Capítulo 6 — Configuración del entrenamiento
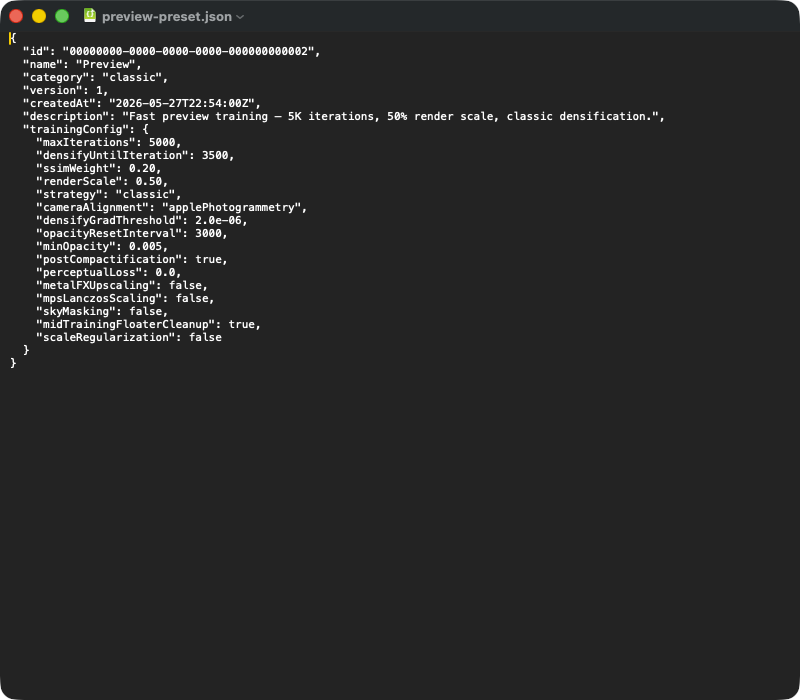
Una exportación típica de un ajuste preestablecido como JSON. Campos de nivel superior: id (UUID), name, (classic | mcmc | sceneClass | custom), (versión de schema), (timestamp), (texto libre). El objeto anidado contiene los parámetros críticos para la reproducibilidad — en la importación, todo el bloque se deserializa en el struct TrainingConfig, y los defaults de la versión actual de la app rellenan los campos que falten en el JSON (p. ej., tras una actualización de la app). Para pasar un ajuste preestablecido a otro Mac, basta con enviar este archivo JSON.
El struct TrainingConfig es el corazón de cada run de entrenamiento en RadianceKit. Recopila todos los parámetros que influyen en el entrenamiento — desde el número máximo de iteraciones, pasando por las ocho learning rates, hasta los campos especiales para MCMC, Mip-Splatting, el currículum y la lógica de tope consciente de la escena. Lo editas en la barra lateral en la sección Training Configuration (Vista Experto), lo guardas como ajuste preestablecido o lo entregas como exportación JSON a otro Mac. Al iniciar el entrenamiento, este mismo objeto se congela y se entrega al backend de GPU.
Este capítulo es material de referencia para power users y autores de scripts. Lista los 81 campos públicos, los 9 ajustes preestablecidos estáticos y el único método público. El archivo fuente es TrainingConfig.swift — en caso de duda, el comentario de doc almacenado allí y el valor por defecto del inicializador son la fuente de verdad.
Índice:
+ Iteración (T1–T2) + Learning Rates (T3–T10) + Densificación — Classic (T11–T16) + Loss (T17–T20) + Progresión de grado SH (T21) + Rendimiento (T22–T25) + Diagnóstico y preparación de la nube de puntos (T26–T30) + Regularización (T31–T37) + Refinamiento (T38–T44) + Sky Dome (T45–T48) + Adam + schedule de LR (T49–T55) + Post-procesado + Apple AI (T56–T60) + Densificación MCMC (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Densificación adaptativa (Q5) (T77–T79) + Currículum (Q6) (T80–T81) + Ajustes preestablecidos estáticos (TP1–TP9) + Método: + ¿Qué campo para qué? (Cheat Sheet) + Campos peligrosos
Iteración (T1–T2)
T1maxIterations
DETALLES
Predeterminado: 30 000 (initializer), 35 000 (.full), 200 000 (.fullMCMC) Rango: 1 000 – 500 000 (deslizador UI), sin límite superior duro en la lógica Definido en:
TÉCNICO
Número total de iteraciones de entrenamiento que ejecuta el backend. Una iteración significa un forward render de una sola cámara de entrenamiento, un backward pass sobre todos los componentes del loss (L1 + SSIM + regularizaciones opcionales + máscara de cielo) y un paso del optimizador Adam. Este número controla directamente los demás schedules: la learning rate de posición sigue una curva cosine annealing de 0 a T1 mismo o a T49 positionLRScheduleEndIteration; la densificación se detiene en T2 densifyUntilIteration; el decay de ruido MCMC termina en T69 mcmcNoiseDecayEnd; los upgrades de grado SH ocurren en las tres marcas de T21. Para la densificación clásica, el sweet spot empírico está en 20 000–35 000 iteraciones (Sesiones 1–32, tests V546), para MCMC en 60 000–200 000 (V534). Empujar mucho más allá de los valores almacenados en el ajuste preestablecido rara vez aporta calidad adicional — el momentum de Adam se satura, y sin un final de decay de LR el loss se estanca. Al contrario, bajar de ~5 000 lleva a geometría incompletamente convergida (la density control tiene muy poco tiempo para clone/split).
T2densifyUntilIteration
DETALLES
Predeterminado: 15 000 (initializer), 5 000 (.full), 160 000 (.fullMCMC) Rango: 0 – Definido en:
TÉCNICO
Iteración en la que se detiene la densificación. Hasta este punto, los Gaussianos se clonan, dividen y podan según las reglas parametrizadas en T11–T16 (Classic) o T67–T70 (MCMC); después, el número de Gaussianos se mantiene constante y solo se optimizan posiciones, rotaciones, escalas, opacidades y coeficientes SH (fase de refinamiento). En el paper original de 3DGS, el valor está en el 50 % de T1, en el preset .full de RadianceKit solo en el ~14 % (5 000 de 35 000) — consecuencia de los experimentos V310/V338 que mostraron que tras 5 000 iteraciones más densificación empeora el resultado (más floaters, mayor uso de memoria, sin ganancia de calidad). MCMC, en cambio, ejecuta la relocalización hasta el 80 % de T1 (V504b) porque MCMC no produce floaters dañinos. Si T2 es demasiado pequeño (< 1 000), surgen muy pocos Gaussianos; demasiado grande bajo Classic (> 50 % de T1) lleva a sobrecrecimiento y a outliers de saturación RGB (véase Outdoor Overtraining Findings).
Learning Rates (T3–T10)
T3positionLearningRate
DETALLES
Predeterminado: 0,00016 Rango: 1e-7 – 1e-3 (recomendado) Definido en:
TÉCNICO
Learning rate de Adam para la posición XYZ de cada Gaussiano al inicio del entrenamiento (iteración 0). Sigue una curva cosine annealing y decae a lo largo del entrenamiento hasta T4 positionLearningRateFinal. El predeterminado 0,00016 viene del paper original de 3DGS (Kerbl et al. 2023) y en RadianceKit no se escala ni siquiera con mayor resolución de imagen — la posición se mueve en coordenadas mundo, no en espacio de píxeles. Un aumento claro (> 0,0005) hace que los Gaussianos salten grandes distancias y el loss se vuelve inestable; valores muy por debajo (< 0,00005) hacen que nubes de puntos mal inicializadas no encuentren nunca su sitio. V414 probó duplicar el valor inicial → 16,8 % peor loss L1; los tuneos V544a confirmaron el default del paper como óptimo. Nota: bajo .fullMCMC lo dejamos deliberadamente en el default — MCMC necesita learning rates constantes para su lógica de relocalización, así que afinar aquí no aporta nada.
T4positionLearningRateFinal
DETALLES
Predeterminado: 0,0000016 (initializer + paper), 0,000016 (.full, .fullMCMC — 10× mayor) Rango: 0 – Definido en:
TÉCNICO
Valor final de la curva cosine annealing de LR de posición. Se alcanza ya sea en T1 maxIterations o, si está fijado, en T49 positionLRScheduleEndIteration. El preset .full de RadianceKit usa 0,000016 — es decir, 10× más alto que el default del paper 0,0000016. Los experimentos V420 mostraron que 0,5× del valor final (0,000008) hace el loss un 6,4 % peor; V414 mostró que 2× el valor inicial lo empeora un 16,8 %. El valor final alto no es un trade-off sino una elección deliberada: con un decay demasiado agresivo, los Gaussianos pierden durante la fase de refinamiento la capacidad de reaccionar a candidatos de densificación recién llegados. Mediante la extensión V431/V433, la fase del schedule se puede acortar (T49 < T1), de modo que T4 se alcance antes del final del entrenamiento y el resto del entrenamiento corra con el mini-LR constante — configuración típica: T49 = 20 000, T1 = 35 000, refinamiento por tanto en 0,000016 durante 15 000 iteraciones.
T5shDCLearningRate
DETALLES
Predeterminado: 0,0025 (initializer + paper), 0,005 (.full y todos los ajustes preestablecidos MCMC — 2×) Rango: 0,0001 – 0,05 Definido en:
TÉCNICO
Learning rate de Adam para el componente DC (grado 0, es decir, albedo constante) del color spherical harmonic. El SH-DC corresponde al tono base independiente de la dirección de un Gaussiano, esencialmente el "color base". Los experimentos V176 y V188 encontraron 2× más alto que el default del paper como óptimo — convergencia de color más rápida, especialmente porque con entrenamiento corto (5 000 iteraciones), el SH-DC en otro caso no converge. A diferencia de las LRs geométricas, el SH-DC no tiene decay; la learning rate se mantiene constante sobre todas las iteraciones (o solo sigue el decay opcional de fase extendida de T51). V416 probó cuadruplicar a 0,01 → loss 6,4 % peor con Adam beta2=0,99.
T6shRestLearningRate
DETALLES
Predeterminado: 0,000125 (initializer + paper), 0,00025 (.full y MCMC — 2×) Rango: 0,000001 – 0,005 Definido en:
TÉCNICO
Learning rate de Adam para los coeficientes SH de orden superior (grados 1, 2, 3 — los componentes de color dependientes de la dirección de visión que producen brillos, reflejos y sombreado suave). 20× más pequeña que T5 por convención del paper, porque esos coeficientes crecen cuadráticamente en número (3 para grado 1, 5 para grado 2, 7 para grado 3 → 15 floats totales por Gaussiano) y sin una learning rate menor sobresaturarían la imagen. Se desbloquean en dos pasos — hasta la primera marca en T21 shDegreeUpgradeIterations solo está activo el grado 0 (así que solo T5), después el 1, luego el 2, finalmente el 3. Los valores bajos aquí son particularmente importantes en escenas con mucha iluminación difusa; en superficies muy especulares (pintura de coche, agua) afinar no ayuda — la propia representación SH está limitada.
T7opacityLearningRate
DETALLES
Predeterminado: 0,05 (initializer + paper), 0,1 (.full, MCMC — 2×) Rango: 0,001 – 1,0 Definido en:
TÉCNICO
Learning rate de Adam para la opacidad logit de cada Gaussiano. La app almacena la opacidad como un valor float no acotado y la transforma con sigmoide a [0, 1]; la LR actúa en espacio logit. El default 0,05 del paper se restauró tras los tests V50 (mejor L1 single-run 0,1664), V71 revirtió el 0,025 de V67. La duplicación V188 a 0,1 hace el pruning más eficiente — los Gaussianos muertos caen más rápido por debajo del T14 pruneOpacityThreshold. V418 mostró: 0,05 con Adam beta2=0,99 es un 7,1 % peor que 0,1 — la interacción con la configuración de Adam no es trivial. Valores bajos (< 0,01) hacen que los Gaussianos "muertos" persistan eternamente y desperdicien memoria; valores demasiado altos (> 0,5) pueden llevar a explosión de opacidad, por lo que el valor logit en el optimizador se hace clamp a [-15, 3] (véase la nota "Opacity Explosion Prevention" en CLAUDE.md).
T8opacityLearningRateFinal
DETALLES
Predeterminado: 0,0 (= "sin decay") Rango: 0 o 0,001 – Definido en:
TÉCNICO
Valor final opcional de decay cosine para la LR de opacidad (V427). Cuando es 0,0, el decay está deshabilitado y la LR de opacidad se mantiene constante en T7 durante todo el entrenamiento. V427 probó un decay 0,1 → 0,01 — resultado fue loss 11,5 % peor; revertido, de ahí el predeterminado "off". La hipótesis tras el campo: en la fase de refinamiento, una LR de opacidad constante podría llevar a oscilación, de modo que splats que ya hubieran alcanzado el nivel correcto de transparencia serían empujados de un lado a otro por fluctuaciones aleatorias de gradiente. Empíricamente no es así — la lógica de clamp logit ya lo atrapa. El campo se mantiene disponible para experimentos futuros; runs MCMC muy largos (> 500K iteraciones) también podrían beneficiarse.
T9scaleLearningRate
DETALLES
Predeterminado: 0,005 (initializer + paper), 0,01 (.full, MCMC — 2×) Rango: 0,0001 – 0,1 Definido en:
TÉCNICO
Learning rate de Adam para los tres componentes de escala de cada Gaussiano en espacio logarítmico (RadianceKit almacena log(scale) para que las escalas se mantengan positivas). El default del paper 0,005, duplicado en RadianceKit a 0,01 para mejor convergencia de escala con las configuraciones de learning rate optimizadas. Experimento V423: 0,005 con Adam beta2=0,99 → loss 18,7 % peor y visiblemente muy pocos Gaussianos (la density control no podía clonar porque las actualizaciones de escala eran demasiado perezosas). La escala controla la extensión de cada Gaussiano — un aprendizaje demasiado rápido lleva a Gaussianos "aguja" (splats extremadamente largos y delgados, véase T34 scaleRatioPruneThreshold), un aprendizaje demasiado lento mantiene los splats demasiado compactos y la density control tiene que dividir demasiado a menudo.
T10rotationLearningRate
DETALLES
Predeterminado: 0,001 (initializer + paper), 0,002 (.full, MCMC — 2×) Rango: 0,0001 – 0,05 Definido en:
TÉCNICO
Learning rate de Adam para los cuatro componentes cuaternión de cada Gaussiano. El cuaternión se renormaliza tras cada actualización de Adam (norma L2 = 1) — en otro caso, la matriz de covarianza degeneraría. RadianceKit duplica el default del paper en los ajustes preestablecidos Quality porque la rotación tiene magnitudes de gradiente absolutas más pequeñas que escala/posición (en la esfera unitaria cada paso se mantiene corto) y sin 2× la rotación estaría claramente sub-convergida en la ventana de 35 000 iteraciones. V188 lo documenta. En escenas NeRF-Blender (Lego, Chair) la rotación importa particularmente — los bordes de objetos solo se alinean correctamente tras 5 000–10 000 iteraciones.
Densificación — Classic (T11–T16)
T11densifyGradThreshold
DETALLES
Predeterminado: 0,000002 (initializer, calibrado para 0,5× resolución), 0,0000011 (.full, calibrado para 1,0×), 0,000004 (.quickTest, calibrado para 0,25×), 2e-7 (.fullClassicPaper) Rango: 1e-8 – 1e-3 (dependiente de resolución) Definido en:
TÉCNICO
Umbral para la norma L2 del gradiente proyectado en espacio de pantalla dMean2D, por encima del cual un Gaussiano se marca para clonado o división. El valor absoluto depende directamente de la resolución de entrenamiento — dMean2D escala aproximadamente como 1/resolución² (más píxeles = gradientes por píxel más pequeños). De ahí que cada paso de T22 trainingRenderScale necesite un umbral calibrado: 0,25× → 4e-6, 0,5× → 2e-6, 1,0× → 5e-8 … 1,1e-6 (.full). El default 0,0002 del paper está normalizado NDC y no es directamente comparable con la pipeline en espacio mundo de RadianceKit. Con el flag T52 adaptiveDensifyThreshold introducido en V440, el valor puede derivarse en runtime del p98 de la distribución actual de gradientes — pero V440 lo probó en escenas reales y produjo 63 K Gaussianos (pérdida catastrófica por pruning); el flag se queda off. Q5 (T77–T79) proporciona una lógica adaptativa alternativa vía mediana rodante. Este campo no es inocuo — partir a la mitad crea 2–4× más Gaussianos (presión de memoria, riesgo OOM); duplicar puede sub-densificar la escena.
T12densifyFromIteration
DETALLES
Predeterminado: 500 Rango: 100 – 5 000 Definido en:
TÉCNICO
Primera iteración en la que la densificación se vuelve activa. Antes solo ocurre aprendizaje "puro" sobre la nube de puntos SfM inicial, sin que se creen nuevos Gaussianos. El default 500 viene del paper 3DGS y da tiempo a la inicialización para estabilizarse — si la densificación arranca ya en la iteración 0, los puntos SfM mal posicionados se clonan muchas veces antes incluso de encontrar su lugar correcto. V349 probó 1000 → loss ligeramente peor; el default es óptimo.
T13densifyInterval
DETALLES
Predeterminado: 100 (initializer, MCMC), 200 (.full) Rango: 50 – 1 000 Definido en:
TÉCNICO
Cuántas iteraciones hay entre dos pasos de densificación. Default del paper 100 — cada 100 iteraciones se evalúa la lista de candidatos a densificar, se clona/divide, y al mismo tiempo se elimina la lista de candidatos a poda (sigmoid(opacity) < T14 pruneOpacityThreshold). Las pruebas V112 encontraron 200 como óptimo para .full — esto descarga la GPU porque corren menos pasadas de reorganización, y da a cada Gaussiano más tiempo para asentarse tras una acción de clonado. V417 probó 100 con Adam beta2=0,99 → 5,8 % peor (957 K Gaussianos, sobre-densificación). Bajo MCMC el mismo campo se interpreta como intervalo de relocalización; véase T67 mcmcRelocationInterval para la lógica específica de MCMC.
T14pruneOpacityThreshold
DETALLES
Predeterminado: 0,005 (initializer, paper, MCMC), 0,001 (.full) Rango: 0,0001 – 0,1 Definido en:
TÉCNICO
Umbral de opacidad sigmoide por debajo del cual un Gaussiano se elimina en el siguiente paso de densificación. Funciona junto con T7 opacityLearningRate y la lógica de clamp logit en el optimizador. V393 bajó el default de 0,005 a 0,001 en .full — resultado: los splats que solo importan bajo ángulos de visión exóticos se mantienen más tiempo y contribuyen a detalle SH. V394 probó 0,0001 → ligeramente peor (muy poco podado, memoria desperdiciada). Importante: la density control DEBE podar siempre, aun cuando la capacidad de buffer ya esté llena por otras medidas (véase "Density Control Must Always Prune" en CLAUDE.md) — en otro caso, los Gaussianos muertos se acumulan y el número se congela.
T15opacityResetInterval
DETALLES
Predeterminado: 3 000 (initializer + paper), 100 000 (.full = efectivamente deshabilitado), 200 000 (.fullMCMC = deshabilitado) Rango: 1 000 – 100 000+ Definido en:
TÉCNICO
Cuántas iteraciones entre reseteos de la opacidad de todos los Gaussianos a un valor bajo (~0,01) — una medida del paper 3DGS para reevaluar splats "congelados". V194 mostró que con el setup de warmup + entrenamiento estocástico + LRs 2× de RadianceKit, el reset de opacidad cuesta un 5,5 % de calidad y que la lógica de clamp logit ya cubre la función reset. De ahí que en .full esté prácticamente deshabilitado (100 000 > 35 000, así que nunca se dispara). V421 probó reset cada 3 000 con Adam beta2=0,99 → 4,9 % peor; revertido. Bajo .fullClassicPaper (test paper-true Q1.5-A) se vuelve a poner deliberadamente en 3 000 — esa fue una de las palancas con las que se intentó alcanzar los presupuestos de Gaussianos de magnitud-paper.
T16maxScreenSize
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 (off) o > 0 Definido en:
TÉCNICO
Tamaño máximo en espacio de pantalla (en píxeles proyectados) que un Gaussiano puede alcanzar antes de dividirse forzosamente. El valor está en 0 (V48 probado y revertido) — la density control de RadianceKit usa en su lugar el umbral de escala en espacio mundo de la lógica dMean2D. Se queda en el catálogo de campos porque futuros experimentos con Mip-Splatting (T74–T76) o estrategias de splatting específicas de escena podrían beneficiarse. Habilitar (valor > 0, p. ej., 20) forzaría a los splats que han crecido mucho en pantalla a subdividirse — relevante con superficies de pared grandes y suaves donde un único splat gigante ofrece muy poco detalle.
Loss (T17–T20)
T17ssimWeight
DETALLES
Predeterminado: 0,2 (initializer + paper + .full), 0,05 (todos los ajustes preestablecidos MCMC) Rango: 0,0 – 1,0 Definido en:
TÉCNICO
Peso del término D-SSIM en la función de loss combinada loss = (1 - λ) * L1 + λ * D-SSIM, donde λ = T17. El default 0,2 del paper 3DGS es óptimo para la densificación clásica — V383 probó 0,3 → 28,9 % peor, V373b confirmó 0,2 como sweet spot. Para MCMC se estableció independientemente en V521b/V534: 0,05 es óptimo porque MCMC, por su exploración estocástica, necesita un componente de señal L1 más fuerte — pesos SSIM más altos diluirían las decisiones de relocalización. SSIM es significativamente más caro de calcular que L1 (ventanas locales 11×11 sobre toda la imagen); RadianceKit usa una implementación acelerada por MPS que se mantiene por debajo de 1 ms por imagen 1080p. Los sweeps Q7 BayesOpt encontraron óptimos específicos de escena entre 0,05 (.outdoorPreset: 0,082) y 0,171 (.indoorPreset).
T18ssimWeightRefinement
DETALLES
Predeterminado: 0,0 (= "sin cambio, mantener ssimWeight") Rango: 0 o 0 – 1,0 Definido en:
TÉCNICO
Valor SSIM opcional para la fase de refinamiento tras T2 densifyUntilIteration. V428 probó 0,2 → 0,3 en refinamiento → 16 % peor loss (tanto L1 como SSIM degradados); revertido, de ahí el default 0,0. La hipótesis tras el campo era que tras la densificación — cuando ya no se crean nuevos Gaussianos — una mayor parte SSIM maximizaría la nitidez estructural. Empíricamente falso: subir el peso SSIM significa indirectamente bajar el peso L1, y L1 es la señal mucho más significativa en la fase final de refinamiento. El campo se mantiene disponible para experimentos futuros con perceptual loss (T60) o edge loss (T19), donde una composición de loss específica de refinamiento podría tener sentido.
T19edgeLossWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,001 – 1,0 Definido en:
TÉCNICO
V437 loss experimental: peso de un loss L1 en dominio gradiente Sobel que compara directamente los bordes de imagen (Sobel ground-truth vs Sobel del render) por encima de L1+SSIM. Hipótesis: la información de borde es una piedra angular perceptual de la calidad de imagen y un término explícito debería animar a los Gaussianos a acertar mejor los bordes. Resultados de prueba: peso 0,1 → 11 % peor loss, 0,01 → neutro para calidad pero 10 % más lento. La pasada Sobel cuesta un forward MPS extra sobre ground truth y render. De ahí que esté deshabilitado permanentemente. Caso de uso futuro: escenas con bordes artificiales duros (arquitectura, mobiliario, renderizados) podrían beneficiarse — los ajustes Scene Class de Q7 sin embargo no lo eligieron, escalaron en su lugar el peso SSIM.
T20skyMaskingEnabled
DETALLES
Predeterminado: false (initializer y todos los ajustes preestablecidos) Rango: booleano Definido en:
TÉCNICO
Habilita el enmascaramiento de cielo. En cada imagen se enmascara la región de cielo mediante Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest), y el loss en esa región se pone a cero. Razón: las escenas exteriores sufren a menudo de píxeles de cielo azul/gris/blanco que llevan a la app a colocar Gaussianos exactamente ahí — lo que se percibe como "floaters". Sin máscara de cielo, el loss en esa región nunca sería cero, porque el cielo en la imagen varía ligeramente y la app sigue intentando reconstruirlo con splats. La máscara Vision se calcula una vez por cámara antes del entrenamiento y se mantiene en RAM. Típicamente se activa junto con T45 skyDomeEnabled (lógica UI en la vista de Ajustes). Déjalo deshabilitado para escenas interiores o renderizados sintéticos — la máscara detectaría erróneamente techos o paredes como "cielo".
Progresión de grado SH (T21)
T21shDegreeUpgradeIterations
DETALLES
Predeterminado: [1_000, 2_000, 3_000] (initializer), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — grado 3 saltado) Rango: [Int], cada valor en [0, maxIterations], monótonamente creciente Definido en:
TÉCNICO
Iteraciones en las que el grado SH activo se sube 0→1, 1→2, 2→3. Antes de la primera marca solo están activos los componentes DC (es decir, T5 shDCLearningRate), después de la primera marca DC + 3 coeficientes de grado 1, después de la segunda marca + 5 coeficientes de grado 2, después de la tercera marca los 15 coeficientes. El consumo de memoria por Gaussiano crece por pasos en consecuencia — 4 floats → 16 floats → 36 floats → 64 floats. Los ajustes preestablecidos Quality retrasan los upgrades respecto a los defaults del initializer (V228) porque la geometría debería estabilizarse primero, antes de que los detalles de color con su frecuencia más alta se añadan encima. V384 probó [1K, 2K, 3K] para .full → 9,3 % peor — confirma el retraso. .preview se topa en grado 2, porque el grado 3 no converge en 5 000 iteraciones y solo consume capacidad de optimizador. Q6 (T80–T81) ofrece una lógica de currículum alternativa que sobrescribe esta lista de forma dinámica.
Rendimiento (T22–T25)
T22trainingRenderScale
DETALLES
Predeterminado: 1,0 (initializer, .full, MCMC, Scene-Class), 0,5 (.preview), 0,25 (.quickTest) Rango: 0,05 – 2,0 (típicamente 0,25, 0,5, 1,0) Definido en:
TÉCNICO
Resolución de renderizado durante el entrenamiento relativa a la resolución original de las imágenes de entrenamiento. En 0,5 cada imagen se reduce al 50 % de ancho × 50 % de alto (es decir, 25 % de los píxeles) y el renderizado Gaussiano ocurre a esa resolución más baja. Reduce cuadráticamente tanto memoria como cómputo. Importante: T11 densifyGradThreshold tiene que coincidir con la resolución elegida — las magnitudes de gradiente escalan con 1/resolución², por lo que .quickTest (0,25×) tiene un umbral mucho más alto (4e-6) que .full (1,0×, 1,1e-6). RadianceKit avisa con imágenes muy grandes y ajusta automáticamente — 3 MP de resolución objetivo. Con imágenes de entrada 4K extremas, 0,5 o incluso 0,25 tendría sentido; en otro caso, cualquier Mac correrá solo en compactación CPU.
T23resolutionWarmupScale
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,1 – Definido en:
TÉCNICO
Optimización V133: entrena la fase de densificación (iter 0 a T2) a una resolución más baja que la fase de refinamiento. V308 lo apagó de nuevo para .full porque con T22 = 1,0 y cosine annealing, el ahorro de tiempo era marginal y la calidad sufría ligeramente. Se queda en el catálogo de campos porque podría volver a ser útil con entradas 4K y runs largos — el currículum Q6 (T80) recogió una lógica similar, aunque ahí está atada al schedule de LR. Si está habilitado y T80 curriculumResolutionRamp también es true, Q6 gana y sobrescribe este valor.
T24tileSize
DETALLES
Predeterminado: 16 Rango: 8, 16, 32 Definido en:
TÉCNICO
Tamaño de los tiles de rasterización en píxeles. El renderizado Gaussian Splatting es basado en tiles: la imagen se divide en tiles de 16×16 píxeles, cada tile recopila los Gaussianos relevantes para él, los ordena por profundidad y los mezcla. 16 es el estándar que usan prácticamente todas las implementaciones 3DGS y está codificado en duro en los kernels Metal de RadianceKit; cambiar este valor requeriría recompilación del shader y no es efectivo en el estado actual. Se queda como campo por si una versión futura del engine soporta tamaño de tile dinámico.
T25throttleDelayMs
DETALLES
Predeterminado: 0 (initializer, .full, MCMC, Scene-Class), 0 (.preview) Rango: 0 – 100 Definido en:
TÉCNICO
Retardo artificial entre iteraciones de entrenamiento en milisegundos. 0 = a toda velocidad (predeterminado). Valores más altos hacen el Mac más "utilizable" durante el entrenamiento, al dar a GPU/CPU pausas regulares — la responsividad de otras apps mejora, pero el tiempo de entrenamiento crece linealmente con el retardo. Valores típicos: 1–2 ms ("throttling ligero", +5 % de tiempo de entrenamiento, el Mac se siente más responsivo), 5 ms ("medio", +15 %), 10+ ms ("eco", potencialmente el doble de tiempo de entrenamiento). Se ofrece en el Inspector bajo "Performance" pero no en la vista predeterminada — véase el backlog dev_ux-backlog.md que sugiere quitarlo de la Vista Experto porque, malinterpretado, extiende dramáticamente el tiempo de entrenamiento.
Diagnóstico y preparación de la nube de puntos (T26–T30)
T26depthDistortionWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,0001 – 0,05 Definido en:
TÉCNICO
V366 experimental: peso de un loss de regularización de distorsión de profundidad. Penaliza Gaussianos que, a lo largo de un rayo de render, están apilados en profundidad pero conceptualmente pertenecen a la misma superficie — esto anima a distribuciones de profundidad concentradas y reduce los floaters. Pruebas: 0,01 → 4,5 % peor, 0,001 → 8,1 % peor. La ventaja teórica — mejorar la consistencia multi-vista — no se ve en el loss L1, porque la hipótesis asume implícitamente que la geometría de SfM es correcta y los Gaussianos solo necesitan "apilarse". En la práctica, la nube de puntos SfM suele ser el componente más débil, no el apilado. Se mantiene disponible para datasets multi-vista con poses particularmente limpias (sintéticos, Mip-NeRF 360 con ground truth).
T27singleViewOverfit
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Flag diagnóstico: cuando es true, cada iteración de entrenamiento debe usar el índice de cámara 0 en lugar de uno aleatorio del pool de cámaras. Razón: si el modelo no es capaz ni siquiera de hacer overfit a una sola vista (es decir, el loss sobre la vista 0 no va a cero ni siquiera tras 10 000 iteraciones), hay un bug fundamental en el forward/backward pass. Este switch se usó intensivamente durante el desarrollo de los shaders Metal y los kernels del rasterizador diferenciable — fase V42–V47. Hoy solo disponible como chequeo de sanidad si alguien ha modificado código del backend y quiere hacer un test de regresión. Vía CLI con –single-view.
T28maxCameras
DETALLES
Predeterminado: 0 (= "usar todas las cámaras") Rango: 0 o 1 – N Definido en:
TÉCNICO
Límite diagnóstico de V43: entrenar solo con las primeras N cámaras, ignorar todas las demás. Razón original: probar la hipótesis de que demasiadas cámaras crean conflictos de gradiente (demasiadas señales de loss conflictivas para el mismo Gaussiano). Resultado de prueba: sin ventaja sistemática del limitado artificial — más frames aportan prácticamente siempre más calidad. Se queda como flag CLI (–max-cameras N) para experimentos dirigidos, p. ej., "¿funciona el entrenamiento en las primeras 100 imágenes de un vuelo de dron de 1 500?". No expuesto en la UI.
T29maxInitialPoints
DETALLES
Predeterminado: 0 (= "usar todos los puntos SfM") Rango: 0 o 1 000 – 200 000+ Definido en:
TÉCNICO
Red de seguridad V54: limita el número de puntos iniciales SfM con los que comienza el entrenamiento. Las reconstrucciones COLMAP densas pueden producir > 60 000 puntos, lo que con escalas iniciales grandes lleva a un solapamiento de 200–300 Gaussianos por píxel — esto crea un "campo de niebla" en el que el entrenamiento no converge. El submuestreo a ~16 000 puntos (lógica de hard-cap en el motor de entrenamiento) trae la densidad inicial al nivel usado por el 3DGS de referencia, y reduce dramáticamente el solapamiento. Se fija automáticamente con SfMs muy densos; vía CLI con –max-points N.
T30cameraClusterOutlierMultiplier
DETALLES
Predeterminado: 10,0 (todos los ajustes preestablecidos — nunca sobrescrito) Rango: 1,0 – 100,0 Definido en:
TÉCNICO
Multiplicador para el filtro de outliers del cluster de cámaras, introducido en la Fase 3.10 A.1. Antes del entrenamiento, el motor de entrenamiento calcula el centroide de todas las posiciones de cámara y la distancia máxima de cualquier cámara al centroide. Los puntos SfM cuya distancia al centroide supera multiplier × maxCameraDistance se descartan como outliers. El default 10× preserva el comportamiento previo a la Fase 3.10. Un bug sutil: SfM más apretado (cámaras más juntas) → más pequeña → umbral más pequeño → más puntos se descartan como outliers. SfM más holgado → umbral más grande → menos puntos descartados. Esta es una de las causas de la anti-correlación funnel-vs-training de la Fase 3.9: un mejor SfM puede llevar aguas abajo a peor entrenamiento porque se matan demasiados puntos iniciales. El campo está disponible como override CLI (–camera-cluster-outlier-multiplier) para los sweeps A.3; no expuesto en la UI. Los valores por debajo de 5 suelen ser demasiado restrictivos, por encima de 20 inefectivos.
Regularización (T31–T37)
T31coarseToFineBlurRadius
DETALLES
Predeterminado: 0 (= deshabilitado) Rango: 0 o 1 – 10 Definido en:
TÉCNICO
V369 experimental: radio de box blur aplicado al inicio de la fase de densificación a la imagen ground truth, reducido linealmente a 0 al final de la densificación (T2). Hipótesis: el entrenamiento coarse-to-fine — primero aprender estructuras gruesas, después detalles — debería dar geometría más estable. Pruebas: r=3 → 9,6 % peor, r=1 → 5,1 % peor. Razón del fallo: la densificación decide en base a gradientes en dominio de imagen, y el blur reduce exactamente las señales importantes para "hay que clonar aquí". Se queda en el catálogo de campos para pruebas futuras con un esquema distinto de density control.
T32scaleRegWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,0001 – 0,05 Definido en:
TÉCNICO
V370 experimental: regularización L1 sobre escala en espacio mundo. Penaliza Gaussianos que crecen demasiado — evita "mega splats" que cubren superficies enteras de pared con un solo Gaussiano. Pruebas: 0,01 → 200 % peor loss (2 M Gaussianos, explosión total), 0,001 → 214 % peor. Razón: la regularización de escala entra en conflicto con la density control — escalas más pequeñas significa que se necesitan más Gaussianos, así que la density control divide más a menudo, lo que a su vez significa más trabajo de gradiente. Deshabilitado, pero documentado para experimentos Mip-Splatting (T74): en ese contexto un límite inferior de escala podría tener sentido.
T33anisotropyRegWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,0001 – 0,05 Definido en:
TÉCNICO
V445 experimental: penalización sobre el cociente max(scale)/min(scale), pensada para evitar Gaussianos "aguja" extremadamente alargados que se perciben como floaters. Pruebas: 0,01 → 69 % peor, 0,001 → 15 % peor. Razón: la regularización fuerza a los splats a forma "redonda", lo que sobre una superficie plana (pared, mesa, suelo) es exactamente incorrecto — ahí un Gaussiano plano y ancho es más eficiente que uno esférico. Deshabilitado. V549f ofreció con T34 scaleRatioPruneThreshold un enfoque alternativo más dirigido, que también se revirtió.
T34scaleRatioPruneThreshold
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 5,0 – 100,0 (típicamente 10,0 – 30,0) Definido en:
TÉCNICO
Pruning post-training experimental que elimina cada Gaussiano cuyo ratio max(scale)/min(scale) supera el umbral lineal aquí fijado. Apunta a floaters "aguja/disco" extremadamente alargados que no se pueden eliminar solo con regularización. En pruebas, el pruning eliminó floaters como se esperaba, pero también splats planos útiles en paredes y suelos — la imagen se volvió más agujereada. De ahí off por defecto; el flag CLI (–scale-ratio-prune N) sigue para experimentos dirigidos. Valores recomendados si quieres probar: 30 (muy conservador, elimina solo outliers extremos), 10 (agresivo, cuesta detalle).
T35opacityRegWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,0001 – 0,05 Definido en:
TÉCNICO
V446 experimental: penalización de cross-entropy binaria que tira de la opacidad hacia 0 o 1 (es decir, lejos de "semi-transparente"). Hipótesis: una distribución de opacidad más nítida mejoraría la claridad de imagen. Probado combinado con T33 → la regularización cuesta calidad, ambos deshabilitados. Deshabilitado. Atención: en la beta 1.4.3 apareció un bug que tenía exactamente este campo con un valor default cambiado (initializer = 0,01), lo que llevó a la extinción masiva del número de Gaussianos (460 K → 5 en una iteración). Desde 1.4.4 fijado en duro a 0,0 como default.
T36opacityDecayFactor
DETALLES
Predeterminado: 0,0 (initializer = deshabilitado), 0,9995 (.full, .classicBalanced — estándar HTGS) Rango: 0 (off) o 0,95 – 1,0 Definido en:
TÉCNICO
Implementación V546 del esquema HTGS (Hierarchical Time-Gating, Eurographics 2025): cada T37 opacityDecayInterval iteraciones la opacidad sigmoide de cada Gaussiano se multiplica por este factor. 0,9995 × 100 aplicaciones dan ~95 % residual por fase de densificación — una presión a la baja ligera pero constante sobre todas las opacidades, que deja caer de forma fiable a los Gaussianos que aportan poco por debajo del T14 pruneOpacityThreshold. El resultado: 14 % mejor loss L1 en Horse Full (3-trial avg V546) vs V438 sin decay. Activo solo durante la fase de densificación (hasta T2), después el entrenamiento sigue sin decay, así que las opacidades establecidas durante refinamiento se mantienen estables. No se usa bajo MCMC (MCMC tiene sus propios mecanismos vía T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold).
T37opacityDecayInterval
DETALLES
Predeterminado: 50 Rango: 10 – 500 Definido en:
TÉCNICO
Intervalo de iteraciones al que se aplica T36 opacityDecayFactor. Default del paper HTGS 50, dejado así en .full. Intervalos largos (>200) cancelan parcialmente el efecto porque entre dos aplicaciones ocurren suficientes actualizaciones de gradiente como para que la opacidad vuelva a subir. Intervalos más cortos (<20) hacen el decay demasiado agresivo. Activo solo en la fase de densificación.
Refinamiento (T38–T44)
T38gradientAccumulationSteps
DETALLES
Predeterminado: 1 (= "una vista por paso Adam") Rango: 1 – 8 Definido en:
TÉCNICO
Función V424: número de vistas cuyos gradientes se acumulan antes de que corra una actualización de Adam. Con > 1 la app corre por una vía backward project "unfused" separada que suma los gradientes a un buffer separado; la aplicación final escala por 1/N para mantener la magnitud constante. V424 probó 2-vistas → neutro para calidad pero 10 % más lento (porque unfused es más caro que fused). Revertido para .full pero usado deliberadamente para MCMC — .fullMCMC corre con, pero los tests V544a mostraron que con el gap de calidad respecto a Classic se encoge a 5 % (en lugar de 11 %). En el default initializer 1, en el preset actual 1, queda como flag CLI (–accum-steps N).
T39testViewIndices
DETALLES
Predeterminado: [] (= vacío, todas las vistas se usan para entrenamiento) Rango: Set<Int>, subconjunto arbitrario de índices de cámara Definido en:
TÉCNICO
Función V546: conjunto de índices de cámara que NO se usan para entrenamiento sino que se guardan como holdout para evaluación PSNR/SSIM/LPIPS. Se fija automáticamente cuando el flag CLI –benchmark está activo: entonces cada 8ª vista empezando por el índice 0 (estándar LLFF, idéntico a las convenciones Mip-NeRF 360 y del paper 3DGS). Sin benchmark vacío — el entrenamiento usa todas las vistas. Atención: fijar manualmente este campo sin entender los índices puede inutilizar el benchmark (p. ej., cuando todos los índices están por encima de N mientras hay solo N-50 vistas → sin holdouts → sin evaluación). Cuando exportas tu propio ajuste preestablecido, testViewIndices no se persiste porque es dependiente de la escena y en otro caso dejaría valores sin sentido entre datasets distintos.
T40refinementPruneInterval
DETALLES
Predeterminado: 0 (= deshabilitado) Rango: 0 o 100 – 5 000 Definido en:
TÉCNICO
Función V425: cada N iteraciones durante la fase de refinamiento (tras T2) corre una pasada de prune adicional que elimina Gaussianos con sigmoid(opacity) < T41 refinementPruneOpacityThreshold. Razón: durante la densificación hay llamadas regulares de density control, después ya no — pero los Gaussianos cuya opacidad sigue cayendo se quedan en el buffer. V425 probado y revertido: el pruning adicional correlacionaba con V426 (Densificación de Dos Fases, que también acabó en un cascade failure de 0 Gaussianos). Deshabilitado. Flag CLI disponible para experimentos; si está habilitado, 1 000 o 2 000 son valores sensatos.
T41refinementPruneOpacityThreshold
DETALLES
Predeterminado: 0,0 (= "usar T14") Rango: 0 o 0,001 – 0,1 Definido en:
TÉCNICO
V425b: umbral de opacidad separado para el pruning de refinamiento. Tras la densificación, la mayoría de los Gaussianos han alcanzado una opacidad claramente más alta (> 0,001), por lo que el default T14 pruneOpacityThreshold sería demasiado laxo. Si T40 está activo, este campo determina su propio umbral. En 0,0 se usa T14 como antes. Solo relevante si T40 > 0.
T42midTrainingCompactificationIterations
DETALLES
Predeterminado: [] (= deshabilitado) Rango: [Int], valores en (densifyUntilIteration, maxIterations) Definido en:
TÉCNICO
Función V549: puntos de iteración explícitos durante la fase de refinamiento en los que corre una pasada de compactificación (elimina sigmoid(opacity) < 0,01 + Gaussianos de escala outlier, misma lógica que T56 postTrainingCompactification). Razón: las fases de refinamiento largas pueden mostrar acumulación de confeti/ floaters, cuyo SH luego sobreajusta a artefactos específicos de vista. Configuración típica si está habilitado: [10000, 20000, 30000] para 40K Classic. PERO: los tests A/B V549 sobre el dataset Family mostraron peor L1 en todas las configuraciones: [10K,20K,30K]@0.01 → −48 % count pero +36 % L1; [20K,30K]@0.005 → −44 % count pero +45 % L1; [20K,30K]@0.001 → −17 % count pero +87 % L1. De ahí deshabilitado. Flag CLI –mid-compact "10000,20000" disponible, si prefieres el trade-off visual de floaters (menos confeti en la vista) sobre la regresión de loss.
T43frustumCullEnabled
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función V549b: tras el entrenamiento, todos los Gaussianos fuera de la unión de todos los frustums de cámara de entrenamiento se eliminan. Esos Gaussianos nunca estuvieron restringidos por la señal de loss y son siempre floaters. Particularmente efectivo para escenas en las que la novel view está detrás o al lado del recorrido de la cámara (p. ej., detrás de un vuelo de dron lineal) — los floaters allí nunca son visibles durante el entrenamiento pero sí más tarde al moverse en el visor 3D. A/B V549b en vuelos de dron mostró resultados positivos, de ahí disponible como opt-in. Default false porque para capturas de objeto con cobertura orbital completa la unión de frustums abarca toda la escena y la función no elimina nada — se ofrece en Settings bajo "Floater Reduction" y también se prueba implícitamente en el preset Q9 Outdoor vía T44 frustumCullExpansion (Q7 BayesOpt no lo habilitó, porque la cúpula de cielo outdoor resuelve mejor el mismo problema).
T44frustumCullExpansion
DETALLES
Predeterminado: 1,1 Rango: 1,0 – 2,0 Definido en:
TÉCNICO
Margen NDC para T43 frustumCullEnabled. 1,0 cortaría exactamente en el borde de imagen, lo que recortaría splats tambaleantes cerca del borde de manera demasiado agresiva. 1,1 = 10 % de padding más allá del encuadre exacto de la cámara — da algo de tolerancia para píxeles de borde que aún podrían ser visibles en una novel view ligeramente desplazada. Valores > 1,2 hacen el cull prácticamente inefectivo porque el frustum expandido abarca demasiado espacio.
Sky Dome (T45–T48)
T45skyDomeEnabled
DETALLES
Predeterminado: false (initializer + todos los ajustes preestablecidos excepto P9 Outdoor) Rango: booleano Definido en:
TÉCNICO
Función V549e: antes de iniciar el entrenamiento se genera una nube de puntos esférica (esfera Fibonacci con T46 puntos de muestra), se coloca a un radio de T47 skyDomeRadiusMultiplier × scene_extent alrededor del centro de la escena y se inicializa con los colores de los píxeles enmascarados como cielo de todas las cámaras de entrenamiento (véase T20 skyMaskingEnabled). Estos Gaussianos de sky dome se insertan al inicio del buffer Gaussiano y durante el entrenamiento están "congelados" (gradientes position/scale/rotation = 0, solo SH y opacidad permanecen optimizables). Efecto: en lugar de áreas negras de "confeti" a la distancia, el usuario ve un cielo real en novel views. El MVP V549e funciona muy bien en escenas de dron y paisaje; en el preset P9 Outdoor activado por defecto. Déjalo off para escenas interiores — la esfera colgaría inútil fuera de la habitación.
T46skyDomeSampleCount
DETALLES
Predeterminado: 5 000 Rango: 1 000 – 50 000 (típico 2 000 – 10 000) Definido en:
TÉCNICO
Número de puntos de muestra esfera Fibonacci sobre la esfera de la cúpula de cielo. Valores más altos → cúpula más densa (mejor a resoluciones grandes y mucho cielo visible), pero mayor consumo de memoria. 5 000 es el sweet spot para renderizados 4K; a resoluciones más bajas, 2 000–3 000 bastan. Los puntos se inicializan por distancia coseno a cada vector de vista de cámara de entrenamiento con los correspondientes píxeles enmascarados como cielo — los puntos de muestra cuyo cono de vista no es visto por ninguna cámara mantienen un valor inicial de opacidad bajo, pero permanecen sin cambios durante el entrenamiento (congelados).
T47skyDomeRadiusMultiplier
DETALLES
Predeterminado: 30,0 (initializer + la mayoría de ajustes preestablecidos), 59,0 (P9 Outdoor, óptimo Q7 BayesOpt) Rango: 5,0 – 200,0 Definido en:
TÉCNICO
Radio de la esfera de la cúpula de cielo relativo a la extensión de la escena (= distancia media entre posiciones de cámara). 30 = la esfera tiene 30× el diámetro de la nube de cámaras. Demasiado pequeña (< 5) → la cúpula interfiere con la propia escena (p. ej., un splat de cúpula aterriza en primer plano); demasiado grande (> 100) → pérdida de precisión float32 en las posiciones de cúpula, lo que dispara fallos de render a la distancia. Q7 BayesOpt en Bicycle (Mip-NeRF 360) encontró 59,0 como óptimo específico de escena para outdoor — esto sugiere que el default 30,0 es demasiado pequeño para paisajes profundos y que los píxeles de cúpula renderizan visiblemente como una "pared" en regiones de borde de imagen.
T48frozenGaussianCount
DETALLES
Predeterminado: 0 (= sin Gaussianos congelados) Rango: 0 o 1 – T46 Definido en:
TÉCNICO
Número de Gaussianos al inicio del buffer cuyos gradientes position/scale/rotation se ponen a cero en el optimizador — permanecen espacialmente rígidos durante todo el entrenamiento. La density control no puede clonarlos, dividirlos ni podarlos. Usado para la inyección de cúpula de cielo (véase T45): cuando la cúpula está on, este campo se fija automáticamente a T46 skyDomeSampleCount. La fijación manual es posible (p. ej., para congelar una nube de puntos pre-colocada desde un escaneo LiDAR), pero no es directamente accesible en la UI. Importante: los primeros N Gaussianos en el buffer son siempre los congelados — el orden en el buffer decide, no un índice explícito.
Adam + schedule de LR (T49–T55)
T49adamResetIteration
DETALLES
Predeterminado: 0 (= deshabilitado) Rango: 0 o 100 – Definido en:
TÉCNICO
Función V430: iteración en la que los acumuladores de momentum (m1, m2) del optimizador Adam se resetean a cero. La corrección de sesgo posterior corre con (iter - adamResetIteration) en lugar de iter. V430 probó reset en 5 000 (tras el fin de densificación) → loss 12,8 % peor. Razón: el momentum de Adam que se acumuló durante la densificación lleva información sobre las magnitudes de gradiente típicas y acelera la fase de refinamiento. Tirarlo cuesta las primeras ~500 iteraciones de refinamiento en convergencia. Deshabilitado. Se queda como flag CLI para experimentos de investigación.
T50positionLRScheduleEndIteration
DETALLES
Predeterminado: 0 (initializer = "usar maxIterations"), 20 000 (.full — cosine termina en 20K aunque maxIter=35K), 30 000 (.fullClassicPaper) Rango: 0 o 1 000 – Definido en:
TÉCNICO
Función V431: iteración en la que la curva cosine annealing para la LR de posición alcanza su mínimo. Si 0, es idéntico a T1 maxIterations. Si > 0, el schedule corre hasta este valor y se mantiene constante en T4 positionLearningRateFinal después. Esto permite una "fase de refinamiento extendida" con learning rate mínima pero constante — refina posiciones despacio sin un nuevo decay. .full lo hace (el schedule termina en 20K, el entrenamiento corre hasta 35K), V434c/V434d confirmaron: 15K y 25K ambos por igual, 20K marginalmente óptimo. Usado junto con T51 para modificar también las LRs no-posición en la fase extendida.
T51extendedPhaseLRDecay
DETALLES
Predeterminado: 0,0 (= deshabilitado, LRs constantes) Rango: 0 o 0,01 – 1,0 Definido en:
TÉCNICO
Función V433: multiplicador mínimo para las LRs no-posición (escala, rotación, opacidad, SH) en la "fase extendida" — es decir, tras alcanzar T50 y la LR de posición ya en T4. Si 0,1, scale/rotation/opacity/SH se decaen ellas mismas en cosine de 1,0 (= su LR estándar) a 0,1× de su estándar. Si 0,0 (default), permanecen constantes. V457 probó decay completo (0,0, es decir, decay a cero) contra sin decay y encontró: avg 0,0400 (2 runs), el mismo loss que V438 sin decay. Comportamiento más limpio con decay pero no medible mejor. De ahí deshabilitado. Se queda en la CLI como –nonpos-lr-scale F.
T52adaptiveDensifyThreshold
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
V440 experimental: cuando es true, la app calcula en cada paso de densificación el p98 de la distribución actual de gradientes y lo usa como umbral dinámico (clamped a al menos 0,5× del valor configurado de T11 para que no derive demasiado). Hipótesis: la adaptación automática a la fase actual de la escena haría la density control más robusta — p. ej., poda más estricta al principio, más laxa después, o viceversa. V440 probado y revertido: caída catastrófica a 63 K Gaussianos (pruning masivo, porque el p98 en las primeras iteraciones es extremadamente alto y después casi nada supera el umbral). El umbral fijo está ya bien calibrado, el ajuste dinámico hace más daño que bien. Q5 (T77) ofrece una lógica adaptativa alternativa vía mediana rodante que evita el problema.
T53mergeAfterDensification
DETALLES
Predeterminado: false (initializer), true (.full, .classicBalanced, .fullClassicPaper) Rango: booleano Definido en:
TÉCNICO
Función V438: al final de la fase de densificación (iter T2) corre una pasada de merge única que combina Gaussianos cercanos con escala y color similares. Reduce el número de Gaussianos típicamente un 5–15 % sin pérdida visible de calidad. Razón: tras el intenso clonado, surgen clusters de Gaussianos casi idénticos que no aportan nada nuevo — mergearlos libera capacidad de optimizador para otras áreas. Por defecto en los ajustes preestablecidos Classic Quality. No usado bajo MCMC, porque MCMC mediante su lógica de relocalización no deja que esos clusters se formen en primer lugar.
T54densifyPhase2FromIteration
DETALLES
Predeterminado: 0 (= deshabilitado) Rango: 0 o T2 – T1 Definido en:
TÉCNICO
V426 experimental: habilita una segunda fase de densificación que comienza tras la pausa de refinamiento en esta iteración y corre hasta T55. Hipótesis: tras una fase de refinamiento los acumuladores de gradiente tienen magnitudes más estables y pueden indicar con más precisión qué regiones aún necesitan Gaussianos adicionales. V426 probado y revertido: la densificación de dos fases cayó en cascade failure de 0 Gaussianos (combinada con el pruning de refinamiento V425 destruyó el buffer). Deshabilitado. Flag CLI disponible para experimentos.
T55densifyPhase2UntilIteration
DETALLES
Predeterminado: 0 Rango: 0 o T54 – T1 Definido en:
TÉCNICO
Fin de la densificación de dos fases V426. Solo relevante cuando T54 > 0. Ambos campos juntos deshabilitados.
Post-procesado + Apple AI (T56–T60)
T56postTrainingCompactification
DETALLES
Predeterminado: true (en todos los ajustes preestablecidos de producción), false (.quickTest, .preview) Rango: booleano Definido en:
TÉCNICO
Función V443: tras terminar el entrenamiento, los Gaussianos con sigmoid(opacity) < 0,01 se eliminan en duro (prácticamente ya no contribuyen a la imagen). Reduce el número de Gaussianos típicamente un 58 % y el tamaño del archivo de exportación un 55 % sin pérdida visible de calidad. On por defecto en ajustes preestablecidos de producción — el resultado final debería entregarse lo más compacto posible. Off en .quickTest, porque un run diagnóstico no se exporta de todos modos. A diferencia de T42 midTrainingCompactificationIterations (V549), la compactificación solo ocurre al final — el refinamiento puede usar todos los Gaussianos hasta entonces.
T57metalFXUpscaling
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función V444: habilita el Apple MetalFX Spatial Upscaler en lugar de interpolación bilineal en la salida del visor 3D. Cuando la resolución de entrenamiento < tamaño de la vista (p. ej., entrenando a 0,5×, visualización de vista a resolución completa), MetalFX puede entregar una imagen claramente más nítida. Cambia en vivo en la vista, no se requiere reentrenar. Mutuamente exclusivo con T58 mpsLanczosScaling — MetalFX tiene prioridad. Recomendación: habilitar cuando la imagen en el visor parece "deslavada" comparada con el detalle esperado.
T58mpsLanczosScaling
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función V444: MPSImageLanczosScale para el escalado de vista en lugar de interpolación bilineal. Lanczos es un método de resampling basado en sinc clásico que entrega resultados significativamente más nítidos que bilineal con overhead mínimo. Conmutador en vivo. Sobrescrito por T57 cuando ambos están on.
T59livePreviewInterval
DETALLES
Predeterminado: 50 (initializer y la mayoría de ajustes preestablecidos) Rango: 0 (off) o 10 – 5 000 Definido en:
TÉCNICO
Cada cuánto se refresca el visor 3D durante el entrenamiento con los Gaussianos actuales. 50 = cada 50 iteraciones un nuevo render en el visor — suficiente para observar el progreso sin ralentizar el entrenamiento. 0 = el visor no se actualiza en absoluto (entrenamiento en segundo plano, velocidad máxima). Ajuste típico: bajo .quickTest bajarlo a 10 (quieres ver cada paso), en runs MCMC largos subirlo a 500–2000 (el overhead de actualización suma a ratos).
T60perceptualLossWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado) Rango: 0 o 0,001 – 0,5 Definido en:
TÉCNICO
Función futura V444: peso de un término de perceptual loss vía MPSGraph (red pequeña tipo VGG). Capturaría similitud estructural y textural a un nivel semántico más alto que L1+SSIM — típico en pipelines de investigación donde "píxel-perfecto" importa menos que "se ve realista". Implementación pendiente (stub de código presente, pero el forward pass no implementado). Predeterminado 0,0. Se queda en el catálogo de campos para activación futura; flag CLI –percep-weight F reservado.
Densificación MCMC (T61–T73)
T61densificationStrategy
DETALLES
Predeterminado: .classic (initializer + ajustes Classic), .mcmc (todos los ajustes preestablecidos MCMC + Scene-Class) Rango: .classic o .mcmc Definido en:
TÉCNICO
Elige entre densificación clásica (clone/split/prune, Kerbl et al. 2023) y densificación MCMC (Stochastic Gradient Langevin Dynamics con relocalización, Kheradmand et al. NeurIPS 2024). Con .classic se evalúan T11–T16, con .mcmc los T62–T73. Cuidado al cambiar: los defaults Classic y MCMC están calibrados de forma completamente distinta — quien gire el selector en la Vista Experto sin cargar un ajuste preestablecido coincidente arriesga una extinción masiva tipo bug-1.4.3 (460 K → 5 en una iteración, porque el opacity reg 0,01 de MCMC mata las opacidades Classic). De ahí que los defaults del initializer MCMC estén deliberadamente "soft-washed" (todos los valores reg 0,0).
T62mcmcMaxGaussians
DETALLES
Predeterminado: 150 000 (initializer + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — variante Mip-Splatting con presupuesto 10×), 1,19 M (.renderPreset), 1,25 M (.outdoorPreset), 670 K (.indoorPreset) Rango: 0 (= "usar capacidad de buffer") o 10 000 – 5 000 000 Definido en:
TÉCNICO
Cota superior dura para el número de Gaussianos bajo estrategia MCMC. El número crece gradualmente por T70 mcmcGrowthRate (típicamente 5 %) por paso de relocalización hasta este tope. V473/V531 encontraron 150 K como sweet spot — por encima de 200 K diluye la calidad del splat (demasiados Gaussianos redundantes pequeños), por debajo de 100 K deja la escena sub-densificada. Con escenas muy grandes (p. ej., vuelo de dron de 1 545 fotos con 158 K init SfM), 150 K es demasiado bajo — de ahí la extensión 1.4.5 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7 BayesOpt encontró óptimos específicos de escena entre 670 K (Indoor) y 1,25 M (Outdoor). Con valor 0, el engine usa la capacidad completa del buffer como tope.
T63mcmcNoiseScale
DETALLES
Predeterminado: 0,00005 (5e-5 = default del paper) Rango: 1e-6 – 1e-3 Definido en:
TÉCNICO
Multiplicador para el ruido Gaussiano que en cada iteración MCMC se añade a la posición de cada Gaussiano (lógica SGLD). Más alto = más exploración (los Gaussianos vagan más, encontrando puntos potencialmente mejores), más bajo = más explotación (los Gaussianos se quedan donde ya están bien). V467 y V536 confirmaron 5e-5 como óptimo — 1e-5/2e-5 demasiado poca exploración, 1e-4 demasiada (los splats se difunden). Cosine-decayed sobre el tiempo de entrenamiento hasta T69 mcmcNoiseDecayEnd — al final del rango de decay, el ruido es efectivamente 0 y los Gaussianos convergen.
T64mcmcOpacityRegWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado en defaults de RadianceKit, paper: 0,01) Rango: 0 o 0,001 – 0,05 Definido en:
TÉCNICO
Penalización L1 específica de MCMC sobre la opacidad. Default del paper 0,01 (empuja los Gaussianos no usados hacia cero, los hace disponibles para relocalización). V464b mostró sin embargo: sin reg es medible mejor en RadianceKit (Sesión 28 confirmado). Razón: el criterio de pruning definido con T68 mcmcDeadOpacityThreshold es suficiente por sí solo — una penalización L1 adicional también fuerza a Gaussianos valiosos de baja opacidad a morir. De ahí default 0. Atención: en el build beta 1.4.3 el default del initializer estaba erróneamente en 0,01, lo que resultó en el bug de extinción masiva (véase explicación T61); desde 1.4.4 fijado a 0,0.
T65mcmcScaleRegWeight
DETALLES
Predeterminado: 0,0 (= deshabilitado, paper: 0,01) Rango: 0 o 0,001 – 0,05 Definido en:
TÉCNICO
Penalización L1 específica de MCMC sobre los autovalores de escala. Default del paper 0,01. V464b: sin reg mejor, mismo razonamiento que T64. Deshabilitado en todos los ajustes preestablecidos MCMC de RadianceKit. Misma precaución que T64: bug 1.4.3.
T66mcmcRelocationInterval
DETALLES
Predeterminado: 100 (initializer + todos los ajustes preestablecidos MCMC, estándar del paper), 155 (P9 Outdoor — óptimo Q7 BayesOpt) Rango: 50 – 500 Definido en:
TÉCNICO
Intervalo de iteraciones en el que MCMC reubica los Gaussianos muertos (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) a nuevas posiciones. V537 probó 50 (demasiado disruptivo, el loss fluctúa) y 200 (marginalmente peor, MCMC pierde responsividad). 100 es óptimo. Q7 BayesOpt en Bicycle encontró 155 como óptimo específico de escena para outdoor — los intervalos ligeramente más largos dan a Adam más tiempo para integrar los Gaussianos recién colocados antes de que el siguiente evento reloc los ponga bajo presión.
T67mcmcWarmupIterations
DETALLES
Predeterminado: 500 Rango: 100 – 5 000 Definido en:
TÉCNICO
Número de iteraciones iniciales durante las que no ocurre relocalización MCMC. Solo tras este warmup entra en acción la lógica de reloc. Razón: en las primeras iteraciones los valores de opacidad no se han estabilizado — si reloc empezara directamente, los Gaussianos serían colocados en sitios equivocados y tendrían que moverse de nuevo enseguida, lo que destruiría el momentum de Adam. Default del paper 500. RadianceKit adopta este valor porque V464b mostró que es robusto.
T68mcmcDeadOpacityThreshold
DETALLES
Predeterminado: 0,005 (initializer, estándar del paper), 0,01 (.fullMCMC y todos los ajustes preestablecidos MCMC — óptimo V535) Rango: 0,001 – 0,05 Definido en:
TÉCNICO
Umbral sigmoid(opacity) por debajo del cual un Gaussiano cuenta como "muerto" y es elegible para relocalización. V535 encontró 0,01 como óptimo (0,005 marginal, 0,02 peor). Más alto = reloc más agresivo (más Gaussianos movidos), más bajo = más cauteloso. 0,01 corresponde aproximadamente a "0,5 % de visibilidad visual". P10 Indoor usa 0,0142 como óptimo vía Q7 BayesOpt.
T69mcmcNoiseDecayEnd
DETALLES
Predeterminado: 0 (initializer = "sin decay"), 160 000 (.fullMCMC = 80 % de 200K), 96 000 (.mcmcBalanced = 80 % de 120K), 40 000 (.mcmcPreview) Rango: 0 o 1 000 – Definido en:
TÉCNICO
Iteración en la que el ruido T63 mcmcNoiseScale se amortigua del todo a cero (cosine decay desde iter 0 hasta aquí). V497c/V502 encontraron 80 % de maxIterations como óptimo — da a MCMC suficiente tiempo de exploración pero deja el último 20 % a la convergencia sin ruido. 0 = ruido constante sobre todas las iteraciones (rara vez sensato, MCMC no puede converger entonces).
T70mcmcGrowthRate
DETALLES
Predeterminado: 0,05 (estándar del paper = 5 %) Rango: 0,01 – 0,2 Definido en:
TÉCNICO
Tasa de crecimiento del tamaño objetivo de la población MCMC por paso de relocalización. La lógica: en cada evento reloc el tamaño objetivo de población se multiplica por (1 + growthRate), hasta alcanzar T62 mcmcMaxGaussians (o la variante escalada vía T72/T73). V512/V522 encontraron 0,05 como óptimo — valores más altos llevan a crecimiento demasiado rápido (los Gaussianos se insertan antes de que el momentum de Adam pueda integrarlos), valores más bajos a escenas sub-densificadas al final.
T71mcmcSigmoidK
DETALLES
Predeterminado: 100,0 Rango: 10,0 – 500,0 Definido en:
TÉCNICO
Parámetro de nitidez sigmoide para la atenuación de ruido MCMC. En el paso SGLD, el ruido por Gaussiano se amortigua por — los Gaussianos de alta opacidad (cuyo logit es positivo) reciben exponencialmente menos ruido que los de baja opacidad. K = 100 es nítido, significa que la transición de "ruido pleno" a "sin ruido" ocurre muy rápido en torno a opacidad 0,5. V484–V487 encontraron K = 100 como óptimo — valores más pequeños (10–50) también dejan tambalearse a los Gaussianos de alta opacidad (destruye los convergidos), los más grandes (> 500) hacen la transición artificialmente dura y los Gaussianos muertos ya no se mueven en absoluto.
T72mcmcCapMultiplier
DETALLES
Predeterminado: 3,0 (initializer + .fullMCMC), 2,0 (.mcmcPreview), 2,5 (.mcmcBalanced), 2,98 (P8 Render), 5,32 (P9 Outdoor), 1,76 (P10 Indoor) Rango: 0 (= deshabilitado) o 1,0 – 10,0 Definido en:
TÉCNICO
Función 1.4.5: escalado de tope consciente de la escena. Cuando T73 mcmcAutoScaleByScene es true, el tope efectivo se calcula como (clamped a la capacidad del buffer). Contexto: con escenas grandes (p. ej., vuelo de dron de 1 545 fotos → 158 K SfM init), T62 = 150 000 es demasiado bajo — la density control no podría crecer en absoluto. Con multiplicador 3,0, el tope se escala a 474 K en este ejemplo (158 K × 3,0). Q7 BayesOpt encontró óptimos específicos de escena: outdoor se beneficia de un multiplicador alto (5,32 → ~830 K de tope con 156 K bicycle init), indoor se contenta con 1,76 (las paredes saturan más rápido). Para la resolución completa del tope véase el método.
T73mcmcAutoScaleByScene
DETALLES
Predeterminado: true (initializer + todos los ajustes preestablecidos MCMC) Rango: booleano Definido en:
TÉCNICO
Función 1.4.5: interruptor maestro para la lógica de tope consciente de la escena (véase T72 +). Cuando es false, solo se usa T62 mcmcMaxGaussians como tope (vuelta al comportamiento 1.4.4). On por defecto porque los problemas de extinción masiva con escenas grandes desde 1.4.3 volverían en otro caso. Deshabilítalo manualmente solo cuando quieras fijar explícitamente un tope duro — p. ej., para entrenar una variante 150 K cuyo tamaño final sea planificable.
Mip-Splatting (Q1.5) (T74–T76)
Estado: Q1.5 fue rechazado el 2026-05-25 tras 14 iteraciones autónomas + comprobación nocturna de confianza con 1,5 M como "closed no-win" (max Δ@2× = +0,27 dB, la puerta original requería ≥ +1,5 dB de media sobre 0,5×/2×, FALLA en 0/11 escenas pareadas). Los campos permanecen opt-in para experimentos de investigación; todos los ajustes preestablecidos de producción los tienen off. Véase el veredicto:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
DETALLES
Predeterminado: false (todos los ajustes de producción), true (.fullMCMCMip — hermano de investigación) Rango: booleano Definido en:
TÉCNICO
Habilita Mip-Splatting (Yu et al. CVPR 2024): filtro de suavizado 3D + filtro 2D + compensación α que limita la frecuencia por Gaussiano al bound de Nyquist de la tasa de muestreo de cámara de entrenamiento más densa. Objetivo teórico: eliminar aliasing al renderizar a escalas distintas del entrenamiento (0,5× o 2× de la resolución de entrenamiento). Habilitado en los shaders de preprocess y backward projection, corrección funcional verificada en el test Q1.5-D. Pero: la puerta de aceptación original (Δ@1× ≥ +0,3 dB Y avg(Δ@0,5×, Δ@2×) ≥ +1,5 dB) no se alcanzó en ninguna de las 11 escenas pareadas. Máximo observado: family 750K classic Δ@2× = +0,270 dB. Las escenas outdoor (Truck, Flowers) incluso mostraron empeoramiento en 1× y 0,5×. Hipótesis: el suavizado 3D compite con la relocalización MCMC a Gs alto. El campo se mantiene para una reevaluación multi-escala futura con metodología correcta Mip-NeRF-360 (véase el backlog O3 en la ruta de benchmark).
T75mipSmoothing3DScale
DETALLES
Predeterminado: 0,2 (default del paper) Rango: 0,05 – 1,0 Definido en:
TÉCNICO
Parámetro de escala de suavizado 3D (Yu et al. §3.3, default del paper 0,2). Más grande = más suavizado en espacio mundo por Gaussiano (= más anti-aliasing pero también más blur a la escala default), más pequeño = más nítido pero más propenso a aliasing. Solo se consulta cuando T74 useMipSplatting = true. No se ha optimizado más en las pruebas Q1.5 — la puerta A/B ya se perdió con el default del paper 0,2, sweeps adicionales serían inútiles.
T76mipFilter2DVariance
DETALLES
Predeterminado: 0,3 (= exactamente el comportamiento legacy V242) Rango: 0,1 – 1,0 Definido en:
TÉCNICO
Varianza del filtro 2D Mip añadida a la diagonal Σ_2D (varianza directamente, no al cuadrado). 0,3 es exactamente el valor legacy V242 que estaba codificado en duro en el kernel antes de Mip-Splatting. Cuando T74 useMipSplatting = false, el kernel ignora este valor por completo y escribe el 0,3 codificado — para que la línea base no pueda regresar (garantía S3-1 ronda 1 de Codex). Cuando, se usa el valor aquí fijado. Se queda en el catálogo de campos para sweeps Mip.
Densificación adaptativa (Q5) (T77–T79)
T77adaptiveDensification
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función Q5: tracker de mediana rodante como alternativa al T11 densifyGradThreshold fijo. Cuando es true, en cada paso de densify, el umbral actual se sobrescribe con median(últimas N muestras avgGrad) × T79 adaptiveDensifyMultiplier. N = T78 adaptiveWindow. Más estricto que el V440 p98 (la trampa catastrófica de pruning a 63 K), median + 2× se sitúa en torno al p70–p80 de la distribución de gradientes en estado estable. Pruebas Q5: sola FALLA 0/3 escenas, pero junto con Q6 (véase T80/T81) PASA 1/3 escenas — el bundle Q5+Q6 pasó el 2026-05-25 como opt-in y se habilita vía CLI –adaptive-densify. Q6 es el "portador" de la ganancia de calidad, Q5 contribuye más a la estabilidad.
T78adaptiveWindow
DETALLES
Predeterminado: 1 000 Rango: 100 – 10 000 Definido en:
TÉCNICO
Ventana de mediana rodante en eventos de densificación (NO iteraciones — cada paso T13 densifyInterval da una muestra). Default 1 000 — con eso, las últimas 100 000 iteraciones de entrenamiento contribuyen a la mediana, así que típicamente toda la historia de entrenamiento hasta aquí. Fase temprana (antes de T78 muestras): el tracker devuelve nil → fallback al umbral fijo T11. Solo relevante cuando.
T79adaptiveDensifyMultiplier
DETALLES
Predeterminado: 2,0 Rango: 1,0 – 4,0 Definido en:
TÉCNICO
Multiplicador sobre la mediana rodante para el umbral adaptativo. Default 2,0 corresponde aproximadamente al p70–p80 de la distribución típica de gradientes. Más bajo = crecimiento más agresivo (más clones), más alto = más estricto (menos clones). Pruebas Q5 en rango 1,5–3,0 — 2,0 mejor default. Solo relevante cuando.
Currículum (Q6) (T80–T81)
T80curriculumResolutionRamp
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función Q6: la resolución de entrenamiento empieza en 0,5× y cambia en T50 positionLRScheduleEndIteration / 2 (o T1 maxIterations / 2, si T50 no está fijado) a T22 trainingRenderScale. Usa la infraestructura resize/restoreImageBuffers desarrollada en Q1.5.1. Sobrescribe T23 resolutionWarmupScale cuando está habilitado. Q6 pasó como "portador de la ganancia de calidad" en el bundle Q5+Q6 (véase T77) — el aumento gradual de resolución da a la app tiempo para encontrar la geometría gruesa a menor resolución antes de pasar al trabajo de detalle fino. Vía CLI: –curriculum-resolution.
T81curriculumSHProgression
DETALLES
Predeterminado: false Rango: booleano Definido en:
TÉCNICO
Función Q6: sobrescribe T21 shDegreeUpgradeIterations con [maxIter/4, maxIter/2, maxIter*3/4], distribuyendo los upgrades SH de forma uniforme a lo largo del tiempo de entrenamiento en lugar de cargarlos al principio. Hipótesis: una geometría estable se establece antes de la explosión de detalle de color, lo que coloca con más precisión los efectos de brillo dependientes de la dirección de visión. Q5+Q6 juntos PASAN 1/3 escenas, Q6 como portador de la ganancia (Q5 sola FALLA). Vía CLI: –curriculum-sh.
Ajustes preestablecidos estáticos (TP1–TP9)
Aquí solo las diferencias estructurales respecto al default del initializer. La descripción completa de marketing de los diez ajustes preestablecidos UI P1–P10 está en el Capítulo 7.
TP1.preview
DETALLES
Ajuste preestablecido diagnóstico/previsualización para sistemas ≥ 10 GB de RAM. Overrides vs. initializer: - 30 000 → 5 000 - 15 000 → 3 500 (70 % de maxIter) - 1,6e-6 → 1,6e-5 (10× más alto, decay menos agresivo) -,,,, cada 2× (V176) - 3 000 → 100 000 (efectivamente off, V172: el reset destruye entrenamientos cortos) - [1K, 2K, 3K] → [1K, 2K] (V182: el grado 3 no converge en 2K iter) - 1,0 → 0,5
TP2.full
DETALLES
Producción Quality Classic. Overrides: - 30 000 → 35 000 (V550: pruebas 40K Truck overtraining +10,7 % Gs con -1,3 % L1) - 15 000 → 5 000 (V310 sweet spot, V338 7K peor) - Todas las LRs 2× (V188) - 1,6e-6 → 1,6e-5 (V45 10×) - 2e-6 → 1,1e-6 (V335) - 100 → 200 (V112) - 0,005 → 0,001 (V393) - 3 000 → 100 000 (V194 deshabilitado, V421 confirmado) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 retrasado) - 0,0 → 0,9995 (V546 HTGS, 14 % de mejora) - 50 (sin cambios, V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443, ya default initializer para .full)
TP3.fullClassicPaper
DETALLES
Hermano de prueba Q1.5-A de TP2, Classic fiel al paper. Overrides vs. TP2: - 35 000 → 30 000 (estándar del paper) - 5 000 → 15 000 (paper: 50 % de maxIter) - 1,6e-5 → 1,6e-6 (default del paper) -,, vuelta a defaults del paper (0,05, 0,005, 0,001) - 1,1e-6 → 2e-7 (calibrado para ~1-2M Gs en Bicycle) - 200 → 100 (paper) - 0,001 → 0,005 (default del paper) - 100 000 → 3 000 (paper §5.2, arriesgado — puede disparar la regresión V194) - 0,9995 → 0,0 (el paper no tiene decay) - 20 000 → 30 000 (cosine corre hasta 100 % de maxIter)
TP4.fullMCMC
DETALLES
Producción Quality MCMC. Overrides vs. initializer: - 30 000 → 200 000 (V534, MCMC necesita 5× más iter que Classic) - 15 000 → 160 000 (V504b 80 % de maxIter) - 1,6e-6 → 1,6e-5 - Schedule de LR como TP2 (todas 2×) - 0,2 → 0,05 (V521b/V534: MCMC necesita señal L1 más fuerte) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (ya en initializer, confirmado en el preset) - 5e-5 (V467/V536 óptimo) - 0,005 → 0,01 (V535 óptimo) - 0 → 160 000 (80 % de maxIter, V497c/V502) - 3,0 (ya en initializer) - true (ya en initializer) - 3 000 → 200 000 (efectivamente off, MCMC usa reloc en lugar de reset)
TP5.fullMCMCMip
DETALLES
Hermano de prueba Q1.5-D de TP4, con Mip-Splatting + presupuesto MCMC de magnitud-paper. Overrides vs. TP4: - mcmcMaxGaussians 150 000 → 1 500 000 (10×, magnitud paper) - useMipSplatting false → true (Mip on)
TP6.classicBalanced
DETALLES
Mid-tier Classic. Overrides vs. TP2: - 35 000 → 20 000 (V149: 20K = 30K con 33 % menos tiempo) - 20 000 → 0 (cosine corre hasta maxIter = 20K, sin fase extendida)
TP7.mcmcPreview
DETALLES
Diagnóstico MCMC. Overrides vs. TP4: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80 %) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3,0 → 2,0 (1.4.5: Preview = escalado más ligero)
TP8.mcmcBalanced
DETALLES
Mid-tier MCMC. Overrides vs. TP4: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80 %) - 160 000 → 96 000 (80 %) - 3,0 → 2,5 (entre Preview 2,0 y Full 3,0)
TP9.quickTest
DETALLES
Prueba de funcionamiento pura. Overrides vs. initializer: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (calibrado para 0,25× resolución) - 100 → 50 - 3 000 → 100 000 (off, ya que demasiado corto) - 1,0 → 0,25
Método:
Firma: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int Definido en:
Fuente única de verdad para la pregunta "¿hasta cuántos Gaussianos se puede dejar crecer a MCMC?" Calculado a partir de tres entradas: el T62 mcmcMaxGaussians configurado (con suelo de extinción masiva 150 000 si 0), el (número de puntos init de SfM) y el (tamaño de buffer Gaussiano preasignado). Lógica:
+ base = T62 > 0 ? T62: 150_000 (el suelo de extinción masiva protege contra bugs de default de initializer como el incidente de extinción masiva 1.4.3) + Si T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) else
+ Si bufferCapacity > 0: return min(scaled, bufferCapacity) + Else return scaled
Ejemplo: Bicycle (Mip-NeRF 360, 194 frames de foto) → SfM init ~156 K puntos, T62 = 150 000, T72 = 5,32, capacidad de buffer 8 M. Tope resuelto = min(8M, max(150K, ceil(156K × 5,32))) = min(8M, 830K) = 830 K. Ese es el tope de crecimiento efectivo al que se atiene la lógica de relocalización MCMC.
Calcula el número máximo real de splats bajo MCMC. Toma tu ajuste, mira con cuántos puntos empieza tu escena, y escala por el Multiplier, si está activada la adaptación automática. Así el tope se adapta a la escena en lugar de forzar el mismo valor para una escena diminuta y una enorme. No tienes que llamar tú al método — el entrenamiento lo usa internamente.
¿Qué campo para qué? (Cheat Sheet)
| Objetivo | Campos a ajustar |
|---|---|
| Más detalle a la distancia | T62 mcmcMaxGaussians arriba, T72 mcmcCapMultiplier 5+ |
| Más detalle en general (Classic) | T1 maxIterations arriba (≤ 40K), T2 densifyUntilIteration ≤ 14 % de T1 |
| Reducir floaters en vuelos de dron | T43 frustumCullEnabled on, T20 skyMaskingEnabled on, T45 skyDomeEnabled on |
| Cielo agradable en escenas exteriores | T45 skyDomeEnabled on, T47 skyDomeRadiusMultiplier 30–60 |
| Archivo de exportación más pequeño | Estrategia .mcmc (T61), T56 postTrainingCompactification on, T62 mcmcMaxGaussians ≤ 200K |
| Entrenamiento más rápido | T22 trainingRenderScale 0,5, T1 maxIterations a la mitad — ¡pero no ambos! |
| Mejores brillos | T21 shDegreeUpgradeIterations con [2K, 5K, 8K] (sin front-load temprano), MCMC + 200K iter |
| Mantener el Mac responsivo | T25 throttleDelayMs 5–10 (cuesta ~15 % de tiempo de entrenamiento) |
| Previsualización en vivo más a menudo | T59 livePreviewInterval abajo a 10–20 |
| Transiciones más suaves en sombras | T17 ssimWeight ligeramente arriba (0,15–0,25), pero no por encima de 0,3 |
| Mantener compactos los interiores | Ajuste preestablecido P10 Indoor (, T72 = 1,76) |
Campos peligrosos
Estos campos pueden, con una mala configuración, llevar a OOM, crash de la app, extinción masiva de Gaussianos o datos de benchmark inutilizables. Trátalos con cuidado:
- T11 densifyGradThreshold — partir a la mitad puede crear 2–4× más Gaussianos, lo que rápidamente revienta la memoria GPU. Ten en cuenta también: debe coincidir con T22 trainingRenderScale (1,0× → 1e-6, 0,5× → 2e-6, 0,25× → 4e-6). - T72 mcmcCapMultiplier — con escenas grandes con > 200 K puntos init SfM y un multiplicador > 5, surge un tope resuelto de millones de Gaussianos. En Macs de 36 GB de RAM, OOM es posible. El ajuste preestablecido Outdoor 5,32 funciona solo porque Mip-NeRF 360 Bicycle tiene 156 K puntos init → tope 830 K. - T39 testViewIndices — fijarlo manualmente puede inutilizar el benchmark (todos los índices > N → sin holdouts). Deja que lo fije el flag –benchmark. - T64 mcmcOpacityRegWeight y T65 mcmcScaleRegWeight — En la beta 1.4.3 puestos a 0,01, lo que llevó a la extinción masiva (460 K → 5 Gaussianos en una iteración). Desde 1.4.4 fijados en 0,0, pero subirlos manualmente puede reproducir el problema. - T15 opacityResetInterval — si no está en 100 000+ (efectivamente off) y el entrenamiento es más corto que 10 000 iteraciones, el reset destruye la convergencia. .preview por eso lo tiene en 100 000 a pesar de maxIterations = 5 000. - T54/T55 densifyPhase2* — la densificación de dos fases acabó en pruebas en una cascada de 0 Gaussianos. Deja ambos en 0. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, puede incluso empeorar el PSNR en algunas escenas outdoor. Default off, opt-in solo para investigación.
Si un campo está en esta lista y quieres cambiarlo, primero haz copia de seguridad de tu ajuste preestablecido actual (exporta como JSON) y considera si puedes medir el resultado de forma reproducible — en otro caso, no sabrás después si has provocado una mejora o un empeoramiento.