Bölüm 6 — Eğitim Yapılandırması
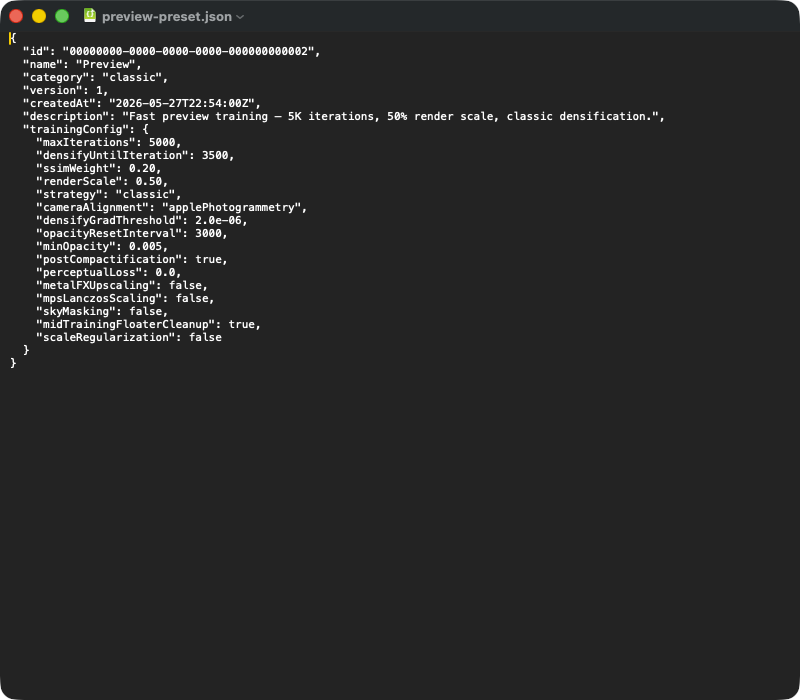
Tipik bir önayar JSON dışa aktarması. Üst düzey alanlar: id (UUID), name, (classic | mcmc | sceneClass | custom), (şema sürümü), (zaman damgası), (serbest metin). İç içe nesne yeniden üretilebilirlik için kritik parametreleri içerir — içe aktarmada tüm blok TrainingConfig yapısına deserialize edilir ve uygulama sürümünün varsayılanları JSON'da eksik alanları doldurur (ör. uygulama güncellemesinden sonra). Bir önayarı başka bir Mac'e aktarmak isteyen, bu JSON dosyasını basitçe gönderir.
TrainingConfig yapısı RadianceKit'teki her eğitim çalıştırmasının kalbidir. Eğitimi etkileyen her parametreyi toplar — maksimum iterasyon sayısından sekiz öğrenme hızına ve MCMC, Mip-Splatting, müfredat ve sahne farkındalıklı üst sınır mantığı için özel alanlara kadar. Bunu kenar çubuğunda Eğitim Yapılandırması bölümü alanında (Expert View) düzenler, bir önayar olarak kaydeder veya başka bir Mac'e JSON dışa aktarımı olarak iletirsin. Eğitim sırasında tam olarak bu nesne dondurulur ve GPU arka ucuna iletilir.
Bu bölüm güç kullanıcıları ve script yazarları için referans malzemesidir. Tüm 81 herkese açık alanı, 9 statik önayarı ve tek herkese açık yöntemi listeler. Kaynak dosya TrainingConfig.swift'dir — şüphede orada saklanan doc yorumu ve başlatıcı varsayılanı tek doğruluk kaynağıdır.
İçindekiler:
+ İterasyon (T1–T2) + Öğrenme hızları (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH derece ilerlemesi (T21) + Performans (T22–T25) + Tanı ve nokta bulutu hazırlığı (T26–T30) + Düzenleme (T31–T37) + İnce ayar (T38–T44) + Sky-Dome (T45–T48) + Adam + LR programı (T49–T55) + Son işleme + Apple AI (T56–T60) + MCMC Densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Uyarlanabilir Densification (Q5) (T77–T79) + Müfredat (Q6) (T80–T81) + Statik önayarlar (TP1–TP9) + Yöntem: + Hangi alan ne için? (kopya kağıdı) + Tehlikeli alanlar
İterasyon (T1–T2)
T1maxIterations
DETAYLAR
Varsayılan: 30 000 (inizializzatore), 35 000 (.full), 200 000 (.fullMCMC) Range: 1 000 – 500 000 (slider UI), nessun limite superiore rigido nella logica Tanımlandığı yer:
TEKNİK
Numero totale di iterazioni di training che il backend esegue. Un'iterazione indica un forward render di una singola fotocamera di training, un backward pass su tutti i componenti di loss (L1 + SSIM + regolarizzazioni opzionali + sky mask) e uno step Adam optimizer. Questo numero agisce direttamente sugli altri schedule: la learning rate di posizione segue una curva di cosine annealing da 0 fino o a T1 stesso o a T49 positionLRScheduleEndIteration; la densification si ferma a T2 densifyUntilIteration; il decadimento del rumore MCMC termina a T69 mcmcNoiseDecayEnd; gli upgrade del grado SH avvengono ai tre marker definiti in T21. Con densification classica il sweet spot determinato empiricamente è 20 000–35 000 iterazioni (sessioni 1–32, test V546), con MCMC 60 000–200 000 (V534). Un aumento drastico oltre i valori memorizzati nel preset raramente porta qualità aggiuntiva — l'Adam momentum satura, e senza fine del LR decay il loss ristagna. Viceversa, scendere sotto ~5 000 porta a geometrie convergenti in modo incompleto (il density control ha troppo poco tempo per clone/split).
T2densifyUntilIteration
DETAYLAR
Varsayılan: 15 000 (inizializzatore), 5 000 (.full), 160 000 (.fullMCMC) Range: 0 – Tanımlandığı yer:
TEKNİK
Iterazione a partire dalla quale la densification si ferma. Fino a qui le gaussiane vengono clonate, divise e prune secondo le regole parametrizzate in T11–T16 (Classic) o T67–T70 (MCMC); dopo il numero di gaussiane rimane costante e solo posizioni, rotazioni, scale, opacità e coefficienti SH vengono ottimizzati (fase di refinement). Nel paper 3DGS originale il valore è al 50% di T1, nel preset .full di RadianceKit solo a ~14% (5 000 su 35 000) — conseguenza degli esperimenti V310/V338, che hanno mostrato che dopo 5 000 iterazioni un'ulteriore densificazione peggiora piuttosto il risultato (più floater, più memoria, nessun guadagno di qualità). MCMC invece esegue la rilocazione fino all'80% di T1 (V504b), perché MCMC non produce floater dannosi. Se T2 è troppo piccolo (< 1 000), nascono troppe poche gaussiane; troppo grande con Classic (> 50% di T1) porta a overgrowth e RGB saturation outlier (vedi findings di outdoor overtraining).
Öğrenme hızları (T3–T10)
T3positionLearningRate
DETAYLAR
Varsayılan: 0.00016 Range: 1e-7 – 1e-3 (raccomandato) Tanımlandığı yer:
TEKNİK
Learning rate Adam per la posizione XYZ di ogni gaussiana all'inizio del training (iterazione 0). Segue una curva di cosine annealing e scende durante il training a T4 positionLearningRateFinal. Il default 0.00016 proviene dal paper 3DGS originale (Kerbl et al. 2023) e in RadianceKit non va scalato anche all'aumentare della risoluzione dell'immagine — la posizione si muove nel sistema di coordinate mondo, non nello spazio dei pixel. Un aumento significativo (> 0.0005) fa sì che le gaussiane saltino su lunghe distanze e il loss diventi instabile; valori significativamente più bassi (< 0.00005) portano nuvole di punti inizializzate in modo errato a non trovare mai il loro posto. V414 ha testato il raddoppio del valore di init → 16.8% di loss L1 peggiore; i tuning V544a hanno confermato il default del paper come ottimale. Nota: con .fullMCMC lasciamo deliberatamente questo valore al default — MCMC ha bisogno di learning rate costanti per la sua logica di rilocazione, quindi il tuning qui non porta nulla.
T4positionLearningRateFinal
DETAYLAR
Varsayılan: 0.0000016 (inizializzatore + paper), 0.000016 (.full, .fullMCMC — 10× più alto) Range: 0 – Tanımlandığı yer:
TEKNİK
Valore finale della curva di cosine annealing della LR di posizione. Viene raggiunto o a T1 maxIterations o, se impostato, a T49 positionLRScheduleEndIteration. Il preset .full di RadianceKit usa 0.000016 — quindi 10× più alto del default del paper 0.0000016. Gli esperimenti V420 hanno mostrato che 0.5× del valore finale (0.000008) peggiora il loss del 6.4%; V414 ha mostrato che 2× del valore di init lo peggiora del 16.8%. L'alto valore finale non è un trade-off, ma una scelta deliberata: con decay troppo forte le gaussiane perdono nella fase di refinement la capacità di adattarsi ai candidati di densification appena aggiunti. Tramite l'estensione V431/V433 la fase schedule può essere accorciata (T49 < T1), in modo che T4 venga raggiunto già prima della fine del training e il resto del training corra con mini LR costante — configurazione tipica: T49 = 20 000, T1 = 35 000, refinement quindi a 0.000016 per 15 000 iterazioni.
T5shDCLearningRate
DETAYLAR
Varsayılan: 0.0025 (inizializzatore + paper), 0.005 (.full e tutti i preset MCMC — 2×) Range: 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Learning rate Adam per la quota DC (grado 0, quindi albedo costante) del colore SH. SH-DC corrisponde al tono base indipendente dalla direzione di una gaussiana, in un certo senso il "colore base". Gli esperimenti V176 e V188 hanno trovato 2× più alto del default del paper come ottimale — convergenza del colore più veloce, soprattutto perché con training breve (5 000 iterazioni) altrimenti SH-DC non si forma. A differenza delle LR geometriche SH-DC non ha decay; la learning rate rimane costante su tutte le iterazioni (o segue solo il decay opzionale extended phase di T51). V416 ha testato la quadruplicazione a 0.01 → 6.4% di loss peggiore con Adam beta2=0.99.
T6shRestLearningRate
DETAYLAR
Varsayılan: 0.000125 (inizializzatore + paper), 0.00025 (.full e MCMC — 2×) Range: 0.000001 – 0.005 Defined in:
TEKNİK
Learning rate Adam per i coefficienti SH di ordine superiore (grado 1, 2, 3 — quindi le quote di colore dipendenti dalla direzione di vista, che si occupano di luci speculari, riflessi e ombreggiature morbide). 20× più piccolo di T5 per convenzione del paper, perché questi coefficienti crescono quadraticamente in numero (3 per grado 1, 5 per grado 2, 7 per grado 3 → in totale 15 float per gaussiana) e senza learning rate più piccola sovrasaturerebbero l'immagine. Viene sbloccato in due passaggi — fino al primo marker in T21 shDegreeUpgradeIterations è attivo solo il grado 0 (quindi solo T5), dopo 1, poi 2, infine 3. Valori bassi qui sono particolarmente importanti su scene con molta illuminazione diffusa; su superfici molto lucide (vernice auto, acqua) non vale la pena regolare — la rappresentazione SH di per sé è limitata.
T7opacityLearningRate
DETAYLAR
Varsayılan: 0.05 (inizializzatore + paper), 0.1 (.full, MCMC — 2×) Range: 0.001 – 1.0 Tanımlandığı yer:
TEKNİK
Learning rate Adam per l'opacità logit di ogni gaussiana. L'app memorizza l'opacità come valore float non limitato e la trasforma con sigmoid in [0, 1]; la LR agisce nello spazio logit. Il default del paper 0.05 è ripristinato dopo i test V50 (best single run L1 0.1664), V71 ha ripristinato 0.025 di V67. Il raddoppio V188 a 0.1 rende il pruning più efficiente — le gaussiane morte cadono più velocemente sotto la T14 pruneOpacityThreshold. V418 ha mostrato: 0.05 con Adam beta2=0.99 è 7.1% peggiore di 0.1 — l'interazione con la configurazione Adam non è banale. Valori bassi (< 0.01) portano le gaussiane "morte" a rimanere in giro per sempre e consumare memoria; valori troppo alti (> 0.5) possono portare a esplosione dell'opacità, quindi il valore logit nell'optimizer viene limitato a [-15, 3] (vedi nota "Opacity Explosion Prevention" in CLAUDE.md).
T8opacityLearningRateFinal
DETAYLAR
Varsayılan: 0.0 (= "nessun decay") Range: 0 oppure 0.001 – Tanımlandığı yer:
TEKNİK
Valore finale opzionale di cosine decay per la LR di opacità (V427). Se 0.0, decay disabilitato e la LR di opacità rimane costante a T7 su tutto il training. V427 ha testato un decay 0.1 → 0.01 — risultato 11.5% di loss peggiore; revertito, da qui il default "off". L'ipotesi dietro il campo: nella fase di refinement una LR di opacità costante potrebbe portare a oscillazione, in modo che splat che hanno già raggiunto il giusto grado di trasparenza vengano spostati di nuovo da fluttuazioni casuali del gradiente. Empiricamente non si conferma — la logica di logit clamping lo intercetta comunque. Il campo rimane disponibile per esperimenti futuri; anche run MCMC molto lunghi (> 500K iterazioni) potrebbero beneficiarne.
T9scaleLearningRate
DETAYLAR
Varsayılan: 0.005 (inizializzatore + paper), 0.01 (.full, MCMC — 2×) Range: 0.0001 – 0.1 Tanımlandığı yer:
TEKNİK
Learning rate Adam per le tre componenti di scala di ogni gaussiana nello spazio log (RadianceKit memorizza log(scale), in modo che le scale rimangano positive). Il default del paper 0.005, in RadianceKit raddoppiato a 0.01 per migliore convergenza di scala con le configurazioni di learning rate ottimizzate. Esperimento V423: 0.005 con Adam beta2=0.99 → 18.7% di loss peggiore e visibilmente troppo poche gaussiane (il density control non poteva clonare, perché gli update di scala erano troppo lenti). La scala controlla l'estensione di ogni gaussiana — apprendimento troppo veloce porta a gaussiane "ago" (splat estremamente lunghi e sottili, vedi T34 scaleRatioPruneThreshold), apprendimento troppo lento fa rimanere gli splat troppo compatti e il density control deve splittare troppo spesso.
T10rotationLearningRate
DETAYLAR
Varsayılan: 0.001 (inizializzatore + paper), 0.002 (.full, MCMC — 2×) Range: 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Learning rate Adam per le quattro componenti quaternione di ogni gaussiana. Il quaternione viene rinormalizzato ad ogni step optimizer dopo l'update Adam (norma L2 = 1) — altrimenti la matrice di covarianza diventerebbe degenere. RadianceKit raddoppia il default del paper nei preset Quality, perché la rotazione rispetto a scala/posizione ha magnitudini di gradiente assolute più piccole (sulla sfera unitaria ogni step rimane breve) e senza 2× la rotazione nella finestra di 35 000 iterazioni sarebbe nettamente sotto-convergente. V188 documentato. Su scene NeRF-Blender (Lego, Chair) la rotazione si ripercuote in modo particolare — gli spigoli degli oggetti si allineano correttamente solo dopo 5 000–10 000 iterazioni.
Densification — Classic (T11–T16)
T11densifyGradThreshold
DETAYLAR
Varsayılan: 0.000002 (inizializzatore, calibrato per risoluzione 0.5×), 0.0000011 (.full, calibrato per 1.0×), 0.000004 (.quickTest, calibrato per 0.25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (dipendente dalla risoluzione) Tanımlandığı yer:
TEKNİK
Soglia per la norma L2 del gradiente proiettato nello screen space dMean2D, sopra la quale una gaussiana viene contrassegnata per clone o split. Il valore assoluto dipende direttamente dalla risoluzione di training — dMean2D scala approssimativamente come 1/risoluzione² (più pixel = gradienti per pixel più piccoli). Quindi ogni stadio di T22 trainingRenderScale ha bisogno di una soglia calibrata: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). Il default del paper 0.0002 è NDC-normalizzato e nella pipeline spazio-mondo di RadianceKit non direttamente confrontabile. Con il flag T52 adaptiveDensifyThreshold aggiunto in V440 il valore può essere calcolato in runtime dal p98 della distribuzione attuale del gradiente — ma V440 l'ha testato su scene reali e ha prodotto 63 K gaussiane (perdita catastrofica di pruning); il flag rimane off. Q5 (T77–T79) fornisce una logica adattiva alternativa via rolling median. Questo campo non è privo di pericoli — dimezzandolo si producono 2–4× più gaussiane (pressione di memoria, rischio OOM); raddoppiandolo si può sotto-densificare la scena.
T12densifyFromIteration
DETAYLAR
Varsayılan: 500 Range: 100 – 5 000 Defined in:
TEKNİK
Prima iterazione a partire dalla quale la densification diventa attiva. Prima avviene solo apprendimento "nudo" sulla nuvola di punti SfM iniziale, senza che vengano create nuove gaussiane. Il default 500 proviene dal paper 3DGS e dà tempo all'inizializzazione di stabilizzarsi — se si densifica già dall'iterazione 0, i punti SfM posizionati in modo errato si clonano in molte copie, prima che trovino il loro posto corretto. V349 ha testato 1000 → loss leggermente peggiore; il default è ottimale.
T13densifyInterval
DETAYLAR
Varsayılan: 100 (inizializzatore, MCMC), 200 (.full) Range: 50 – 1 000 Tanımlandığı yer:
TEKNİK
Quante iterazioni si trovano tra due step di densification. Nel default del paper 100 — ogni 100 iterazioni viene valutata la lista dei candidati di densify, clonata/divisa e contemporaneamente la lista dei candidati di prune (sigmoid(opacity) < T14 pruneOpacityThreshold) rimossa. I test V112 hanno trovato 200 come ottimale per .full — ciò alleggerisce la GPU, perché vengono eseguiti meno pass di riorganizzazione, e dà a ogni gaussiana più tempo per stabilizzarsi dopo un'azione di clone. V417 ha testato 100 con beta2=0.99 → 5.8% peggiore (957 K gaussiane, sovra-densificazione). Con MCMC lo stesso campo viene interpretato come intervallo di rilocazione; vedi T67 mcmcRelocationInterval per la logica specifica MCMC.
T14pruneOpacityThreshold
DETAYLAR
Varsayılan: 0.005 (inizializzatore, paper, MCMC), 0.001 (.full) Range: 0.0001 – 0.1 Tanımlandığı yer:
TEKNİK
Soglia di opacità sigmoid sotto la quale una gaussiana viene eliminata al prossimo step di densification. Agisce insieme a T7 opacityLearningRate e alla logica di logit clamp nell'optimizer. V393 ha abbassato il default da 0.005 a 0.001 in .full — conseguenza: gli splat che giocano un ruolo solo da angoli di visualizzazione esotici rimangono più a lungo e contribuiscono al dettaglio SH. V394 ha testato 0.0001 → leggermente peggio (troppo poco pruning, memoria sprecata). Importante: il density control deve SEMPRE eseguire il pruning, anche se la capacità del buffer è già piena tramite altre misure (vedi "Density Control Must Always Prune" in CLAUDE.md) — altrimenti le gaussiane morte si accumulano e il count si congela.
T15opacityResetInterval
DETAYLAR
Varsayılan: 3 000 (inizializzatore + paper), 100 000 (.full = effettivamente disabilitato), 200 000 (.fullMCMC = disabilitato) Range: 1 000 – 100 000+ Tanımlandığı yer:
TEKNİK
Ogni quante iterazioni l'opacità di tutte le gaussiane viene resettata a un valore basso (~0.01) — una misura del paper 3DGS per rivalutare splat "congelati". V194 ha mostrato che con il setup warmup + stochastic training + 2× learning rate di RadianceKit il reset di opacità costa il 5.5% di qualità e il logit clamp copre già la funzione di reset. Quindi in .full praticamente disabilitato (100 000 > 35 000 = mai attivato). V421 ha testato reset ogni 3 000 con beta2=0.99 → 4.9% peggiore; revertito. Con .fullClassicPaper (Q1.5-A, test fedele al paper) è deliberatamente riportato a 3 000 — è una delle leve con cui si dovevano raggiungere i budget di gaussiane con magnitudine paper.
T16maxScreenSize
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 (off) o > 0 Tanımlandığı yer:
TEKNİK
Dimensione massima screen space (in pixel proiettati) che una gaussiana può raggiungere prima di essere splittata forzatamente. Il valore è impostato a 0 (V48 ha testato e revertito) — il density control di RadianceKit usa invece la soglia di scala spazio mondo della logica dMean2D. Rimane nel catalogo dei campi, perché futuri esperimenti con Mip-Splatting (T74–T76) o strategie di splatting specifiche per scena potrebbero beneficiarne. L'attivazione (valore > 0, ad es. 20) costringerebbe gli splat che sono diventati molto grandi nello screen a dividersi — rilevante con grandi superfici lisce di pareti, dove un singolo splat gigante offre troppo poco dettaglio.
Loss (T17–T20)
T17ssimWeight
DETAYLAR
Varsayılan: 0.2 (inizializzatore + paper + .full), 0.05 (tutti i preset MCMC) Range: 0.0 – 1.0 Tanımlandığı yer:
TEKNİK
Peso della quota D-SSIM nella funzione di loss combinata loss = (1 - λ) * L1 + λ * D-SSIM, dove λ = T17. Il default del paper 3DGS 0.2 è ottimale per la densification Classic — V383 ha testato 0.3 → 28.9% peggiore, V373b ha confermato 0.2 come sweet spot. Per MCMC in V521b/V534 è stato indipendentemente stabilito: 0.05 è ottimale, perché MCMC tramite la sua esplorazione stocastica ha bisogno di una quota di segnale L1 più forte — pesi SSIM più alti annacquerebbero le decisioni di rilocazione. SSIM è significativamente più costoso da calcolare di L1 (finestre locali 11×11 sull'intera immagine); RadianceKit usa un'implementazione accelerata MPS che rimane sotto 1 ms per immagine 1080p. Gli sweep Q7-BayesOpt hanno trovato ottimi specifici per scena tra 0.05 (.outdoorPreset: 0.082) e 0.171 (.indoorPreset).
T18ssimWeightRefinement
DETAYLAR
Varsayılan: 0.0 (= "nessun cambio, mantieni ssimWeight") Range: 0 oppure 0 – 1.0 Tanımlandığı yer:
TEKNİK
Valore SSIM opzionale per la fase di refinement dopo T2 densifyUntilIteration. V428 ha testato 0.2 → 0.3 in refinement → 16% di loss peggiore (sia L1 sia SSIM sono peggiorati); revertito, da qui default 0.0. L'ipotesi dietro il campo era che dopo la densification — quando non nascono più nuove gaussiane — una quota SSIM più forte massimizzerebbe la nitidezza strutturale. Empiricamente errato: aumentare il peso SSIM significa indirettamente abbassare il peso L1, e L1 è il segnale nettamente più espressivo nella fase di refinement finale. Il campo rimane disponibile per esperimenti futuri con loss percettiva (T60) o edge loss (T19), dove potrebbe essere sensata una composizione di loss specifica per refinement.
T19edgeLossWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.001 – 1.0 Tanımlandığı yer:
TEKNİK
Loss sperimentale V437: peso di un loss L1 sul gradient domain Sobel, che confronta direttamente i bordi dell'immagine (Sobel ground truth vs Sobel render) in aggiunta a L1+SSIM. Ipotesi: l'informazione sui bordi è un pilastro percettivo della qualità dell'immagine e un termine esplicito dovrebbe incoraggiare le gaussiane a colpire meglio i bordi. Risultati dei test: peso 0.1 → 11% di loss peggiore, 0.01 → neutrale in qualità ma 10% più lento. Il pass Sobel costa un forward MPS aggiuntivo su ground truth e render. Quindi disabilitato in modo permanente. Caso d'uso futuro: scene con bordi artificiali duri (architettura, mobili, rendering) potrebbero beneficiare — i preset Q7-Scene-Class però non l'hanno preso, ma hanno invece scalato il peso SSIM.
T20skyMaskingEnabled
DETAYLAR
Varsayılan: false (inizializzatore e tutti i preset) Range: boolean Tanımlandığı yer:
TEKNİK
Attiva il Sky Masking. In ogni immagine la regione del cielo viene mascherata via Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest), e il loss in quest'area viene impostato a zero. Senso: le scene outdoor soffrono spesso del fatto che pixel di cielo blu/grigi/bianchi portano l'app a posizionare gaussiane esattamente lì — ciò che viene percepito come "floater". Senza sky mask il loss in quest'area non sarebbe mai zero, perché il cielo nell'immagine varia leggermente e l'app cerca all'infinito di ricostruirlo con splat. La maschera Vision viene calcolata una volta per fotocamera prima del training e mantenuta in RAM. Tipicamente attivata insieme a T45 skyDomeEnabled (logica UI nella view Impostazioni). Con scene interne o rendering sintetici lasciare disabilitato — la maschera riconoscerebbe erroneamente soffitti o pareti come "cielo".
SH derece ilerlemesi (T21)
T21shDegreeUpgradeIterations
DETAYLAR
Varsayılan: [1_000, 2_000, 3_000] (inizializzatore), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — grado 3 saltato) Range: [Int], ogni valore in [0, maxIterations], monotonamente crescente Tanımlandığı yer:
TEKNİK
Iterazioni a cui il grado SH attivo viene aumentato da 0→1, 1→2, 2→3. Prima del primo marker sono attive solo le componenti DC (quindi T5 shDCLearningRate), dopo il primo marker DC + 3 coefficienti di grado 1, dopo il secondo marker + 5 coefficienti di grado 2, dopo il terzo marker tutti i 15 coefficienti. Il fabbisogno di memoria per gaussiana cresce a stadi — 4 float → 16 float → 36 float → 64 float. I preset Quality ritardano gli upgrade rispetto ai default dell'inizializzatore (V228), perché la geometria dovrebbe prima stabilizzarsi, prima che i dettagli di colore con la loro frequenza più alta vengano sopra. V384 ha testato [1K, 2K, 3K] per .full → 9.3% peggiore — conferma il ritardo. .preview si ferma al grado 2, perché il grado 3 in 5 000 iterazioni non converge e consuma solo capacità optimizer. Q6 (T80–T81) offre una logica curriculum alternativa che sovrascrive dinamicamente questa lista.
Performans (T22–T25)
T22trainingRenderScale
DETAYLAR
Varsayılan: 1.0 (inizializzatore, .full, MCMC, Scene-Class), 0.5 (.preview), 0.25 (.quickTest) Range: 0.05 – 2.0 (tipico 0.25, 0.5, 1.0) Tanımlandığı yer:
TEKNİK
Risoluzione di rendering al training relativa alla risoluzione originale delle immagini di training. A 0.5 ogni immagine viene ridotta al 50% larghezza × 50% altezza (quindi 25% dei pixel) e il rendering delle gaussiane avviene in questa risoluzione più piccola. Riduce quadraticamente sia il fabbisogno di memoria che quello di calcolo. Importante: T11 densifyGradThreshold deve corrispondere alla risoluzione scelta — le magnitudini di gradiente scalano con 1/risoluzione², quindi .quickTest (0.25×) ha una soglia molto più alta (4e-6) di .full (1.0×, 1.1e-6). RadianceKit avverte con immagini molto grandi e adatta automaticamente — risoluzione target 3 MP. Con immagini di input estreme 4K 0.5 o anche 0.25 sarebbe sensato, altrimenti ogni Mac va in compaction CPU.
T23resolutionWarmupScale
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.1 – Tanımlandığı yer:
TEKNİK
Ottimizzazione V133: addestra la fase di densification (iter 0 a T2) in una risoluzione più bassa rispetto alla fase di refinement. V308 l'ha spenta di nuovo per .full, perché con T22 = 1.0 e cosine annealing il guadagno di tempo era marginale e la qualità soffriva minimamente. Rimane nel catalogo dei campi, perché potrebbe diventare di nuovo sensata con input 4K e lunghi run di training — Q6 Curriculum (T80) ha ripreso una logica simile, lì è però accoppiata allo LR schedule. Se attivato e T80 curriculumResolutionRamp anche true, vince Q6 e sovrascrive questo valore.
T24tileSize
DETAYLAR
Varsayılan: 16 Range: 8, 16, 32 Tanımlandığı yer:
TEKNİK
Dimensione delle tile di rasterizzazione in pixel. Il rendering Gaussian Splatting è basato su tile: l'immagine viene divisa in tile 16×16 pixel, ogni tile raccoglie le gaussiane rilevanti per essa, le ordina per profondità e le compone. 16 è lo standard usato praticamente da tutte le implementazioni 3DGS ed è hard-coded nei kernel Metal di RadianceKit; una modifica di questo valore richiederebbe la ricompilazione degli shader e non è effettiva nello stato attuale. Rimane come campo, nel caso una futura versione del motore supporti dinamicamente la tile size.
T25throttleDelayMs
DETAYLAR
Varsayılan: 0 (inizializzatore, .full, MCMC, Scene-Class), 0 (.preview) Range: 0 – 100 Tanımlandığı yer:
TEKNİK
Ritardo artificiale tra iterazioni di training in millisecondi. 0 = piena velocità (standard). Valori più alti rendono il Mac più "usabile" durante il training, dando a GPU/CPU regolari pause di respiro — l'usabilità di altre app aumenta, il tempo di training però linearmente con il ritardo. Valori tipici: 1–2 ms (throttling "leggero", +5% di tempo training, il Mac si sente più reattivo), 5 ms ("medio", +15% di tempo training), 10+ ms ("Eco", potenzialmente tempo training doppio). Viene offerto nell'Inspector sotto "Performance", ma non è nella vista standard — vedi backlog dev_ux-backlog.md, che propone di rimuoverlo dalla vista esperto, perché frainteso prolunga drammaticamente il tempo di training.
Tanı ve nokta bulutu hazırlığı (T26–T30)
T26depthDistortionWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Sperimentale V366: peso di un loss di regolarizzazione di depth distortion. Penalizza le gaussiane che sono stratificate in profondità lungo un raggio di render ma concettualmente appartengono alla stessa superficie — ciò incoraggia distribuzioni di profondità concentrate e riduce i floater. Test: 0.01 → 4.5% peggiore, 0.001 → 8.1% peggiore. Il vantaggio teorico — migliorare la consistenza multi-view — non si riflette nel loss L1, perché l'ipotesi assume implicitamente che la geometria SfM sia corretta e le gaussiane debbano solo essere "impilate". In pratica la nuvola di punti SfM è di solito il componente più debole, non l'impilamento. Rimane disponibile per dataset multi-view con pose particolarmente pulite (sintetici, Mip-NeRF 360 con ground truth).
T27singleViewOverfit
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Flag diagnostico: se true, in ogni iterazione di training viene forzatamente usato l'indice di fotocamera 0 invece di uno a caso dal pool. Senso: se il modello non riesce a fare overfitting nemmeno su una singola view (cioè il loss su view 0 anche dopo 10 000 iterazioni non va a zero), nel forward/backward pass c'è un bug fondamentale. Questo switch è stato usato intensamente durante lo sviluppo degli shader Metal e dei kernel del rasterizzatore differenziabile — fase V42–V47. Oggi disponibile solo come sanity check, se qualcuno ha modificato il codice backend e vuole fare un regression test. Via CLI con –single-view.
T28maxCameras
DETAYLAR
Varsayılan: 0 (= "usare tutte le fotocamere") Range: 0 oppure 1 – N Tanımlandığı yer:
TEKNİK
Limite diagnostico da V43: addestra solo con le prime N fotocamere, ignora tutte le altre. Senso originale: testare l'ipotesi che troppe fotocamere generino conflitti di gradiente (troppi segnali di loss contraddittori per la stessa gaussiana). Risultato del test: nessun vantaggio sistematico con limitazione artificiale — più frame portano praticamente sempre più qualità. Rimane come flag CLI (–max-cameras N) per esperimenti mirati, ad es. "il training funziona sulle prime 100 immagini di un volo di drone di 1 500 immagini?" Non esposto nell'UI.
T29maxInitialPoints
DETAYLAR
Varsayılan: 0 (= "usare tutti i punti SfM") Range: 0 oppure 1 000 – 200 000+ Tanımlandığı yer:
TEKNİK
Salvaguardia V54: limita il numero di punti SfM iniziali con cui inizia il training. Le ricostruzioni COLMAP dense possono produrre > 60 000 punti, il che con grandi scale iniziali porta a 200–300 gaussiane per overlap di pixel — ciò crea un "campo di nebbia" in cui il training non converge. Il sottocampionamento a ~16 000 punti (logica di hard cap nel motore di training) porta la densità iniziale al livello che il 3DGS di riferimento usa, e riduce drammaticamente l'overlap. Viene impostato automaticamente con SfM molto densi; via CLI con –max-points N.
T30cameraClusterOutlierMultiplier
DETAYLAR
Varsayılan: 10.0 (tutti i preset — mai sovrascritto) Range: 1.0 – 100.0 Tanımlandığı yer:
TEKNİK
Moltiplicatore per il camera cluster outlier filter, introdotto in fase 3.10 A.1. Prima del training, il motore di training calcola il centroide di tutte le posizioni delle fotocamere e la distanza massima di una fotocamera dal centroide. I punti SfM la cui distanza dal centroide supera multiplier × maxCameraDistance vengono scartati come outlier. Default 10× preserva il comportamento prima della fase 3.10. Un bug sottile: SfM tighter (fotocamere più strette insieme) → maxCameraDistance più piccolo → soglia più piccola → più punti scartati come outlier. SfM looser → soglia più grande → meno punti scartati. Questa è una delle cause dell'anti-correlazione funnel-vs-training della fase 3.9: un SfM migliore può portare downstream a un training peggiore, perché vengono uccisi troppi punti iniziali. Il campo è disponibile come override CLI (–camera-cluster-outlier-multiplier) per gli sweep A.3; non esposto nell'UI. Valori sotto 5 sono di solito troppo restrittivi, sopra 20 inefficaci.
Düzenleme (T31–T37)
T31coarseToFineBlurRadius
DETAYLAR
Varsayılan: 0 (= disabilitato) Range: 0 oppure 1 – 10 Tanımlandığı yer:
TEKNİK
Sperimentale V369: raggio di box blur che viene applicato all'immagine ground truth all'inizio della fase di densification e ridotto linearmente fino alla fine della densification (T2) a 0. Ipotesi: training coarse-to-fine — prima imparare strutture grossolane, poi dettagli — dovrebbe fornire geometria più stabile. Test: r=3 → 9.6% peggiore, r=1 → 5.1% peggiore. Il motivo del fallimento: la densification decide basandosi sui gradienti nel dominio dell'immagine, e il blur riduce esattamente i segnali importanti per "qui deve essere clonato". Rimane nel catalogo per futuri test con schema di density control diverso.
T32scaleRegWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Sperimentale V370: regolarizzazione L1 su scala spazio mondo. Penalizza gaussiane che diventano troppo grandi — impedisce "mega splat" che coprono intere superfici di parete con una singola gaussiana. Test: 0.01 → 200% di loss peggiore (2 M gaussiane, esplosione totale), 0.001 → 214% peggiore. Il motivo: la regolarizzazione di scala entra in conflitto con il density control — scale più piccole significano che servono più gaussiane, quindi il density control splitta più spesso, il che significa più sforzo di gradiente. Disabilitato, ma documentato per esperimenti Mip-Splatting (T74): in questo contesto un limite inferiore di scala potrebbe essere sensato.
T33anisotropyRegWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Sperimentale V445: penalità sul rapporto max(scale)/min(scale), dovrebbe impedire gaussiane "ago" estreme allungate, che vengono percepite come floater. Test: 0.01 → 69% peggiore, 0.001 → 15% peggiore. Il motivo: la regolarizzazione costringe gli splat verso forma "rotonda", il che su una superficie piatta (parete, tavolo, pavimento) è esattamente sbagliato — lì una gaussiana piatta e larga è più efficiente di una sferica. Disabilitato. V549f ha offerto con T34 scaleRatioPruneThreshold un approccio alternativo più mirato, anch'esso revertito.
T34scaleRatioPruneThreshold
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 5.0 – 100.0 (tipico 10.0 – 30.0) Tanımlandığı yer:
TEKNİK
Pruning post-training sperimentale che elimina ogni gaussiana il cui rapporto max(scale)/min(scale) supera la soglia lineare qui impostata. Mira a floater "ago/disco" estremamente allungati che non possono essere eliminati con la sola regolarizzazione. Nel test il pruning rimuoveva i floater come sperato, ma contemporaneamente anche splat piatti sensati su pareti e pavimenti — l'immagine è diventata più bucata. Quindi di default off, il flag CLI (–scale-ratio-prune N) rimane disponibile per esperimenti mirati. Valori raccomandati se si vuole comunque testare: 30 (molto conservativo, rimuove solo outlier estremi), 10 (aggressivo, costa dettaglio).
T35opacityRegWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.0001 – 0.05 Tanımlandığı yer:
TEKNİK
Sperimentale V446: penalità di binary cross entropy che tira l'opacità verso 0 o 1 (quindi via da "semi trasparente"). Ipotesi: distribuzione di opacità più nitida migliorerebbe la chiarezza dell'immagine. Test combinato con T33 → la regolarizzazione costa qualità, entrambi disabilitati. Disabilitato. Attenzione: nella 1.4.3 beta è emerso un bug che aveva esattamente questo campo in una modifica del valore di default (inizializzatore = 0.01), il che ha portato a mass extinction del gaussian count (460 K → 5 in un'iterazione). Dalla 1.4.4 fissato a 0.0 come default.
T36opacityDecayFactor
DETAYLAR
Varsayılan: 0.0 (inizializzatore = disabilitato), 0.9995 (.full, .classicBalanced — standard HTGS) Range: 0 (off) oppure 0.95 – 1.0 Tanımlandığı yer:
TEKNİK
Implementazione V546 dello schema HTGS (Hierarchical Time-Gating, Eurographics 2025): ogni T37 opacityDecayInterval iterazioni l'opacità sigmoid di ogni gaussiana viene moltiplicata con questo fattore. 0.9995 × 100 applicazioni dà ~95% di rimanenza per fase di densification — una leggera ma costante pressione verso il basso su tutte le opacità, che fa scendere in modo affidabile le gaussiane che contribuiscono poco contro la T14 pruneOpacityThreshold. Il risultato: 14% di loss L1 migliore su Horse Full (3-trial-avg V546) rispetto a V438 senza decay. Attivo solo durante la fase di densification (fino a T2), dopo il training prosegue senza decay, in modo che le opacità stabilite nel refinement rimangano stabili. Con MCMC non usato (MCMC ha propri meccanismi via T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETAYLAR
Varsayılan: 50 Range: 10 – 500 Tanımlandığı yer:
TEKNİK
Intervallo di iterazione in cui viene applicato T36 opacityDecayFactor. Default paper HTGS 50, lasciato in .full. Intervalli lunghi (>200) annullano parzialmente l'effetto, perché tra due applicazioni avvengono abbastanza update di gradiente che l'opacità risale. Intervalli più brevi (<20) rendono il decay troppo aggressivo. Attivo solo in fase di densification.
İnce ayar (T38–T44)
T38gradientAccumulationSteps
DETAYLAR
Varsayılan: 1 (= "una view per step Adam") Range: 1 – 8 Tanımlandığı yer:
TEKNİK
Funzione V424: numero di view i cui gradienti vengono accumulati prima che venga eseguito un update Adam. Con > 1 l'app gira su un percorso backward project separato e "unfused" che somma i gradienti in un buffer separato; l'applicazione finale scala con 1/N per mantenere costante la magnitudine. V424 ha testato 2-view → neutro in qualità, ma 10% più lento (perché il percorso unfused è più costoso del fused). Revertito per .full, ma per MCMC deliberatamente usato — .fullMCMC gira con, ma i test V544a hanno mostrato che con esso il gap di qualità verso Classic si riduce al 5% (invece dell'11%). Nel default dell'inizializzatore 1, nel preset attuale 1, rimane flag CLI (–accum-steps N).
T39testViewIndices
DETAYLAR
Varsayılan: [] (= vuoto, tutte le view vengono usate per il training) Range: Set<Int>, qualsiasi sottoinsieme degli indici di fotocamera Tanımlandığı yer:
TEKNİK
Funzione V546: set di indici di fotocamera che NON vengono usati per il training, ma riservati come holdout per la valutazione PSNR/SSIM/LPIPS. Viene impostato automaticamente quando il flag CLI –benchmark è attivo: allora ogni ottava view, iniziando dall'indice 0 (standard LLFF, identico alle convenzioni Mip-NeRF-360 e paper 3DGS). Senza benchmark vuoto — il training usa tutte le view. Attenzione: l'impostazione manuale di questo campo senza comprensione degli indici può rendere inutilizzabile il benchmark (ad es. se tutti gli indici sono impostati sopra N, mentre ci sono solo N-50 view → nessun holdout → nessuna valutazione). Al proprio export preset testViewIndices non viene persistito, perché è dipendente dalla scena e altrimenti lascerebbe valori senza senso tra diversi dataset.
T40refinementPruneInterval
DETAYLAR
Varsayılan: 0 (= disabilitato) Range: 0 oppure 100 – 5 000 Tanımlandığı yer:
TEKNİK
Funzione V425: ogni N iterazioni durante la fase di refinement (dopo T2) viene eseguito un pass di prune aggiuntivo, che rimuove le gaussiane con sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Senso: durante la densification ci sono regolari chiamate di density control, dopo non più — le gaussiane la cui opacità continua a scendere rimangono però nel buffer. V425 ha testato e revertito: il pruning aggiuntivo correlava con V426 (Two-Phase Densification, anch'esso interrotto in 0-gaussian cascade failure). Disabilitato. Flag CLI disponibile per esperimenti; se attivato, 1 000 o 2 000 sono valori sensati.
T41refinementPruneOpacityThreshold
DETAYLAR
Varsayılan: 0.0 (= "usa T14") Range: 0 oppure 0.001 – 0.1 Tanımlandığı yer:
TEKNİK
V425b: soglia di opacità separata per refinement prune. Dopo la densification la maggior parte delle gaussiane ha raggiunto un'opacità decisamente più alta (> 0.001), quindi lo standard T14 pruneOpacityThreshold sarebbe troppo lasco. Se T40 attivo, questo campo determina la propria soglia. A 0.0 viene continuato l'uso di T14. Rilevante solo se T40 > 0.
T42midTrainingCompactificationIterations
DETAYLAR
Varsayılan: [] (= disabilitato) Range: [Int], valori in (densifyUntilIteration, maxIterations) Tanımlandığı yer:
TEKNİK
Funzione V549: punti di iterazione espliciti durante la fase di refinement, in cui viene eseguito un pass di compactification (rimuove sigmoid(opacity) < 0.01 + gaussiane di scala outlier, stessa logica di T56 postTrainingCompactification). Senso: lunghe fasi di refinement possono mostrare accumulo di confetti/floater, il cui SH poi va in overfitting su artefatti specifici della view. Configurazione tipica se attivata: [10000, 20000, 30000] per 40K Classic. MA: i test V549 A/B sul dataset Family hanno mostrato in tutte le configurazioni un L1 peggiore: [10K,20K,30K]@0.01 → −48% count ma +36% L1; [20K,30K]@0.005 → −44% count ma +45% L1; [20K,30K]@0.001 → −17% count ma +87% L1. Quindi disabilitato. Flag CLI –mid-compact "10000,20000" disponibile, se si preferisce il tradeoff floater visivo (meno confetti nel viewport) rispetto alla regressione di loss.
T43frustumCullEnabled
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V549b: dopo il training vengono rimosse tutte le gaussiane che si trovano al di fuori dell'unione di tutti i frustum delle fotocamere di training. Tali gaussiane non sono mai state limitate dal segnale di loss e sono sempre floater. Particolarmente efficace per scene in cui la novel view si trova dietro o accanto al percorso della fotocamera (ad es. retro di un volo di drone lineare) — i floater lì non sono mai visibili nella fase di training, ma sì nello spostamento successivo nel viewer 3D. V549b A/B su voli di drone risultati positivi, quindi disponibile come opt-in. Default false, perché con object capture con piena copertura orbit l'unione dei frustum comprende l'intera scena e la funzione non rimuove nulla — viene offerta nelle Settings sotto "Floater Reduction" e testata anche in Q9 Outdoor preset implicitamente tramite T44 frustumCullExpansion (Q7-BayesOpt però non l'ha attivata, perché Outdoor Sky Dome risolve meglio lo stesso problema).
T44frustumCullExpansion
DETAYLAR
Varsayılan: 1.1 Range: 1.0 – 2.0 Tanımlandığı yer:
TEKNİK
Margine NDC per T43 frustumCullEnabled. 1.0 taglierebbe esattamente al bordo dell'immagine, il che taglierebbe troppo splat traballanti al bordo dell'immagine. 1.1 = 10% di padding oltre l'esatto framing della fotocamera — dà un po' di tolleranza per pixel di bordo che in una novel view leggermente spostata potrebbero diventare visibili. Valori > 1.2 rendono il cull praticamente inefficace, perché il frustum espanso comprende molto più spazio.
Sky-Dome (T45–T48)
T45skyDomeEnabled
DETAYLAR
Varsayılan: false (inizializzatore + tutti i preset eccetto P9 Outdoor) Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V549e: prima dell'avvio del training viene generata una nuvola di punti sferica (sfera di Fibonacci con T46 sample point), posizionata in un raggio di T47 skyDomeRadiusMultiplier × scene_extent attorno al centro della scena e inizializzata con i colori dei pixel mascherati come cielo di tutte le fotocamere di training (vedi T20 skyMaskingEnabled). Queste gaussiane sky dome vengono inserite all'inizio del buffer gaussiano e "congelate" durante il training (gradienti posizione/scala/rotazione = 0, solo SH e opacità rimangono ottimizzabili). Effetto: invece di aree "confetti" nere in lontananza, l'utente vede in novel view un cielo reale. MVP V549e funziona molto bene su scene di drone e paesaggio; in P9 Outdoor preset default on. Con scene interne lasciare off — la sfera penderebbe inutile fuori dalla stanza.
T46skyDomeSampleCount
DETAYLAR
Varsayılan: 5 000 Range: 1 000 – 50 000 (tipico 2 000 – 10 000) Tanımlandığı yer:
TEKNİK
Numero di sample point della sfera di Fibonacci sulla sfera sky dome. Valori più alti → sky dome più denso (migliore con grandi risoluzioni e molto cielo visibile), ma più fabbisogno di memoria. 5 000 è sweet spot per rendering 4K; con risoluzioni più basse 2 000–3 000 basta. I punti vengono inizializzati per cosine distance a ogni vettore di vista delle fotocamere di training con i corrispondenti pixel mascherati come cielo — i sample point il cui view cone non vede alcuna fotocamera rimangono indietro con un basso valore iniziale di opacità, ma non vengono modificati durante il training (congelati).
T47skyDomeRadiusMultiplier
DETAYLAR
Varsayılan: 30.0 (inizializzatore + la maggior parte dei preset), 59.0 (P9 Outdoor, ottimo Q7-BayesOpt) Range: 5.0 – 200.0 Tanımlandığı yer:
TEKNİK
Raggio della sfera sky dome relativo all'estensione della scena (= distanza media tra posizioni delle fotocamere). 30 = la sfera ha 30 volte il diametro della nuvola della fotocamera. Troppo piccolo (< 5) → lo sky dome interferisce con la scena stessa (ad es. uno splat sky dome finisce in primo piano); troppo grande (> 100) → perdita di precisione float32 sulle posizioni sky dome, il che provoca glitch di rendering in lontananza. Q7-BayesOpt su Bicycle (Mip-NeRF 360) ha trovato 59.0 come ottimo specifico per scena outdoor — ciò indica che lo standard 30.0 è troppo piccolo per paesaggi profondi e i pixel sky dome nelle aree di bordo immagine renderizzano visibilmente come "parete".
T48frozenGaussianCount
DETAYLAR
Varsayılan: 0 (= nessuna gaussiana congelata) Range: 0 oppure 1 – T46 Tanımlandığı yer:
TEKNİK
Numero di gaussiane all'inizio del buffer i cui gradienti posizione/scala/rotazione vengono impostati a zero nell'optimizer — rimangono spazialmente rigide su tutto il training. Il density control non può clonarle, splittarle o prunarle. Usato per l'iniezione sky dome (vedi T45): se sky dome è on, questo campo viene impostato automaticamente su T46 skyDomeSampleCount. L'impostazione manuale è possibile (ad es. per congelare una nuvola di punti pre-posizionata da una scansione LiDAR), ma non direttamente accessibile nell'UI. Importante: le prime N gaussiane nel buffer sono sempre le frozen — l'ordine nel buffer decide, non un indice esplicito.
Adam + LR programı (T49–T55)
T49adamResetIteration
DETAYLAR
Varsayılan: 0 (= disabilitato) Range: 0 oppure 100 – Tanımlandığı yer:
TEKNİK
Funzione V430: iterazione a cui gli accumulatori di momentum Adam (m1, m2) vengono resettati a zero. La correzione del bias successivamente gira con (iter - adamResetIteration) invece di iter. V430 ha testato reset a 5 000 (dopo fine densification) → 12.8% di loss peggiore. Motivo: il momentum Adam che si è costruito durante la densification porta informazioni sulle magnitudini tipiche di gradiente e accelera la fase di refinement. Gettarlo via costa le prime ~500 iterazioni di refinement in convergenza. Disabilitato. Rimane flag CLI per esperimenti di ricerca.
T50positionLRScheduleEndIteration
DETAYLAR
Varsayılan: 0 (inizializzatore = "usa maxIterations"), 20 000 (.full — cosine termina a 20K nonostante maxIter=35K), 30 000 (.fullClassicPaper) Range: 0 oppure 1 000 – Tanımlandığı yer:
TEKNİK
Funzione V431: iterazione a cui la curva di cosine annealing per la LR di posizione raggiunge il suo minimo. Se 0, è identico a T1 maxIterations. Se > 0, lo schedule corre fino a questo valore e dopo rimane a T4 positionLearningRateFinal costante. Ciò permette una "extended refinement phase" con LR minima ma costante — raffina lentamente le posizioni senza nuovo decay. .full lo fa (schedule end a 20K, il training corre fino a 35K), V434c/V434d hanno confermato: 15K e 25K entrambi più o meno uguali, 20K minimamente ottimale. Continua ad essere usato in combinazione con T51, per modificare nella extended phase anche le LR non di posizione.
T51extendedPhaseLRDecay
DETAYLAR
Varsayılan: 0.0 (= disabilitato, LR costanti) Range: 0 oppure 0.01 – 1.0 Tanımlandığı yer:
TEKNİK
Funzione V433: moltiplicatore minimo per le LR non di posizione (scala, rotazione, opacità, SH) nella "extended phase" — cioè dopo che T50 è raggiunto e la LR di posizione è già a T4. Se 0.1, scala/rotazione/opacità/SH vengono a loro volta cosine-decayed da 1.0 (= la loro LR standard) a 0.1× del loro standard. Se 0.0 (default), rimangono costanti. V457 ha testato decay completo (0.0 = decay-fino-a-zero) contro nessun decay e ha trovato: avg 0.0400 (2 run) = stesso loss di V438 senza decay. Comportamento più pulito con decay, ma non misurabilmente migliore. Quindi disabilitato. Rimane nel CLI come –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Sperimentale V440: se true, l'app calcola in ogni step di densification il p98 dell'attuale distribuzione del gradiente e lo usa come soglia dinamica (limitata ad almeno 0.5× del valore configurato da T11, in modo che non sbordi troppo). Ipotesi: l'adattamento automatico alla fase di scena attuale renderebbe il density control più robusto — ad es. all'inizio pruning più severo, dopo più lasco, o viceversa. V440 ha testato e revertito: drop catastrofico a 63 K gaussiane (mass pruning, perché il p98 nelle prime iterazioni è estremamente alto e poi quasi nulla supera la soglia). La soglia fissa è già ben calibrata, l'adattamento dinamico danneggia più di quanto giovi. Q5 (T77) offre una logica adattiva alternativa via rolling median che aggira il problema.
T53mergeAfterDensification
DETAYLAR
Varsayılan: false (inizializzatore), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V438: alla fine della fase di densification (iter T2) viene eseguito un pass di merge una tantum, che unisce gaussiane vicine tra loro con scala e colore simili. Riduce il numero di gaussiane tipicamente del 5–15% senza perdita di qualità visibile. Senso: dopo un intenso clonaggio nascono cluster di gaussiane quasi identiche, che non contribuiscono nulla di nuovo — il merging libera capacità optimizer per altre aree. Standard nei preset Classic Quality. Con MCMC non usato, perché MCMC tramite la sua logica di rilocazione non lascia nemmeno nascere tali cluster.
T54densifyPhase2FromIteration
DETAYLAR
Varsayılan: 0 (= disabilitato) Range: 0 oppure T2 – T1 Tanımlandığı yer:
TEKNİK
Sperimentale V426: abilita una seconda fase di densification che inizia dopo la pausa di refinement a questa iterazione e corre fino a T55. Ipotesi: dopo una fase di refinement gli accumulatori di gradiente hanno magnitudini più stabili e possono dire più precisamente quali aree hanno bisogno di gaussiane aggiuntive. V426 ha testato e revertito: densification a due fasi è caduta in 0-gaussian-cascade-failure (combinata con V425 refinement pruning ha distrutto il buffer). Disabilitata. Flag CLI disponibile per esperimenti.
T55densifyPhase2UntilIteration
DETAYLAR
Varsayılan: 0 Range: 0 oppure T54 – T1 Defined in:
TEKNİK
Fine della Two-Phase Densification V426. Rilevante solo se T54 > 0. Entrambi i campi insieme disabilitati.
Son işleme + Apple AI (T56–T60)
T56postTrainingCompactification
DETAYLAR
Varsayılan: true (in tutti i preset di produzione), false (.quickTest, .preview) Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V443: dopo la fine del training le gaussiane con sigmoid(opacity) < 0.01 vengono rimosse duramente (non contribuiscono praticamente più all'immagine). Riduce il gaussian count tipicamente del 58% e la dimensione del file di export del 55% senza perdita di qualità visibile. Attiva di default nei preset di produzione — il risultato finale dovrebbe poter essere consegnato il più compatto possibile. In .quickTest off, perché un run diagnostico non viene comunque esportato. A differenza di T42 midTrainingCompactificationIterations (V549) la compactification avviene solo alla fine — il refinement può usare fino ad allora tutte le gaussiane.
T57metalFXUpscaling
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V444: attiva l'upscaler spaziale MetalFX di Apple invece dell'interpolazione bilineare nell'output del viewer 3D. Se la risoluzione di training < dimensione viewport (ad es. training a 0.5×, visualizzazione viewport in piena risoluzione), MetalFX può fornire un'immagine decisamente più nitida. Cambia live nel viewport, nessun re-training necessario. Si esclude con T58 mpsLanczosScaling — MetalFX ha la precedenza. Raccomandazione: accendere se l'immagine nel viewer appare "sbiadita" rispetto al dettaglio atteso.
T58mpsLanczosScaling
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione V444: MPSImageLanczosScale per lo scaling viewport invece dell'interpolazione bilineare. Lanczos è un metodo di ricampionamento classico basato su sinc che fornisce risultati decisamente più nitidi del bilineare con overhead minimo. Toggle dal vivo. Viene sovrascritto da T57 se entrambi attivi.
T59livePreviewInterval
DETAYLAR
Varsayılan: 50 (inizializzatore e la maggior parte dei preset) Range: 0 (off) oppure 10 – 5 000 Tanımlandığı yer:
TEKNİK
Quanto spesso durante il training il viewer 3D viene aggiornato con le gaussiane attuali. 50 = ogni 50 iterazioni un nuovo render nel viewer — abbastanza per osservare il progresso senza rallentare il training. 0 = il viewer non viene aggiornato affatto (training in background, max velocità). Adattamento tipico: con .quickTest giù a 10 (si vuole vedere ogni step), con lunghi run MCMC su a 500–2000 (overhead di update in totale percettibile).
T60perceptualLossWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato) Range: 0 oppure 0.001 – 0.5 Tanımlandığı yer:
TEKNİK
Funzione futura V444: peso di un termine di loss percettivo via MPSGraph (piccola rete simil-VGG). Catturerebbe similarità strutturale e di texture a un livello semantico superiore a L1+SSIM — tipico in pipeline di ricerca, dove "pixel-perfect" è meno importante di "sembra realistico". Implementazione ancora in attesa (stub di codice presente, ma forward pass non implementato). Default 0.0. Rimane nel catalogo dei campi per attivazione futura; flag CLI –percep-weight F riservato.
MCMC Densification (T61–T73)
T61densificationStrategy
DETAYLAR
Varsayılan: .classic (inizializzatore + preset Classic), .mcmc (tutti i preset MCMC + Scene-Class) Range: .classic o .mcmc Tanımlandığı yer:
TEKNİK
Sceglie tra densification classica (clone/split/prune, Kerbl et al. 2023) e densification MCMC (Stochastic Gradient Langevin Dynamics con rilocazione, Kheradmand et al. NeurIPS 2024). Con .classic vengono valutati T11–T16, con .mcmc i T62–T73. Attenzione al cambio: i default Classic e i default MCMC sono calibrati in modo completamente diverso — chi flippa il picker nella vista esperto senza caricare un preset appropriato, rischia mass extinction in stile 1.4.3 bug (460 K → 5 in un'iterazione, perché MCMC OpacityReg a 0.01 uccide le opacità Classic). Quindi i default init MCMC deliberatamente "addolciti" (tutti i valori reg 0.0).
T62mcmcMaxGaussians
DETAYLAR
Varsayılan: 150 000 (inizializzatore + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — variante Mip-Splatting con budget 10×), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) Range: 0 (= "usa capacità buffer") oppure 10 000 – 5 000 000 Defined in:
TEKNİK
Limite superiore rigido per il numero di gaussiane con strategia MCMC. Il numero cresce gradualmente di T70 mcmcGrowthRate (tipico 5%) per step di rilocazione fino a questo cap. V473/V531 hanno trovato 150 K come sweet spot — oltre 200 K si dilata la qualità degli splat (troppe gaussiane piccole, ridondanti), sotto 100 K la scena rimane sotto-densificata. Con scene molto grandi (ad es. volo di drone da 1 545 foto con 158 K SfM-init) 150 K è troppo basso — da qui l'estensione 1.4.5 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt ha trovato ottimi specifici per scena tra 670 K (Indoor) e 1.25 M (Outdoor). Con valore 0 il motore usa la piena capacità buffer come cap.
T63mcmcNoiseScale
DETAYLAR
Varsayılan: 0.00005 (5e-5 = default paper) Range: 1e-6 – 1e-3 Tanımlandığı yer:
TEKNİK
Moltiplicatore per il rumore gaussiano che in ogni iterazione MCMC viene aggiunto alla posizione di ogni gaussiana (logica SGLD). Più alto = più esplorazione (le gaussiane vagano di più, trovano potenzialmente posti migliori), più basso = più exploitation (le gaussiane rimangono dove sono già buone). V467 e V536 hanno confermato 5e-5 come ottimale — 1e-5/2e-5 troppo poco esplorazione, 1e-4 troppo (gli splat si dissipano). Viene cosine-decayed sul tempo di training fino a T69 mcmcNoiseDecayEnd — alla fine della zona di decay il rumore è effettivamente 0 e le gaussiane convergono.
T64mcmcOpacityRegWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato nei default RadianceKit, paper: 0.01) Range: 0 oppure 0.001 – 0.05 Tanımlandığı yer:
TEKNİK
Penalità L1 specifica MCMC sull'opacità. Default paper 0.01 (spinge le gaussiane non usate verso zero, le rende disponibili per rilocazione). V464b ha mostrato però: senza reg in RadianceKit è misurabilmente migliore (sessione 28 conferma). Motivo: il criterio di pruning definito con T68 mcmcDeadOpacityThreshold basta da solo — una penalità L1 aggiuntiva costringe a morire anche gaussiane preziose a bassa opacità. Quindi default 0. Attenzione: nella build 1.4.3 beta il default dell'inizializzatore era erroneamente 0.01, il che è risultato nel mass extinction bug (vedi spiegazione T61); dalla 1.4.4 fissato a 0.0.
T65mcmcScaleRegWeight
DETAYLAR
Varsayılan: 0.0 (= disabilitato, paper: 0.01) Range: 0 oppure 0.001 – 0.05 Tanımlandığı yer:
TEKNİK
Penalità L1 specifica MCMC sugli autovalori di scala. Default paper 0.01. V464b: senza reg migliore, stesso ragionamento di T64. Disabilitato in tutti i preset MCMC di RadianceKit. Attenzione come per T64: bug 1.4.3.
T66mcmcRelocationInterval
DETAYLAR
Varsayılan: 100 (inizializzatore + tutti i preset MCMC, standard paper), 155 (P9 Outdoor — ottimo Q7-BayesOpt) Range: 50 – 500 Tanımlandığı yer:
TEKNİK
Intervallo di iterazione in cui MCMC riloca le gaussiane morte (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) in nuove posizioni. V537 ha testato 50 (troppo dirompente, loss oscilla) e 200 (marginalmente peggio, MCMC perde reattività). 100 è ottimale. Q7-BayesOpt su Bicycle ha trovato 155 come ottimo specifico per scena outdoor — gli intervalli un po' più lunghi danno ad Adam più tempo per integrare le gaussiane nuove posizionate, prima che il prossimo evento di reloc le metta sotto pressione.
T67mcmcWarmupIterations
DETAYLAR
Varsayılan: 500 Range: 100 – 5 000 Tanımlandığı yer:
TEKNİK
Numero di iterazioni iniziali in cui non avviene ancora rilocazione MCMC. Solo dopo questo warmup inizia la logica di reloc. Senso: nelle prime iterazioni i valori di opacità non sono ancora stabilizzati — se si iniziasse subito con reloc, le gaussiane verrebbero posizionate in punti sbagliati e dovrebbero essere subito spostate, il che distrugge il momentum Adam. Default paper 500. RadianceKit assume questo valore, perché V464b ha mostrato che è robusto.
T68mcmcDeadOpacityThreshold
DETAYLAR
Varsayılan: 0.005 (inizializzatore, standard paper), 0.01 (.fullMCMC e tutti i preset MCMC — ottimo V535) Range: 0.001 – 0.05 Tanımlandığı yer:
TEKNİK
Soglia sigmoid(opacity) sotto la quale una gaussiana è considerata "morta" ed entra in considerazione per rilocazione. V535 ha trovato 0.01 come ottimale (0.005 marginale, 0.02 peggiore). Più alto = reloc più aggressivo (più gaussiane vengono spostate), più basso = più cauto. 0.01 corrisponde a circa "0.5% di visibilità visiva". P10 Indoor usa via Q7-BayesOpt 0.0142 come ottimo.
T69mcmcNoiseDecayEnd
DETAYLAR
Varsayılan: 0 (inizializzatore = "nessun decay"), 160 000 (.fullMCMC = 80% di 200K), 96 000 (.mcmcBalanced = 80% di 120K), 40 000 (.mcmcPreview) Range: 0 oppure 1 000 – Tanımlandığı yer:
TEKNİK
Iterazione a cui il rumore T63 mcmcNoiseScale viene smorzato completamente a zero (cosine decay da iter 0 a qui). V497c/V502 hanno trovato 80% del maxIterations ottimale — dà a MCMC abbastanza tempo di esplorazione, ma lascia l'ultimo 20% alla convergenza senza rumore. 0 = rumore costante su tutte le iterazioni (raramente sensato, MCMC non può poi convergere).
T70mcmcGrowthRate
DETAYLAR
Varsayılan: 0.05 (standard paper = 5%) Range: 0.01 – 0.2 Tanımlandığı yer:
TEKNİK
Tasso di crescita del target di popolazione MCMC per step di rilocazione. La logica: ad ogni evento reloc la dimensione target di popolazione viene aumentata di (1 + growthRate), fino a quando T62 mcmcMaxGaussians (o la variante scalata via T72/T73) viene raggiunta. V512/V522 hanno trovato 0.05 come ottimale — valori più alti portano a crescita troppo veloce (le gaussiane vengono inserite prima che l'Adam momentum possa integrarle), più bassi a scene sotto-densificate alla fine.
T71mcmcSigmoidK
DETAYLAR
Varsayılan: 100.0 Range: 10.0 – 500.0 Defined in:
TEKNİK
Parametro di sharpness sigmoid per l'attenuazione del rumore MCMC. Nello step SGLD il rumore per gaussiana viene smorzato attraverso — gaussiane ad alta opacità (il cui logit è positivo) ricevono esponenzialmente meno rumore di quelle a bassa opacità. K = 100 è nitido, cioè la transizione da "pieno-rumore" a "nessun-rumore" avviene molto velocemente attorno a opacità 0.5. V484–V487 hanno trovato K = 100 ottimale — valori più piccoli (10–50) lasciano tremare anche gaussiane ad alta opacità (distrugge gaussiane convergenti), più grandi (> 500) rendono la transizione artificialmente dura e le gaussiane morte non vengono più spostate.
T72mcmcCapMultiplier
DETAYLAR
Varsayılan: 3.0 (inizializzatore + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Range: 0 (= disabilitato) oppure 1.0 – 10.0 Tanımlandığı yer:
TEKNİK
Funzione 1.4.5: scaling cap adattivo alla scena. Se T73 mcmcAutoScaleByScene è true, il cap effettivo viene calcolato come (limitato a capacità buffer). Sfondo: con scene grandi (ad es. volo di drone da 1 545 foto → 158 K SfM-init) T62 = 150 000 è troppo basso — il density control non potrebbe affatto crescere. Con multiplier 3.0 il cap in questo esempio viene scalato a 474 K (158 K × 3.0). Q7-BayesOpt ha trovato ottimi specifici per scena: Outdoor beneficia di multiplier alto (5.32 → ~830 K cap con 156 K bicycle init), Indoor si accontenta di 1.76 (le pareti saturano più velocemente). Risoluzione completa del cap vedi metodo.
T73mcmcAutoScaleByScene
DETAYLAR
Varsayılan: true (inizializzatore + tutti i preset MCMC) Range: boolean Tanımlandığı yer:
TEKNİK
Funzione 1.4.5: master switch per la logica cap scene-aware (vedi T72 +). Se false, viene usato esclusivamente T62 mcmcMaxGaussians come cap (ritorno al comportamento 1.4.4). Standardmente on, perché altrimenti i problemi di mass extinction con scene grandi della 1.4.3 ritornano. Disattivare manualmente solo se vuoi esplicitamente impostare un cap rigido — ad es. per addestrare una variante 150 K la cui dimensione finale è pianificabile.
Mip-Splatting (Q1.5) (T74–T76)
Stato: Q1.5 il 2026-05-25 dopo 14 iterazioni autonome + overnight 1.5M confidence check è stato scartato come "closed no-win" (max Δ@2× = +0.27 dB, il gate originale richiedeva ≥ +1.5 dB di media su 0.5×/2×, FALLISCE su 0/11 pair scenes). I campi rimangono opt-in per esperimenti di ricerca; tutti i preset di produzione hanno. Vedi verdetto:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETAYLAR
Varsayılan: false (tutti i preset di produzione), true (.fullMCMCMip — sibling di ricerca) Range: boolean Tanımlandığı yer:
TEKNİK
Attiva Mip-Splatting (Yu et al. CVPR 2024): filtro di smoothing 3D + filtro 2D + compensazione α, che limita la frequenza per gaussiana al limite di Nyquist della densità di campionamento più alta della fotocamera di training. Obiettivo teorico: eliminazione dell'aliasing al rendering in scale fuori training (0.5× o 2× della risoluzione di training). Attivato negli shader di preprocess e backward projection, funzionalmente verificato corretto nel test Q1.5-D. Ma: il gate di accettazione originale (Δ@1× ≥ +0.3 dB E avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) non è stato raggiunto su nessuna delle 11 pair scenes. Massimo osservato: family 750K classic Δ@2× = +0.270 dB. Le scene outdoor (Truck, Flowers) hanno mostrato addirittura peggioramento 1× e 0.5×. Ipotesi: lo smoothing 3D compete con la rilocazione MCMC con high-Gs. Il campo rimane per future re-eval multi-scala con metodologia Mip-NeRF-360 corretta (vedi O3-backlog nel benchmark path).
T75mipSmoothing3DScale
DETAYLAR
Varsayılan: 0.2 (default paper) Range: 0.05 – 1.0 Tanımlandığı yer:
TEKNİK
Parametro di scala di smoothing 3D (Yu et al. §3.3, default paper 0.2). Più grande = più smoothing spazio mondo per gaussiana (= più antialiasing, ma anche più blur nella scala di default), più piccolo = più nitido ma più suscettibile all'aliasing. Viene consultato solo se T74 useMipSplatting = true. Nei test Q1.5 non ulteriormente ottimizzato — il gate A/B ha già perso con default paper 0.2, ulteriori sweep sarebbero inutili.
T76mipFilter2DVariance
DETAYLAR
Varsayılan: 0.3 (= esattamente il comportamento legacy V242) Range: 0.1 – 1.0 Tanımlandığı yer:
TEKNİK
Varianza filtro 2D Mip che viene aggiunta alla diagonale Σ_2D (varianza direttamente, non al quadrato). 0.3 è esattamente il valore legacy V242, che prima di Mip-Splatting era hardcoded nel kernel. Se T74 useMipSplatting = false, il kernel ignora completamente questo valore e scrive lo hard-coded 0.3 — in modo che la baseline non possa regredire (garanzia Codex-Round-1-S3-1). Se, viene usato il valore qui impostato. Rimane nel catalogo dei campi per sweep Mip.
Uyarlanabilir Densification (Q5) (T77–T79)
T77adaptiveDensification
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione Q5: rolling median tracker come alternativa al fisso T11 densifyGradThreshold. Se true, in ogni step di densify la soglia attuale viene sovrascritta con median(ultimi N avgGrad samples) × T79 adaptiveDensifyMultiplier. N = T78 adaptiveWindow. Più rigoroso di V440 p98 (la trappola catastrofica di 63 K pruning), median + 2× si trova circa al p70–p80 della distribuzione del gradiente in steady state. Test Q5: da solo FAIL 0/3 scene, ma insieme a Q6 (vedi T80/T81) PASS 1/3 scene — il bundle Q5+Q6 è stato passato come opt-in il 2026-05-25 ed è attivabile via CLI –adaptive-densify. Q6 è così il "portatore" del guadagno di qualità, Q5 contribuisce piuttosto alla stabilità.
T78adaptiveWindow
DETAYLAR
Varsayılan: 1 000 Range: 100 – 10 000 Defined in:
TEKNİK
Rolling median window in eventi di densification (NON iterazioni — ogni step T13 densifyInterval fornisce un sample). Default 1 000 — con significa che le ultime 100 000 iterazioni di training contribuiscono al median, quindi tipicamente l'intera storia del training fino a qui. Fase iniziale (prima dei sample T78): il tracker restituisce nil → fallback alla soglia fissa T11. Rilevante solo se.
T79adaptiveDensifyMultiplier
DETAYLAR
Varsayılan: 2.0 Range: 1.0 – 4.0 Tanımlandığı yer:
TEKNİK
Moltiplicatore sul rolling median per la soglia adattiva. Default 2.0 corrisponde approssimativamente a p70–p80 della distribuzione tipica del gradiente. Più basso = crescita più aggressiva (più cloni), più alto = più rigoroso (meno cloni). Test Q5 in range 1.5–3.0 — 2.0 miglior default. Rilevante solo se.
Müfredat (Q6) (T80–T81)
T80curriculumResolutionRamp
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione Q6: la risoluzione di training inizia a 0.5× e cambia a T50 positionLRScheduleEndIteration / 2 (o T1 maxIterations / 2, se T50 non è impostato) a T22 trainingRenderScale. Usa l'infrastruttura resize/restoreImageBuffers sviluppata in Q1.5.1. Sovrascrive T23 resolutionWarmupScale se attivato. Q6 è passato come "portatore del guadagno di qualità" nel bundle Q5+Q6 (vedi T77) — l'aumento graduale di risoluzione dà all'app tempo di trovare geometria grossolana sulla risoluzione più bassa, prima di passare al lavoro di dettaglio fine. Via CLI: –curriculum-resolution.
T81curriculumSHProgression
DETAYLAR
Varsayılan: false Range: boolean Tanımlandığı yer:
TEKNİK
Funzione Q6: sovrascrive T21 shDegreeUpgradeIterations con [maxIter/4, maxIter/2, maxIter*3/4], distribuisce quindi gli upgrade SH uniformemente sul tempo di training invece di caricarli sul fronte. Ipotesi: la geometria stabile viene stabilita prima dell'esplosione del color detail, il che posiziona più precisamente gli effetti di luce dipendenti dalla direzione di vista. Q5+Q6 insieme PASS 1/3 scene, Q6 come portatore del guadagno (Q5 alone FAIL). Via CLI: –curriculum-sh.
Statik önayarlar (TP1–TP9)
Burada yalnızca başlatıcı varsayılanına göre yapısal farklar yer alır. On UI önayarı P1–P10 için tam pazarlama açıklamasını Bölüm 7'de bulursun.
TP1.preview
DETAYLAR
Preset diagnostico/anteprima per sistemi ≥ 10 GB RAM. Override rispetto all'inizializzatore: - 30 000 → 5 000 - 15 000 → 3 500 (70% di maxIter) - 1.6e-6 → 1.6e-5 (10× più alto, decay meno aggressivo) - ,,,, ciascuno 2× (V176) - 3 000 → 100 000 (effettivamente off, V172: il reset distrugge i training brevi) - [1K, 2K, 3K] → [1K, 2K] (V182: il grado 3 non converge in 2K iter) - 1.0 → 0.5
TP2.full
DETAYLAR
Quality di produzione Classic. Override: - 30 000 → 35 000 (V550: i test 40K Truck overtraining +10.7% Gs con -1.3% L1) - 15 000 → 5 000 (V310 sweet spot, V338 7K worse) - Tutte le LR 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 disabilitato, V421 confermato) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 ritardato) - 0.0 → 0.9995 (V546 HTGS, 14% di miglioramento) - 50 (invariato, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, già default dell'inizializzatore per .full)
TP3.fullClassicPaper
DETAYLAR
Sibling di test Q1.5-A di TP2, Classic fedele al paper. Override rispetto a TP2: - 35 000 → 30 000 (standard paper) - 5 000 → 15 000 (paper: 50% di maxIter) - 1.6e-5 → 1.6e-6 (default paper) - ,, indietro a default paper (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (calibrato per ~1-2M Gs su Bicycle) - 200 → 100 (paper) - 0.001 → 0.005 (default paper) - 100 000 → 3 000 (paper §5.2, rischioso — può scatenare regressione V194) - 0.9995 → 0.0 (paper non ha decay) - 20 000 → 30 000 (cosine gira al 100% di maxIter)
TP4.fullMCMC
DETAYLAR
Quality di produzione MCMC. Override rispetto all'inizializzatore: - 30 000 → 200 000 (V534, MCMC ha bisogno di 5× più iter di Classic) - 15 000 → 160 000 (V504b 80% di maxIter) - 1.6e-6 → 1.6e-5 - LR schedule come TP2 (tutte 2×) - 0.2 → 0.05 (V521b/V534: MCMC ha bisogno di segnale L1 più forte) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (già nell'inizializzatore, nel preset confermato) - 5e-5 (V467/V536 ottimale) - 0.005 → 0.01 (V535 ottimale) - 0 → 160 000 (80% di maxIter, V497c/V502) - 3.0 (già nell'inizializzatore) - true (già nell'inizializzatore) - 3 000 → 200 000 (effettivamente off, MCMC usa reloc invece di reset)
TP5.fullMCMCMip
DETAYLAR
Sibling di test Q1.5-D di TP4, con Mip-Splatting + budget MCMC di magnitudine paper. Override rispetto a TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, magnitudine paper) - useMipSplatting false → true (Mip on)
TP6.classicBalanced
DETAYLAR
Mid-tier Classic. Override rispetto a TP2: - 35 000 → 20 000 (V149: 20K = 30K con 33% in meno di tempo) - 20 000 → 0 (cosine corre su maxIter = 20K, nessuna extended phase)
TP7.mcmcPreview
DETAYLAR
Diagnostica MCMC. Override rispetto a TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80%) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: Preview = scaling più leggero)
TP8.mcmcBalanced
DETAYLAR
Mid-tier MCMC. Override rispetto a TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80%) - 160 000 → 96 000 (80%) - 3.0 → 2.5 (tra Preview 2.0 e Full 3.0)
TP9.quickTest
DETAYLAR
Puro test funzionale. Override rispetto all'inizializzatore: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (calibrato per risoluzione 0.25×) - 100 → 50 - 3 000 → 100 000 (off, perché troppo breve) - 1.0 → 0.25
Yöntem:
Signature: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Tanımlandığı yer:
Unica fonte di verità per la domanda "quante gaussiane MCMC può far crescere al massimo?". Si calcola da tre input: il T62 mcmcMaxGaussians configurato (con floor mass extinction 150 000, se 0), il (numero di punti SfM init) e la (dimensione del buffer gaussiano pre-allocato). Logica:
+ base = T62 > 0 ? T62: 150_000 (il floor mass extinction protegge contro bug di default dell'inizializzatore come l'incidente mass extinction 1.4.3) + Se T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) altrimenti
+ Se bufferCapacity > 0: return min(scaled, bufferCapacity) + Altrimenti return scaled
Esempio: Bicycle (Mip-NeRF 360, 194 foto-frame) → SfM-init ~156 K punti, T62 = 150 000, T72 = 5.32, capacità buffer 8 M. Resolved cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. È il cap di crescita effettivo a cui si attiene la logica di rilocazione MCMC.
Calcola il vero numero massimo di splat con MCMC. Prende la tua impostazione, guarda quanti punti ha la tua scena all'inizio, e scala con il Multiplier se l'adattamento automatico è on. Così il cap si adatta alla scena, invece di forzare lo stesso valore per una scena piccola e una enorme. Non devi chiamare il metodo tu stesso — il training lo usa internamente.
Hangi alan ne için? (kopya kağıdı)
| Obiettivo | Campi da regolare |
|---|---|
| Più dettaglio in lontananza | T62 mcmcMaxGaussians alto, T72 mcmcCapMultiplier 5+ |
| Più dettaglio in generale (Classic) | T1 maxIterations alto (≤ 40K), T2 densifyUntilIteration ≤ 14% di T1 |
| Ridurre floater nei voli di drone | T43 frustumCullEnabled on, T20 skyMaskingEnabled on, T45 skyDomeEnabled on |
| Bel cielo in scene esterne | T45 skyDomeEnabled on, T47 skyDomeRadiusMultiplier 30–60 |
| File di export più piccolo | Strategia .mcmc (T61), T56 postTrainingCompactification on, T62 mcmcMaxGaussians ≤ 200K |
| Training più veloce | T22 trainingRenderScale 0.5, T1 maxIterations dimezzare — ma non entrambi! |
| Migliori luci speculari | T21 shDegreeUpgradeIterations con [2K, 5K, 8K] (nessun early front load), MCMC + 200K iter |
| Mantenere il Mac reattivo | T25 throttleDelayMs 5–10 (costa ~15% di tempo training) |
| Live preview più frequente | T59 livePreviewInterval giù a 10–20 |
| Transizioni più morbide alle ombre | T17 ssimWeight un po' alto (0.15–0.25), ma non oltre 0.3 |
| Mantenere interni compatti | Preset P10 Indoor (, T72 = 1.76) |
Tehlikeli alanlar
Questi campi con configurazione errata possono portare a OOM, crash dell'app, mass extinction delle gaussiane o dati benchmark inutilizzabili. Da trattare con cautela:
- T11 densifyGradThreshold — un dimezzamento può generare 2–4× più gaussiane, il che fa rapidamente esplodere la memoria GPU. Da considerare anche: deve corrispondere a T22 trainingRenderScale (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — con scene grandi con > 200 K punti SfM-init e multiplier > 5 nasce un cap risolto di milioni di gaussiane. Su Mac da 36 GB di RAM OOM possibile. Il 5.32 del preset Outdoor funziona solo perché Mip-NeRF-360 Bicycle ha 156 K punti init → 830 K cap. - T39 testViewIndices — l'impostazione manuale può rendere il benchmark inutilizzabile (tutti gli indici > N → nessun holdout). Lascia che il flag –benchmark lo imposti. - T64 mcmcOpacityRegWeight e T65 mcmcScaleRegWeight — nella 1.4.3 beta impostati a 0.01, il che ha portato a mass extinction (460 K → 5 gaussiane in un'iterazione). Dalla 1.4.4 fissato a 0.0, ma l'aumento manuale può riprodurre il problema. - T15 opacityResetInterval — se non 100 000+ (effettivamente off) e il training è più breve di 10 000 iterazioni, il reset distrugge la convergenza. .preview ce l'ha quindi su 100 000 nonostante maxIterations = 5 000. - T54/T55 densifyPhase2* — la densification a due fasi è stata interrotta nei test in 0-gaussian cascade. Lascia entrambi a 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, può addirittura peggiorare il PSNR su alcune scene outdoor. Default off, opt-in solo per ricerca.
Se un campo è in questa lista e vuoi modificarlo, fai prima un backup del tuo preset attuale (export come JSON) e considera se puoi misurare in modo riproducibile il risultato — altrimenti dopo non sai se hai prodotto un miglioramento o un peggioramento.