Kapitola 6 — Konfigurace tréninku
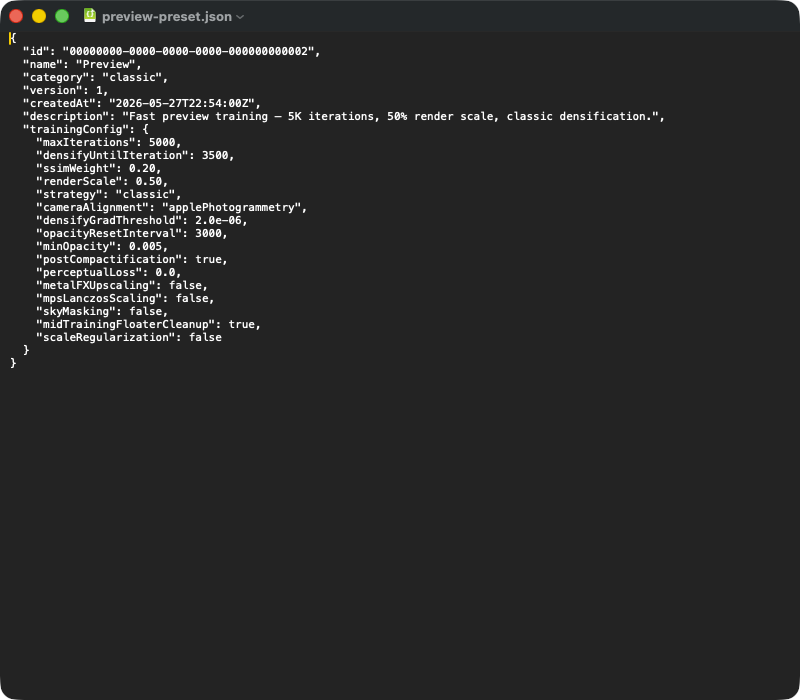
Typický JSON export předvolby. Top-level pole: id (UUID), name, kategorie (classic | mcmc | sceneClass | custom), verze schématu, timestamp, free-text. Vnořený objekt obsahuje pro reprodukovatelnost kritické parametry — při importu se celý blok deserializuje do struktury TrainingConfig a defaulty z verze aplikace doplní pole, která v JSON chybí (např. po update aplikace). Kdo předvolbu předává na jiný Mac, posílá jednoduše tento JSON soubor.
Struktura TrainingConfig je srdcem každého tréninkového běhu v RadianceKitu. Sdružuje každý parametr, který trénink ovlivňuje — od maximálního počtu iterací přes osm learning rate až po speciální pole pro MCMC, Mip-Splatting, curriculum a scene-aware cap logiku. Editujš ji v sidebaru v sekci Konfigurace tréninku (Expert View), ukládáš ji jako předvolbu nebo předáváš jako JSON export na jiný Mac. Při tréninku se přesně tento objekt zmrazí a předá GPU backendu.
Tato kapitola je referenční materiál pro power-usery a autory skriptů. Listuje všech 81 veřejných polí, 9 statických předvoleb a jednu veřejnou metodu. Zdrojový soubor je TrainingConfig.swift — v případě pochybností platí tam uložený doc comment a default initializéru jako source of truth.
Obsah:
+ Iterace (T1–T2) + Learning Rates (T3–T10) + Densifikace — Classic (T11–T16) + Loss (T17–T20) + Progrese SH stupně (T21) + Výkon (T22–T25) + Diagnostika a příprava mraku bodů (T26–T30) + Regularizace (T31–T37) + Refinement (T38–T44) + Sky-Dome (T45–T48) + Adam + LR schedule (T49–T55) + Post-processing + Apple AI (T56–T60) + MCMC densifikace (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptivní densifikace (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + Statické předvolby (TP1–TP9) + Metoda: + Které pole na co? (Cheat-sheet) + Nebezpečná pole
Iterace (T1–T2)
T1maxIterations
DETAILY
Default: 30 000 (Initializer), 35 000 (.full), 200 000 (.fullMCMC) Range: 1 000 – 500 000 (UI slider), žádná tvrdá horní hranice v logice Defined in:
TECHNICKY
Celkový počet tréninkových iterací, které backend proběhne. Iterace označuje forward render jedné tréninkové kamery, backward pass přes všechny loss komponenty (L1 + SSIM + volitelné regularizace + sky mask) a Adam optimizer step. Toto číslo působí přímo na ostatní schedule: position learning rate sleduje cosine-annealing křivku od 0 buď k T1 samému nebo k T49 positionLRScheduleEndIteration; densifikace končí u T2 densifyUntilIteration; MCMC noise decay končí u T69 mcmcNoiseDecayEnd; SH degree upgrady se dějí na třech značkách definovaných v T21. U klasické densifikace leží empiricky určený sweet spot na 20 000–35 000 iteracích (Sessions 1–32, V546 testy), u MCMC na 60 000–200 000 (V534). Drastické zvýšení nad hodnoty uložené v předvolbě zřídka přináší dodatečnou kvalitu — Adam momentum se sytí a bez LR decay konce loss stagnuje. Naopak podstřelení ~5 000 vede k neúplně zkonvergovaným geometriím (density control má příliš málo času na klonování/štěpení).
T2densifyUntilIteration
DETAILY
Default: 15 000 (Initializer), 5 000 (.full), 160 000 (.fullMCMC) Range: 0 – Defined in:
TECHNICKY
Iterace, od které densifikace přestává. Až sem se Gaussiany klonují, štěpí a prune podle pravidel parametrizovaných v T11–T16 (Classic) nebo T67–T70 (MCMC); poté zůstává počet Gaussianů konstantní a optimalizují se už jen pozice, rotace, škály, opacity a SH koeficienty (refinement fáze). V originálním 3DGS paperu leží hodnota na 50 % T1, v RadianceKit .full předvolbě jen na ~14 % (5 000 z 35 000) — důsledek V310/V338 experimentů, které ukázaly, že po 5 000 iteracích další densifikace výsledek spíše zhoršuje (více floaterů, větší paměťová náročnost, žádný kvalitativní zisk). MCMC oproti tomu nechává relokaci běžet do 80 % T1 (V504b), protože MCMC neprodukuje škodlivé floatery. Pokud je T2 zvoleno příliš malé (< 1 000), vznikne příliš málo Gaussianů; příliš velké u Classic (> 50 % T1) vede k overgrowth a RGB saturation outlierům (viz outdoor overtraining findings).
Learning Rates (T3–T10)
T3positionLearningRate
DETAILY
Default: 0.00016 Range: 1e-7 – 1e-3 (doporučeno) Defined in:
TECHNICKY
Adam learning rate pro XYZ pozici každého Gaussianu na začátku tréninku (iterace 0). Sleduje cosine annealing křivku a v průběhu tréninku klesá na T4 positionLearningRateFinal. Default 0.00016 pochází z originálního 3DGS paperu (Kerbl et al. 2023) a v RadianceKitu se neškáluje ani při zvýšení rozlišení obrazu — pozice se pohybuje ve světovém souřadnicovém systému, ne v pixel prostoru. Výrazné zvýšení (> 0.0005) způsobí, že Gaussiany skáčou na dlouhé vzdálenosti a loss se stane nestabilním; hodnoty výrazně nižší (< 0.00005) vedou k tomu, že špatně inicializované mraky bodů nikdy nenajdou své místo. V414 testoval zdvojnásobení init hodnoty → 16.8 % horší L1 loss; V544a tuningy potvrdily paper default jako optimální. Pozor: u .fullMCMC ponecháváme tuto hodnotu záměrně na defaultu — MCMC potřebuje konstantní learning rates pro svou relokační logiku, takže ladění tady nepřináší nic.
T4positionLearningRateFinal
DETAILY
Default: 0.0000016 (Initializer + paper), 0.000016 (.full, .fullMCMC — 10× vyšší) Range: 0 – Defined in:
TECHNICKY
Koncová hodnota position LR cosine annealing křivky. Je dosažena buď u T1 maxIterations, nebo, pokud je nastaveno, u T49 positionLRScheduleEndIteration. RadianceKit .full předvolba používá 0.000016 — tedy 10× vyšší než paper default 0.0000016. V420 experimenty ukázaly, že 0.5× final hodnoty (0.000008) zhoršuje loss o 6.4 %; V414 ukázal, že 2× init hodnota ho zhoršuje o 16.8 %. Vysoká final hodnota není trade-off, ale záměrná volba: u příliš silného decay ztrácejí Gaussiany během refinement fáze schopnost se přizpůsobit nově přidaným densifikačním kandidátům. Přes rozšíření V431/V433 lze schedule fázi zkrátit (T49 < T1), takže T4 je dosaženo už před koncem tréninku a zbytek tréninku běží s konstantní mini-LR — typická konfigurace: T49 = 20 000, T1 = 35 000, refinement tedy na 0.000016 po 15 000 iterací.
T5shDCLearningRate
DETAILY
Default: 0.0025 (Initializer + paper), 0.005 (.full a všechny MCMC předvolby — 2×) Range: 0.0001 – 0.05 Defined in:
TECHNICKY
Adam learning rate pro DC podíl (degree 0, tedy konstantní albedo) spherical harmonic barvy. SH-DC odpovídá směrově nezávislému základnímu tónu Gaussianu, jaksi „základní barva". V176 a V188 experimenty našly 2× vyšší než paper default optimální — rychlejší konvergenci barev, právě proto, že u krátkého tréninku (< 5 000 iterací) SH-DC jinak nedojde do formy. Na rozdíl od geometrických LR nemá SH-DC žádný decay; learning rate zůstává přes všechny iterace konstantní (nebo sleduje pouze volitelný extended-phase decay z T51). V416 testoval zčtyřnásobení na 0.01 → 6.4 % horší loss u beta2=0.99-Adam.
T6shRestLearningRate
DETAILY
Default: 0.000125 (Initializer + paper), 0.00025 (.full a MCMC — 2×) Range: 0.000001 – 0.005 Defined in:
TECHNICKY
Adam learning rate pro SH koeficienty vyššího řádu (Degree 1, 2, 3 — tedy view direction závislé barevné podíly, které zajišťují lesklá místa, odrazy a jemné stínování). 20× menší než T5 per paper konvenci, protože tyto koeficienty rostou kvadraticky v počtu (3 pro degree 1, 5 pro degree 2, 7 pro degree 3 → celkem 15 floatů na Gaussian) a bez menší learning rate by obraz přesyceně. Aktivuje se ve dvou krocích — až do první značky v T21 shDegreeUpgradeIterations je aktivní pouze degree 0 (tedy jen T5), poté 1, později 2, nakonec 3. Nízké hodnoty zde jsou obzvláště důležité na scénách s mnoha difuzním osvětlením; u velmi lesklých povrchů (laku aut, voda) se ladění nevyplatí — SH reprezentace sama je omezená.
T7opacityLearningRate
DETAILY
Default: 0.05 (Initializer + paper), 0.1 (.full, MCMC — 2×) Range: 0.001 – 1.0 Defined in:
TECHNICKY
Adam learning rate pro logit opacity každého Gaussianu. Aplikace ukládá opacity jako neomezenou float hodnotu a transformuje ji sigmoidem do [0, 1]; LR působí v logit space. Paper default 0.05 je po V50 testech (best single run L1 0.1664) obnoven, V71 revertoval V67 0.025. V188 zdvojnásobení na 0.1 dělá pruning efektivnější — mrtvé Gaussiany rychleji klesnou pod T14 pruneOpacityThreshold. V418 ukázal: 0.05 s beta2=0.99 Adam je o 7.1 % horší než 0.1 — interakce s Adam konfigurací není triviální. Nízké hodnoty (< 0.01) vedou k tomu, že „dead" Gaussiany leží věčně dokola a žerou paměť; příliš vysoké hodnoty (> 0.5) mohou vést k opacity explosion, proto je logit hodnota v optimizeru clampována na [-15, 3] (viz poznámku „Opacity Explosion Prevention" v CLAUDE.md).
T8opacityLearningRateFinal
DETAILY
Default: 0.0 (= „žádný decay") Range: 0 nebo 0.001 – Defined in:
TECHNICKY
Volitelná cosine decay end hodnota pro opacity LR (V427). Pokud 0.0, decay deaktivován a opacity LR zůstává přes celý trénink konstantní na T7. V427 testoval decay 0.1 → 0.01 — výsledek 11.5 % horší loss; revertováno, proto default „vypnuto". Hypotéza za polem: v refinement fázi by konstantní opacity LR mohla vést k oscilaci, takže splaty, které už dosáhly správné míry transparence, se náhodnými gradient fluktuacemi opět posouvají. Empiricky se to nepotvrzuje — logit clamping logika to stejně zachytí. Pole zůstává dostupné pro budoucí experimenty; i velmi dlouhé MCMC běhy (> 500K iterací) by z toho mohly profitovat.
T9scaleLearningRate
DETAILY
Default: 0.005 (Initializer + paper), 0.01 (.full, MCMC — 2×) Range: 0.0001 – 0.1 Defined in:
TECHNICKY
Adam learning rate pro tři škálové komponenty každého Gaussianu v log space (RadianceKit ukládá log(scale), aby škály zůstaly kladné). Paper default 0.005, v RadianceKitu zdvojnásobeno na 0.01 pro lepší škálovou konvergenci u optimalizovaných LR konfigurací. V423 experiment: 0.005 s beta2=0.99 Adam → 18.7 % horší loss a viditelně příliš málo Gaussianů (density control nemohl klonovat, protože škálové updaty byly příliš lenivé). Škála řídí rozšíření každého Gaussianu — příliš rychlé učení vede k „needle" Gaussianům (extrémně dlouhé tenké splaty, viz T34 scaleRatioPruneThreshold), příliš pomalé učení nechává splaty zůstat příliš kompaktními a density control musí příliš často štěpit.
T10rotationLearningRate
DETAILY
Default: 0.001 (Initializer + paper), 0.002 (.full, MCMC — 2×) Range: 0.0001 – 0.05 Defined in:
TECHNICKY
Adam learning rate pro čtyři kvaternionové komponenty každého Gaussianu. Kvaternion se v každém optimizer kroku po Adam update opět normalizuje (L2 norm = 1) — jinak by kovarianční matice degenerovala. RadianceKit zdvojnásobuje paper default v Quality předvolbách, protože rotation má vůči škále / pozici menší absolutní gradient magnitudy (na jednotkové sféře zůstává každý krok krátký) a bez 2× by rotation v 35 000 iterací byla výrazně pod-konvergovaná. V188 dokumentuje. Na NeRF-Blender scénách (Lego, Chair) se rotation projevuje obzvláště — hrany objektů se vyrovnají správně až po 5 000–10 000 iteracích.
Densifikace — Classic (T11–T16)
T11densifyGradThreshold
DETAILY
Default: 0.000002 (Initializer, kalibrováno pro 0.5× rozlišení), 0.0000011 (.full, kalibrováno pro 1.0×), 0.000004 (.quickTest, kalibrováno pro 0.25×), 2e-7 (.fullClassicPaper) Range: 1e-8 – 1e-3 (závislé na rozlišení) Defined in:
TECHNICKY
Threshold pro L2 normu screen-space projektovaného gradientu dMean2D, nad kterým je Gaussian označen pro klonování nebo štěpení. Absolutní hodnota závisí přímo na tréninkovém rozlišení — dMean2D škáluje zhruba jako 1/rozlišení² (více pixelů = menší per-pixel gradienty). Proto každý T22 trainingRenderScale stupeň potřebuje kalibrovaný threshold: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). Paper default 0.0002 je NDC normalizován a v RadianceKit world space pipeline není přímo srovnatelný. S ve V440 přidaným T52 adaptiveDensifyThreshold flagem lze hodnotu v běhu spočítat z p98 aktuální gradient distribuce — ale V440 to testoval na reálných scénách a produkoval 63 K Gaussianů (katastrofální pruning ztráta); flag zůstává vypnut. Q5 (T77–T79) dodává alternativní adaptivní logiku přes rolling median. Bezpečné toto pole není — halvení produkuje 2–4× více Gaussianů (paměťový tlak, OOM riziko); zdvojnásobení může scénu pod-densifikovat.
T12densifyFromIteration
DETAILY
Default: 500 Range: 100 – 5 000 Defined in:
TECHNICKY
První iterace, od které je densifikace aktivní. Předtím se děje pouze „nahá" učení na počátečním SfM mraku bodů, aniž by vznikaly nové Gaussiany. Default 500 pochází z 3DGS paperu a dává inicializaci čas, aby se stabilizovala — pokud se densifikuje už od iterace 0, špatně umístěné SfM body se klonují mnohonásobně, ještě než najdou své správné místo. V349 testoval 1000 → mírně horší loss; default je optimální.
T13densifyInterval
DETAILY
Default: 100 (Initializer, MCMC), 200 (.full) Range: 50 – 1 000 Defined in:
TECHNICKY
Kolik iterací leží mezi dvěma densifikačními kroky. V paper defaultu 100 — každých 100 iterací se vyhodnocuje seznam densify kandidátů, klonuje/štěpí se a současně se odstraňuje seznam prune kandidátů (sigmoid(opacity) < T14 pruneOpacityThreshold). V112 testy našly 200 jako optimální pro .full — odlehčí GPU, protože méně reorganizačních passů běží, a dává každému Gaussianu více času, aby se po klonovací akci usadil. V417 testoval 100 s beta2=0.99 → 5.8 % horší (957 K Gaussianů, over-densifikace). U MCMC se totéž pole interpretuje jako relocation interval; viz T67 mcmcRelocationInterval pro MCMC specifickou logiku.
T14pruneOpacityThreshold
DETAILY
Default: 0.005 (Initializer, paper, MCMC), 0.001 (.full) Range: 0.0001 – 0.1 Defined in:
TECHNICKY
Sigmoid opacity threshold, pod kterým je Gaussian při dalším densifikačním kroku smazán. Působí dohromady s T7 opacityLearningRate a logit clamp logikou v optimizeru. V393 snížil default z 0.005 na 0.001 v .full — důsledek: splaty, které hrají roli jen pod exotickými úhly pohledu, zůstávají déle zachovány a přispívají k SH detailu. V394 testoval 0.0001 → mírně horší (málo pruning, plýtvání paměti). Důležité: density control musí VŽDY prune, i když je kapacita bufferu jinými opatřeními už plná (viz „Density Control Must Always Prune" v CLAUDE.md) — jinak se hromadí mrtvé Gaussiany a count zamrzne.
T15opacityResetInterval
DETAILY
Default: 3 000 (Initializer + paper), 100 000 (.full = efektivně deaktivováno), 200 000 (.fullMCMC = deaktivováno) Range: 1 000 – 100 000+ Defined in:
TECHNICKY
Po kolika iteracích se opacity všech Gaussianů resetuje na nízkou hodnotu (~0.01) — opatření z 3DGS paperu pro opětovné posouzení „zmrazených" splatů. V194 ukázal, že s RadianceKit warmup + stochastic training setup + 2× learning rates opacity reset stojí 5.5 % kvality a logit clamp už funkci resetu pokrývá. Proto v .full prakticky deaktivováno (100 000 > 35 000 takže nikdy nespuštěno). V421 testoval reset každých 3 000 s beta2=0.99 → 4.9 % horší; revertováno. U .fullClassicPaper (Q1.5-A, paper-věrný test) je záměrně opět nastaveno na 3 000 — to byla jedna z pák, kterými mělo být dosaženo paper-magnitude Gaussian budgetů.
T16maxScreenSize
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 (off) nebo > 0 Defined in:
TECHNICKY
Maximální screen space velikost (v projektovaných pixelech), kterou Gaussian smí dosáhnout, než bude násilně rozštěpen. Hodnota je nastavena na 0 (V48 testoval a revertoval) — RadianceKit density control místo toho používá world space scale threshold z dMean2D logiky. Zůstává v katalogu polí, protože budoucí experimenty s Mip-Splatting (T74–T76) nebo scéně-specifickými splatting strategiemi z toho mohly profitovat. Aktivace (hodnota > 0, např. 20) by donutila velmi velké splaty na obrazovce rozdělit se — relevantní u velkých hladkých stěn, kde jeden obří splat nabízí málo detailu.
Loss (T17–T20)
T17ssimWeight
DETAILY
Default: 0.2 (Initializer + paper + .full), 0.05 (všechny MCMC předvolby) Range: 0.0 – 1.0 Defined in:
TECHNICKY
Váha D-SSIM podílu v kombinované loss funkci loss = (1 - λ) * L1 + λ * D-SSIM, kde λ = T17. 3DGS paper default 0.2 je pro classic densifikaci optimální — V383 testoval 0.3 → 28.9 % horší, V373b potvrdil 0.2 jako sweet spot. Pro MCMC bylo ve V521b/V534 nezávisle zjištěno: 0.05 je optimální, protože MCMC přes svou stochastickou exploraci potřebuje silnější L1 signál — vyšší SSIM váhy by relokační rozhodnutí rozředily. SSIM je výrazně dražší spočítat než L1 (lokální 11×11 okna přes celý obraz); RadianceKit používá MPS-akcelerovanou implementaci, která zůstává pod 1 ms na 1080p obraz. Q7 BayesOpt sweepy našly scéně-specifická optima mezi 0.05 (.outdoorPreset: 0.082) a 0.171 (.indoorPreset).
T18ssimWeightRefinement
DETAILY
Default: 0.0 (= „žádné přepnutí, ponechej ssimWeight") Range: 0 nebo 0 – 1.0 Defined in:
TECHNICKY
Volitelná SSIM hodnota pro refinement fázi po T2 densifyUntilIteration. V428 testoval 0.2 → 0.3 v refinementu → 16 % horší loss (jak L1, tak SSIM se zhoršily); revertováno, proto default 0.0. Hypotéza za polem byla, že po densifikaci — když už nevznikají nové Gaussiany — by silnější SSIM podíl maximalizoval strukturální ostrost. Empiricky špatně: zvýšit SSIM váhu znamená nepřímo snížit L1 váhu, a L1 je výrazně výmluvnější signál ve finální refinement fázi. Pole zůstává dostupné pro budoucí experimenty s perceptual loss (T60) nebo edge loss (T19), kde by refinement-specifická loss kompozice mohla mít smysl.
T19edgeLossWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.001 – 1.0 Defined in:
TECHNICKY
V437 experimentální loss: váha Sobel gradient domain L1 loss, který porovnává hrany obrazu přímo (ground truth Sobel vs render Sobel) navíc k L1+SSIM. Hypotéza: edge informace je perceptuální základ kvality obrazu a explicitní term by měl Gaussiany povzbuzovat zasáhnout hrany lépe. Výsledky testů: váha 0.1 → 11 % horší loss, 0.01 → quality-neutrální ale 10 % pomalejší. Sobel pass stojí další MPS forward na ground truth a render. Proto trvale deaktivováno. Budoucí use case: scény s tvrdými umělými hranami (architektura, nábytek, renderingy) by mohly profitovat — Q7 Scene-Class předvolby to ale nevybraly, místo toho škálovaly SSIM váhu.
T20skyMaskingEnabled
DETAILY
Default: false (Initializer a všechny předvolby) Range: boolean Defined in:
TECHNICKY
Zapíná Sky Masking. Při tom se v každém obrazu přes Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest) sky oblast vymaskovává a loss v této oblasti se nastavuje na nulu. Smysl: outdoor scény často trpí tím, že modré/šedé/bílé sky pixely přivedou aplikaci k tomu, aby umístila Gaussiany přesně tam — co je vnímáno jako „floater". Bez sky mask by loss v této oblasti nikdy nebyl nulový, protože obloha v obrazu lehce variuje a aplikace se věčně snaží to splaty napodobit. Vision maska se počítá jednou na kameru před tréninkem a drží v RAM. Typicky se aktivuje společně s T45 skyDomeEnabled (UI logika ve Settings View). U interiérových scén nebo syntetických renderingů nech deaktivováno — maska by tam chybně rozpoznala stropy nebo stěny jako „sky".
Progrese SH stupně (T21)
T21shDegreeUpgradeIterations
DETAILY
Default: [1_000, 2_000, 3_000] (Initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — degree 3 přeskočen) Range: [Int], každá hodnota v [0, maxIterations], monotónně rostoucí Defined in:
TECHNICKY
Iterace, na kterých se aktivní SH degree přepíná 0→1, 1→2, 2→3. Před první značkou jsou aktivní pouze DC komponenty (tedy T5 shDCLearningRate), po první značce DC + 3 degree-1 koeficienty, po druhé značce + 5 degree-2 koeficientů, po třetí značce všech 15 koeficientů. Paměťová náročnost na Gaussian roste stupňovitě — 4 floaty → 16 floatů → 36 floatů → 64 floatů. Quality předvolby zpožďují upgrade vůči initializer defaultům (V228), protože geometrie má nejprve stabilizovat, než přijdou barevné detaily s vyšší frekvencí. V384 testoval [1K, 2K, 3K] pro .full → 9.3 % horší — potvrzuje delay. .preview kape u degree 2, protože degree 3 v 5 000 iteracích nekonverguje a jen plýtvá optimizer kapacitou. Q6 (T80–T81) nabízí alternativní curriculum logiku, která tento seznam dynamicky přepíše.
Výkon (T22–T25)
T22trainingRenderScale
DETAILY
Default: 1.0 (Initializer, .full, MCMC, Scene-Class), 0.5 (.preview), 0.25 (.quickTest) Range: 0.05 – 2.0 (typicky 0.25, 0.5, 1.0) Defined in:
TECHNICKY
Render rozlišení při tréninku relativně k původnímu rozlišení tréninkových obrázků. Při 0.5 se každý obraz přepočítává na 50 % šířky × 50 % výšky (tedy 25 % pixelů) a Gaussian rendering se děje v tomto menším rozlišení. Redukuje jak paměťovou, tak výpočetní náročnost kvadraticky. Důležité: T11 densifyGradThreshold musí odpovídat zvolenému rozlišení — gradient magnitudy škálují s 1/rozlišení², proto má .quickTest (0.25×) mnohem vyšší threshold (4e-6) než .full (1.0×, 1.1e-6). RadianceKit varuje u velmi velkých obrazů a automaticky upravuje — cíl 3 MP. Při extrémních 4K vstupních obrazech by 0.5 nebo dokonce 0.25 dávalo smysl, jinak běží každý Mac jen v CPU compaction.
T23resolutionWarmupScale
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.1 – Defined in:
TECHNICKY
V133 optimalizace: trénuj densifikační fázi (iter 0 do T2) v nižším rozlišení než refinement fázi. V308 ji pro .full opět vypnul, protože při T22 = 1.0 a cosine annealing byl časový zisk marginální a kvalita minimálně trpěla. Zůstává v katalogu polí, protože u 4K vstupů a dlouhých tréninkových běhů by mohla opět dávat smysl — Q6 curriculum (T80) přebralo podobnou logiku, ale je tam spárováno s LR schedule. Pokud aktivováno a T80 curriculumResolutionRamp také true, vyhrává Q6 a tuto hodnotu přepisuje.
T24tileSize
DETAILY
Default: 16 Range: 8, 16, 32 Defined in:
TECHNICKY
Velikost rasterizačních tile v pixelech. Gaussian Splatting rendering je tile-based: obraz se dělí do 16×16 pixel dlaždic, každá dlaždice sbírá pro sebe relevantní Gaussiany, řadí je podle hloubky a vkládá. 16 je standard použitý prakticky všemi 3DGS implementacemi a v RadianceKit Metal kernelech napevno zakódováno; změna této hodnoty by vyžadovala re-kompilaci shaderů a v aktuálním stavu není efektivní. Zůstává jako pole, pokud budoucí engine verze podporuje tile size dynamicky.
T25throttleDelayMs
DETAILY
Default: 0 (Initializer, .full, MCMC, Scene-Class), 0 (.preview) Range: 0 – 100 Defined in:
TECHNICKY
Umělé zpoždění mezi tréninkovými iteracemi v milisekundách. 0 = plná rychlost (standard). Vyšší hodnoty činí Mac během tréninku „použitelnějším", protože GPU/CPU pravidelně dostávají oddychové pauzy — pohodlí používání ostatních aplikací roste, ale tréninkový čas lineárně se zpožděním. Typické hodnoty: 1–2 ms („lehké" throttling, +5 % tréninkového času, Mac se cítí responzivnější), 5 ms („středně těžký", +15 % tréninkového času), 10+ ms („Eco", potenciálně dvojnásobný tréninkový čas). V Inspektoru se nabízí pod „Performance", ale není ve standardním zobrazení — viz backlog dev_ux-backlog.md, který navrhuje ho z Expert View odstranit, protože špatně pochopen drasticky prodlužuje tréninkový čas.
Diagnostika a příprava mraku bodů (T26–T30)
T26depthDistortionWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.0001 – 0.05 Defined in:
TECHNICKY
V366 experimentální: váha depth distortion regularizačního lossu. Trestá Gaussiany, které jsou podél render paprsku sice hloubkově odstupňované, ale konceptuálně patří k téže ploše — podporuje koncentrované hloubkové distribuce a redukuje floatery. Testy: 0.01 → 4.5 % horší, 0.001 → 8.1 % horší. Teoretická výhoda — vylepšit multi-view konzistenci — se nepromítá do L1 lossu, protože hypotéza implicitně předpokládá, že SfM geometrie je správná a Gaussiany se musejí jen „naskládat". V praxi je SfM mrak bodů obvykle nejslabší komponentou, ne skládání. Zůstává dostupné pro multi-view datasety s obzvláště čistými pozicemi (Synthetic, Mip-NeRF 360 s ground truth).
T27singleViewOverfit
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
Diagnostický flag: pokud true, v každé tréninkové iteraci se musí použít kamera index 0 místo náhodné z camera poolu. Smysl: pokud model nemůže overfittovat ani jediný view (tedy loss na view 0 ani po 10 000 iteracích nepoklesne k nule), je v forward/backward passu fundamentální bug. Tento přepínač byl během vývoje Metal shaderů a differentiable rasterizer kernelů intenzivně používán — V42–V47 fáze. Dnes dostupný už jen jako sanity check, pokud někdo modifikoval backend kód a chce udělat regression test. Přes CLI s –single-view.
T28maxCameras
DETAILY
Default: 0 (= „použít všechny kamery") Range: 0 nebo 1 – N Defined in:
TECHNICKY
Diagnostický limit z V43: trénuj jen s prvními N kamerami, ignoruj všechny další. Smysl původně: testovat hypotézu, že příliš mnoho kamer generuje gradient konflikty (příliš mnoho protichůdných loss signálů pro tentýž Gaussian). Výsledek testu: žádná systematická výhoda u umělého omezení — více framů přináší prakticky vždy více kvality. Zůstává jako CLI flag (–max-cameras N) pro cílené experimenty, např. „funguje trénink na prvních 100 obrázcích 1 500 obrázkového dronového letu?" V UI neexponováno.
T29maxInitialPoints
DETAILY
Default: 0 (= „použít všechny SfM body") Range: 0 nebo 1 000 – 200 000+ Defined in:
TECHNICKY
V54 pojistka: limituje počet počátečních SfM bodů, se kterými trénink startuje. Husté COLMAP rekonstrukce mohou produkovat > 60 000 bodů, což u velkých init škál vede ke 200–300 Gaussianům na pixel-overlap — to dělá „mlhové pole", ve kterém trénink nekonverguje. Subsampling na ~16 000 bodů (hard-cap logika v tréninkovém enginu) přivádí počáteční hustotu na úroveň, kterou používá referenční 3DGS, a dramaticky redukuje overlap. U velmi hustých SfM se nastavuje automaticky; přes CLI s –max-points N.
T30cameraClusterOutlierMultiplier
DETAILY
Default: 10.0 (všechny předvolby — nikdy přepisováno) Range: 1.0 – 100.0 Defined in:
TECHNICKY
Multiplikátor pro camera cluster outlier filtr, zavedený v Phase 3.10 A.1. Před tréninkem tréninkový engine počítá centroid všech pozic kamer a maximální vzdálenost kamery od centroidu. SfM body, jejichž vzdálenost od centroidu překračuje multiplier × maxCameraDistance, se zahazují jako outliery. Default 10× zachovává chování před fází 3.10. Subtilní bug: tighter SfM (kamery těsněji u sebe) → menší → menší threshold → více bodů se zahazuje jako outlier. Looser SfM → větší threshold → méně bodů se zahazuje. To je jedna z příčin Phase 3.9 funnel-vs-training anti-korelace: lepší SfM může downstream vést k horšímu tréninku, protože je zabito příliš mnoho počátečních bodů. Pole leží jako CLI override (–camera-cluster-outlier-multiplier) pro A.3 sweepy; v UI neexponováno. Hodnoty pod 5 jsou zpravidla příliš restriktivní, nad 20 bezúčinné.
Regularizace (T31–T37)
T31coarseToFineBlurRadius
DETAILY
Default: 0 (= deaktivováno) Range: 0 nebo 1 – 10 Defined in:
TECHNICKY
V369 experimentální: box blur radius, který se na začátku densifikační fáze aplikuje na ground truth obraz a lineárně do konce densifikace (T2) snižuje na 0. Hypotéza: coarse-to-fine trénink — nejprve hrubé struktury, pak detaily — by měl dodávat stabilnější geometrii. Testy: r=3 → 9.6 % horší, r=1 → 5.1 % horší. Důvod selhání: densifikace rozhoduje na základě image domain gradientů, a blurování redukuje právě signály, které jsou důležité pro „zde se musí klonovat". Zůstává v katalogu polí pro budoucí testy s jiným density control schématem.
T32scaleRegWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.0001 – 0.05 Defined in:
TECHNICKY
V370 experimentální: L1 regularizace na world space škálu. Trestá Gaussiany, kteří se stávají příliš velkými — zabraňuje „mega splatům", které pokrývají celé stěny jediným Gaussianem. Testy: 0.01 → 200 % horší loss (2 M Gaussianů, totální exploze), 0.001 → 214 % horší. Důvod: scale regularizace přichází do konfliktu s density control — menší škály znamenají, že je potřeba více Gaussianů, takže density control štěpí častěji, což opět znamená více gradient práce. Disabled, ale dokumentováno pro Mip-Splatting experimenty (T74): v tomto kontextu by mohla mít smysl spodní hranice škály.
T33anisotropyRegWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.0001 – 0.05 Defined in:
TECHNICKY
V445 experimentální: penalty na poměr max(scale)/min(scale), má zabránit extrémně dlouhým „needle" Gaussianům, které jsou vnímány jako floatery. Testy: 0.01 → 69 % horší, 0.001 → 15 % horší. Důvod: regularizace nutí splaty směrem ke „kulaté" formě, což je na ploché ploše (stěna, stůl, podlaha) přesně špatně — tam je plochý široký Gaussian efektivnější než kulový. Disabled. V549f nabídl s T34 scaleRatioPruneThreshold alternativní cílenější přístup, který byl rovněž revertován.
T34scaleRatioPruneThreshold
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 5.0 – 100.0 (typicky 10.0 – 30.0) Defined in:
TECHNICKY
Experimentální post-training pruning, který maže každý Gaussian, jehož poměr max(scale)/min(scale) překračuje zde nastavený lineární threshold. Cílí na extrémně dlouhé „needle/disc" floatery, které nelze eliminovat samotnou regularizací. V testu pruning odstraňoval floatery jak doufáno, ale současně i smysluplné ploché splaty na stěnách a podlahách — obraz se stal děravějším. Proto defaultně vypnuto, CLI flag (–scale-ratio-prune N) zůstává pro cílené experimenty. Doporučené hodnoty pokud někdo přesto chce testovat: 30 (velmi konzervativní, odstraní pouze extrémní outliery), 10 (agresivní, stojí detail).
T35opacityRegWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.0001 – 0.05 Defined in:
TECHNICKY
V446 experimentální: binary cross entropy penalty, který opacity táhne k 0 nebo 1 (tedy pryč od „polotransparentní"). Hypotéza: ostřejší opacity distribuce by zlepšila čistotu obrazu. Test s T33 kombinován → regularizace stojí kvalitu, obě deaktivována. Disabled. Pozor: v 1.4.3-Beta se vynořil bug, který přesně toto pole měl v default value změně (Initializer = 0.01), což vedlo k mass extinction Gaussian countu (460 K → 5 v jedné iteraci). Od 1.4.4 pevně zakotveno na 0.0 jako default.
T36opacityDecayFactor
DETAILY
Default: 0.0 (Initializer = deaktivováno), 0.9995 (.full, .classicBalanced — HTGS standard) Range: 0 (off) nebo 0.95 – 1.0 Defined in:
TECHNICKY
V546 implementace HTGS schématu (Hierarchical Time Gating, Eurographics 2025): každé T37 opacityDecayInterval iterací se sigmoid opacity každého Gaussianu násobí tímto faktorem. 0.9995 × 100 aplikací dává ~95 % zůstatek na densifikační fázi — lehký, ale stálý sestupný tlak na všechny opacities, který slaběji přispívající Gaussiany spolehlivě nechává klesnout proti T14 pruneOpacityThreshold. Výsledek: 14 % lepší L1 loss na Horse Full (3-trial avg V546) oproti V438 bez decay. Aktivní pouze během densifikační fáze (do T2), poté trénink běží bez decay dál, aby opacities etablované v refinementu zůstaly stabilní. U MCMC se nepoužívá (MCMC má vlastní mechanismy přes T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETAILY
Default: 50 Range: 10 – 500 Defined in:
TECHNICKY
Iterační interval, ve kterém se T36 opacityDecayFactor aplikuje. HTGS paper default 50, v .full ponecháno. Dlouhé intervaly (>200) ruší efekt částečně, protože mezi dvěma aplikacemi se děje dost gradient updatů, takže opacity opět stoupá. Kratší intervaly (<20) činí decay příliš agresivním. Aktivní pouze v densifikační fázi.
Refinement (T38–T44)
T38gradientAccumulationSteps
DETAILY
Default: 1 (= „jeden view na Adam krok") Range: 1 – 8 Defined in:
TECHNICKY
V424 feature: počet views, jejichž gradienty se akumulují, než se provede Adam update. Při > 1 aplikace běží na samostatné „unfused" backward project cestě, která sčítá gradienty v samostatném bufferu; finální aplikace škáluje s 1/N, aby magnituda zůstala konstantní. V424 testoval 2-view → quality neutrální, ale 10 % pomalejší (protože unfused cesta je dražší než fused). Revertováno pro .full, ale pro MCMC záměrně použito — .fullMCMC běží se zapnutým, ale V544a testy ukázaly, že s ním quality gap k Classic klesá na 5 % (místo 11 %). V default initializéru 1, v aktuální předvolbě 1, zůstává CLI flag (–accum-steps N).
T39testViewIndices
DETAILY
Default: [] (= prázdné, všechny views se používají pro trénink) Range: Set<Int>, libovolná podmnožina camera indexů Defined in:
TECHNICKY
V546 feature: set camera indexů, které se NEPOUŽÍVAJÍ pro trénink, ale šetří se jako holdout pro PSNR/SSIM/LPIPS vyhodnocení. Automaticky se nastavuje, když je aktivní –benchmark CLI flag: pak každý osmý view, počínaje indexem 0 (LLFF standard, identický s Mip-NeRF-360 a 3DGS paper konvencemi). Bez benchmarku prázdné — trénink používá všechny views. Pozor: manuální nastavení tohoto pole bez porozumění indexům může učinit benchmark nepoužitelným (např. pokud jsou všechny indexy nastaveny na hodnoty nad N, zatímco existuje pouze N-50 views → žádné holdouts → žádné vyhodnocení). U vlastního exportu předvolby se testViewIndices nepersistuje, protože je scéně-závislé a jinak by mezi různými datasety nechalo nesmyslné hodnoty.
T40refinementPruneInterval
DETAILY
Default: 0 (= deaktivováno) Range: 0 nebo 100 – 5 000 Defined in:
TECHNICKY
V425 feature: každých N iterací během refinement fáze (po T2) se spustí další prune pass, který odstraňuje Gaussiany s sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Smysl: během densifikace se konají pravidelné density control calls, poté už ne — Gaussiany, jejichž opacity dál klesá, ale zůstávají v bufferu. V425 testoval a revertoval: dodatečné pruning korelovalo s V426 (Two-Phase Densification, rovněž zhroucením do 0 Gaussianů). Disabled. CLI flag dostupný pro experimenty; pokud aktivováno, 1 000 nebo 2 000 jsou smysluplné hodnoty.
T41refinementPruneOpacityThreshold
DETAILY
Default: 0.0 (= „použij T14") Range: 0 nebo 0.001 – 0.1 Defined in:
TECHNICKY
V425b: samostatný opacity threshold pro refinement pruning. Po densifikaci dosáhla většina Gaussianů výrazně vyšší opacity (> 0.001), takže standardní T14 pruneOpacityThreshold by byl příliš shovívavý. Pokud je T40 aktivní, toto pole určuje vlastní threshold. Při 0.0 se dál používá T14. Relevantní pouze když T40 > 0.
T42midTrainingCompactificationIterations
DETAILY
Default: [] (= deaktivováno) Range: [Int], hodnoty v (densifyUntilIteration, maxIterations) Defined in:
TECHNICKY
V549 feature: explicitní iterační body během refinement fáze, na kterých běží compactification pass (odstraňuje sigmoid(opacity) < 0.01 + outlier-scale Gaussiany, stejná logika jako T56 postTrainingCompactification). Smysl: dlouhé refinement fáze mohou ukazovat konfeti/floater akumulaci, jejíž SH pak overfittuje na view-specifické artefakty. Typická konfigurace pokud aktivováno: [10000, 20000, 30000] pro 40K Classic. ALE: V549 A/B testy na Family datasetu ukázaly ve všech konfiguracích horší L1: [10K,20K,30K]@0.01 → −48 % count ale +36 % L1; [20K,30K]@0.005 → −44 % count ale +45 % L1; [20K,30K]@0.001 → −17 % count ale +87 % L1. Proto disabled. CLI flag –mid-compact "10000,20000" dostupný, pokud někdo preferuje vizuální floater tradeoff (méně konfeti v náhledu) oproti loss regresi.
T43frustumCullEnabled
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
V549b feature: po tréninku se odstraní všechny Gaussiany, které leží mimo sjednocení všech tréninkových camera frust. Takové Gaussiany nebyly nikdy omezeny loss signálem a jsou vždy floatery. Obzvláště efektivní pro scény, ve kterých novel-view leží za nebo vedle camera path (např. zadní strana lineárního dronového letu) — floatery tam nikdy v tréninkové fázi nejsou viditelné, ale při pozdějším pohybu v 3D vieweru velmi ano. V549b A/B na dronových letech pozitivní výsledky, proto jako opt-in dostupné. Default false, protože u object captures s plným orbit coverage frustum union obsahuje celou scénu a feature nic neodstraňuje — v Settings se nabízí pod „Floater Reduction" a v Q9 Outdoor předvolbě implicitně přes T44 frustumCullExpansion testováno (Q7 BayesOpt to ale neaktivoval, protože Outdoor Sky Dome řeší stejný problém lépe).
T44frustumCullExpansion
DETAILY
Default: 1.1 Range: 1.0 – 2.0 Defined in:
TECHNICKY
NDC margin pro T43 frustumCullEnabled. 1.0 by řezal přesně na okraji obrazu, což by viklavé splaty u okraje příliš zkrátil. 1.1 = 10 % padding přes přesný framing kamery — dává trochu tolerance pro hraniční pixely, které by mohly být v lehce posunutém novel-view přece viditelné. Hodnoty > 1.2 činí cull prakticky neúčinným, protože rozšířený frustum zahrnuje mnohem více prostoru.
Sky-Dome (T45–T48)
T45skyDomeEnabled
DETAILY
Default: false (Initializer + všechny předvolby kromě P9 Outdoor) Range: boolean Defined in:
TECHNICKY
V549e feature: před startem tréninku se generuje sférický mrak bodů (Fibonacci sphere s T46 sample points), v poloměru T47 skyDomeRadiusMultiplier × scene_extent kolem středu scény umístěn a inicializován barvami z sky-maskovaných pixelů všech tréninkových kamer (viz T20 skyMaskingEnabled). Tyto Sky-Dome Gaussiany se vkládají na začátek Gaussian bufferu a během tréninku „zamrznou" (position/scale/rotation gradienty = 0, jen SH a opacity zůstávají optimalizovatelné). Efekt: místo černých „konfeti" oblastí v dáli vidí uživatel v novel-views skutečnou oblohu. V549e MVP funguje na dronových a krajinných scénách velmi dobře; v P9 Outdoor předvolbě default-on. U interiérových scén nech vypnuté — sféra by visela nesmyslně mimo místnost.
T46skyDomeSampleCount
DETAILY
Default: 5 000 Range: 1 000 – 50 000 (typicky 2 000 – 10 000) Defined in:
TECHNICKY
Počet Fibonacci sphere sample points na Sky-Dome sféře. Vyšší hodnoty → hustší Sky-Dome (lepší u velkých rozlišení a velmi viditelné oblohy), ale více paměťové náročnosti. 5 000 je sweet spot pro 4K renderingy; u nižších rozlišení stačí 2 000–3 000. Body se podle cosine distance ke každému tréninkovému camera view vektoru inicializují odpovídajícími sky-maskovanými pixely — sample points, jejichž view cone nevidí žádná kamera, zůstávají s nízkou počáteční opacity hodnotou vzadu, ale v tréninku se nemění (zamrznuté).
T47skyDomeRadiusMultiplier
DETAILY
Default: 30.0 (Initializer + většina předvoleb), 59.0 (P9 Outdoor, Q7 BayesOpt optimum) Range: 5.0 – 200.0 Defined in:
TECHNICKY
Poloměr Sky-Dome sféry relativně ke scéně rozsahu (= střední vzdálenosti mezi pozicemi kamer). 30 = koule má 30-násobný průměr camera mraku. Příliš malé (< 5) → Sky-Dome interferuje se scénou samotnou (např. Sky-Dome splat přistane v popředí); příliš velké (> 100) → float32 ztráta přesnosti na Sky-Dome pozicích, což spouští render glitche v dálce. Q7 BayesOpt na Bicycle (Mip-NeRF 360) našel 59.0 jako scéně-specifické optimum pro outdoor — to naznačuje, že standardní 30.0 je pro hluboké krajiny příliš malé a Sky-Dome pixely v hraničních oblastech obrazu jsou viditelné jako „stěna".
T48frozenGaussianCount
DETAILY
Default: 0 (= žádné zmrazené Gaussiany) Range: 0 nebo 1 – T46 Defined in:
TECHNICKY
Počet Gaussianů na začátku bufferu, jejichž position/scale/rotation gradienty se v optimizeru nastavují na nulu — zůstávají přes celý trénink prostorově ztuhlí. Density control je nesmí klonovat, štěpit ani prune. Použito pro Sky-Dome injection (viz T45): pokud je Sky-Dome zapnutý, toto pole se automaticky nastavuje na T46 skyDomeSampleCount. Manuální nastavení je možné (např. pro zmrazení předem umístěného mraku bodů z LiDAR skenu), ale v UI ne přímo přístupné. Důležité: prvních N Gaussianů v bufferu jsou vždy zmrazené — pořadí v bufferu rozhoduje, ne explicitní index.
Adam + LR schedule (T49–T55)
T49adamResetIteration
DETAILY
Default: 0 (= deaktivováno) Range: 0 nebo 100 – Defined in:
TECHNICKY
V430 feature: iterace, na které se Adam optimizer momentum akumulátory (m1, m2) resetují na nulu. Bias korekce poté běží s (iter - adamResetIteration) místo s iter. V430 testoval reset na 5 000 (po konci densifikace) → 12.8 % horší loss. Důvod: Adam momentum, které se nahromadilo během densifikace, nese informaci o typických gradient magnitudách a zrychluje refinement fázi. Zahodit ho stojí prvních ~500 iterací refinementu na konvergenci. Disabled. Zůstává CLI flag pro výzkumné experimenty.
T50positionLRScheduleEndIteration
DETAILY
Default: 0 (Initializer = „použij maxIterations"), 20 000 (.full — cosine končí u 20K přes maxIter=35K), 30 000 (.fullClassicPaper) Range: 0 nebo 1 000 – Defined in:
TECHNICKY
V431 feature: iterace, na které position LR cosine annealing křivka dosáhne svého minima. Pokud 0, identické s T1 maxIterations. Pokud > 0, schedule běží do této hodnoty a poté zůstává konstantní na T4 positionLearningRateFinal. To umožňuje „extended refinement phase" s minimální, ale konstantní learning rate — pomalu vylaďuje pozice bez opětovného decay. .full to dělá (schedule konec na 20K, trénink běží do 35K), V434c/V434d potvrdily: 15K a 25K obě zhruba stejně, 20K minimálně optimální. Používá se ve spojení s T51 pro modifikaci i non-position LR v extended phase.
T51extendedPhaseLRDecay
DETAILY
Default: 0.0 (= deaktivováno, konstantní LR) Range: 0 nebo 0.01 – 1.0 Defined in:
TECHNICKY
V433 feature: minimální multiplikátor pro non-position LR (scale, rotation, opacity, SH) v „extended phase" — tedy: poté co je dosaženo T50 a position LR je už na T4. Pokud 0.1, scale/rotation/opacity/SH jsou samy cosine decay od 1.0 (= jejich standardní LR) na 0.1× svého standardu. Pokud 0.0 (default), zůstávají konstantní. V457 testoval plný decay (0.0 = decay-do-nuly) proti žádný decay a našel: avg 0.0400 (2 runy) = stejný loss jako V438 bez decay. Chování čistší s decay, ale ne měřitelně lepší. Proto disabled. Zůstává v CLI jako –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
V440 experimentální: pokud true, aplikace v každém densifikačním kroku počítá p98 aktuální gradient distribuce a používá ho jako dynamický threshold (clampovaný na alespoň 0.5× konfigurované hodnoty z T11, aby moc neunikla). Hypotéza: automatické přizpůsobení aktuální scénové fázi by činilo density control robustnějším — např. na začátku přísnější pruning, později uvolněnější, nebo opačně. V440 testoval a revertoval: katastrofální pokles na 63 K Gaussianů (mass pruning, protože p98 je v prvních iteracích extrémně vysoké a pak skoro nic threshold nepřekročí). Pevný threshold je už dobře kalibrovaný, dynamické přizpůsobení škodí víc, než přináší. Q5 (T77) nabízí alternativní adaptivní logiku přes rolling median, která problém obchází.
T53mergeAfterDensification
DETAILY
Default: false (Initializer), true (.full, .classicBalanced, .fullClassicPaper) Range: boolean Defined in:
TECHNICKY
V438 feature: na konci densifikační fáze (iter T2) se provede jednorázový merge pass, který spojuje blízko sebe ležící Gaussiany s podobnou škálou a barvou. Redukuje počet Gaussianů typicky o 5–15 % bez viditelné ztráty kvality. Smysl: po intenzivním klonování vznikají clustery kvazi-identických Gaussianů, které nic nového nepřispívají — merging uvolňuje kapacitu optimizéru pro jiné oblasti. Standard v Classic Quality předvolbách. U MCMC se nepoužívá, protože MCMC díky své relokační logice takové clustery vůbec nenechá vzniknout.
T54densifyPhase2FromIteration
DETAILY
Default: 0 (= deaktivováno) Range: 0 nebo T2 – T1 Defined in:
TECHNICKY
V426 experimentální: umožňuje druhou densifikační fázi, která startuje po refinement pauze na této iteraci a běží do T55. Hypotéza: po refinement fázi mají gradient akumulátory stabilnější magnitudy a mohou přesněji říci, které oblasti ještě potřebují další Gaussiany. V426 testoval a revertoval: Two-Phase densifikace spadla do 0-Gaussians-cascade-failure (s V425 refinement pruning kombinováno zničilo buffer). Disabled. CLI flag dostupný pro experimenty.
T55densifyPhase2UntilIteration
DETAILY
Default: 0 Range: 0 nebo T54 – T1 Defined in:
TECHNICKY
Konec V426 Two-Phase densifikace. Relevantní pouze když T54 > 0. Obě pole dohromady disabled.
Post-processing + Apple AI (T56–T60)
T56postTrainingCompactification
DETAILY
Default: true (ve všech production předvolbách), false (.quickTest, .preview) Range: boolean Defined in:
TECHNICKY
V443 feature: po konci tréninku se Gaussiany s sigmoid(opacity) < 0.01 tvrdě odstraňují (prakticky nepřispívají k obrazu). Redukuje Gaussian count typicky o 58 % a export velikost souboru o 55 % bez viditelné ztráty kvality. Standardně v production předvolbách aktivní — konečný výsledek má být dodáván co nejkompaktněji. V .quickTest vypnuto, protože diagnostický běh se stejně neexportuje. Na rozdíl od T42 midTrainingCompactificationIterations (V549) probíhá compactification až na konci — refinement může do té doby všechny Gaussiany používat.
T57metalFXUpscaling
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
V444 feature: aktivuje Apple MetalFX Spatial Upscaler místo bilineární interpolace v 3D viewer output. Pokud je tréninkové rozlišení < velikost náhledu (např. trénink na 0.5×, náhled v plném rozlišení), může MetalFX poskytovat výrazně ostřejší obraz. Mění se živě v náhledu, není potřeba re-training. Vylučuje se s T58 mpsLanczosScaling — MetalFX má přednost. Doporučení: zapnout, pokud obraz v vieweru působí „rozmazaně" oproti očekávanému detailu.
T58mpsLanczosScaling
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
V444 feature: MPSImageLanczosScale pro viewport škálování místo bilineární interpolace. Lanczos je klasický sinc-based resampling postup, který dodává výrazně ostřejší výsledky než bilineární s minimálním overheadem. Live toggle. Je přepsáno T57, pokud jsou oba zapnuté.
T59livePreviewInterval
DETAILY
Default: 50 (Initializer a většina předvoleb) Range: 0 (off) nebo 10 – 5 000 Defined in:
TECHNICKY
Jak často se během tréninku aktualizuje 3D viewer s aktuálními Gaussiany. 50 = každých 50 iterací nový render ve vieweru — dobré pro sledování postupu, aniž by zpomalovalo trénink. 0 = viewer se vůbec neaktualizuje (background trénink, max rychlost). Typické přizpůsobení: u .quickTest dolů na 10 (chce se vidět každý krok), u dlouhých MCMC běhů nahoru na 500–2000 (update overhead v součtu znatelný).
T60perceptualLossWeight
DETAILY
Default: 0.0 (= deaktivováno) Range: 0 nebo 0.001 – 0.5 Defined in:
TECHNICKY
V444 future-feature: váha perceptuálního loss termu přes MPSGraph (VGG-like malá síť). Zachytávala by strukturální a texturní podobnost na vyšší sémantické úrovni než L1+SSIM — typické v research pipelines, kde „pixel-perfect" je méně důležité než „vypadá realisticky". Implementace ještě nedokončená (code stub k dispozici, ale forward pass neimplementován). Default 0.0. Zůstává v katalogu polí pro budoucí aktivaci; CLI flag –percep-weight F rezervován.
MCMC densifikace (T61–T73)
T61densificationStrategy
DETAILY
Default: .classic (Initializer + Classic předvolby), .mcmc (všechny MCMC předvolby + Scene-Class) Range: .classic nebo .mcmc Defined in:
TECHNICKY
Vybírá mezi Classic densifikací (klonování/štěpení/prune, Kerbl et al. 2023) a MCMC densifikací (Stochastic Gradient Langevin Dynamics s relokací, Kheradmand et al. NeurIPS 2024). Při .classic se vyhodnocují T11–T16, při .mcmc T62–T73. Pozor při změně: Classic defaulty a MCMC defaulty jsou úplně jinak kalibrované — kdo v Expert View flipne picker, aniž by načetl odpovídající předvolbu, riskuje 1.4.3 bug-style mass extinction (460 K → 5 v jedné iteraci, protože MCMC opacity reg na 0.01 zabije Classic opacities). Proto jsou MCMC init defaulty záměrně „rozředěné" (všechny reg hodnoty 0.0).
T62mcmcMaxGaussians
DETAILY
Default: 150 000 (Initializer + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — Mip-Splatting varianta s 10× rozpočtem), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) Range: 0 (= „použít kapacitu bufferu") nebo 10 000 – 5 000 000 Defined in:
TECHNICKY
Tvrdá horní hranice pro počet Gaussianů u MCMC strategie. Počet roste graduálně o T70 mcmcGrowthRate (typicky 5 %) per relocation step až po tento cap. V473/V531 našly 150 K jako sweet spot — nad 200 K rozřeďuje splatovou kvalitu (příliš mnoho malých redundantních Gaussianů), pod 100 K zůstává scéna pod-densifikovaná. U velmi velkých scén (např. 1 545 obrázkový dronový let s 158 K SfM-init) je 150 K příliš nízké — proto rozšíření 1.4.5 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7 BayesOpt našel scéně-specifická optima mezi 670 K (Indoor) a 1.25 M (Outdoor). U hodnoty 0 engine používá plnou kapacitu bufferu jako cap.
T63mcmcNoiseScale
DETAILY
Default: 0.00005 (5e-5 = paper default) Range: 1e-6 – 1e-3 Defined in:
TECHNICKY
Multiplikátor pro Gaussovo rušení, které se v každé MCMC iteraci přidává k pozici každého Gaussianu (SGLD logika). Vyšší = více explorace (Gaussiany více putují, potenciálně najdou lepší místa), nižší = více exploitation (Gaussiany zůstávají tam, kde jsou už dobří). V467 a V536 potvrdily 5e-5 jako optimální — 1e-5/2e-5 příliš málo explorace, 1e-4 příliš mnoho (splaty se rozprasují). Cosine decayuje přes tréninkový čas do T69 mcmcNoiseDecayEnd — na konci decay oblasti je rušení efektivně 0 a Gaussiany konvergují.
T64mcmcOpacityRegWeight
DETAILY
Default: 0.0 (= deaktivováno v RadianceKit defaultech, paper: 0.01) Range: 0 nebo 0.001 – 0.05 Defined in:
TECHNICKY
MCMC specifická L1 penalty na opacity. Paper default 0.01 (tlačí nepoužívané Gaussiany k nule, činí je dostupnými pro relokaci). V464b ale ukázal: bez reg je to v RadianceKitu měřitelně lepší (Session 28 potvrdila). Důvod: s T68 mcmcDeadOpacityThreshold definované pruning kritérium stačí samo — dodatečná L1 penalty nutí i hodnotné nízko-opacity Gaussiany umírat. Proto default 0. Pozor: v 1.4.3-Beta buildu byl initializer default chybně 0.01, což vyústilo v mass extinction bug (viz T61 vysvětlení); od 1.4.4 fixováno na 0.0.
T65mcmcScaleRegWeight
DETAILY
Default: 0.0 (= deaktivováno, paper: 0.01) Range: 0 nebo 0.001 – 0.05 Defined in:
TECHNICKY
MCMC specifická L1 penalty na škálové eigenvalues. Paper default 0.01. V464b: bez reg lepší, stejné odůvodnění jako T64. Disabled ve všech RadianceKit MCMC předvolbách. Pozor jako u T64: 1.4.3 bug.
T66mcmcRelocationInterval
DETAILY
Default: 100 (Initializer + všechny MCMC předvolby, paper standard), 155 (P9 Outdoor — Q7 BayesOpt optimum) Range: 50 – 500 Defined in:
TECHNICKY
Iterační interval, ve kterém MCMC relokuje mrtvé Gaussiany (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) na nové pozice. V537 testoval 50 (příliš disruptivní, loss kolísá) a 200 (marginálně horší, MCMC ztrácí reaktivitu). 100 je optimální. Q7 BayesOpt na Bicycle našel 155 jako scéně-specifické optimum pro outdoor — mírně delší intervaly dávají Adam více času integrovat nově umístěné Gaussiany, než je další reloc event dostane pod tlak.
T67mcmcWarmupIterations
DETAILY
Default: 500 Range: 100 – 5 000 Defined in:
TECHNICKY
Počet počátečních iterací, ve kterých ještě neprobíhá MCMC relokace. Až po tomto warmupu začíná reloc logika. Smysl: v prvních iteracích opacity hodnoty ještě nejsou ustálené — pokud by se hned reloc start, Gaussiany by byly umisťovány na špatná místa a hned znovu pohybovány, což ničí Adam momentum. Paper default 500. RadianceKit přebírá tuto hodnotu, protože V464b ukázal, že je robustní.
T68mcmcDeadOpacityThreshold
DETAILY
Default: 0.005 (Initializer, paper standard), 0.01 (.fullMCMC a všechny MCMC předvolby — V535 optimum) Range: 0.001 – 0.05 Defined in:
TECHNICKY
Sigmoid(opacity) threshold, pod kterým je Gaussian „mrtvý" a může být relokován. V535 našel 0.01 jako optimální (0.005 marginální, 0.02 horší). Vyšší = agresivnější reloc (více Gaussianů se pohybuje), nižší = opatrnější. 0.01 odpovídá zhruba „0.5 % vizuální viditelnost". P10 Indoor používá přes Q7 BayesOpt 0.0142 jako optimum.
T69mcmcNoiseDecayEnd
DETAILY
Default: 0 (Initializer = „žádný decay"), 160 000 (.fullMCMC = 80 % z 200K), 96 000 (.mcmcBalanced = 80 % z 120K), 40 000 (.mcmcPreview) Range: 0 nebo 1 000 – Defined in:
TECHNICKY
Iterace, na které je T63 mcmcNoiseScale rušení úplně utlumeno na nulu (cosine decay od iter 0 sem). V497c/V502 našly 80 % maxIterations optimální — dává MCMC dost času pro exploraci, ale nechává posledních 20 % na konvergenci bez rušení. 0 = konstantní rušení přes všechny iterace (zřídka rozumné, MCMC pak nemůže konvergovat).
T70mcmcGrowthRate
DETAILY
Default: 0.05 (paper standard = 5 %) Range: 0.01 – 0.2 Defined in:
TECHNICKY
Růstová rychlost MCMC populačního targetu per relocation step. Logika: při každém reloc eventu se cíl populační velikosti zvyšuje o (1 + growthRate), dokud se nedosáhne T62 mcmcMaxGaussians (nebo varianta škálovaná přes T72/T73). V512/V522 našly 0.05 jako optimální — vyšší hodnoty vedou k příliš rychlému růstu (Gaussiany se vkládají, než je Adam momentum stihne integrovat), nižší k pod-densifikovaným scénám na konci.
T71mcmcSigmoidK
DETAILY
Default: 100.0 Range: 10.0 – 500.0 Defined in:
TECHNICKY
Sigmoid sharpness parametr pro MCMC noise attenuation. V SGLD kroku je per-Gaussian rušení tlumeno — vysoko opaké Gaussiany (jejichž logit je pozitivní) dostávají exponenciálně méně rušení než nízko opaké. K = 100 je ostré, tedy přechod z „plné-noise" na „žádné-noise" se děje velmi rychle kolem opacity 0.5. V484–V487 našly K = 100 optimální — menší hodnoty (10–50) nechávají i vysoko opaké Gaussiany kymácet (ničí konvergované Gaussiany), větší (> 500) činí přechod umělý tvrdý a mrtvé Gaussiany se vůbec nepohybují.
T72mcmcCapMultiplier
DETAILY
Default: 3.0 (Initializer + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) Range: 0 (= deaktivováno) nebo 1.0 – 10.0 Defined in:
TECHNICKY
1.4.5 feature: scéně-adaptivní cap škálování. Pokud je T73 mcmcAutoScaleByScene true, efektivní cap se počítá jako (clampované na kapacitu bufferu). Pozadí: u velkých scén (např. 1 545 obrázkový dronový let → 158 K SfM-init) je T62 = 150 000 příliš nízké — density control by vůbec nemohl růst. S multiplier 3.0 se cap u tohoto příkladu škáluje na 474 K (158 K × 3.0). Q7 BayesOpt našel scéně-specifická optima: outdoor profituje z vysokého multiplikátoru (5.32 → ~830 K cap u 156 K bicycle init), indoor se spokojuje s 1.76 (stěny syt rychleji). Kompletní řešení capu viz metoda.
T73mcmcAutoScaleByScene
DETAILY
Default: true (Initializer + všechny MCMC předvolby) Range: boolean Defined in:
TECHNICKY
1.4.5 feature: master switch pro scene-aware cap logiku (viz T72 +). Pokud false, používá se výhradně T62 mcmcMaxGaussians jako cap (zpět k 1.4.4 chování). Standardně zapnuto, protože mass extinction problémy u velkých scén z 1.4.3 by jinak vrátily. Ručně deaktivovat jen, pokud explicitně chceš nastavit tvrdý cap — např. pro trénink 150 K varianty, jejíž konečná velikost je plánovatelná.
Mip-Splatting (Q1.5) (T74–T76)
Status: Q1.5 byl 2026-05-25 po 14 autonomních iteracích + overnight 1.5M confidence check zavržen jako „closed no-win" (max Δ@2× = +0.27 dB, originální gate vyžadoval ≥ +1.5 dB průměr přes 0.5×/2×, FAIL na 0/11 pair-scenes). Pole zůstávají opt-in pro výzkumné experimenty; všechny production předvolby mají vypnuto. Viz verdikt:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETAILY
Default: false (všechny production předvolby), true (.fullMCMCMip — výzkumný sourozenec) Range: boolean Defined in:
TECHNICKY
Aktivuje Mip-Splatting (Yu et al. CVPR 2024): 3D smoothing filtr + 2D filtr + α kompenzace, který omezuje per-Gaussian frekvenci na Nyquist hranici hustoty sampling rate tréninkové kamery. Teoretický cíl: eliminace aliasingu při renderingu v off-training škálách (0.5× nebo 2× tréninkového rozlišení). V preprocess a backward projection shaderech aktivováno, funkčně správně ověřeno v Q1.5-D testu. Ale: originální akceptační gate (Δ@1× ≥ +0.3 dB A avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) nebylo dosaženo na žádné z 11 pair-scenes. Maximálně pozorováno: family 750K classic Δ@2× = +0.270 dB. Outdoorové scény (Truck, Flowers) dokonce ukázaly zhoršení 1× a 0.5×. Hypotéza: 3D smoothing konkuruje s MCMC relokací u high-Gs. Pole zůstává pro budoucí multi-scale re-eval se správnou Mip-NeRF-360 metodologií (viz O3 backlog v benchmark cestě).
T75mipSmoothing3DScale
DETAILY
Default: 0.2 (paper default) Range: 0.05 – 1.0 Defined in:
TECHNICKY
3D smoothing škálový parametr (Yu et al. §3.3, paper default 0.2). Větší = více world space hlazení per Gaussian (= více antialiasingu, ale i více blur na default škále), menší = ostřejší ale náchylnější k aliasingu. Konzultuje se pouze pokud T74 useMipSplatting = true. V Q1.5 testech dále neoptimalizováno — A/B gate prohrál už s paper defaultem 0.2, další sweepy by byly zbytečné.
T76mipFilter2DVariance
DETAILY
Default: 0.3 (= přesně V242 legacy chování) Range: 0.1 – 1.0 Defined in:
TECHNICKY
2D Mip filter variance, která se přidává k Σ_2D diagonále (variance přímo, ne kvadratura). 0.3 je přesně V242 legacy hodnota, která byla před Mip-Splatting hardcoded v kernelu. Pokud T74 useMipSplatting = false, kernel tuto hodnotu kompletně ignoruje a zapisuje napevno 0.3 — takže baseline nemůže regrese (Codex round-1 S3-1 záruka). Pokud zapnuto, použije se zde nastavená hodnota. Zůstává v katalogu polí pro Mip sweepy.
Adaptivní densifikace (Q5) (T77–T79)
T77adaptiveDensification
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
Q5 feature: rolling median tracker jako alternativa k pevnému T11 densifyGradThreshold. Pokud true, v každém densify kroku se aktuální threshold přepíše median(posledních N avgGrad samples) × T79 adaptiveDensifyMultiplier. N = T78 adaptiveWindow. Striktnější než V440 p98 (katastrofální 63 K pruning past), median + 2× sedí zhruba na p70–p80 gradient distribuce v steady state. Q5 testy: samostatně FAIL 0/3 scén, ale společně s Q6 (viz T80/T81) PASS 1/3 scén — bundle Q5+Q6 byl 2026-05-25 propuštěn jako opt-in a aktivuje se přes CLI –adaptive-densify. Q6 je při tom „carrier" quality zisku, Q5 přispívá spíše ke stabilitě.
T78adaptiveWindow
DETAILY
Default: 1 000 Range: 100 – 10 000 Defined in:
TECHNICKY
Rolling median window v densification eventech (NE iteracích — každý T13 densifyInterval step dodá sample). Default 1 000 — u to znamená posledních 100 000 tréninkových iterací přispívá k median, tedy typicky celá tréninková historie do zde. Raná fáze (před T78 samples): tracker vrací nil → fallback na pevný threshold T11. Relevantní pouze pokud zapnuto.
T79adaptiveDensifyMultiplier
DETAILY
Default: 2.0 Range: 1.0 – 4.0 Defined in:
TECHNICKY
Multiplikátor na rolling median pro adaptivní threshold. Default 2.0 odpovídá zhruba p70–p80 typické gradient distribuce. Nižší = agresivnější růst (více klonů), vyšší = přísnější (méně klonů). Q5 testy v rozsahu 1.5–3.0 — 2.0 nejlepší default. Relevantní pouze pokud zapnuto.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
Q6 feature: tréninkové rozlišení startuje na 0.5× a přepíná u T50 positionLRScheduleEndIteration / 2 (nebo T1 maxIterations / 2, pokud T50 není nastaveno) na T22 trainingRenderScale. Používá v Q1.5.1 vyvinutou resize/restoreImageBuffers infrastrukturu. Přepisuje T23 resolutionWarmupScale, pokud aktivováno. Q6 je propuštěn jako „carrier quality zisku" v Q5+Q6 bundle (viz T77) — postupné zvyšování rozlišení dává aplikaci čas najít hrubou geometrii v nižším rozlišení, než přejde k jemné detailní práci. Přes CLI: –curriculum-resolution.
T81curriculumSHProgression
DETAILY
Default: false Range: boolean Defined in:
TECHNICKY
Q6 feature: přepisuje T21 shDegreeUpgradeIterations s [maxIter/4, maxIter/2, maxIter*3/4], rozkládá tedy SH upgrade rovnoměrně přes tréninkový čas místo front-to-load. Hypotéza: stabilní geometrie se etabluje před color detail explosion, což view-direction závislé lesklé efekty přesněji umisťuje. Q5+Q6 dohromady PASS 1/3 scén, Q6 jako carrier zisku (Q5 samo FAIL). Přes CLI: –curriculum-sh.
Statické předvolby (TP1–TP9)
Zde pouze strukturální rozdíly proti default initializéru. Plný marketingový popis 10 UI předvoleb P1–P10 najdeš v Kapitole 7.
TP1.preview
DETAILY
Diagnostická/preview předvolba pro systémy ≥ 10 GB RAM. Overrides oproti Initializeru: - 30 000 → 5 000 - 15 000 → 3 500 (70 % maxIter) - 1.6e-6 → 1.6e-5 (10× vyšší, méně agresivní decay) - několik LR 2× (V176) - 3 000 → 100 000 (efektivně off, V172: reset zničí krátké tréninky) - [1K, 2K, 3K] → [1K, 2K] (V182: degree 3 nekonverguje v 2K iter) - 1.0 → 0.5
TP2.full
DETAILY
Production-Quality Classic. Overrides: - 30 000 → 35 000 (V550: 40K testy Truck overtraining +10.7 % Gs při -1.3 % L1) - 15 000 → 5 000 (V310 sweet spot, V338 7K horší) - všechny LR 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 disabled, V421 confirmed) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 delayed) - 0.0 → 0.9995 (V546 HTGS, 14 % zlepšení) - 50 (nezměněno, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, už initializer default pro .full)
TP3.fullClassicPaper
DETAILY
Q1.5-A test sourozenec TP2, paper-věrný Classic. Overrides oproti TP2: - 35 000 → 30 000 (paper standard) - 5 000 → 15 000 (paper: 50 % maxIter) - 1.6e-5 → 1.6e-6 (paper default) - několik LR zpět na paper defaulty (0.05, 0.005, 0.001) - 1.1e-6 → 2e-7 (kalibrováno pro ~1-2M Gs na Bicycle) - 200 → 100 (paper) - 0.001 → 0.005 (paper default) - 100 000 → 3 000 (paper §5.2, rizikové — může vyvolat V194 regresi) - 0.9995 → 0.0 (paper nemá decay) - 20 000 → 30 000 (cosine běží na 100 % maxIter)
TP4.fullMCMC
DETAILY
Production-Quality MCMC. Overrides oproti Initializeru: - 30 000 → 200 000 (V534, MCMC potřebuje 5× více iter než Classic) - 15 000 → 160 000 (V504b 80 % maxIter) - 1.6e-6 → 1.6e-5 - LR schedule jako TP2 (všechny 2×) - 0.2 → 0.05 (V521b/V534: MCMC potřebuje silnější L1 signál) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (v Initializeru už, v předvolbě potvrzeno) - 5e-5 (V467/V536 optimální) - 0.005 → 0.01 (V535 optimální) - 0 → 160 000 (80 % maxIter, V497c/V502) - 3.0 (v Initializeru už) - true (v Initializeru už) - 3 000 → 200 000 (efektivně off, MCMC používá reloc místo reset)
TP5.fullMCMCMip
DETAILY
Q1.5-D test sourozenec TP4, s Mip-Splatting + paper-magnitude MCMC rozpočtem. Overrides oproti TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, paper magnitude) - useMipSplatting false → true (Mip-on)
TP6.classicBalanced
DETAILY
Mid-tier Classic. Overrides oproti TP2: - 35 000 → 20 000 (V149: 20K = 30K při 33 % méně času) - 20 000 → 0 (cosine běží na maxIter = 20K, žádná extended phase)
TP7.mcmcPreview
DETAILY
MCMC diagnostika. Overrides oproti TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: Preview = lighter scaling)
TP8.mcmcBalanced
DETAILY
Mid-tier MCMC. Overrides oproti TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3.0 → 2.5 (mezi Preview 2.0 a Full 3.0)
TP9.quickTest
DETAILY
Čistý funkční test. Overrides oproti Initializeru: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (kalibrováno pro 0.25× rozlišení) - 100 → 50 - 3 000 → 100 000 (off, protože příliš krátké) - 1.0 → 0.25
Metoda: resolveMcmcMaxGaussians
Signature: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Defined in:
Jediný source of truth pro otázku „kolik Gaussianů smí MCMC maximálně vyrůst?". Počítá se ze tří vstupů: konfigurovaného T62 mcmcMaxGaussians (s mass extinction floor 150 000, pokud 0), initialPointCount (počet SfM init bodů) a bufferCapacity (předalokovaná velikost Gaussian bufferu). Logika:
+ base = T62 > 0 ? T62: 150_000 (mass extinction floor chrání proti initializer default bugům jako 1.4.3 mass extinction incident) + Pokud T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) jinak + Pokud bufferCapacity > 0: return min(scaled, bufferCapacity) + Jinak return scaled
Příklad: Bicycle (Mip-NeRF 360, 194 foto framů) → SfM init ~156 K bodů, T62 = 150 000, T72 = 5.32, kapacita bufferu 8 M. Resolved cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. To je efektivní růstový cap, ke kterému se drží MCMC relokační logika.
Počítá skutečný maximální počet splatů u MCMC. Bere tvé nastavení, dívá se, kolik bodů má tvá scéna na začátku, a škáluje s Multiplier, pokud je automatické přizpůsobení zapnuto. Tak se cap přizpůsobí scéně, místo aby pro malou a obří scénu vynucoval stejnou hodnotu. Metodu nemusíš volat sám — trénink ji používá interně.
Které pole na co? (Cheat-sheet)
| Cíl | Pole k otáčení |
|---|---|
| Více detailu v dáli | T62 mcmcMaxGaussians vysoko, T72 mcmcCapMultiplier 5+ |
| Více detailu obecně (Classic) | T1 maxIterations vysoko (≤ 40K), T2 densifyUntilIteration ≤ 14 % T1 |
| Redukovat floatery v dronových letech | T43 frustumCullEnabled on, T20 skyMaskingEnabled on, T45 skyDomeEnabled on |
| Krásná obloha ve venkovních scénách | T45 skyDomeEnabled on, T47 skyDomeRadiusMultiplier 30–60 |
| Menší export soubor | Strategie .mcmc (T61), T56 postTrainingCompactification on, T62 mcmcMaxGaussians ≤ 200K |
| Rychlejší trénink | T22 trainingRenderScale 0.5, T1 maxIterations na polovinu — ale ne obojí! |
| Lepší lesklá místa | T21 shDegreeUpgradeIterations s [2K, 5K, 8K] (žádný early-front-load), MCMC + 200K iter |
| Udržet Mac responzivní | T25 throttleDelayMs 5–10 (stojí ~15 % tréninkového času) |
| Live náhled častěji | T59 livePreviewInterval dolů na 10–20 |
| Měkčí přechody ve stínech | T17 ssimWeight trochu vysoko (0.15–0.25), ale ne nad 0.3 |
| Udržet interiéry kompaktní | P10 Indoor předvolba (, T72 = 1.76) |
Nebezpečná pole
Tato pole mohou při špatné konfiguraci vést k OOM, pádu aplikace, mass extinction Gaussianů nebo nepoužitelným benchmark datům. Zacházet s opatrností:
- T11 densifyGradThreshold — halvení může vytvořit 2–4× více Gaussianů, což rychle vyhodí GPU paměť. Také pamatovat: musí odpovídat T22 trainingRenderScale (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — u velkých scén s > 200 K SfM init bodů a multiplikátorem > 5 vzniká resolved cap milionů Gaussianů. Na 36 GB RAM Maců OOM možné. Outdoor předvolba 5.32 funguje jen proto, že Mip-NeRF 360 Bicycle má 156 K init bodů → 830 K cap. - T39 testViewIndices — manuální nastavení může učinit benchmark nepoužitelným (všechny indexy > N → žádné holdouts). Nech to –benchmark flagu nastavovat. - T64 mcmcOpacityRegWeight a T65 mcmcScaleRegWeight — v 1.4.3 betě nastaveno na 0.01, což vedlo k mass extinction (460 K → 5 Gaussianů v jedné iteraci). Od 1.4.4 fixováno na 0.0, ale ruční zvýšení může problém reprodukovat. - T15 opacityResetInterval — pokud ne 100 000+ (efektivně off) a trénink je kratší než 10 000 iterací, reset zničí konvergenci. .preview to má proto na 100 000 přes maxIterations = 5 000. - T54/T55 densifyPhase2* — Two-Phase densifikace v testech zhroucena na 0-Gaussians-cascade. Nech obě na 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, může na některých outdoorových scénách dokonce zhoršit PSNR. Default off, opt-in jen pro výzkum.
Pokud pole stojí na tomto seznamu a chceš ho měnit, udělej nejdřív zálohu své aktuální předvolby (export jako JSON) a uvaž, zda můžeš výsledek reprodukovatelně měřit — jinak hned nevíš, zda jsi zlepšení nebo zhoršení způsobil.