-Two-Phase-Densification. Nur relevant wenn T54 > 0. Beide Felder zusammen disabled.
Post-Processing + Apple AI (T56–T60)
T56postTrainingCompactification
DETAILS
Default: true (in allen Production-Presets), false (.quickTest, .preview) Range: boolean Defined in:
TECHNISCH
V443-Feature: nach Trainingsende werden Gaussians mit sigmoid(opacity) < 0.01 hart entfernt (sie tragen praktisch nicht mehr zum Bild bei). Reduziert Gaussian-Count um typisch 58 % und Export-Dateigröße um 55 % ohne sichtbaren Qualitätsverlust. Standardmäßig in Production-Presets aktiv — das Endresultat soll möglichst kompakt ausgeliefert werden können. In .quickTest aus, weil ein Diagnose-Lauf sowieso nicht exportiert wird. Anders als T42 midTrainingCompactificationIterations (V549) findet die Compactification erst am Ende statt — Refinement kann bis dahin alle Gaussians benutzen.
T57metalFXUpscaling
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V444-Feature: aktiviert Apples MetalFX Spatial Upscaler statt bilineare Interpolation im 3D-Viewer-Output. Wenn Trainingsauflösung < Viewport-Größe (z.B. Training auf 0.5×, Viewport-Anzeige in voller Auflösung), kann MetalFX ein deutlich schärferes Bild liefern. Ändert sich live im Viewport, kein Re-Training nötig. Schließt sich mit T58 mpsLanczosScaling aus — MetalFX hat Vorrang. Empfehlung: einschalten, wenn das Bild im Viewer „verwaschen" wirkt im Vergleich zum erwarteten Detail.
T58mpsLanczosScaling
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
V444-Feature: MPSImageLanczosScale für Viewport-Skalierung statt bilineare Interpolation. Lanczos ist ein klassisches Sinc-basiertes Resampling-Verfahren, das deutlich schärfere Ergebnisse als Bilinear liefert mit minimalem Overhead. Live-Toggle. Wird von T57 überschrieben, wenn beide an.
T59livePreviewInterval
DETAILS
Default: 50 (Initializer und meisten Presets) Range: 0 (off) oder 10 – 5 000 Defined in:
TECHNISCH
Wie oft während des Trainings der 3D-Viewer mit den aktuellen Gaussians aktualisiert wird. 50 = alle 50 Iterationen ein neues Render im Viewer — gut genug, um den Fortschritt zu beobachten, ohne das Training zu verlangsamen. 0 = Viewer wird gar nicht aktualisiert (Hintergrund-Training, max Geschwindigkeit). Typische Anpassung: bei .quickTest runter auf 10 (man will jeden Schritt sehen), bei langen MCMC-Läufen hoch auf 500–2000 (Update-Overhead in Summe spürbar).
T60perceptualLossWeight
DETAILS
Default: 0.0 (= deaktiviert) Range: 0 oder 0.001 – 0.5 Defined in:
TECHNISCH
V444-Future-Feature: Gewicht eines perceptuellen Loss-Terms via MPSGraph (VGG-ähnliches kleines Netzwerk). Würde strukturelle und texturelle Ähnlichkeit auf einer höheren semantischen Ebene als L1+SSIM erfassen — typisch in Forschungs-Pipelines, wo „pixel-perfect" weniger wichtig ist als „sieht realistisch aus". Implementation noch ausstehend (Code-Stub vorhanden, aber Forward-Pass nicht implementiert). Default 0.0. Bleibt im Feldkatalog für künftige Aktivierung; CLI-Flag –percep-weight F reserviert.
MCMC-Densification (T61–T73)
T61densificationStrategy
DETAILS
Default: .classic (Initializer + Classic-Presets), .mcmc (alle MCMC-Presets + Scene-Class) Range: .classic oder .mcmc Defined in:
TECHNISCH
Wählt zwischen Classic-Densification (Klon/Split/Prune, Kerbl et al.~2023) und MCMC-Densification (Stochastic Gradient Langevin Dynamics mit Relocation, Kheradmand et al.~NeurIPS 2024). Bei .classic werden T11–T16 ausgewertet, bei .mcmc die T62–T73. Achtung beim Wechsel: Classic Defaults und MCMC Defaults sind völlig anders kalibriert — wer den Picker im Expert View flippt, ohne ein passendes Preset zu laden, riskiert 1.4.3-Bug-Style Mass-Extinction (460 K → 5 in einer Iteration, weil MCMC-OpacityReg auf 0.01 die Classic-Opacities killt). Daher die MCMC-Init Defaults absichtlich „weichgespült" (alle Reg-Werte 0.0).
T62mcmcMaxGaussians
DETAILS
Default: 150 000 (Initializer + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — Mip-Splatting-Variante mit 10× Budget), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) Range: 0 (= „verwende Buffer-Kapazität") oder 10 000 – 5 000 000 Defined in:
TECHNISCH
Harte Obergrenze für die Anzahl der Gaussians bei MCMC-Strategie. Die Anzahl wächst graduell um T70 mcmcGrowthRate (typisch 5 %) pro Relocation-Step bis zu diesem Cap. V473/V531 fanden 150 K als sweet spot — über 200 K dilutet die Splat-Qualität (zu viele kleine, redundante Gaussians), unter 100 K bleibt die Szene unter-densifiziert. Bei sehr großen Szenen (z.B. 1 545-Foto-Drohnenflug mit 158 K SfM-init) ist 150 K zu niedrig — daher die 1.4.5-Erweiterung T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt fand szenenspezifische Optima zwischen 670 K (Indoor) und 1.25 M (Outdoor). Bei Wert 0 verwendet die Engine die volle Buffer-Kapazität als Cap.
T63mcmcNoiseScale
DETAILS
Default: 0.00005 (5e-5 = Paper-Default) Range: 1e-6 – 1e-3 Defined in:
TECHNISCH
Multiplikator für das Gauss'sche Rauschen, das in jeder MCMC-Iteration zur Position jeder Gaussian addiert wird (SGLD-Logik). Höher = mehr Exploration (Gaussians wandern mehr, finden potenziell bessere Plätze), niedriger = mehr Exploitation (Gaussians bleiben da, wo sie schon gut sind). V467 und V536 bestätigten 5e-5 als optimal — 1e-5/2e-5 zu wenig Exploration, 1e-4 zu viel (Splats zerlaufen). Wird über die Trainingszeit cosine-decayed bis T69 mcmcNoiseDecayEnd — am Ende des Decay-Bereichs ist Noise effektiv 0 und die Gaussians konvergieren.
T64mcmcOpacityRegWeight
DETAILS
Default: 0.0 (= deaktiviert in den RadianceKit Defaults, Paper: 0.01) Range: 0 oder 0.001 – 0.05 Defined in:
TECHNISCH
MCMC-spezifische L1-Penalty auf Opacity. Paper-Default 0.01 (drückt unbenutzte Gaussians gegen Null, macht sie für Relocation verfügbar). V464b zeigte aber: ohne Reg ist es in RadianceKit messbar besser (Session 28 bestätigt). Grund: Das mit T68 mcmcDeadOpacityThreshold definierte Pruning-Kriterium reicht alleine — eine zusätzliche L1-Penalty zwingt auch wertvolle, niedrig-Opacity-Gaussians zum Sterben. Daher Default 0. Achtung: in 1.4.3-Beta-Build war der Initializer-Default fälschlich 0.01, was im Mass-Extinction-Bug resultierte (siehe T61-Erläuterung); seit 1.4.4 auf 0.0 fixiert.
T65mcmcScaleRegWeight
DETAILS
Default: 0.0 (= deaktiviert, Paper: 0.01) Range: 0 oder 0.001 – 0.05 Defined in:
TECHNISCH
MCMC-spezifische L1-Penalty auf die Skala-Eigenwerte. Paper-Default 0.01. V464b: ohne Reg besser, gleiche Begründung wie T64. Disabled in allen RadianceKit-MCMC-Presets. Achtung wie bei T64: 1.4.3-Bug.
T66mcmcRelocationInterval
DETAILS
Default: 100 (Initializer + alle MCMC-Presets, Paper-Standard), 155 (P9 Outdoor — Q7-BayesOpt-Optimum) Range: 50 – 500 Defined in:
TECHNISCH
Iterations-Intervall, in dem MCMC tote Gaussians (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) zu neuen Positionen relociert. V537 testete 50 (zu disruptiv, Loss schwankt) und 200 (marginal schlechter, MCMC verliert Reaktionsfähigkeit). 100 ist optimal. Q7-BayesOpt auf Bicycle fand 155 als szenenspezifisches Optimum für outdoor — die etwas längeren Intervalle geben Adam mehr Zeit, neu plazierte Gaussians zu integrieren, bevor das nächste Reloc-Event sie unter Druck setzt.
T67mcmcWarmupIterations
DETAILS
Default: 500 Range: 100 – 5 000 Defined in:
TECHNISCH
Anzahl der Initial-Iterationen, in denen noch keine MCMC-Relocation passiert. Erst nach diesem Warmup beginnt die Reloc-Logik. Sinn: in den ersten Iterationen sind die Opacity-Werte noch nicht eingeschwungen — würde direkt mit Reloc gestartet, würden Gaussians an den falschen Stellen plaziert und müssten gleich wieder bewegt werden, was Adam-Momentum zerstört. Paper-Default 500. RadianceKit übernimmt diesen Wert, weil V464b zeigte dass es robust ist.
T68mcmcDeadOpacityThreshold
DETAILS
Default: 0.005 (Initializer, Paper-Standard), 0.01 (.fullMCMC und alle MCMC-Presets — V535-Optimum) Range: 0.001 – 0.05 Defined in:
TECHNISCH
sigmoid(Opacity)-Schwellwert, unter dem eine Gaussian als „tot" gilt und für Relocation in Frage kommt. V535 fand 0.01 als optimal (0.005 marginal, 0.02 schlechter). Höher = aggressiveres Reloc (mehr Gaussians werden bewegt), niedriger = vorsichtiger. 0.01 entspricht ungefähr „0.5 % visuelle Sichtbarkeit". P10 Indoor verwendet via Q7-BayesOpt 0.0142 als Optimum.
T69mcmcNoiseDecayEnd
DETAILS
Default: 0 (Initializer = „kein Decay"), 160 000 (.fullMCMC = 80 % von 200K), 96 000 (.mcmcBalanced = 80 % von 120K), 40 000 (.mcmcPreview) Range: 0 oder 1 000 – Defined in:
TECHNISCH
Iteration, an der das T63 mcmcNoiseScale-Rauschen vollständig auf null gedämpft wird (Cosine-Decay von Iter 0 bis hier). V497c/V502 fanden 80 % der maxIterations optimal — gibt MCMC genug Exploration-Zeit, lässt aber die letzten 20 % zur Konvergenz ohne Rauschen. 0 = konstantes Rauschen über alle Iterationen (selten sinnvoll, MCMC kann dann nicht konvergieren).
T70mcmcGrowthRate
DETAILS
Default: 0.05 (Paper-Standard = 5 %) Range: 0.01 – 0.2 Defined in:
TECHNISCH
Wachstumsrate des MCMC-Populations-Targets pro Relocation-Step. Die Logik: bei jedem Reloc-Event wird das Ziel-Populations-Größe um (1 + growthRate) erhöht, bis T62 mcmcMaxGaussians (oder die per T72/T73 skalierte Variante) erreicht ist. V512/V522 fanden 0.05 als optimal — höhere Werte führen zu zu schnellem Wachstum (Gaussians werden eingefügt, bevor das Adam-Momentum sie integrieren kann), niedrigere zu unter-densifizierten Szenen am Ende.
T71mcmcSigmoidK
DETAILS
Default: 100.0 Range: 10.0 – 500.0 Defined in:
TECHNISCH
Sigmoid-Sharpness-Parameter für die MCMC-Noise-Attenuation. Im SGLD-Schritt wird das pro-Gaussian-Rauschen durch gedämpft — hoch-opake Gaussians (deren Logit positiv ist) bekommen exponentiell weniger Rauschen als niedrig-opake. K = 100 ist scharf, sprich der Übergang von „voll-Noise" zu „kein-Noise" passiert sehr schnell um Opacity 0.5. V484–V487 fanden K = 100 optimal — kleinere Werte (10–50) lassen auch hoch-opake Gaussians mit-Wackeln (zerstört konvergierte Gaussians), größere (> 500) machen den Übergang künstlich hart und tote Gaussians werden gar nicht mehr bewegt.
T72mcmcCapMultiplier
DETAILS
Default: 3.0 (Initializer + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Range: 0 (= deaktiviert) oder 1.0 – 10.0 Defined in:
TECHNISCH
1.4.5-Feature: szenen-adaptive Cap-Skalierung. Wenn T73 mcmcAutoScaleByScene true ist, wird der effektive Cap als berechnet (geclamped an Buffer-Kapazität). Hintergrund: bei großen Szenen (z.B. 1 545-Foto-Drohnenflug → 158 K SfM-init) ist T62 = 150 000 zu niedrig — Density-Control würde gar nicht wachsen können. Mit Multiplier 3.0 wird der Cap bei diesem Beispiel auf 474 K skaliert (158 K × 3.0). Q7-BayesOpt fand szenenspezifische Optima: Outdoor profitiert von hohem Multiplier (5.32 → ~830 K Cap bei 156 K bicycle-init), Indoor begnügt sich mit 1.76 (Wände sättigen schneller). Komplette Auflösung des Caps siehe -Methode.
T73mcmcAutoScaleByScene
DETAILS
Default: true (Initializer + alle MCMC-Presets) Range: boolean Defined in:
TECHNISCH
1.4.5-Feature: Master-Switch für die scene-aware Cap-Logik (siehe T72 +). Wenn false, wird ausschließlich T62 mcmcMaxGaussians als Cap verwendet (zurück zu 1.4.4-Verhalten). Standardmäßig an, weil die Mass-Extinction-Probleme bei großen Szenen aus 1.4.3 sonst wiederkehren. Manuell deaktivieren nur, wenn du explizit ein hartes Cap setzen willst — z.B. um eine 150 K-Variante zu trainieren, deren Endgröße planbar ist.
Mip-Splatting (Q1.5) (T74–T76)
Status: Q1.5 wurde am 2026-05-25 nach 14 autonomen Iterationen + Overnight-1.5M-Confidence-Check als „closed no-win" verworfen (max Δ@2× = +0.27 dB, Original-Gate verlangte ≥ +1.5 dB Mittelwert über 0.5×/2×, FAILT auf 0/11 Pair-Scenes). Die Felder bleiben opt-in für Forschungs-Experimente; alle Production-Presets haben. Siehe Verdict:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETAILS
Default: false (alle Production-Presets), true (.fullMCMCMip — Forschungs-Sibling) Range: boolean Defined in:
TECHNISCH
Aktiviert Mip-Splatting (Yu et al.~CVPR 2024): 3D-Smoothing-Filter + 2D-Filter + α-Kompensation, der die per-Gaussian-Frequenz auf die Nyquist-Grenze der dichtesten Trainingskamera-Sampling-Rate begrenzt. Theoretisches Ziel: Eliminierung von Aliasing bei Rendering in off-training-Skalen (0.5× oder 2× der Trainingsauflösung). In den Preprocess- und Backward-Projection-Shadern aktiviert, funktional korrekt verifiziert in Q1.5-D-Test. Aber: der Original-Akzeptanz-Gate (Δ@1× ≥ +0.3 dB UND avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) wurde auf keinem von 11 Pair-Scenes erreicht. Maximal beobachtet: family 750K classic Δ@2× = +0.270 dB. Outdoor-Szenen (Truck, Flowers) zeigten sogar Verschlechterung 1× und 0.5×. Hypothese: 3D-Smoothing konkurriert mit MCMC-Relocation bei high-Gs. Feld bleibt für künftige Multi-Scale-Re-Eval mit korrekter Mip-NeRF-360-Methodology (siehe O3-Backlog im Benchmark-Pfad).
T75mipSmoothing3DScale
DETAILS
Default: 0.2 (Paper-Default) Range: 0.05 – 1.0 Defined in:
TECHNISCH
3D-Smoothing-Skala-Parameter (Yu et al.~§3.3, Paper-Default 0.2). Größer = mehr Welt-Raum-Glättung pro Gaussian (= mehr Anti-Aliasing, aber auch mehr blur in der Default-Skala), kleiner = schärfer aber anfälliger für Aliasing. Wird nur konsultiert, wenn T74 useMipSplatting = true. In Q1.5-Tests nicht weiter optimiert — die A/B-Gate hat schon mit Paper-Default 0.2 verloren, weitere Sweeps wären zwecklos.
T76mipFilter2DVariance
DETAILS
Default: 0.3 (= exakt das V242-Legacy-Verhalten) Range: 0.1 – 1.0 Defined in:
TECHNISCH
2D-Mip-Filter-Varianz, die zur Σ_2D-Diagonale addiert wird (Varianz direkt, nicht quadriert). 0.3 ist exakt der V242-Legacy-Wert, der vor Mip-Splatting hardcoded im Kernel war. Wenn T74 useMipSplatting = false, ignoriert der Kernel diesen Wert komplett und schreibt das hartkodierte 0.3 — sodass die Baseline nicht regredieren kann (Codex-Round-1-S3-1-Garantie). Wenn, wird der hier gesetzte Wert verwendet. Bleibt im Feld-Katalog für Mip-Sweeps.
Adaptive Densification (Q5) (T77–T79)
T77adaptiveDensification
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q5-Feature: rolling-median-Tracker als Alternative zum fixen T11 densifyGradThreshold. Wenn true, wird in jedem Densify-Step der aktuelle Schwellwert mit median(letzte N avgGrad-Samples) × T79 adaptiveDensifyMultiplier überschrieben. N = T78 adaptiveWindow. Strikter als V440 p98 (die katastrophale 63 K-Pruning-Falle), median + 2× sitzt etwa beim p70–p80 der Gradient-Verteilung in steady state. Q5-Tests: alleinstehend FAIL 0/3 Szenen, aber gemeinsam mit Q6 (siehe T80/T81) PASS 1/3 Szenen — das Bundle Q5+Q6 wurde 2026-05-25 als opt-in gepasst und ist via CLI –adaptive-densify aktivierbar. Q6 ist dabei der „Carrier" des Quality-Gewinns, Q5 trägt eher zur Stabilität bei.
T78adaptiveWindow
DETAILS
Default: 1 000 Range: 100 – 10 000 Defined in:
TECHNISCH
Rolling-Median-Window in Densification-Events (NICHT Iterationen — jeder T13 densifyInterval-Step liefert ein Sample). Default 1 000 — bei heißt das die letzten 100 000 Trainings-Iterationen tragen zum Median bei, also typisch die gesamte Trainingshistorie bis hierhin. Frühe Phase (vor T78 Samples): Tracker returns nil → Fallback auf fixen Threshold T11. Nur relevant wenn.
T79adaptiveDensifyMultiplier
DETAILS
Default: 2.0 Range: 1.0 – 4.0 Defined in:
TECHNISCH
Multiplikator auf den Rolling-Median für den adaptiven Schwellwert. Default 2.0 entspricht ungefähr p70–p80 der typischen Gradient-Verteilung. Niedriger = aggressiveres Wachstum (mehr Klone), höher = strenger (weniger Klone). Q5-Tests in Range 1.5–3.0 — 2.0 bestes Default. Nur relevant wenn.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q6-Feature: Trainings-Auflösung startet bei 0.5× und wechselt bei T50 positionLRScheduleEndIteration / 2 (oder T1 maxIterations / 2, falls T50 nicht gesetzt) auf T22 trainingRenderScale. Verwendet die in Q1.5.1 entwickelte resize/restoreImageBuffers-Infrastruktur. Überschreibt T23 resolutionWarmupScale, wenn aktiviert. Q6 ist als „Carrier des Quality-Gewinns" im Q5+Q6-Bundle gepasst (siehe T77) — die schrittweise Auflösungserhöhung gibt der App Zeit, grobe Geometrie auf der niedrigeren Auflösung zu finden, bevor sie zur feinen Detailarbeit übergeht. Über CLI: –curriculum-resolution.
T81curriculumSHProgression
DETAILS
Default: false Range: boolean Defined in:
TECHNISCH
Q6-Feature: überschreibt T21 shDegreeUpgradeIterations mit [maxIter/4, maxIter/2, maxIter*3/4], verteilt also die SH-Aufstufungen gleichmäßig über die Trainingszeit statt sie front-zu-loaden. Hypothese: stabile Geometrie wird vor Color-Detail-Explosion etabliert, was die View-Direction-abhängigen Glanz-Effekte präziser positioniert. Q5+Q6 zusammen PASS 1/3 Szenen, Q6 als Carrier des Gewinns (Q5 alone FAIL). Via CLI: –curriculum-sh.
Statische Presets (TP1–TP9)
Hier nur die strukturellen Unterschiede zum Initializer-Default. Die volle Marketing-Beschreibung der zehn UI-Presets P1–P10 findest du in Kapitel 7.
TP1.preview
DETAILS
Diagnose-/Vorschau-Preset für Systeme ≥ 10 GB RAM. Overrides gegenüber Initializer: - 30 000 → 5 000 - 15 000 → 3 500 (70 % von maxIter) - 1.6e-6 → 1.6e-5 (10× höher, weniger aggressiver Decay) -,,,, jeweils 2× (V176) - 3 000 → 100 000 (effektiv aus, V172: Reset zerstört kurze Trainings) - [1K, 2K, 3K] → [1K, 2K] (V182: Degree 3 konvergiert in 2K Iter nicht) - 1.0 → 0.5
TP2.full
DETAILS
Production-Quality Classic. Overrides: - 30 000 → 35 000 (V550: 40K-Tests Truck-Overtraining +10.7 % Gs bei -1.3 % L1) - 15 000 → 5 000 (V310 sweet spot, V338 7K worse) - Alle LRs 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 disabled, V421 confirmed) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 delayed) - 0.0 → 0.9995 (V546 HTGS, 14 % Verbesserung) - 50 (unverändert, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, schon Initializer-Default für .full)
TP3.fullClassicPaper
DETAILS
Q1.5-A-Test-Sibling von TP2, paper-treuer Classic. Overrides gegenüber TP2: - 35 000 → 30 000 (Paper-Standard) - 5 000 → 15 000 (Paper: 50 % von maxIter) - 1.6e-5 → 1.6e-6 (Paper-Default) -,, zurück auf Paper Defaults (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (kalibriert für ~1-2M Gs auf Bicycle) - 200 → 100 (Paper) - 0.001 → 0.005 (Paper-Default) - 100 000 → 3 000 (Paper §5.2, riskant — kann V194-Regression auslösen) - 0.9995 → 0.0 (Paper hat keinen Decay) - 20 000 → 30 000 (cosine läuft auf 100 % von maxIter)
TP4.fullMCMC
DETAILS
Production-Quality MCMC. Overrides gegenüber Initializer: - 30 000 → 200 000 (V534, MCMC braucht 5× mehr Iter als Classic) - 15 000 → 160 000 (V504b 80 % von maxIter) - 1.6e-6 → 1.6e-5 - LR-Schedule wie TP2 (alle 2×) - 0.2 → 0.05 (V521b/V534: MCMC braucht stärkeres L1-Signal) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (im Initializer schon, im Preset bestätigt) - 5e-5 (V467/V536 optimal) - 0.005 → 0.01 (V535 optimal) - 0 → 160 000 (80 % von maxIter, V497c/V502) - 3.0 (im Initializer schon) - true (im Initializer schon) - 3 000 → 200 000 (effektiv aus, MCMC nutzt Reloc statt Reset)
TP5.fullMCMCMip
DETAILS
Q1.5-D-Test-Sibling von TP4, mit Mip-Splatting + Paper-Magnitude-MCMC-Budget. Overrides gegenüber TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, Paper-Magnitude) - useMipSplatting false → true (Mip-on)
TP6.classicBalanced
DETAILS
Mid-Tier Classic. Overrides gegenüber TP2: - 35 000 → 20 000 (V149: 20K = 30K bei 33 % weniger Zeit) - 20 000 → 0 (Cosine läuft auf maxIter = 20K, kein extended phase)
TP7.mcmcPreview
DETAILS
MCMC-Diagnose. Overrides gegenüber TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: Preview = lighter scaling)
TP8.mcmcBalanced
DETAILS
Mid-Tier MCMC. Overrides gegenüber TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3.0 → 2.5 (zwischen Preview 2.0 und Full 3.0)
TP9.quickTest
DETAILS
Reiner Funktionstest. Overrides gegenüber Initializer: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (kalibriert für 0.25× Auflösung) - 100 → 50 - 3 000 → 100 000 (aus, da viel zu kurz) - 1.0 → 0.25
Methode:
Signature: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Defined in:
Einzige Source-of-Truth für die Frage „wie viele Gaussians darf MCMC maximal wachsen lassen?". Berechnet sich aus drei Eingaben: dem konfigurierten T62 mcmcMaxGaussians (mit Mass-Extinction-Floor 150 000, falls 0), dem (Anzahl der SfM-Init-Punkte) und der (vorallozierte Gaussian-Buffer-Größe). Logik:
+ base = T62 > 0 ? T62: 150_000 (der Mass-Extinction-Floor schützt gegen Initializer-Default-Bugs wie den 1.4.3-Mass-Extinction-Vorfall) + Falls T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) sonst
+ Falls bufferCapacity > 0: return min(scaled, bufferCapacity) + Sonst return scaled
Beispiel: Bicycle (Mip-NeRF 360, 194 Foto-Frames) → SfM-init ~156 K Punkte, T62 = 150 000, T72 = 5.32,, Buffer-Kapazität 8 M. Resolved Cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. Das ist der effektive Wachstums-Cap, an den die MCMC-Relocation-Logik sich hält.
Berechnet die wirkliche maximale Splat-Anzahl bei MCMC. Nimmt deine Einstellung, schaut sich an, wie viele Punkte deine Szene anfangs hat, und skaliert mit dem Multiplier, falls die automatische Anpassung an ist. So passt sich der Cap an die Szene an, statt für eine kleine und eine riesige Szene den gleichen Wert zu erzwingen. Du musst die Methode nicht selbst aufrufen — das Training nutzt sie intern.
Welches Feld wofür? (Cheat-Sheet)
| Ziel | Felder zum Drehen |
|---|---|
| Mehr Detail in der Ferne | T62 mcmcMaxGaussians hoch, T72 mcmcCapMultiplier 5+ |
| Mehr Detail allgemein (Classic) | T1 maxIterations hoch (≤ 40K), T2 densifyUntilIteration ≤ 14 % von T1 |
| Floater in Drohnenflügen reduzieren | T43 frustumCullEnabled an, T20 skyMaskingEnabled an, T45 skyDomeEnabled an |
| Schöner Himmel in Außen-Szenen | T45 skyDomeEnabled an, T47 skyDomeRadiusMultiplier 30–60 |
| Kleinere Export-Datei | Strategie .mcmc (T61), T56 postTrainingCompactification an, T62 mcmcMaxGaussians ≤ 200K |
| Schnelleres Training | T22 trainingRenderScale 0.5, T1 maxIterations halbieren — aber nicht beides! |
| Bessere Glanzlichter | T21 shDegreeUpgradeIterations mit [2K, 5K, 8K] (kein early-front-load), MCMC + 200K iter |
| Mac responsiv halten | T25 throttleDelayMs 5–10 (kostet ~15 % Trainingszeit) |
| Live-Vorschau häufiger | T59 livePreviewInterval runter auf 10–20 |
| Sanftere Übergänge an Schatten | T17 ssimWeight etwas hoch (0.15–0.25), aber nicht über 0.3 |
| Innenräume kompakt halten | P10 Indoor-Preset (, T72 = 1.76) |
Gefährliche Felder
Diese Felder können bei Falsch-Konfiguration zu OOM, App-Crash, Mass-Extinction der Gaussians oder unbrauchbaren Benchmark-Daten führen. Mit Vorsicht zu behandeln:
- T11 densifyGradThreshold — eine Halbierung kann 2–4× so viele Gaussians erzeugen, was schnell den GPU-Speicher sprengt. Auch zu beachten: muss zur T22 trainingRenderScale passen (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — bei großen Szenen mit > 200 K SfM-init-Punkten und Multiplier > 5 entsteht ein Resolved-Cap von Millionen Gaussians. Auf 36-GB-RAM-Macs OOM möglich. Outdoor-Preset 5.32 funktioniert nur, weil Mip-NeRF-360-Bicycle 156 K init-Punkte hat → 830 K Cap. - T39 testViewIndices — manuelles Setzen kann den Benchmark unbrauchbar machen (alle Indices > N → keine Holdouts). Lass das –benchmark-Flag das setzen. - T64 mcmcOpacityRegWeight und T65 mcmcScaleRegWeight — In 1.4.3-Beta auf 0.01 gesetzt, was zu Mass-Extinction führte (460 K → 5 Gaussians in einer Iteration). Seit 1.4.4 auf 0.0 fixiert, aber manuelles Erhöhen kann das Problem reproduzieren. - T15 opacityResetInterval — wenn nicht 100 000+ (effektiv aus) und das Training kürzer als 10 000 Iterationen ist, zerstört der Reset die Konvergenz. .preview hat es deshalb auf 100 000 trotz maxIterations = 5 000. - T54/T55 densifyPhase2* — Two-Phase Densification ist in Tests in 0-Gaussians-Cascade abgebrochen. Lass beide auf 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, kann auf manchen Outdoor-Szenen sogar PSNR verschlechtern. Default off, opt-in nur für Forschung.
Wenn ein Feld auf dieser Liste steht und du es ändern willst, mache vorher eine Sicherung deines aktuellen Presets (Export als JSON) und überlege, ob du das Resultat reproduzierbar messen kannst — sonst weißt du hinterher nicht, ob du eine Verbesserung oder Verschlechterung herbeigeführt hast.