Capítulo 6 — Configuração de treinamento
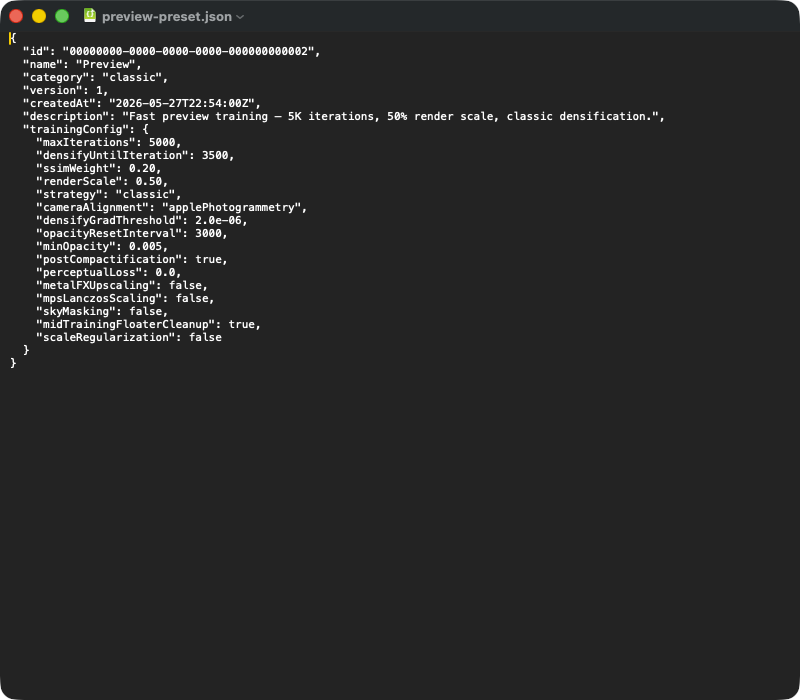
Um export típico de predefinição em JSON. Campos no topo: id (UUID), name, (classic | mcmc | sceneClass | custom), (versão de schema), (timestamp), (texto livre). O objeto aninhado contém os parâmetros críticos para reprodutibilidade — no import, todo o bloco é deserializado para a struct TrainingConfig, e os defaults da versão do app preenchem os campos faltantes (p. ex. após update do app). Quem passa uma predefinição para outro Mac envia apenas esse JSON.
A struct TrainingConfig é o coração de todo treinamento no RadianceKit. Ela reúne cada parâmetro que afeta o treinamento — do número máximo de iterações pelas oito learning rates até os campos especiais de MCMC, Mip-Splatting, currículo e a lógica scene-aware de cap. Você a edita na sidebar na seção Configuração de treinamento (Expert View), salva como predefinição ou repassa como export JSON para outro Mac. No treinamento, esse objeto é congelado e entregue ao backend de GPU.
Este capítulo é material de referência para usuários avançados e autores de script. Lista todos os 81 campos públicos, as 9 predefinições estáticas e o método público único. O arquivo-fonte é TrainingConfig.swift — em caso de dúvida, vale o doc comment ali e o default do initializer como source-of-truth.
Sumário:
+ Iteração (T1–T2) + Learning rates (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + Progressão de SH degree (T21) + Performance (T22–T25) + Diagnóstico e preparação da nuvem de pontos (T26–T30) + Regularização (T31–T37) + Refinement (T38–T44) + Sky Dome (T45–T48) + Adam + LR Schedule (T49–T55) + Pós-processamento + Apple AI (T56–T60) + MCMC Densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptive Densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Predefinições estáticas (TP1–TP9) + Método: + Qual campo para quê? (cheat sheet) + Campos perigosos
Iteração (T1–T2)
T1maxIterations
DETALHES
Default: 30 000 (Initializer), 35 000 (.full), 200 000 (.fullMCMC) Range: 1 000 – 500 000 (slider UI), sem limite duro na lógica Defined in:
TÉCNICO
Total de iterações de treinamento que o backend percorre. Uma iteração denota um forward render de uma única câmera de treinamento, um backward pass por todos os componentes de loss (L1 + SSIM + regularizações opcionais + máscara de céu) e um passo do otimizador Adam. Esse número atua direto sobre outros schedules: LR de posição segue cosine annealing de 0 até T1 ou T49 positionLRScheduleEndIteration; densification para em T2 densifyUntilIteration; decaimento de noise MCMC termina em T69 mcmcNoiseDecayEnd; upgrades de SH degree acontecem nas três marcas definidas em T21. Em densification classic, o sweet spot empírico está em 20 000–35 000 iterações (Sessões 1–32, testes V546); em MCMC, em 60 000–200 000 (V534). Aumentar bem acima dos valores do preset raramente traz mais qualidade — momentum Adam satura e, sem fim de LR decay, o loss estagna. Reduzir abaixo de ~5 000 leva a geometrias não convergidas (density control não tem tempo de clone/split).
T2densifyUntilIteration
DETALHES
Default: 15 000 (Initializer), 5 000 (.full), 160 000 (.fullMCMC) Range: 0 – Defined in:
TÉCNICO
Iteração em que a densification para. Até aqui, Gaussians são clonados, splitados e prunidos pelas regras dos campos T11–T16 (Classic) ou T67–T70 (MCMC); depois a contagem fica constante e só posições, rotações, escalas, opacidades e SH são otimizados (refinement). No paper original 3DGS o valor fica em 50% de T1; no .full do RadianceKit em apenas ~14% (5 000 de 35 000) — resultado dos experimentos V310/V338, que mostraram que após 5 000 iters mais densification piora o resultado (mais floaters, mais memória, sem ganho). Em MCMC, a relocação roda até 80 % de T1 (V504b), porque MCMC não produz floaters daninhos. T2 pequeno demais (< 1 000) gera poucos Gaussians; grande demais em Classic (> 50 % de T1) leva a overgrowth e outliers de RGB saturation (ver Outdoor Overtraining Findings).
Learning rates (T3–T10)
T3positionLearningRate
DETALHES
Default: 0.00016 Range: 1e-7 – 1e-3 (recomendado) Defined in:
TÉCNICO
LR Adam para posição XYZ de cada Gaussian no início do treinamento (iter 0). Segue cosine annealing e desce ao longo do treinamento até T4 positionLearningRateFinal. O default 0.00016 vem do paper 3DGS original (Kerbl et al., 2023) e no RadianceKit não escala com a resolução — posição se move em coordenadas do mundo, não em pixel space. Aumentar muito (> 0.0005) faz Gaussians pularem distâncias grandes e o loss fica instável; diminuir muito (< 0.00005) faz pontos mal inicializados nunca encontrarem o lugar. V414 testou dobrar o init → loss 16.8 % pior; V544a confirmou o paper default como ótimo. Nota: em .fullMCMC, mantemos esse valor no default propositadamente — MCMC precisa de LRs constantes para sua lógica de relocação; tunar aqui não ajuda.
T4positionLearningRateFinal
DETALHES
Default: 0.0000016 (Initializer + paper), 0.000016 (.full, .fullMCMC — 10× maior) Range: 0 – Defined in:
TÉCNICO
Valor final da curva cosine annealing de position LR. É atingido em T1 maxIterations ou em T49 positionLRScheduleEndIteration (se definido). O preset .full do RadianceKit usa 0.000016 — ou seja 10× o paper default 0.0000016. V420 mostrou que 0.5× do final (0.000008) piora o loss em 6.4 %; V414 mostrou que 2× o init piora em 16.8 %. O final alto não é trade-off, é escolha consciente: com decay forte demais, os Gaussians perdem na refinement a capacidade de se ajustar aos novos candidatos de densification. Via extensão V431/V433 a fase de schedule pode ser encurtada (T49 < T1), de modo que T4 é atingido antes do fim e o restante roda em mini-LR constante — configuração típica: T49 = 20 000, T1 = 35 000, refinement em 0.000016 por 15 000 iters.
T5shDCLearningRate
DETALHES
Default: 0.0025 (Initializer + paper), 0.005 (.full e todas predefinições MCMC — 2×) Range: 0.0001 – 0.05 Defined in:
TÉCNICO
LR Adam para a parte DC (degree 0, albedo constante) da cor SH. SH-DC corresponde ao tom base independente de direção de uma Gaussian, a „cor base". V176 e V188 acharam 2× o paper default ótimo — convergência de cor mais rápida, especialmente em treinos curtos (< 5 000 iters), onde SH-DC senão não toma forma. Diferente das LRs geométricas, SH-DC não tem decay; fica constante ou segue o decay opcional de extended phase em T51. V416 testou quadruplicar para 0.01 → 6.4 % pior com Adam beta2=0.99.
T6shRestLearningRate
DETALHES
Default: 0.000125 (Initializer + paper), 0.00025 (.full e MCMC — 2×) Range: 0.000001 – 0.005 Defined in:
TÉCNICO
LR Adam para SHs de ordem mais alta (degree 1, 2, 3 — as partes de cor dependentes de direção que dão highlights, reflexões e shading suave). 20× menor que T5 por convenção do paper, porque esses coeficientes crescem quadraticamente em número (3 para degree 1, 5 para 2, 7 para 3 → 15 floats totais por Gaussian) e sem LR menor saturaria a imagem. É liberado em dois passos — até a primeira marca de T21 shDegreeUpgradeIterations só degree 0 (só T5), depois 1, depois 2, depois 3. Valores baixos aqui são importantes em cenas com muita iluminação difusa; em superfícies muito brilhantes (laca de carro, água) não vale girar — a representação SH em si é limitada.
T7opacityLearningRate
DETALHES
Default: 0.05 (Initializer + paper), 0.1 (.full, MCMC — 2×) Range: 0.001 – 1.0 Defined in:
TÉCNICO
LR Adam para opacidade logit por Gaussian. O app guarda opacidade como float sem limite e aplica sigmoid em [0, 1]; a LR atua no logit space. O default do paper 0.05 foi restaurado após V50 (best single run L1 0.1664); V71 reverteu o 0.025 de V67. A duplicação V188 para 0.1 torna o pruning mais eficiente — Gaussians mortos caem mais rápido abaixo de T14 pruneOpacityThreshold. V418: 0.05 com Adam beta2=0.99 é 7.1 % pior que 0.1 — a interação com Adam não é trivial. Valores baixos (< 0.01) deixam „dead" Gaussians para sempre e gastam memória; altos (> 0.5) causam explosão de opacidade, daí o clamp do logit em [-15, 3] no otimizador (ver „Opacity Explosion Prevention" em CLAUDE.md).
T8opacityLearningRateFinal
DETALHES
Default: 0.0 (= „sem decay") Range: 0 ou 0.001 – Defined in:
TÉCNICO
Valor final opcional de cosine decay para LR de opacidade (V427). Em 0.0, decay desligado; LR fica constante em T7. V427 testou decay 0.1 → 0.01 → 11.5 % pior; reverted. Hipótese: LR constante de opacidade poderia oscilar na refinement, com splats de transparência certa sendo deslocados por ruído. Empiricamente falso — o clamp do logit já cuida. O campo fica disponível para futuros experimentos; runs MCMC muito longos (> 500K iters) poderiam se beneficiar.
T9scaleLearningRate
DETALHES
Default: 0.005 (Initializer + paper), 0.01 (.full, MCMC — 2×) Range: 0.0001 – 0.1 Defined in:
TÉCNICO
LR Adam para os três componentes de escala em log space (RadianceKit guarda log(scale) para escala ficar positiva). Paper default 0.005, dobrado no RadianceKit para 0.01 em prol de melhor convergência. V423: 0.005 com Adam beta2=0.99 → 18.7 % pior + poucos Gaussians (density control não clonava porque updates de escala eram lentos). Escala controla extensão de cada Gaussian — aprender rápido demais leva a Gaussians-agulha (T34 scaleRatioPruneThreshold); lento demais mantém splats compactos e density control divide demais.
T10rotationLearningRate
DETALHES
Default: 0.001 (Initializer + paper), 0.002 (.full, MCMC — 2×) Range: 0.0001 – 0.05 Defined in:
TÉCNICO
LR Adam para os quatro componentes de quaternion de cada Gaussian. O quaternion é re-normalizado a cada passo (norma L2 = 1); senão a matriz de covariância degenera. RadianceKit duplica o paper default em quality presets porque rotação tem magnitudes menores de gradiente que escala/posição (na esfera unitária cada passo é curto) e sem 2× ficaria sub-convergida em 35 000 iters. V188 documenta. Em cenas NeRF-Blender (Lego, Chair) rotação se destaca — bordas só se alinham depois de 5 000–10 000 iters.
Densification — Classic (T11–T16)
T11densifyGradThreshold
DETALHES
Default: 0.000002 (Initializer, calibrado para 0.5×), 0.0000011 (.full, calibrado para 1.0×), 0.000004 (.quickTest, 0.25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (dependente da resolução) Defined in:
TÉCNICO
Limiar para a norma L2 do gradiente projetado em screen space dMean2D, acima do qual um Gaussian é marcado para clone/split. O valor absoluto depende direto da resolução de treino — dMean2D escala como ~1/resolução² (mais pixels = gradientes por pixel menores). Por isso cada degrau de T22 trainingRenderScale precisa de um limiar calibrado: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 ... 1.1e-6 (.full). O paper default 0.0002 é normalizado em NDC e não comparável diretamente ao pipeline em world space do RadianceKit. Com o flag T52 adaptiveDensifyThreshold (V440) ativo, o valor sai do p98 da distribuição corrente — mas V440 testou em cenas reais e produziu 63 K Gaussians (perda catastrófica de pruning); o flag fica off. Q5 (T77–T79) traz alternativa via rolling median. Não é seguro — metade gera 2–4× mais Gaussians (pressão de memória, risco de OOM); dobrar pode sub-densificar.
T12densifyFromIteration
DETALHES
Default: 500 Range: 100 – 5 000 Defined in:
TÉCNICO
Primeira iter em que densification fica ativa. Antes, treinamento „nu" na nuvem inicial SfM, sem novos Gaussians. O default 500 vem do paper 3DGS e dá à inicialização tempo de se estabilizar — com densify desde iter 0, pontos SfM mal posicionados clonariam várias vezes antes mesmo de achar o lugar. V349 testou 1000 → loss um pouco pior; o default é ótimo.
T13densifyInterval
DETALHES
Default: 100 (Initializer, MCMC), 200 (.full) Range: 50 – 1 000 Defined in:
TÉCNICO
Quantas iters entre dois passos de densification. Paper default 100 — a cada 100 iters avalia candidatos de densify, clone/split e ao mesmo tempo prune (sigmoid(opacity) < T14 pruneOpacityThreshold) os mortos. V112: 200 é ótimo para .full — alivia a GPU (menos passos de reorganização) e dá a cada Gaussian mais tempo de se acomodar após clone. V417 testou 100 com beta2=0.99 → 5.8 % pior (957K Gaussians, sobredensify). Em MCMC, o mesmo campo é interpretado como intervalo de relocação; ver T67 mcmcRelocationInterval para a lógica MCMC.
T14pruneOpacityThreshold
DETALHES
Default: 0.005 (Initializer, paper, MCMC), 0.001 (.full) Range: 0.0001 – 0.1 Defined in:
TÉCNICO
Limiar de sigmoid(opacity) abaixo do qual o Gaussian é deletado no próximo passo de densify. Trabalha junto com T7 opacityLearningRate e o clamp do logit no otimizador. V393 baixou o default em .full de 0.005 para 0.001 — splats que só importam em ângulos exóticos sobrevivem mais tempo e contribuem para detalhe SH. V394 testou 0.0001 → um pouco pior (pouco pruning, memória desperdiçada). Importante: density control DEVE sempre prunar, mesmo quando a capacidade do buffer já está cheia por outros motivos (ver „Density Control Must Always Prune" em CLAUDE.md) — senão Gaussians mortos acumulam e a contagem trava.
T15opacityResetInterval
DETALHES
Default: 3 000 (Initializer + paper), 100 000 (.full = efetivamente desativado), 200 000 (.fullMCMC = desativado) Range: 1 000 – 100 000+ Defined in:
TÉCNICO
A cada quantas iters a opacidade de todos os Gaussians é resetada para baixo (~0.01) — medida do paper 3DGS para reavaliar splats „congelados". V194 mostrou que, com warmup + treino estocástico + LRs 2× do RadianceKit, o reset custa 5.5 % de qualidade; o clamp do logit já cobre a função do reset. Por isso desativado de fato em .full (100 000 > 35 000 = nunca dispara). V421 testou reset a cada 3 000 com beta2=0.99 → 4.9 % pior; reverted. Em .fullClassicPaper (Q1.5-A, testes paper-faithful) está propositadamente em 3 000 — um dos levers para atingir os budgets de Gaussian do paper.
T16maxScreenSize
DETALHES
Default: 0.0 (= desativado) Range: 0 (off) ou > 0 Defined in:
TÉCNICO
Tamanho máximo em screen space (pixels projetados) que um Gaussian pode atingir antes de ser splitado. Em 0 (V48 testou e reverted) — density control do RadianceKit usa o threshold de escala world space do dMean2D em vez disso. Fica no catálogo porque experimentos futuros com Mip-Splatting (T74–T76) ou estratégias scene-specific podem usar. Ativar (> 0, p. ex. 20) forçaria splats muito grandes na tela a se dividirem — relevante em paredes grandes/lisas onde um splat gigante teria pouco detalhe.
Loss (T17–T20)
T17ssimWeight
DETALHES
Default: 0.2 (Initializer + paper + .full), 0.05 (todas predefinições MCMC) Range: 0.0 – 1.0 Defined in:
TÉCNICO
Peso da parte D-SSIM na função de loss combinada loss = (1 - λ) * L1 + λ * D-SSIM, com λ = T17. O paper default 0.2 é ótimo para Classic — V383 testou 0.3 → 28.9 % pior; V373b confirmou 0.2 como sweet spot. Em MCMC, V521b/V534 acharam independentemente 0.05 ótimo — MCMC, por sua exploração estocástica, precisa de sinal L1 mais forte; pesos SSIM maiores diluiriam decisões de relocação. SSIM é caro (janela 11×11 sobre toda a imagem); RadianceKit usa implementação MPS abaixo de 1 ms por imagem 1080p. Q7-BayesOpt achou ótimos por cena entre 0.05 (.outdoorPreset: 0.082) e 0.171 (.indoorPreset).
T18ssimWeightRefinement
DETALHES
Default: 0.0 (= „sem troca, mantém ssimWeight") Range: 0 ou 0 – 1.0 Defined in:
TÉCNICO
Valor SSIM opcional para a fase de refinement após T2 densifyUntilIteration. V428 testou 0.2 → 0.3 no refinement → 16 % pior (L1 e SSIM ambos pioraram); reverted, daí default 0.0. Hipótese: após densification, mais SSIM maximizaria nitidez estrutural. Empiricamente falso: subir SSIM reduz peso L1, e L1 é o sinal mais informativo no refinement final. O campo fica para futuros experimentos com perceptual loss (T60) ou edge loss (T19), onde composição de loss específica para refinement pode fazer sentido.
T19edgeLossWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.001 – 1.0 Defined in:
TÉCNICO
Loss experimental V437: peso de L1 em domínio de gradiente Sobel comparando bordas (Sobel da ground truth vs Sobel do render) adicionalmente a L1+SSIM. Hipótese: borda é pilar perceptual de qualidade; termo explícito encorajaria Gaussians a acertar bordas. Resultado: peso 0.1 → 11 % pior loss, 0.01 → neutro mas 10 % mais lento. O Sobel custa MPS forward extra em GT + render. Por isso permanentemente off. Caso futuro: cenas com bordas artificiais duras (arquitetura, móveis, renders) poderiam ganhar — mas Q7 Scene Class não escolheu, e sim escalou peso SSIM.
T20skyMaskingEnabled
DETALHES
Default: false (Initializer e todas predefinições) Range: boolean Defined in:
TÉCNICO
Liga sky masking. A região de céu é mascarada em cada imagem via Apple Vision (VNGenerateForegroundInstanceMaskRequest) e o loss nessa área é zerado. Motivo: cenas externas sofrem quando pixels azuis/cinzas/brancos de céu fazem o app posicionar Gaussians lá — percebidos como floaters. Sem máscara de céu, o loss nessa área nunca é zero (céu varia levemente) e o app tenta infinitamente reproduzir com splats. A máscara Vision é calculada uma vez por câmera antes do treinamento e mantida em RAM. Tipicamente ativado junto com T45 skyDomeEnabled (lógica UI em Settings). Em cenas internas ou renders sintéticos, deixe off — a máscara identificaria tetos ou paredes como „céu".
Progressão de SH degree (T21)
T21shDegreeUpgradeIterations
DETALHES
Default: [1_000, 2_000, 3_000] (Initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — degree 3 pulado) Range: [Int], cada um em [0, maxIterations], monoticamente crescente Defined in:
TÉCNICO
Iters em que o SH degree ativo passa de 0→1, 1→2, 2→3. Antes da primeira marca só DC (T5 shDCLearningRate); após primeira, DC + 3 coefs degree 1; após segunda, + 5 degree 2; após terceira, todos os 15. Memória por Gaussian cresce em degraus — 4 floats → 16 → 36 → 64. Quality presets atrasam os upgrades vs Initializer (V228) porque a geometria deve estabilizar antes da cor de frequência mais alta. V384 testou [1K, 2K, 3K] em .full → 9.3 % pior — confirma o atraso. .preview para em degree 2 porque degree 3 não converge em 5 000 iters e só gasta otimizador. Q6 (T80–T81) oferece lógica alternativa de currículo que sobrescreve essa lista dinamicamente.
Performance (T22–T25)
T22trainingRenderScale
DETALHES
Default: 1.0 (Initializer, .full, MCMC, Scene Class), 0.5 (.preview), 0.25 (.quickTest) Range: 0.05 – 2.0 (típico 0.25, 0.5, 1.0) Defined in:
TÉCNICO
Resolução de render no treinamento relativa à resolução original das imagens. Em 0.5, cada imagem é reduzida a 50 % largura × 50 % altura (25 % dos pixels) e o render Gaussian roda nessa resolução. Reduz memória e compute quadraticamente. Importante: T11 densifyGradThreshold deve combinar — magnitudes escalam com 1/resolução², por isso .quickTest (0.25×) tem threshold muito maior (4e-6) que .full (1.0×, 1.1e-6). RadianceKit avisa em imagens grandes e ajusta automaticamente — alvo ~3 MP. Em 4K extremo, 0.5 ou 0.25 fazem sentido; senão CPU compaction.
T23resolutionWarmupScale
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.1 – Defined in:
TÉCNICO
Otimização V133: treina a fase de densification (iter 0 a T2) numa resolução mais baixa que a refinement. V308 desligou em .full, porque com T22 = 1.0 e cosine annealing o ganho de tempo era marginal e a qualidade sofria. Fica no catálogo porque em entradas 4K com treinos longos pode voltar a fazer sentido — Q6 Curriculum (T80) pegou lógica similar mas acoplada ao schedule de LR. Se ativado e T80 curriculumResolutionRamp também true, Q6 vence e sobrescreve.
T24tileSize
DETALHES
Default: 16 Range: 8, 16, 32 Defined in:
TÉCNICO
Tamanho dos tiles de rasterização em pixels. O rendering Gaussian é tile-based: a imagem é dividida em tiles 16×16; cada tile coleta seus Gaussians relevantes, ordena por profundidade e blendea. 16 é o padrão de quase todas as implementações 3DGS e hard-coded nos kernels Metal; mudar pediria recompilação de shaders — não efetivo no estado atual. Fica como campo caso versão futura suporte tile size dinâmico.
T25throttleDelayMs
DETALHES
Default: 0 (Initializer, .full, MCMC, Scene Class), 0 (.preview) Range: 0 – 100 Defined in:
TÉCNICO
Delay artificial entre iters em ms. 0 = full speed (padrão). Maior torna o Mac mais „usável" no treinamento porque GPU/CPU pegam pausas — responsividade de outros apps sobe, tempo de treinamento sobe linearmente. Típicos: 1–2 ms (throttling leve, +5 %), 5 ms (médio, +15 %), 10+ ms (eco, potencialmente dobro). Oferecido no Inspetor em „Performance" mas fora da view padrão — ver backlog dev_ux-backlog.md que sugere removê-lo do Expert View porque, mal entendido, alonga muito o treinamento.
Diagnóstico e preparação da nuvem de pontos (T26–T30)
T26depthDistortionWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.0001 – 0.05 Defined in:
TÉCNICO
Experimental V366: peso de um loss de regularização de distorção de profundidade. Penaliza Gaussians que ao longo de um ray estão escalonados em profundidade mas conceitualmente pertencem à mesma superfície — encoraja distribuições concentradas e reduz floaters. Testes: 0.01 → 4.5 % pior, 0.001 → 8.1 % pior. Vantagem teórica de melhorar consistência multi-view não vira ganho de L1, porque a hipótese implícita é geometria SfM correta. Na prática, SfM é o componente mais fraco, não o empilhamento. Disponível para datasets multi-view com poses muito limpas (Synthetic, Mip-NeRF 360 com ground truth).
T27singleViewOverfit
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Flag de diagnóstico: em true, cada iter usa o camera index 0 obrigatoriamente. Sentido: se o modelo não consegue overfitar uma única view (loss em view 0 não vai a zero após 10 000 iters), há bug fundamental no forward/backward. Usado intensamente no desenvolvimento dos shaders Metal e do differentiable rasterizer — fase V42–V47. Hoje só como sanity check para quem modificou backend e quer um regression test. Via CLI: –single-view.
T28maxCameras
DETALHES
Default: 0 (= „todas as câmeras") Range: 0 ou 1 – N Defined in:
TÉCNICO
Limite diagnóstico V43: treina só com as primeiras N câmeras, ignora o resto. Hipótese original: muitas câmeras gerariam conflitos de gradiente (muitos sinais de loss contraditórios para a mesma Gaussian). Resultado: nenhum benefício sistemático com limite artificial — mais frames quase sempre trazem mais qualidade. Fica como CLI (–max-cameras N) para experimentos pontuais. Sem exposição na UI.
T29maxInitialPoints
DETALHES
Default: 0 (= „todos os pontos SfM") Range: 0 ou 1 000 – 200 000+ Defined in:
TÉCNICO
Salvaguarda V54: limita pontos SfM iniciais. Reconstruções COLMAP densas podem ter > 60 000 pontos, o que com escalas iniciais grandes gera 200–300 Gaussians por pixel-overlap — vira „neblina" e o treino não converge. Subsampling a ~16 000 (hard cap na engine de treinamento) traz densidade inicial ao nível do 3DGS de referência e reduz overlap dramaticamente. Setado automaticamente em SfMs muito densos; via CLI: –max-points N.
T30cameraClusterOutlierMultiplier
DETALHES
Default: 10.0 (todas predefinições — nunca sobrescrito) Range: 1.0 – 100.0 Defined in:
TÉCNICO
Multiplicador para o filtro de outliers de cluster de câmeras, introduzido na Fase 3.10 A.1. Antes do treinamento, a engine calcula o centroide das posições de câmera e a distância máxima de câmera ao centroide. Pontos SfM cuja distância ao centroide excede multiplier × maxCameraDistance são descartados. 10× preserva comportamento pré-Fase 3.10. Bug sutil: SfM mais apertado → menor → menor limiar → mais pontos descartados como outliers. SfM mais largo → maior limiar → menos descartados. É uma das causas da anti-correlação funnel-vs-treinamento da Fase 3.9: melhor SfM pode dar treinamento pior porque mata pontos iniciais demais. Campo via CLI (–camera-cluster-outlier-multiplier) para sweeps A.3; não exposto na UI. < 5 muito restritivo; > 20 sem efeito.
Regularização (T31–T37)
T31coarseToFineBlurRadius
DETALHES
Default: 0 (= desativado) Range: 0 ou 1 – 10 Defined in:
TÉCNICO
Experimental V369: raio de box blur aplicado à ground truth no início da densification, reduzido linearmente até o fim de densification (T2) para 0. Hipótese: treino coarse to fine — estruturas grossas primeiro, detalhes depois — daria geometria mais estável. Testes: r=3 → 9.6 % pior, r=1 → 5.1 % pior. Motivo: density control decide com base em gradientes no domínio da imagem; blur reduz justamente os sinais para „clone aqui". Fica no catálogo para futuros esquemas de density control.
T32scaleRegWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.0001 – 0.05 Defined in:
TÉCNICO
Experimental V370: regularização L1 sobre escala world space. Pune Gaussians grandes demais — evita „mega splats" que cobrem paredes inteiras. Testes: 0.01 → 200 % pior loss (2M Gaussians, explosão total); 0.001 → 214 % pior. Motivo: regularização de escala briga com density control — escalas menores significam mais Gaussians necessários, density control divide com frequência, mais compute de gradiente. Disabled mas documentado para experimentos Mip Splatting (T74): nesse contexto um lower bound de escala pode fazer sentido.
T33anisotropyRegWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.0001 – 0.05 Defined in:
TÉCNICO
Experimental V445: penalidade sobre razão max(scale)/min(scale), para evitar Gaussians-agulha percebidos como floaters. Testes: 0.01 → 69 % pior, 0.001 → 15 % pior. Motivo: regularização força splats para forma „redonda", o que em superfície plana (parede, mesa, chão) é justo o errado — ali um Gaussian achatado e largo é mais eficiente que esférico. Disabled. V549f ofereceu via T34 scaleRatioPruneThreshold uma alternativa mais direcionada que também foi revertida.
T34scaleRatioPruneThreshold
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 5.0 – 100.0 (típico 10.0 – 30.0) Defined in:
TÉCNICO
Pruning experimental pós-treinamento que apaga Gaussian cuja razão max(scale)/min(scale) excede limiar. Foco em floaters tipo „needle/disc" que regularização sozinha não elimina. Em testes removeu floaters mas também splats úteis em paredes e chãos — a imagem ficou esburacada. Off por padrão; CLI (–scale-ratio-prune N) para experimentos. Valores recomendados se testar: 30 (conservador, só extremos), 10 (agressivo, custa detalhe).
T35opacityRegWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.0001 – 0.05 Defined in:
TÉCNICO
Experimental V446: penalidade BCE que puxa opacidade para 0 ou 1 (afasta do „meio-transparente"). Hipótese: opacidade mais nítida melhoraria clareza. Combinado com T33 → regularização custa qualidade; ambos desligados. Disabled. Bug 1.4.3-beta: o default do initializer estava errado em 0.01, o que causou mass extinction (460K → 5 Gaussians numa iter). Desde 1.4.4 fixado em 0.0.
T36opacityDecayFactor
DETALHES
Default: 0.0 (Initializer = desativado), 0.9995 (.full, .classicBalanced — padrão HTGS) Range: 0 (off) ou 0.95 – 1.0 Defined in:
TÉCNICO
Implementação V546 do esquema HTGS (Hierarchical Time Gating, Eurographics 2025): a cada T37 opacityDecayInterval iters, sigmoid(opacity) é multiplicado por esse fator. 0.9995 × 100 aplicações = ~95 % retenção por fase de densification — pressão suave mas constante para baixo que leva Gaussians fracos confiavelmente ao T14 pruneOpacityThreshold. Resultado: 14 % melhor L1 em Horse Full (avg 3 trials V546) vs V438 sem decay. Só ativo na fase de densification (até T2); depois roda sem decay, para manter estáveis as opacidades estabelecidas no refinement. Em MCMC não usado (MCMC tem T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETALHES
Default: 50 Range: 10 – 500 Defined in:
TÉCNICO
Intervalo de iters de T36 opacityDecayFactor. Default HTGS 50, mantido em .full. Intervalos longos (>200) cancelam parte do efeito — entre duas aplicações há gradiente suficiente para opacidade subir de novo. Curtos (<20) são agressivos demais. Só ativo na fase de densification.
Refinement (T38–T44)
T38gradientAccumulationSteps
DETALHES
Default: 1 (= „uma view por passo Adam") Range: 1 – 8 Defined in:
TÉCNICO
Feature V424: número de views cujos gradientes são acumulados antes de um Adam step. Com > 1, app roda numa trilha „unfused" backward project que soma gradientes em buffer separado; a aplicação final escala por 1/N para manter magnitude. V424 testou 2-view → neutro em qualidade mas 10 % mais lento (unfused é mais caro que fused). Reverted para .full, mas em MCMC é usado — .fullMCMC roda com, e V544a mostrou que com isso o gap a Classic cai para 5 % (em vez de 11 %). No initializer 1, no preset atual 1, fica via CLI (–accum-steps N).
T39testViewIndices
DETALHES
Default: [] (= vazio, todas as views vão para treinamento) Range: Set<Int>, subconjunto de indices de câmera Defined in:
TÉCNICO
Feature V546: set de indices que NÃO vão para treinamento, mas viram holdout para PSNR/SSIM/LPIPS. Setado automaticamente com –benchmark: cada 8ª view a partir do índice 0 (padrão LLFF, idêntico ao Mip-NeRF 360 e ao 3DGS paper). Sem benchmark, vazio — treinamento usa todas. Cuidado: setar sem entender os índices pode invalidar o benchmark (p. ex. indices > N com só N-50 views → sem holdout → sem avaliação). No export de predefinição, testViewIndices não persiste, porque depende da cena e poderia deixar valores sem sentido entre datasets.
T40refinementPruneInterval
DETALHES
Default: 0 (= desativado) Range: 0 ou 100 – 5 000 Defined in:
TÉCNICO
Feature V425: a cada N iters durante refinement (após T2), um passo extra de pruning roda e remove Gaussian com sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Sentido: na densification havia density control regular; depois não — Gaussians cuja opacidade segue caindo ficam no buffer. V425 testou e reverted: o pruning extra correlacionou com V426 (two-phase densification, também caiu em cascade failure de 0 Gaussians). Disabled. CLI disponível; se ativar, 1 000 ou 2 000 são razoáveis.
T41refinementPruneOpacityThreshold
DETALHES
Default: 0.0 (= „usa T14") Range: 0 ou 0.001 – 0.1 Defined in:
TÉCNICO
V425b: threshold separado para pruning de refinement. Após densification, a maioria dos Gaussians tem opacidade > 0.001, e o T14 pruneOpacityThreshold padrão seria frouxo. Se T40 ativo, este campo define o threshold próprio. Em 0.0, usa T14. Só relevante com T40 > 0.
T42midTrainingCompactificationIterations
DETALHES
Default: [] (= desativado) Range: [Int], valores em (densifyUntilIteration, maxIterations) Defined in:
TÉCNICO
Feature V549: iters explícitas na refinement em que roda compactification (mesma lógica de T56 postTrainingCompactification). Sentido: refinements longos acumulam confetti/floaters cujo SH overfita artefatos por view. Configuração típica: [10000, 20000, 30000] para Classic 40K. Mas: A/B V549 em family-dataset mostrou em todas as configs piores L1: [10K,20K,30K]@0.01 → −48 % count mas +36 % L1; [20K,30K]@0.005 → −44 % count mas +45 % L1; [20K,30K]@0.001 → −17 % count mas +87 % L1. Daí disabled. CLI –mid-compact "10000,20000" disponível para o trade-off „menos floater no viewport mas imagem mais embolada".
T43frustumCullEnabled
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature V549b: após treinamento remove Gaussians fora da união dos frusta de câmeras de treinamento. Esses Gaussians nunca foram restringidos pelo loss e são sempre floaters. Efetivo em cenas onde a novel view fica atrás ou ao lado da trajetória (p. ex. costas de drone linear) — floaters ali não aparecem em treino mas aparecem ao navegar em 3D. A/B V549b em drones positivos, daí opt-in. Default false, porque em object captures com orbit completa a união cobre tudo — ofereço em Settings „Floater Reduction" e implicitamente em P9 Outdoor testado via T44 frustumCullExpansion (Q7-BayesOpt não ativou, porque Outdoor sky dome resolve melhor o mesmo problema).
T44frustumCullExpansion
DETALHES
Default: 1.1 Range: 1.0 – 2.0 Defined in:
TÉCNICO
Margem NDC para T43 frustumCullEnabled. 1.0 cortaria exato na borda — splats ondulantes ali ficariam cortados demais. 1.1 = 10 % de padding além do framing exato — tolerância para pixels de borda que numa novel view ligeiramente deslocada apareceriam. Acima de 1.2 torna o cull quase inútil (o frustum estendido cobre demais).
Sky Dome (T45–T48)
T45skyDomeEnabled
DETALHES
Default: false (Initializer + todas predefs exceto P9 Outdoor) Range: boolean Defined in:
TÉCNICO
Feature V549e: antes do início do treinamento, uma nuvem esférica (fibonacci sphere com T46 pontos) é gerada, posicionada num raio de T47 skyDomeRadiusMultiplier × scene_extent em torno do centro e inicializada com cores dos pixels de céu mascarados (ver T20 skyMaskingEnabled). Esses Sky Dome Gaussians ficam no começo do buffer e são „congelados" no treinamento (gradientes de posição/escala/rotação = 0; só SH e opacidade são otimizados). Efeito: em vez de „confetti" preto distante, usuário vê céu real em novel views. MVP V549e funciona muito bem em drones e landscapes; em P9 Outdoor on por padrão. Em cenas internas off — esfera ficaria sem sentido fora do quarto.
T46skyDomeSampleCount
DETALHES
Default: 5 000 Range: 1 000 – 50 000 (típico 2 000 – 10 000) Defined in:
TÉCNICO
Número de pontos fibonacci sphere no Sky Dome. Maior → dome mais denso (melhor em altas resoluções e muito céu visível), mais memória. 5 000 é o sweet spot para 4K; em resoluções menores 2 000–3 000 bastam. Os pontos são inicializados pela distância cosseno ao view vetor de cada câmera e os pixels sky maskeados correspondentes — samples cujo view cone não vê nenhuma câmera ficam com baixa opacidade inicial, mas no treinamento não mudam (congelados).
T47skyDomeRadiusMultiplier
DETALHES
Default: 30.0 (Initializer + maioria das predefinições), 59.0 (P9 Outdoor, ótimo Q7-BayesOpt) Range: 5.0 – 200.0 Defined in:
TÉCNICO
Raio do Sky Dome relativo à extensão da cena (= distância média entre câmeras). 30 = esfera 30× o diâmetro da nuvem de câmeras. Pequeno demais (< 5) → dome interfere com a cena (p. ex. um splat dome no plano principal); grande demais (> 100) → perda de precisão float32 nas posições, render glitches distantes. Q7-BayesOpt em Bicycle (Mip-NeRF 360) achou 59.0 como ótimo scene-specific para outdoor — indica que 30 é pequeno demais para landscapes profundas; pixels do dome aparecem como „parede" na borda.
T48frozenGaussianCount
DETALHES
Default: 0 (= sem Gaussians congelados) Range: 0 ou 1 – T46 Defined in:
TÉCNICO
Número de Gaussians no começo do buffer cujos gradientes de posição/escala/rotação são zerados no otimizador — permanecem espacialmente rígidos. Density control não os clona/splita/pruna. Usado para injeção de Sky Dome (ver T45): quando dome on, este campo é setado automaticamente para T46 skyDomeSampleCount. Setar manualmente é possível (p. ex. congelar nuvem LiDAR pre-posicionada), mas não exposto na UI. Importante: os primeiros N Gaussians do buffer são sempre os congelados — ordem manda, não índice.
Adam + LR Schedule (T49–T55)
T49adamResetIteration
DETALHES
Default: 0 (= desativado) Range: 0 ou 100 – Defined in:
TÉCNICO
Feature V430: iter em que momentos Adam (m1, m2) são zerados. Correção de bias passa a rodar com (iter - adamResetIteration) em vez de iter. V430 testou reset em 5 000 (pós densification) → 12.8 % pior loss. Motivo: momento Adam acumulado na densification carrega informação sobre magnitudes típicas e acelera o refinement. Descartar custa as primeiras ~500 iters de convergência. Disabled. Fica CLI para experimentos.
T50positionLRScheduleEndIteration
DETALHES
Default: 0 (Initializer = „usa maxIterations"), 20 000 (.full — cosine termina em 20K embora maxIter=35K), 30 000 (.fullClassicPaper) Range: 0 ou 1 000 – Defined in:
TÉCNICO
Feature V431: iter em que o cosine annealing para position LR atinge mínimo. Em 0 = igual a T1. Em > 0, roda até esse valor e depois fica em T4 constante. Permite uma „extended refinement phase" com LR mínima mas constante — refina posições devagar sem decay extra. .full faz (schedule termina em 20K, treinamento até 35K); V434c/V434d confirmaram: 15K e 25K parecidos, 20K marginalmente ótimo. Em combinação com T51 permite modificar também as não-position LRs na extended phase.
T51extendedPhaseLRDecay
DETALHES
Default: 0.0 (= desativado, LRs constantes) Range: 0 ou 0.01 – 1.0 Defined in:
TÉCNICO
Feature V433: multiplicador mínimo para as LRs não-position (Scale, Rotation, Opacity, SH) na „extended phase" — depois de T50 atingido. Em 0.1, escala/rotação/opacity/SH fazem cosine decay de 1.0 (LR padrão) para 0.1× do padrão. Em 0.0 (default), constantes. V457 testou decay total (0.0 = decay até zero) vs sem decay → avg 0.0400 (2 runs) = mesmo loss que V438 sem decay. Comportamento mais limpo com decay, mas não mensuravelmente melhor. Daí disabled. CLI: –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Experimental V440: em true, calcula p98 da distribuição corrente de gradientes a cada densify step e usa como threshold dinâmico (clamped a no mínimo 0.5× do T11). Hipótese: adaptação a fase tornaria density control mais robusto. V440 testou e reverteu: drop catastrófico para 63K Gaussians (mass pruning, porque p98 nas primeiras iters é altíssimo e quase nada o ultrapassa). O threshold fixo já é bem calibrado; dinâmico estraga. Q5 (T77) traz lógica adaptive alternativa via rolling median.
T53mergeAfterDensification
DETALHES
Default: false (Initializer), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Defined in:
TÉCNICO
Feature V438: no fim da fase de densification (iter T2), pass único de merge agrupa Gaussians próximos com escala e cor parecidas. Reduz contagem em 5–15 % sem perda visual. Sentido: clones produzem clusters quase idênticos que não contribuem — merge libera capacidade do otimizador. Padrão em quality classic. Em MCMC não usado — relocação não permite que esses clusters se formem.
T54densifyPhase2FromIteration
DETALHES
Default: 0 (= desativado) Range: 0 ou T2 – T1 Defined in:
TÉCNICO
Experimental V426: segunda fase de densification que começa aqui após pausa de refinement e roda até T55. Hipótese: após refinement, magnitudes de gradiente são estáveis e podem indicar áreas que ainda precisam de Gaussians. V426 testou e reverted: two-phase densification caiu em cascade de 0 Gaussians (com V425 refinement pruning combinado, destruiu o buffer). Disabled. CLI disponível.
T55densifyPhase2UntilIteration
DETALHES
Default: 0 Range: 0 ou T54 – T1 Defined in:
TÉCNICO
Fim da two-phase densification V426. Só relevante se T54 > 0. Ambos disabled.
Pós-processamento + Apple AI (T56–T60)
T56postTrainingCompactification
DETALHES
Default: true (em todas predefinições de produção), false (.quickTest, .preview) Range: boolean Defined in:
TÉCNICO
Feature V443: após o fim do treinamento, Gaussians com sigmoid(opacity) < 0.01 são removidos (já não contribuem). Reduz contagem em ~58 % e tamanho de export em ~55 % sem perda visual. Padrão em produção — resultado entregue o mais compacto possível. Em .quickTest off, porque diagnose não exporta. Diferente de T42 midTrainingCompactificationIterations (V549), aqui é só no fim — refinement pode usar todos os Gaussians.
T57metalFXUpscaling
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature V444: ativa Apple MetalFX Spatial Upscaler no output do viewport 3D em vez de bilinear. Se a resolução de treinamento < viewport (p. ex. treino em 0.5×, viewport em plena), MetalFX entrega imagem bem mais nítida. Live no viewport, sem retraining. Mutuamente exclusivo com T58 mpsLanczosScaling — MetalFX vence. Recomendação: ligue quando o viewport parece „lavado" para o detalhe esperado.
T58mpsLanczosScaling
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature V444: MPSImageLanczosScale para upscaling do viewport em vez de bilinear. Lanczos é resampling sinc-based clássico, bem mais nítido que bilinear com overhead mínimo. Toggle live. Sobrescrito por T57 quando ambos on.
T59livePreviewInterval
DETALHES
Default: 50 (Initializer e maioria das predefinições) Range: 0 (off) ou 10 – 5 000 Defined in:
TÉCNICO
Com que frequência o viewport é atualizado durante o treinamento. 50 = a cada 50 iters um render novo — suficiente para acompanhar progresso sem retardar muito. 0 = não atualiza (treinamento em background, máximo speed). Ajustes típicos: em .quickTest baixe para 10 (ver cada passo); em runs MCMC longos suba para 500–2000 (overhead acumula).
T60perceptualLossWeight
DETALHES
Default: 0.0 (= desativado) Range: 0 ou 0.001 – 0.5 Defined in:
TÉCNICO
Feature futuro V444: peso de termo perceptual via MPSGraph (pequena rede VGG-like). Capturaria similaridade estrutural/textural em nível semântico acima de L1+SSIM — típico em pipelines de pesquisa que valorizam mais „parece real" que „pixel perfect". Implementação pendente (code stub existe; forward pass não). Default 0.0. Fica para ativação futura; CLI –percep-weight F reservado.
MCMC Densification (T61–T73)
T61densificationStrategy
DETALHES
Default: .classic (Initializer + Classic presets), .mcmc (todas predefinições MCMC + Scene Class) Range: .classic ou .mcmc Defined in:
TÉCNICO
Escolhe entre Classic Densification (clone/split/prune, Kerbl et al., 2023) e MCMC Densification (Stochastic Gradient Langevin Dynamics com relocação, Kheradmand et al., NeurIPS 2024). Em .classic, T11–T16 valem; em .mcmc, T62–T73. Cuidado ao trocar: defaults Classic e MCMC têm calibração muito diferente — quem flipa o picker no Expert View sem carregar preset adequado arrisca mass extinction tipo bug 1.4.3 (460K → 5 numa iter, porque MCMC OpacityReg 0.01 mata as opacities Classic). Por isso os defaults init de MCMC são „amaciados" (todos regs em 0.0).
T62mcmcMaxGaussians
DETALHES
Default: 150 000 (Initializer + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — variante Mip Splatting com budget 10×), 1.19M (.renderPreset), 1.25M (.outdoorPreset), 670K (.indoorPreset) Range: 0 (= „usa capacidade do buffer") ou 10 000 – 5 000 000 Defined in:
TÉCNICO
Limite hard da contagem em MCMC. Cresce gradualmente em T70 mcmcGrowthRate (típico 5 %) por passo de relocação até o cap. V473/V531 acharam 150K sweet spot — acima de 200K dilui qualidade (muitos pequenos redundantes), abaixo de 100K sub-densifica. Em cenas grandes (p. ex. 1 545-foto drone com 158K SfM init) 150K é baixo demais — daí a extensão 1.4.5 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7-BayesOpt achou ótimos por cena entre 670K (Indoor) e 1.25M (Outdoor). Em valor 0, a engine usa a capacidade plena do buffer.
T63mcmcNoiseScale
DETALHES
Default: 0.00005 (5e-5 = paper default) Range: 1e-6 – 1e-3 Defined in:
TÉCNICO
Multiplicador do ruído gaussiano adicionado à posição de cada Gaussian em cada iter MCMC (lógica SGLD). Maior significa mais exploração (Gaussians erram mais, podem achar bons lugares), menor = mais exploitation (ficam onde já estão bons). V467 e V536 confirmaram 5e-5 ótimo — 1e-5/2e-5 pouca exploração, 1e-4 demais (splats se desfazem). Cosine decayed ao longo do treinamento até T69 mcmcNoiseDecayEnd — no fim do decay, ruído ~0 e os Gaussians convergem.
T64mcmcOpacityRegWeight
DETALHES
Default: 0.0 (= desativado nos defaults RadianceKit; paper: 0.01) Range: 0 ou 0.001 – 0.05 Defined in:
TÉCNICO
Penalidade L1 MCMC-specific sobre opacidade. Paper default 0.01 (empurra Gaussians sem uso para 0, deixa disponíveis para relocação). V464b mostrou: sem reg melhor em RadianceKit (Sessão 28 confirma). Motivo: o critério de pruning em T68 mcmcDeadOpacityThreshold basta — penalidade L1 adicional força até Gaussians de baixa opacidade mas valiosos a morrer. Daí default 0. Atenção: em 1.4.3-beta o default no initializer era 0.01 por engano, o que causou mass extinction (ver T61). Desde 1.4.4 fixado em 0.0.
T65mcmcScaleRegWeight
DETALHES
Default: 0.0 (= desativado; paper: 0.01) Range: 0 ou 0.001 – 0.05 Defined in:
TÉCNICO
Penalidade L1 MCMC-specific sobre autovalores de escala. Paper default 0.01. V464b: sem reg melhor, mesmo motivo que T64. Disabled em todas predefinições MCMC do RadianceKit. Atenção como em T64: bug 1.4.3.
T66mcmcRelocationInterval
DETALHES
Default: 100 (Initializer + todas predefinições MCMC, padrão paper), 155 (P9 Outdoor — ótimo Q7-BayesOpt) Range: 50 – 500 Defined in:
TÉCNICO
Intervalo de iters em que MCMC realoca Gaussians mortos (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold). V537 testou 50 (muito disruptivo, loss oscila) e 200 (marginal pior, MCMC perde reatividade). 100 é ótimo. Q7-BayesOpt em Bicycle achou 155 como ótimo scene-specific outdoor — intervalo levemente maior dá ao Adam tempo de integrar Gaussians recém- posicionados antes do próximo reloc evento.
T67mcmcWarmupIterations
DETALHES
Default: 500 Range: 100 – 5 000 Defined in:
TÉCNICO
Iters iniciais sem relocação MCMC. Só após esse warmup começa relocação. Sentido: nas primeiras iters as opacities ainda não estabilizaram — se reloc começasse direto, Gaussians iriam para o lugar errado e teriam que ser deslocados em seguida, destruindo momento Adam. Paper default 500. V464b confirma robustez.
T68mcmcDeadOpacityThreshold
DETALHES
Default: 0.005 (Initializer, paper), 0.01 (.fullMCMC e todas predefinições MCMC — ótimo V535) Range: 0.001 – 0.05 Defined in:
TÉCNICO
Threshold de sigmoid(opacity) abaixo do qual Gaussian é considerado „morto" e elegível para relocação. V535 achou 0.01 ótimo (0.005 marginal, 0.02 pior). Maior = reloc mais agressivo; menor = cuidadoso. 0.01 ~ „0.5 % de visibilidade". P10 Indoor usa via Q7-BayesOpt 0.0142.
T69mcmcNoiseDecayEnd
DETALHES
Default: 0 (Initializer = sem decay), 160 000 (.fullMCMC = 80 % de 200K), 96 000 (.mcmcBalanced = 80 % de 120K), 40 000 (.mcmcPreview) Range: 0 ou 1 000 – Defined in:
TÉCNICO
Iter em que ruído T63 mcmcNoiseScale é totalmente amortecido a zero (cosine decay de iter 0 até aqui). V497c/V502 acharam 80 % de maxIterations ótimo — dá ao MCMC tempo de exploração e reserva os últimos 20 % para convergência sem ruído. 0 = ruído constante por todas as iters (raramente útil, MCMC não converge).
T70mcmcGrowthRate
DETALHES
Default: 0.05 (padrão paper = 5 %) Range: 0.01 – 0.2 Defined in:
TÉCNICO
Taxa de crescimento do target populacional MCMC por passo de relocação. Lógica: a cada reloc, o target sobe em (1 + growthRate) até T62 mcmcMaxGaussians (ou variante escalada via T72/T73). V512/V522 acharam 0.05 ótimo — maiores levam a crescimento rápido demais (Gaussians inseridos antes do Adam integrar), menores deixam cenas sub-densificadas no fim.
T71mcmcSigmoidK
DETALHES
Default: 100.0 Range: 10.0 – 500.0 Defined in:
TÉCNICO
Parâmetro sigmoid sharpness para a atenuação de ruído MCMC. No passo SGLD, o ruído por Gaussian é amortecido por — Gaussians muito opacos (logit positivo) recebem ruído exponencialmente menor que pouco opacos. K = 100 é nítido; transição „full noise" → „no noise" passa rápido em torno de opacity 0.5. V484–V487 acharam K = 100 ótimo — menores (10–50) deixam Gaussians muito opacos tremerem (destrói convergidos); maiores (> 500) fazem transição artificial e Gaussians mortos nem se movem.
T72mcmcCapMultiplier
DETALHES
Default: 3.0 (Initializer + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Range: 0 (= desativado) ou 1.0 – 10.0 Defined in:
TÉCNICO
Feature 1.4.5: scaling adaptive de cap por cena. Quando T73 mcmcAutoScaleByScene true, o cap efetivo é (clamped à capacidade do buffer). Contexto: em cenas grandes (drone 1 545 fotos → 158K SfM init), T62 = 150 000 é baixo — density control nem cresceria. Com multiplier 3.0, cap escala a 474K (158K × 3.0). Q7-BayesOpt achou ótimos: Outdoor com multiplier alto (5.32 → ~830K cap em bicycle 156K init), Indoor com 1.76 (paredes saturam mais cedo). Resolução completa do cap em .
T73mcmcAutoScaleByScene
DETALHES
Default: true (Initializer + todas predefinições MCMC) Range: boolean Defined in:
TÉCNICO
Feature 1.4.5: master switch da lógica scene-aware de cap (ver T72 + ). Em false, só T62 mcmcMaxGaussians vale (comportamento 1.4.4). Padrão on para evitar reincidência dos mass extinctions de 1.4.3 em cenas grandes. Desligar manualmente só se quiser cap rígido — p. ex. treinar variante 150K com tamanho final previsível.
Mip-Splatting (Q1.5) (T74–T76)
Status: Q1.5 foi declarado „closed no-win" em 2026-05-25 após 14 iterações autônomas + overnight 1.5M confidence check (máx Δ@2× = +0.27 dB; gate original exigia ≥ +1.5 dB média sobre 0.5×/2×; FAIL 0/11 pair scenes). Os campos ficam opt-in para experimentos; todas as predefinições de produção têm. Verdict:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETALHES
Default: false (todas predefinições de produção), true (.fullMCMCMip — sibling research) Range: boolean Defined in:
TÉCNICO
Ativa Mip Splatting (Yu et al., CVPR 2024): filtro de smoothing 3D + filtro 2D + compensação α que limita a frequência por Gaussian ao Nyquist da sampling rate mais densa das câmeras. Objetivo teórico: eliminar aliasing em renderings fora da resolução de treino (0.5× ou 2×). Funcionalidade verificada em Q1.5-D-Test. Mas: gate original (Δ@1× ≥ +0.3 dB E avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) não atingido em nenhuma das 11 pair scenes. Máximo observado: family 750K classic Δ@2× = +0.270 dB. Cenas externas (Truck, Flowers) ainda PIORARAM em 1× e 0.5×. Hipótese: smoothing 3D briga com relocação MCMC em high-Gs. Campo fica para futura re-eval multi-scale com methodology Mip- NeRF 360 correta (ver O3-backlog no caminho de benchmark).
T75mipSmoothing3DScale
DETALHES
Default: 0.2 (paper default) Range: 0.05 – 1.0 Defined in:
TÉCNICO
Parâmetro de escala de smoothing 3D (Yu et al. §3.3, paper default 0.2). Maior = mais suavização em world space por Gaussian (= mais anti-aliasing, mais blur na escala default); menor = mais nítido mas suscetível a aliasing. Só consultado se T74 useMipSplatting = true. Em Q1.5 não foi otimizado — o A/B gate já perdeu no paper default 0.2; mais sweeps seriam inúteis.
T76mipFilter2DVariance
DETALHES
Default: 0.3 (= exatamente o comportamento V242 legado) Range: 0.1 – 1.0 Defined in:
TÉCNICO
Variância 2D Mip somada à diagonal de Σ_2D (variância direta, não quadrada). 0.3 é o valor legado V242 hard-coded no kernel antes de Mip Splatting. Quando T74 useMipSplatting = false, o kernel ignora esse valor por completo e escreve 0.3 hard-coded — garantia Codex Round 1 S3-1 de que a baseline não regride. Quando, o valor setado é usado. Fica no catálogo para sweeps Mip.
Adaptive Densification (Q5) (T77–T79)
T77adaptiveDensification
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature Q5: rolling median tracker como alternativa ao fixo T11 densifyGradThreshold. Em true, cada densify step sobrescreve o threshold com median(últimos N avgGrad samples) × T79 adaptiveDensifyMultiplier. N = T78 adaptiveWindow. Mais conservador que o p98 do V440 (cuja armadilha de 63K pruning foi catastrófica); median + 2× fica em ~p70–p80 da distribuição em steady state. Q5 testes: sozinho FAIL 0/3 cenas; combinado com Q6 (ver T80/T81) PASS 1/3 cenas — bundle Q5+Q6 passado em 2026-05-25 como opt-in via CLI –adaptive-densify. Q6 é „carrier" do ganho; Q5 contribui mais para estabilidade.
T78adaptiveWindow
DETALHES
Default: 1 000 Range: 100 – 10 000 Defined in:
TÉCNICO
Window de rolling median em eventos de densification (NÃO iters — cada T13 densifyInterval step dá um sample). Default 1 000 — com isso, as últimas 100 000 iters contribuem, ou seja toda a história até aqui. Fase inicial (antes de T78 samples): tracker retorna nil → fallback no fixo T11. Só relevante se.
T79adaptiveDensifyMultiplier
DETALHES
Default: 2.0 Range: 1.0 – 4.0 Defined in:
TÉCNICO
Multiplicador sobre rolling median para threshold adaptive. Default 2.0 ~p70–p80 da distribuição típica. Menor = mais agressivo (mais clones); maior = mais estrito. Q5 testou em 1.5–3.0; 2.0 é melhor default. Só relevante se.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature Q6: resolução de treino começa em 0.5× e troca em T50 positionLRScheduleEndIteration / 2 (ou T1 maxIterations / 2, se T50 não setado) para T22 trainingRenderScale. Usa a infra resize/restoreImageBuffers desenvolvida em Q1.5.1. Sobrescreve T23 resolutionWarmupScale se ativo. Q6 é „carrier" do ganho no bundle Q5+Q6 (ver T77) — aumento gradual de resolução dá tempo de achar geometria grossa em resolução menor antes do detalhe fino. Via CLI: –curriculum-resolution.
T81curriculumSHProgression
DETALHES
Default: false Range: boolean Defined in:
TÉCNICO
Feature Q6: sobrescreve T21 shDegreeUpgradeIterations com [maxIter/4, maxIter/2, maxIter*3/4], distribuindo upgrades SH uniformemente em vez de front-loaded. Hipótese: geometria estável antes de explosão de detalhe de cor posiciona efeitos dependentes de view com mais precisão. Q5+Q6 juntos PASS 1/3 cenas; Q6 é carrier. CLI: –curriculum-sh.
Predefinições estáticas (TP1–TP9)
Aqui só as diferenças estruturais ao default do Initializer. A descrição completa de marketing das dez predefinições UI P1–P10 está no Capítulo 7.
TP1.preview
DETALHES
Diagnose/preview para sistemas ≥ 10 GB RAM. Overrides: - 30 000 → 5 000 - 15 000 → 3 500 (70 % de maxIter) - 1.6e-6 → 1.6e-5 (10× maior, decay menos agressivo) -,,,, cada 2× (V176) - 3 000 → 100 000 (efetivamente off, V172: reset destrói treinos curtos) - [1K, 2K, 3K] → [1K, 2K] (V182: degree 3 não converge em 2K iters) - 1.0 → 0.5
TP2.full
DETALHES
Production-quality classic. Overrides: - 30 000 → 35 000 (V550: testes 40K Truck overtraining +10.7 % Gs em -1.3 % L1) - 15 000 → 5 000 (sweet spot V310, V338 7K worse) - todas LRs 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 disabled, V421 confirmado) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 delayed) - 0.0 → 0.9995 (V546 HTGS, 14 % de melhoria) - 50 (inalterado, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, já initializer default para .full)
TP3.fullClassicPaper
DETALHES
Sibling Q1.5-A de TP2, paper-faithful Classic. Overrides vs TP2: - 35 000 → 30 000 (paper) - 5 000 → 15 000 (paper: 50 % de maxIter) - 1.6e-5 → 1.6e-6 (paper) -,, paper defaults (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (calibrado para ~1-2M Gs em Bicycle) - 200 → 100 (paper) - 0.001 → 0.005 (paper) - 100 000 → 3 000 (paper §5.2, risco — pode disparar V194 regression) - 0.9995 → 0.0 (paper sem decay) - 20 000 → 30 000 (cosine roda em 100 % de maxIter)
TP4.fullMCMC
DETALHES
Production-quality MCMC. Overrides vs Initializer: - 30 000 → 200 000 (V534, MCMC precisa de 5× mais iter que Classic) - 15 000 → 160 000 (V504b 80 % de maxIter) - 1.6e-6 → 1.6e-5 - LR schedule como TP2 (todas 2×) - 0.2 → 0.05 (V521b/V534: MCMC precisa de sinal L1 mais forte) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (já no initializer, confirmado no preset) - 5e-5 (V467/V536 ótimo) - 0.005 → 0.01 (V535 ótimo) - 0 → 160 000 (80 % de maxIter, V497c/V502) - 3.0 (já no initializer) - true (já no initializer) - 3 000 → 200 000 (efetivamente off, MCMC usa reloc em vez de reset)
TP5.fullMCMCMip
DETALHES
Sibling Q1.5-D de TP4, com Mip Splatting + budget MCMC paper. Overrides vs TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, paper magnitude) - useMipSplatting false → true (Mip on)
TP6.classicBalanced
DETALHES
Mid-tier Classic. Overrides vs TP2: - 35 000 → 20 000 (V149: 20K = 30K em 33 % menos tempo) - 20 000 → 0 (cosine roda em maxIter = 20K, sem extended phase)
TP7.mcmcPreview
DETALHES
Diagnose MCMC. Overrides vs TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: preview = scaling mais leve)
TP8.mcmcBalanced
DETALHES
Mid-tier MCMC. Overrides vs TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3.0 → 2.5 (entre Preview 2.0 e Full 3.0)
TP9.quickTest
DETALHES
Teste de funcionamento puro. Overrides vs Initializer: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (calibrado para 0.25×) - 100 → 50 - 3 000 → 100 000 (off, curto demais) - 1.0 → 0.25
Método:
Assinatura: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Defined in:
Única source-of-truth para „quantos Gaussians MCMC pode crescer ao máximo?". Calcula a partir de três entradas: o configurado T62 mcmcMaxGaussians (com mass-extinction floor 150 000 se 0), o (número de pontos SfM iniciais) e o (tamanho pré-alocado do buffer). Lógica:
+ base = T62 > 0 ? T62: 150_000 (o floor protege contra bugs de initializer default como o incidente 1.4.3) + Se T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)); senão
+ Se bufferCapacity > 0: return min(scaled, bufferCapacity) + Senão return scaled
Exemplo: Bicycle (Mip-NeRF 360, 194 frames) → SfM init ~156K pontos, T62 = 150 000, T72 = 5.32, capacidade do buffer 8M. Cap resolvido = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830K. Esse é o cap de crescimento efetivo a que a relocação MCMC se atém.
Calcula o número máximo real de splats em MCMC. Pega seu setting, olha quantos pontos sua cena tem no início, e escala com o Multiplier se o ajuste automático estiver on. Assim o cap se adapta à cena, em vez de forçar o mesmo valor para uma cena pequena e uma gigante. Você não chama o método diretamente — o treinamento usa internamente.
Qual campo para quê? (cheat sheet)
| Objetivo | Campos para girar |
|---|---|
| Mais detalhe à distância | T62 mcmcMaxGaussians alto, T72 mcmcCapMultiplier 5+ |
| Mais detalhe em geral (Classic) | T1 maxIterations alto (≤ 40K), T2 densifyUntilIteration ≤ 14 % de T1 |
| Reduzir floaters em drones | T43 frustumCullEnabled on, T20 skyMaskingEnabled on, T45 skyDomeEnabled on |
| Belo céu em cenas externas | T45 skyDomeEnabled on, T47 skyDomeRadiusMultiplier 30–60 |
| Arquivo de export menor | Estratégia .mcmc (T61), T56 postTrainingCompactification on, T62 mcmcMaxGaussians ≤ 200K |
| Treinamento mais rápido | T22 trainingRenderScale 0.5, T1 maxIterations pela metade — mas não ambos! |
| Melhores highlights | T21 shDegreeUpgradeIterations com [2K, 5K, 8K] (sem front-load), MCMC + 200K iter |
| Manter Mac responsivo | T25 throttleDelayMs 5–10 (custa ~15 % de treinamento) |
| Live preview mais frequente | T59 livePreviewInterval baixe para 10–20 |
| Transições mais suaves em sombras | T17 ssimWeight um pouco alto (0.15–0.25), mas não acima de 0.3 |
| Internos compactos | P10 Indoor (, T72 = 1.76) |
Campos perigosos
Estes campos podem, mal configurados, levar a OOM, crash, mass extinction de Gaussians ou benchmarks inúteis. Tratar com cuidado:
- T11 densifyGradThreshold — metade pode gerar 2–4× mais Gaussians e estourar memória de GPU. Também: deve combinar com T22 trainingRenderScale (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — em cenas grandes com > 200K pontos iniciais SfM e multiplier > 5, o cap resolvido sobe a milhões de Gaussians. Em Macs com 36 GB, possível OOM. Outdoor 5.32 funciona porque Mip-NeRF 360 Bicycle tem 156K init → 830K. - T39 testViewIndices — setar manualmente pode invalidar benchmark (indices > N → sem holdouts). Deixe o –benchmark setar. - T64 mcmcOpacityRegWeight e T65 mcmcScaleRegWeight — em 1.4.3-beta setados a 0.01 causaram mass extinction (460K → 5 Gaussians). Desde 1.4.4 fixados em 0.0, mas aumentar manualmente reproduz o problema. - T15 opacityResetInterval — se não em 100 000+ (efetivamente off) e treinamento < 10 000 iters, o reset destrói convergência. .preview por isso 100 000 mesmo com maxIterations = 5 000. - T54/T55 densifyPhase2* — two-phase densification caiu em cascade de 0 Gaussians em testes. Mantenha em 0. - T74 useMipSplatting — Q1.5 closed no-win 2026-05-25, pode até PIORAR PSNR em outdoor. Default off; opt-in só para pesquisa.
Se um campo nesta lista te interessa: backup do preset atual (export JSON) antes e pense em como medir o resultado de forma reproduzível — senão não saberá se melhorou ou piorou.