第6章 — トレーニング構成
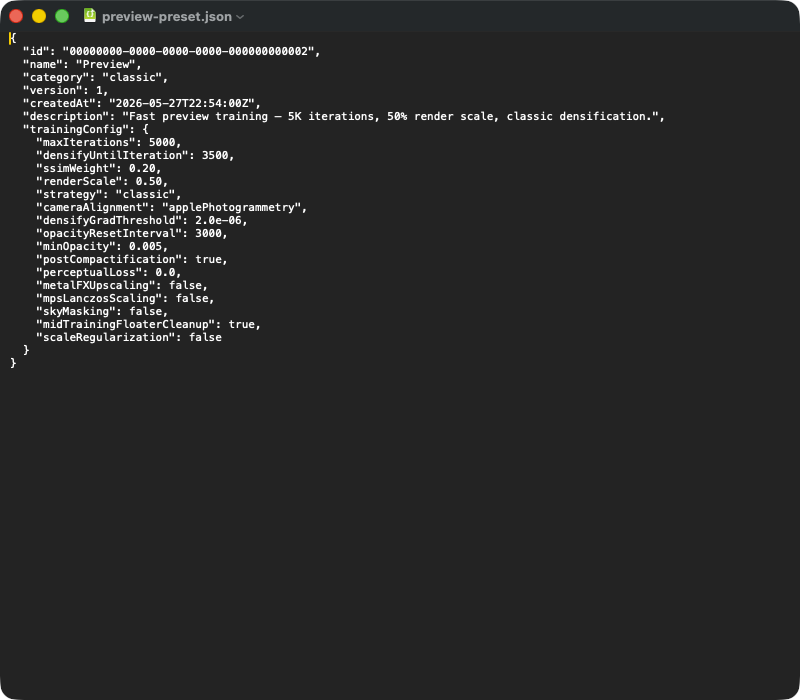
典型的なプリセット JSON エクスポート。トップレベルフィールド: id (UUID)、name、(classic | mcmc | sceneClass | custom)、(スキーマバージョン)、(タイムスタンプ)、 (フリーテキスト)。ネストされたオブジェクトには、再現性に重要な パラメータが含まれます — インポート時、ブロック全体が TrainingConfig 構造体にデシリアライズされ、アプリバージョンからのデフォルトが JSON に 欠けているフィールド (例えばアプリ更新後) を埋めます。プリセットを別の Mac に 渡す場合、単にこの JSON ファイルを送ります。
TrainingConfig 構造体は RadianceKit の各トレーニング実行の核です。 トレーニングに影響するすべてのパラメータを集めます — 最大反復数から 8 つの 学習率、MCMC、Mip-Splatting、Curriculum、scene-aware Cap ロジックの専用 フィールドまで。サイドバーのトレーニング構成セクション (エキスパートビュー) で 編集し、プリセットとして保存するか、JSON エクスポートとして別の Mac に渡します。 トレーニング時、このオブジェクトが正確に固定され、GPU バックエンドに渡されます。
この章は、パワーユーザーとスクリプト作成者向けのリファレンス資料です。すべての 81 のパブリックフィールド、9 つの静的プリセット、1 つのパブリックメソッドを リストします。ソースファイルは TrainingConfig.swift — 疑問があれば、 そこに保存されている Doc コメントと Initializer デフォルトが Source-of-Truth として有効です。
目次:
+ 反復 (T1〜T2) + Learning Rate (T3〜T10) + Densification — Classic (T11〜T16) + Loss (T17〜T20) + SH 次数進行 (T21) + パフォーマンス (T22〜T25) + 診断と点群準備 (T26〜T30) + 正則化 (T31〜T37) + Refinement (T38〜T44) + Sky-Dome (T45〜T48) + Adam + LR スケジュール (T49〜T55) + ポスト処理 + Apple AI (T56〜T60) + MCMC Densification (T61〜T73) + Mip-Splatting (Q1.5) (T74〜T76) + 適応 Densification (Q5) (T77〜T79) + Curriculum (Q6) (T80〜T81) + 静的プリセット (TP1〜TP9) + メソッド: + どのフィールドが何のためか? (チートシート) + 危険なフィールド
反復 (T1〜T2)
T1maxIterations
詳細
デフォルト: 30 000 (Initializer)、35 000 (.full)、200 000 (.fullMCMC) 範囲: 1 000 – 500 000 (UI スライダー)、ロジック内に ハード上限なし 定義場所:
技術詳細
バックエンドが実行するトレーニング反復の総数。1 反復は、単一の トレーニングカメラの順方向レンダリング、すべての Loss コンポーネント (L1 + SSIM + オプションの正則化 + Sky マスク) にわたる逆方向パス、Adam Optimizer ステップを意味します。この数値は他のスケジュールに直接影響します: Position Learning Rate は Cosine Annealing 曲線に従い 0 から T1 自体、または T49 positionLRScheduleEndIteration まで。Densification は T2 densifyUntilIteration で 停止。MCMC Noise Decay は T69 mcmcNoiseDecayEnd で終了。SH Degree アップグレードは T21 で定義された 3 つのマークで発生します。クラシック Densification では、経験的に決定されたスイートスポットは 20 000〜35 000 反復 (Sessions 1〜32、V546 テスト)、MCMC では 60 000〜200 000 (V534)。プリセットに 保存された値を大幅に超える増加は、めったに追加の品質をもたらしません — Adam Momentum が飽和し、LR Decay の終了がないと Loss が停滞します。逆に、 ~5 000 を下回ると、不完全に収束したジオメトリになります (Density Control が クローン/分割の時間が足りない)。
T2densifyUntilIteration
詳細
デフォルト: 15 000 (Initializer)、5 000 (.full)、160 000 (.fullMCMC) 範囲: 0 – 定義場所:
技術詳細
Densification が終了する反復。ここまで Gaussian は T11〜T16 (Classic) または T67〜T70 (MCMC) でパラメータ化されたルールでクローン、分割、Prune され、 その後 Gaussian 数は一定のままで、位置、回転、スケール、Opacity、SH 係数のみが 最適化されます (Refinement フェーズ)。3DGS オリジナル論文では値は T1 の 50% ですが、RadianceKit .full プリセットでは ~14% (35 000 のうち 5 000) — V310/V338 実験の結果、5 000 反復後のさらなる Densification は結果を悪化させる (より多くの Floater、より多くのメモリ要件、品質向上なし) と示されました。MCMC は 対照的に Relocation を T1 の 80% (V504b) まで実行します。MCMC が有害な Floater を 生成しないためです。T2 を小さすぎる (< 1 000) と Gaussian が少なすぎ、 Classic で大きすぎる (> T1 の 50%) と Overgrowth と RGB 飽和外れ値になります (Outdoor 過剰トレーニング所見参照)。
Learning Rate (T3〜T10)
T3positionLearningRate
詳細
デフォルト: 0.00016 範囲: 1e-7 – 1e-3 (推奨) 定義場所:
技術詳細
トレーニング開始時 (反復 0) の各 Gaussian の XYZ 位置用の Adam 学習率。 Cosine Annealing 曲線に従い、トレーニング中に T4 positionLearningRateFinal に 低下します。デフォルト 0.00016 は 3DGS オリジナル論文 (Kerbl et al. 2023) からの ものです。RadianceKit では、画像解像度を増加させても、ピクセル空間ではなく世界 座標系で Gaussian が移動するため、スケーリングしません。著しい増加 (> 0.0005) は Gaussian が長距離をジャンプし、Loss が不安定になります。それを大幅に下回る値 (< 0.00005) は、誤って初期化された点群が決して位置を見つけないことを意味します。 V414 は初期値の倍化をテスト → 16.8% 悪い L1 Loss。V544a チューニングは Paper デフォルトを最適として確認しました。注意: .fullMCMC では、この値を意図的に デフォルトのままにします — MCMC は Relocation ロジックのために一定の学習率を 必要とするため、ここでのチューニングは何ももたらしません。
T4positionLearningRateFinal
詳細
デフォルト: 0.0000016 (Initializer + Paper)、0.000016 (.full、 .fullMCMC — 10× 高い) 範囲: 0 – 定義場所:
技術詳細
Position LR Cosine Annealing 曲線の終値。T1 maxIterations で、または 設定されている場合は T49 positionLRScheduleEndIteration で達成されます。 RadianceKit .full プリセットは 0.000016 — Paper デフォルト 0.0000016 の 10× を 使用します。V420 実験は、Final 値の 0.5× (0.000008) が Loss を 6.4% 悪化させると 示しました。V414 は、初期値の 2× が 16.8% 悪化させると示しました。高い Final 値は トレードオフではなく意図的な選択: 強すぎる Decay では、Refinement フェーズ中に 新しく追加された Densification 候補に Gaussian が適応する能力を失います。 V431/V433 拡張により、スケジュールフェーズを短縮 (T49 < T1) し、T4 がトレーニング 終了前に達成され、トレーニングの残りが一定の Mini-LR で実行されます — 典型的な構成: T49 = 20 000、T1 = 35 000、つまり Refinement は 15 000 反復に わたって 0.000016 で実行。
T5shDCLearningRate
詳細
デフォルト: 0.0025 (Initializer + Paper)、0.005 (.full と すべての MCMC プリセット — 2×) 範囲: 0.0001 – 0.05 定義場所:
技術詳細
球面調和色の DC 部分 (degree 0、つまり一定アルベド) 用の Adam 学習率。 SH-DC は Gaussian の方向に依存しない基本トーンに対応します。いわば「基本色」です。 V176 と V188 実験は Paper デフォルトの 2× が最適であると見つけました — より速い 色収束、特に短いトレーニング (、5 000 反復) では SH-DC が形にならない からです。幾何学的 LR とは異なり、SH-DC には Decay がありません。学習率はすべての 反復で一定のまま (またはオプションの T51 拡張フェーズ Decay のみに従う)。 V416 は 0.01 への 4 倍をテスト → beta2=0.99-Adam で 6.4% 悪い Loss。
T6shRestLearningRate
詳細
デフォルト: 0.000125 (Initializer + Paper)、0.00025 (.full と MCMC — 2×) 範囲: 0.000001 – 0.005 定義場所:
技術詳細
高次 SH 係数 (Degree 1、2、3 — つまり、ハイライト、反射、ソフト シェーディングを引き起こす view 方向依存色部分) 用の Adam 学習率。Paper 規約に 従い T5 より 20× 小さい。これらの係数は数で 2 次的に成長し (Degree 1 で 3、 Degree 2 で 5、Degree 3 で 7 → 合計 Gaussian あたり 15 Float)、小さい学習率なしでは 画像を過飽和させます。T21 shDegreeUpgradeIterations の最初のマークまで Degree 0 のみがアクティブ (つまり T5 のみ)、その後 1、後で 2、最後に 3。ここでの低い値は、 拡散照明の多いシーンで特に重要です。非常に光沢のある表面 (車のペイント、水) では、 調整は価値がありません — SH 表現自体が制限されています。
T7opacityLearningRate
詳細
デフォルト: 0.05 (Initializer + Paper)、0.1 (.full、MCMC — 2×) 範囲: 0.001 – 1.0 定義場所:
技術詳細
各 Gaussian の logit Opacity 用の Adam 学習率。アプリは Opacity を 制約のない Float 値として保存し、Sigmoid で [0, 1] に変換します。LR は logit 空間で 動作します。Paper デフォルト 0.05 は V50 テスト (Best Single-Run L1 0.1664) 後に 復元されました。V71 は V67 の 0.025 を元に戻しました。V188 の 0.1 への倍化は Pruning をより効率的にします — 死んだ Gaussian は T14 pruneOpacityThreshold の 下により速く落ちます。V418 は: 0.05 with beta2=0.99-Adam は 0.1 より 7.1% 悪い — Adam 構成との相互作用は自明ではありません。低い値 (< 0.01) は「死んだ」Gaussian が 永遠に存在しメモリを消費することを意味します。高すぎる値 (> 0.5) は Opacity 爆発を 引き起こす可能性があるため、logit 値が Optimizer で [-15、3] にクランプされます (CLAUDE.md の「Opacity Explosion Prevention」注参照)。
T8opacityLearningRateFinal
詳細
デフォルト: 0.0 (= 「Decay なし」) 範囲: 0 または 0.001 – 定義場所:
技術詳細
Opacity LR 用のオプションの Cosine Decay 終値 (V427)。0.0 の場合、Decay は 無効化され、Opacity LR は全トレーニングにわたって T7 で一定のままです。V427 は Decay 0.1 → 0.01 をテスト — 結果 11.5% 悪い Loss。元に戻され、デフォルトは 「オフ」。フィールドの仮説: Refinement フェーズで、一定の Opacity LR は振動を 引き起こす可能性があり、すでに正しい透明度に達した Splat がランダムな勾配変動で 再び移動される。経験的に確認されません — Logit クランプロジックがすでに それをキャプチャします。フィールドは将来の実験のために使用可能なままで、非常に 長い MCMC 実行 (> 500K 反復) もこれから利益を得られる可能性があります。
T9scaleLearningRate
詳細
デフォルト: 0.005 (Initializer + Paper)、0.01 (.full、MCMC — 2×) 範囲: 0.0001 – 0.1 定義場所:
技術詳細
対数空間 (RadianceKit は log(scale) を保存し、スケールを正に保ちます) で 各 Gaussian の 3 つのスケールコンポーネント用の Adam 学習率。Paper デフォルト 0.005、RadianceKit では 0.01 に倍化されており、最適化された学習率構成での より良いスケール収束のため。V423 実験: beta2=0.99-Adam で 0.005 → 18.7% 悪い Loss と 目に見えて少なすぎる Gaussian (スケール更新が遅すぎたため Density Control が クローンできなかった)。スケールは各 Gaussian の範囲を制御します — 学習が速すぎる と「ニードル」Gaussian (非常に長い細い Splat、T34 scaleRatioPruneThreshold 参照) に なり、学習が遅すぎると Splat がコンパクトすぎるままで Density Control が頻繁に 分割しなければなりません。
T10rotationLearningRate
詳細
デフォルト: 0.001 (Initializer + Paper)、0.002 (.full、MCMC — 2×) 範囲: 0.0001 – 0.05 定義場所:
技術詳細
各 Gaussian の 4 つのクォータニオンコンポーネント用の Adam 学習率。 クォータニオンは各 Optimizer ステップで Adam 更新後に再正規化されます (L2 ノルム = 1) — そうでなければ共分散マトリクスが退化します。RadianceKit は Quality プリセットで Paper デフォルトを倍化します。回転はスケール/位置と比較してより小さな絶対勾配 マグニチュードを持ち (単位球面で各ステップは短いまま)、2× なしでは回転は 35 000 反復ウィンドウで著しく収束不足になります。V188 文書化。NeRF-Blender シーン (Lego、Chair) では、回転は特に影響します — オブジェクトのエッジは 5 000〜 10 000 反復後に初めて正しく整列します。
Densification — Classic (T11〜T16)
T11densifyGradThreshold
詳細
デフォルト: 0.000002 (Initializer、0.5× 解像度用にキャリブレート)、 0.0000011 (.full、1.0× 用にキャリブレート)、0.000004 (.quickTest、0.25× 用に キャリブレート)、2e-7 (.fullClassicPaper) 範囲: 1e-8 – 1e-3 (解像度依存) 定義場所:
技術詳細
画面空間投影された勾配 dMean2D の L2 ノルムの閾値で、これを超えると Gaussian がクローンまたは分割の対象としてマークされます。絶対値はトレーニング解像度に 直接依存します — dMean2D は約 1/解像度² のようにスケーリングします (より多くの ピクセル = より小さいピクセルごとの勾配)。したがって、各 T22 trainingRenderScale レベルにはキャリブレートされた閾値が必要です: 0.25× → 4e-6、0.5× → 2e-6、 1.0× → 5e-8 ... 1.1e-6 (.full)。Paper デフォルト 0.0002 は NDC 正規化されており、 RadianceKit の世界空間パイプラインで直接比較可能ではありません。V440 で追加された T52 adaptiveDensifyThreshold フラグでランタイムで現在の勾配分布の p98 から値を 計算できます — しかし V440 はそれを実際のシーンでテストして 63 K Gaussian を 生成しました (壊滅的な Pruning 損失)。フラグはオフのままです。Q5 (T77〜T79) は rolling median 経由の代替適応ロジックを提供します。このフィールドは 無害ではありません — 半分にすると 2〜4× の Gaussian (メモリ圧、OOM リスク)、 2 倍にするとシーンが過小 Densify される可能性があります。
T12densifyFromIteration
詳細
デフォルト: 500 範囲: 100 – 5 000 定義場所:
技術詳細
Densification がアクティブになる最初の反復。それ以前は、新しい Gaussian が 作成されることなく、初期 SfM 点群での「裸の」学習のみが行われます。デフォルト 500 は 3DGS 論文からのもので、初期化に安定する時間を与えます — 反復 0 から Densify されると、 誤って配置された SfM 点が、正しい位置を見つける前に何度もクローンされます。V349 は 1000 をテスト → わずかに悪い Loss。デフォルトが最適です。
T13densifyInterval
詳細
デフォルト: 100 (Initializer、MCMC)、200 (.full) 範囲: 50 – 1 000 定義場所:
技術詳細
2 つの Densification ステップ間にある反復の数。Paper デフォルト 100 — 100 反復ごとに densify 候補のリストが評価され、クローン/分割され、同時に prune 候補のリスト (sigmoid(opacity) < T14 pruneOpacityThreshold) が削除されます。 V112 テストは 200 を .full に最適と発見 — 再編成パスが少ないため GPU が 軽減され、クローンアクション後に各 Gaussian に安定する時間がより長く与えられます。 V417 は beta2=0.99 で 100 をテスト → 5.8% 悪い (957 K Gaussian、過剰 Densification)。 MCMC では同じフィールドが Relocation 間隔として解釈されます。MCMC 固有のロジックは T67 mcmcRelocationInterval を参照してください。
T14pruneOpacityThreshold
詳細
デフォルト: 0.005 (Initializer、Paper、MCMC)、0.001 (.full) 範囲: 0.0001 – 0.1 定義場所:
技術詳細
次の Densification ステップで Gaussian が削除される Sigmoid Opacity 閾値。T7 opacityLearningRate と Optimizer の Logit クランプロジックと連携して 動作します。V393 は .full でデフォルトを 0.005 から 0.001 に下げました — 結果: エキゾチックな視点でのみ役割を果たす Splat はより長く残り、SH ディテールに 寄与します。V394 は 0.0001 をテスト → わずかに悪い (Prune が少なすぎ、メモリが 無駄)。重要: Density Control は他の対策ですでにバッファ容量がいっぱいでも、 常に Prune する必要があります (CLAUDE.md の「Density Control Must Always Prune」 参照) — そうでなければ死んだ Gaussian が蓄積し、カウントが凍結します。
T15opacityResetInterval
詳細
デフォルト: 3 000 (Initializer + Paper)、100 000 (.full = 事実上無効化)、200 000 (.fullMCMC = 無効化) 範囲: 1 000 – 100 000+ 定義場所:
技術詳細
反復ごとに、すべての Gaussian の Opacity が低い値 (~0.01) にリセット されます — 「凍結」Splat を再評価するための 3DGS 論文の措置。V194 は RadianceKit の Warmup + Stochastic Training Setup + 2× 学習率では、Opacity Reset が 5.5% の品質を コストし、Logit クランプが Reset 機能をすでにカバーしていることを示しました。 したがって .full では事実上無効化 (100 000 > 35 000 = 決してトリガーされない)。 V421 は beta2=0.99 で 3 000 ごとの Reset をテスト → 4.9% 悪い。元に戻されました。 .fullClassicPaper (Q1.5-A、Paper 忠実テスト) では、意図的に再び 3 000 に 設定されています — これは Paper マグニチュード Gaussian バジェットに到達する ためのレバーの 1 つでした。
T16maxScreenSize
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 (オフ) または > 0 定義場所:
技術詳細
Gaussian が強制的に分割される前に達成できる最大画面空間サイズ (投影ピクセル単位)。値は 0 に設定 (V48 はテストして元に戻しました) — RadianceKit の Density Control は代わりに dMean2D ロジックから世界空間スケール 閾値を使用します。Mip-Splatting (T74〜T76) やシーン固有の Splatting 戦略を持つ 将来の実験がこれから利益を得る可能性があるため、フィールドカタログに残ります。 有効化 (値 > 0、例えば 20) は、画面上で非常に大きくなった Splat を強制的に分割します — 単一の巨大な Splat がディテールを提供しない大きな滑らかな壁面に関連します。
Loss (T17〜T20)
T17ssimWeight
詳細
デフォルト: 0.2 (Initializer + Paper + .full)、0.05 (すべての MCMC プリセット) 範囲: 0.0 – 1.0 定義場所:
技術詳細
loss = (1 - λ) * L1 + λ * D-SSIM の結合 Loss 関数の D-SSIM 部分の重み、 ここで λ = T17。3DGS Paper デフォルト 0.2 は Classic Densification に最適 — V383 は 0.3 をテスト → 28.9% 悪い、V373b は 0.2 を sweet spot として確認しました。 MCMC については V521b/V534 で独立して: 0.05 が最適と判明、MCMC は確率的探索を通じて より強力な L1 信号部分を必要とするため — 高い SSIM 重みは Relocation 決定を 希釈します。SSIM は L1 より計算がはるかに高価です (画像全体のローカル 11×11 ウィンドウ)。RadianceKit は MPS 加速実装を使用し、1080p 画像あたり 1 ms 未満です。 Q7 BayesOpt スイープは、0.05 (.outdoorPreset: 0.082) から 0.171 (.indoorPreset) の 間でシーン固有の最適化を見つけました。
T18ssimWeightRefinement
詳細
デフォルト: 0.0 (= 「切り替えなし、ssimWeight を保持」) 範囲: 0 または 0 – 1.0 定義場所:
技術詳細
T2 densifyUntilIteration 後の Refinement フェーズ用のオプション SSIM 値。V428 はテスト 0.2 → Refinement で 0.3 → 16% 悪い Loss (L1 と SSIM の両方が 悪化)。元に戻されたためデフォルト 0.0。フィールドの仮説は、Densification 後 — 新しい Gaussian がもう作成されない場合 — より強い SSIM 部分が構造的シャープネスを 最大化するでしょう。経験的に間違い: SSIM 重みを増やすことは間接的に L1 重みを 下げることを意味し、L1 は最終 Refinement フェーズで著しくより意味のある信号です。 フィールドは知覚 Loss (T60) やエッジ Loss (T19) を使用した将来の実験で利用可能なまま で、そこで Refinement 固有の Loss 構成が意味を持つ可能性があります。
T19edgeLossWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.001 – 1.0 定義場所:
技術詳細
V437 実験的 Loss: 画像エッジを直接比較する Sobel 勾配ドメイン L1 Loss の 重み (Ground-Truth Sobel vs Render Sobel) を L1+SSIM に加えて。仮説: エッジ情報は 画像品質の知覚的礎石で、明示的な項は Gaussian にエッジをより良くヒットさせるよう 奨励するべきです。テスト結果: 重み 0.1 → 11% 悪い Loss、0.01 → 品質ニュートラルだが 10% 遅い。Sobel パスは Ground Truth と Render での追加 MPS 順方向をコストします。 したがって永続的に無効化。将来のユースケース: 硬い人工エッジを持つシーン (建築、 家具、レンダリング) が利益を得る可能性 — Q7 Scene-Class プリセットはそれを ピックアップしませんでしたが、代わりに SSIM 重みをスケーリングしました。
T20skyMaskingEnabled
詳細
デフォルト: false (Initializer とすべてのプリセット) 範囲: boolean 定義場所:
技術詳細
Sky マスキングをオンにします。各画像で Apple Vision Framework (VNGenerateForegroundInstanceMaskRequest) 経由で Sky 領域がマスクアウトされ、 この領域の Loss がゼロに設定されます。意味: 屋外シーンは、青/灰色/白の Sky ピクセルがアプリにそこに Gaussian を配置させることでしばしば苦しみます — 「Floater」として認識されます。Sky マスクなしでは、この領域の Loss はゼロに なりません。空が画像内でわずかに変化し、アプリは Splat でそれを再構築しようと 永遠に試みるためです。Vision マスクはトレーニング前にカメラごとに 1 回計算され、 RAM に保持されます。通常は T45 skyDomeEnabled と一緒に有効化されます (Settings View の UI ロジック)。屋内シーンや合成レンダリングでは無効のままにします — マスクは天井や壁を誤って「Sky」として認識します。
SH 次数進行 (T21)
T21shDegreeUpgradeIterations
詳細
デフォルト: [1_000, 2_000, 3_000] (Initializer)、 [2_000, 5_000, 8_000] (.full、MCMC)、[1_000, 2_000] (.preview — Degree 3 スキップ) 範囲: [Int]、各値が [0, maxIterations] に、単調増加 定義場所:
技術詳細
アクティブな SH Degree が 0→1、1→2、2→3 に上昇する反復。最初のマークの前は DC コンポーネントのみアクティブ (つまり T5 shDCLearningRate)、最初のマーク後は DC + 3 つの Degree-1 係数、2 番目のマーク後は + 5 つの Degree-2 係数、3 番目の マーク後はすべての 15 係数。Gaussian あたりのメモリ需要は段階的に成長 — 4 Float → 16 Float → 36 Float → 64 Float。Quality プリセットは、ジオメトリが最初に安定して から、より高い周波数で色の詳細が来るように、Initializer デフォルトに対してアップ ステップを遅延させます (V228)。V384 は .full で [1K, 2K, 3K] をテスト → 9.3% 悪い — 遅延を確認。.preview は Degree 2 でキャップします、Degree 3 が 5 000 反復で収束せず Optimizer 容量を消費するためです。Q6 (T80〜T81) は、このリストを 動的に上書きする代替 Curriculum ロジックを提供します。
パフォーマンス (T22〜T25)
T22trainingRenderScale
詳細
デフォルト: 1.0 (Initializer、.full、MCMC、Scene-Class)、0.5 (.preview)、0.25 (.quickTest) 範囲: 0.05 – 2.0 (典型 0.25、0.5、1.0) 定義場所:
技術詳細
トレーニング画像のオリジナル解像度に対するトレーニング時のレンダリング 解像度。0.5 では各画像が 50% 幅 × 50% 高さ (つまりピクセルの 25%) に縮小され、 Gaussian レンダリングはこの小さい解像度で行われます。メモリと計算量の両方を 2 次 減少させます。重要: T11 densifyGradThreshold は選択された解像度に一致する必要が あります — 勾配マグニチュードは 1/解像度² でスケーリングするため、.quickTest (0.25×) は .full (1.0×、1.1e-6) よりはるかに高い閾値 (4e-6) を持ちます。 RadianceKit は非常に大きな画像で警告し、自動的に調整します — 3 MP ターゲット 解像度。極端な 4K 入力画像では、0.5 または 0.25 でも意味があります。そうでなければ どの Mac も CPU Compaction でのみ実行されます。
T23resolutionWarmupScale
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.1 – 定義場所:
技術詳細
V133 最適化: Densification フェーズ (Iter 0 から T2 まで) を Refinement フェーズより低い解像度でトレーニング。V308 は .full で再びオフにしました — T22 = 1.0 と Cosine Annealing で時間勝利が最小であり、品質がわずかに苦しんだ ため。4K 入力と長いトレーニング実行で再び意味を持つ可能性があるため、フィールド カタログに残ります — Q6 Curriculum (T80) は同様のロジックを採用しましたが、 そこでは LR スケジュールに結合されています。アクティブで T80 curriculumResolutionRamp も true の場合、Q6 が勝ち、この値を上書きします。
T24tileSize
詳細
デフォルト: 16 範囲: 8、16、32 定義場所:
技術詳細
ピクセル単位のラスタライゼーションタイルのサイズ。Gaussian Splatting レンダリングはタイルベース: 画像は 16×16 ピクセルのタイルに分割され、各タイルは 関連する Gaussian を収集し、深度でソートし、ブレンドします。16 は実質的にすべての 3DGS 実装で使用される標準で、RadianceKit Metal カーネルにハードコードされています。 この値の変更はシェーダーの再コンパイルを必要とし、現在の状態では有効ではありません。 将来のエンジンバージョンがタイルサイズを動的にサポートする場合のフィールドとして 残ります。
T25throttleDelayMs
詳細
デフォルト: 0 (Initializer、.full、MCMC、Scene-Class)、0 (.preview) 範囲: 0 – 100 定義場所:
技術詳細
ミリ秒単位のトレーニング反復間の人工遅延。0 = フル速度 (標準)。高い値は GPU/CPU が定期的に休息を得ることでトレーニング中の Mac を「より使いやすく」します — 他のアプリの使用感が上がりますが、トレーニング時間は遅延と線形に。典型値: 1〜2 ms (「軽い」スロットリング、+5% トレーニング時間、Mac がより反応的に感じる)、 5 ms (「中程度」、+15% トレーニング時間)、10+ ms (「Eco」、潜在的に倍のトレーニング 時間)。Inspector の「Performance」で提供されますが、標準ビューにはありません — Expert View から削除することを提案する dev_ux-backlog.md バックログ参照。誤解 すると、トレーニング時間が劇的に延長されるためです。
診断と点群準備 (T26〜T30)
T26depthDistortionWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.0001 – 0.05 定義場所:
技術詳細
V366 実験: 深度歪み正則化 Loss の重み。レンダリング光線に沿って深く ステージされていますが概念的に同じ表面に属する Gaussian にペナルティを与えます — 集中した深度分布を奨励し、Floater を減らします。テスト: 0.01 → 4.5% 悪い、 0.001 → 8.1% 悪い。理論的な利点 — マルチビュー一貫性の改善 — は L1 Loss に 反映されません。仮説は暗黙的に SfM ジオメトリが正しく、Gaussian は「スタック」 するだけでよいと仮定するためです。実際には、SfM 点群は通常最も弱いコンポーネントで、 スタッキングではありません。特にクリーンなポーズを持つマルチビューデータセット (合成、Mip-NeRF 360 with Ground Truth) のために使用可能なままです。
T27singleViewOverfit
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
診断フラグ: true の場合、Camera プールからランダムに選択する代わりに、 各トレーニング反復で Camera Index 0 が強制的に使用されます。意味: モデルが単一の ビューさえオーバーフィットできない場合 (つまり、View 0 の Loss が 10 000 反復後も ゼロに近づかない)、順方向/逆方向パスに根本的なバグがあります。このスイッチは Metal シェーダーと微分可能ラスタライザーカーネルの開発中に集中的に使用されました — V42〜V47 フェーズ。今日では、誰かがバックエンドコードを変更してリグレッションテストを 実行したい場合のサニティチェックとしてのみ利用可能。CLI 経由で –single-view。
T28maxCameras
詳細
デフォルト: 0 (= 「すべてのカメラを使用」) 範囲: 0 または 1 – N 定義場所:
技術詳細
V43 からの診断制限: 最初の N カメラのみでトレーニングし、それ以上は 無視します。元の意味: 多すぎるカメラが勾配競合を生成する (同じ Gaussian に対する 矛盾する Loss 信号が多すぎる) という仮説をテスト。テスト結果: 人工的な制限による 体系的な利点なし — より多くのフレームは事実上常により多くの品質をもたらします。 ターゲットを絞った実験のために CLI フラグ (–max-cameras N) として残ります。 例えば「1 500 画像ドローン飛行の最初の 100 画像でトレーニングは機能するか?」UI に 公開されていません。
T29maxInitialPoints
詳細
デフォルト: 0 (= 「すべての SfM 点を使用」) 範囲: 0 または 1 000 – 200 000+ 定義場所:
技術詳細
V54 セーフガード: トレーニングを開始する初期 SfM 点の数を制限します。 密な COLMAP 再構築は > 60 000 点を生成でき、大きな初期スケールではピクセル オーバーラップあたり 200〜300 Gaussian になります — これは「霧の場」を作り、 トレーニングが収束しません。~16 000 点へのサブサンプリング (トレーニングエンジンの Hard-cap ロジック) は、初期密度をリファレンス 3DGS が使用するレベルに引き上げ、 オーバーラップを劇的に減らします。非常に密な SfM では自動的に設定されます。 CLI 経由で –max-points N。
T30cameraClusterOutlierMultiplier
詳細
デフォルト: 10.0 (すべてのプリセット — 決して上書きされない) 範囲: 1.0 – 100.0 定義場所:
技術詳細
Phase 3.10 A.1 で導入された Camera Cluster Outlier Filter の Multiplier。 トレーニング前に、トレーニングエンジンはすべてのカメラ位置の重心とカメラから 重心までの最大距離を計算します。重心からの距離が multiplier × maxCameraDistance を 超える SfM 点は Outlier として破棄されます。デフォルト 10× は Phase 3.10 前の動作を 維持します。微妙なバグ: タイトな SfM (カメラがより近い) → 小さい → 小さい閾値 → より多くの点が Outlier として破棄される。緩い SfM → より大きい閾値 → より少ない 点が破棄される。これは Phase 3.9 Funnel-vs-Training 反相関の原因の 1 つです: より 良い SfM はより多くの初期点が殺されるため、ダウンストリームでより悪いトレーニングに つながる可能性があります。フィールドは A.3 スイープ用の CLI オーバーライド (–camera-cluster-outlier-multiplier) として配置されています。UI に公開 されていません。5 未満の値は通常制限的すぎ、20 を超える値は効果がありません。
正則化 (T31〜T37)
T31coarseToFineBlurRadius
詳細
デフォルト: 0 (= 無効化) 範囲: 0 または 1 – 10 定義場所:
技術詳細
V369 実験: Densification フェーズの開始時に Ground Truth 画像に適用され、 Densification (T2) の終わりまで線形に 0 に減少する Box Blur 半径。仮説: Coarse-to-Fine トレーニング — 最初に粗い構造を学び、次にディテール — はより安定したジオメトリを提供するべきです。テスト: r=3 → 9.6% 悪い、r=1 → 5.1% 悪い。 失敗の理由: Densification は画像ドメイン勾配に基づいて決定し、Blur は「ここで クローンする必要がある」に重要な信号を正確に減らします。他の Density Control スキームを使用した将来のテスト用にフィールドカタログに残ります。
T32scaleRegWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.0001 – 0.05 定義場所:
技術詳細
V370 実験: 世界空間スケールでの L1 正則化。大きくなりすぎる Gaussian に ペナルティを与え — 1 つの Gaussian で壁全体をカバーする「メガ Splat」を防ぎます。 テスト: 0.01 → 200% 悪い Loss (2 M Gaussian、全爆発)、0.001 → 214% 悪い。理由: スケール正則化は Density Control と競合します — より小さいスケールは、より多くの Gaussian が必要になることを意味し、Density Control はより頻繁に分割し、それが さらに多くの勾配作業を意味します。無効化、ただし Mip-Splatting 実験 (T74) のために 文書化されています: この文脈では、スケール下限が意味を持つ可能性があります。
T33anisotropyRegWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.0001 – 0.05 定義場所:
技術詳細
V445 実験: max(scale)/min(scale) 比率へのペナルティ、Floater として認識 される極端に細長い「ニードル」Gaussian を防ぐべきです。テスト: 0.01 → 69% 悪い、 0.001 → 15% 悪い。理由: 正則化は Splat を「丸い」形に強制しますが、平らな表面 (壁、テーブル、床) ではまさに間違っています — そこではフラットで広い Gaussian が 球形よりも効率的です。無効化。V549f は T34 scaleRatioPruneThreshold で代替の ターゲットを絞ったアプローチを提供しましたが、それも元に戻されました。
T34scaleRatioPruneThreshold
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 5.0 – 100.0 (典型 10.0 – 30.0) 定義場所:
技術詳細
実験的ポストトレーニング Pruning、max(scale)/min(scale) 比率がここで設定 された線形閾値を超える各 Gaussian を削除します。正則化だけでは排除できない極端に 細長い「ニードル/ディスク」Floater をターゲットにします。テストでは Pruning は期待 通り Floater を削除しましたが、同時に壁や床の意味のあるフラット Splat も削除 しました — 画像はより穴があきました。したがってデフォルトでオフ、CLI フラグ (–scale-ratio-prune N) は対象を絞った実験のために利用可能です。それでもテスト したい場合の推奨値: 30 (非常に保守的、極端な外れ値のみを削除)、10 (積極的、 ディテールをコスト)。
T35opacityRegWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.0001 – 0.05 定義場所:
技術詳細
V446 実験: Opacity を 0 または 1 に引き寄せる Binary-Cross-Entropy ペナルティ (つまり「半透明」から離れる)。仮説: より鋭い Opacity 分布は画像の明瞭さを 改善するべきです。T33 と組み合わせたテスト → 正則化が品質をコスト、両方無効化。 無効化。注意: 1.4.3 ベータで、このフィールドが Default 値の変更 (Initializer = 0.01) で正確にあるバグが現れ、Gaussian カウントの Mass-Extinction (1 反復で 460 K → 5) になりました。1.4.4 以降、デフォルトとして 0.0 に固定。
T36opacityDecayFactor
詳細
デフォルト: 0.0 (Initializer = 無効化)、0.9995 (.full、 .classicBalanced — HTGS 標準) 範囲: 0 (オフ) または 0.95 – 1.0 定義場所:
技術詳細
HTGS スキームの V546 実装 (Hierarchical Time-Gating、Eurographics 2025): すべての T37 opacityDecayInterval 反復で、各 Gaussian の Sigmoid Opacity に この係数が掛けられます。100 回適用で 0.9995 × は Densification フェーズあたり ~95% 残存をもたらします — すべての Opacity に対するわずかだが持続的な下方圧力で、 弱く寄与する Gaussian を確実に T14 pruneOpacityThreshold の下に下げます。結果: Decay なしの V438 と比較して Horse Full (3 試行平均 V546) で 14% 良い L1 Loss。 Densification フェーズ中のみアクティブ (T2 まで)、その後トレーニングは Decay なしで続行され、Refinement で確立された Opacity が安定したままになります。MCMC では使用されません (MCMC は T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold 経由で独自のメカニズムを持ちます)。
T37opacityDecayInterval
詳細
デフォルト: 50 範囲: 10 – 500 定義場所:
技術詳細
T36 opacityDecayFactor が適用される反復間隔。HTGS Paper デフォルト 50、 .full で維持。長い間隔 (>200) は効果を部分的に取り消します。2 つの適用の間で十分な 勾配更新が発生し、Opacity が再び上昇するためです。より短い間隔 (<20) は Decay を 積極的すぎにします。Densification フェーズでのみアクティブ。
Refinement (T38〜T44)
T38gradientAccumulationSteps
詳細
デフォルト: 1 (= 「Adam ステップごとに 1 ビュー」) 範囲: 1 – 8 定義場所:
技術詳細
V424 機能: Adam 更新が実行される前に勾配が蓄積されるビューの数。> 1 の 場合、アプリは別の「unfused」逆方向プロジェクトパスで実行され、勾配を別のバッファに 集計します。最終適用は 1/N でスケールしてマグニチュードを一定に保ちます。V424 は 2 ビューをテスト → 品質ニュートラルだが 10% 遅い (unfused パスが fused パスより 高価なため)。.full では元に戻されましたが、MCMC では意図的に使用 — .fullMCMC は で実行されますが、V544a テストは Classic への品質ギャップが (11% の代わりに) 5% に 縮小すると示しました。Initializer デフォルト 1、現在のプリセットで 1、CLI フラグ (–accum-steps N) として残ります。
T39testViewIndices
詳細
デフォルト: [] (= 空、すべてのビューがトレーニングに使用) 範囲: Set<Int>、Camera インデックスの任意のサブセット 定義場所:
技術詳細
V546 機能: トレーニングに使用されず、PSNR/SSIM/LPIPS 評価のための Holdout として節約される Camera インデックスのセット。–benchmark CLI フラグがアクティブな 場合に自動的に設定されます: その場合、インデックス 0 から始まる 8 番目ごとのビュー (LLFF 標準、Mip-NeRF 360 および 3DGS 論文規約と同一)。Benchmark なしでは空 — トレーニングはすべてのビューを使用します。注意: インデックスを理解せずに このフィールドを手動で設定すると、Benchmark が使用不可になる可能性があります (例えば N より上のすべてのインデックスを設定するが、N-50 ビューしかない場合 → Holdout なし → 評価なし)。独自のプリセットエクスポートでは、testViewIndices は シーン依存で、異なるデータセット間で意味のない値を残すため、永続化されません。
T40refinementPruneInterval
詳細
デフォルト: 0 (= 無効化) 範囲: 0 または 100 – 5 000 定義場所:
技術詳細
V425 機能: Refinement フェーズ中 (T2 後) の N 反復ごとに、 sigmoid(opacity) < T41 refinementPruneOpacityThreshold の Gaussian を削除する 追加の Prune パスが実行されます。意味: Densification 中は定期的な Density Control コールがあり、その後はありません — Opacity がさらに低下する Gaussian はバッファに 残ります。V425 はテストして元に戻しました: 追加の Pruning は V426 (Two-Phase Densification、これも 0 Gaussian カスケード失敗で中止) と相関しました。無効化。 実験用 CLI フラグ利用可能。有効化された場合、1 000 または 2 000 が意味のある値です。
T41refinementPruneOpacityThreshold
詳細
デフォルト: 0.0 (= 「T14 を使用」) 範囲: 0 または 0.001 – 0.1 定義場所:
技術詳細
V425b: Refinement Pruning 用の別の Opacity 閾値。Densification 後、ほとんどの Gaussian は著しく高い Opacity (> 0.001) に達しているため、標準 T14 pruneOpacityThreshold は緩すぎます。T40 がアクティブな場合、このフィールドが 独自の閾値を決定します。0.0 では T14 が引き続き使用されます。T40 > 0 の場合のみ 関連します。
T42midTrainingCompactificationIterations
詳細
デフォルト: [] (= 無効化) 範囲: [Int]、 (densifyUntilIteration, maxIterations) の値 定義場所:
技術詳細
V549 機能: Refinement フェーズ中の明示的な反復ポイントで、Compactification パスが実行されます (sigmoid(opacity) < 0.01 + 外れ値スケール Gaussian を削除、 T56 postTrainingCompactification と同じロジック)。意味: 長い Refinement フェーズは Confetti/Floater 蓄積を示す可能性があり、その SH はビュー固有のアーティファクトに オーバーフィットします。有効化された場合の典型的な構成: [10000, 20000, 30000] for 40K Classic。しかし: V549 A/B テストは Family データセットで、すべての 構成でより悪い L1 を示しました: [10K,20K,30K]@0.01 → −48% カウントだが +36% L1。 [20K,30K]@0.005 → −44% カウントだが +45% L1。[20K,30K]@0.001 → −17% カウント だが +87% L1。したがって無効化。CLI フラグ –mid-compact "10000,20000" が利用 可能、視覚的 Floater トレードオフ (Viewport で Confetti が少ない) を Loss リグレッションよりも優先する場合に。
T43frustumCullEnabled
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
V549b 機能: トレーニング後、すべてのトレーニングカメラ Frusta の Union の 外側にあるすべての Gaussian が削除されます。そのような Gaussian は Loss 信号に よって決して制約されず、常に Floater です。Novel View がカメラパスの後ろまたは 横にあるシーン (例えば線形ドローン飛行の裏側) に特に効果的です — そこの Floater はトレーニングフェーズで決して見えませんが、後で 3D ビューアで動くときに 非常に見えます。V549b A/B はドローン飛行で肯定的な結果、したがって Opt-In として 利用可能。デフォルト false。完全なオービットカバレッジを持つ Object キャプチャでは Frustum Union がシーン全体を含み、機能が何も削除しないため — Settings の 「Floater Reduction」で提供され、Q9 Outdoor プリセットで T44 frustumCullExpansion 経由で 暗黙的にテストされます (Q7 BayesOpt はそれをアクティブにしませんでした。 Outdoor Sky-Dome が同じ問題をより良く解決するため)。
T44frustumCullExpansion
詳細
デフォルト: 1.1 範囲: 1.0 – 2.0 定義場所:
技術詳細
T43 frustumCullEnabled の NDC マージン。1.0 は画像境界で正確に切断し、 ぼやけた Splat を境界で切り詰めすぎます。1.1 = 正確なカメラフレーミングを超えた 10% パディング — わずかにオフセットされた Novel View で見える可能性のある境界 ピクセルに対する許容範囲を与えます。> 1.2 の値は Cull を実質的に無効にします。 拡張された Frustum がはるかに多くの空間をカバーするためです。
Sky-Dome (T45〜T48)
T45skyDomeEnabled
詳細
デフォルト: false (Initializer + P9 Outdoor を除くすべての プリセット) 範囲: boolean 定義場所:
技術詳細
V549e 機能: トレーニング開始前、球状点群が生成され (Fibonacci sphere、 T46 Sample 点)、シーン中心の周りの T47 skyDomeRadiusMultiplier × scene_extent の 半径に配置され、すべてのトレーニングカメラの Sky マスクされたピクセルからの色 (T20 skyMaskingEnabled 参照) で初期化されます。これらの Sky-Dome Gaussian は Gaussian バッファの先頭に挿入され、トレーニング中に「凍結」されます (Position/ Scale/Rotation 勾配 = 0、SH と Opacity のみ最適化可能)。効果: 遠くの黒い「Confetti」 領域の代わりに、Novel View で実際の空が表示されます。V549e MVP はドローンと風景 シーンで非常にうまく機能します。P9 Outdoor プリセットでデフォルトオン。室内シーンでは オフのまま — 球は部屋の外に意味なくぶら下がります。
T46skyDomeSampleCount
詳細
デフォルト: 5 000 範囲: 1 000 – 50 000 (典型 2 000 – 10 000) 定義場所:
技術詳細
Sky-Dome 球面上の Fibonacci Sphere Sample 点の数。高い値 → より密な Sky-Dome (大きな解像度と多くの可視天空でより良い) ですが、より多くのメモリ需要。 5 000 は 4K レンダリング用のスイートスポット。低い解像度では 2 000〜3 000 で十分。 点は各トレーニングカメラ View ベクトルへの Cosine Distance によって、対応する Sky マスクされたピクセルで初期化されます — View Cone がカメラを見ない Sample 点は 低い Opacity 初期値で背景に残ります、しかしトレーニングで変更されません (凍結)。
T47skyDomeRadiusMultiplier
詳細
デフォルト: 30.0 (Initializer + ほとんどのプリセット)、59.0 (P9 Outdoor、Q7 BayesOpt 最適化) 範囲: 5.0 – 200.0 定義場所:
技術詳細
シーン範囲 (= カメラ位置間の平均距離) に対する Sky-Dome 球の半径。30 = 球は カメラ雲の直径の 30 倍を持ちます。小さすぎる (< 5) → Sky-Dome はシーン自体と干渉 します (例えば Sky-Dome Splat が前景に着地)。大きすぎる (> 100) → Sky-Dome 位置で float32 精度損失、遠くでレンダリンググリッチを引き起こします。Q7 BayesOpt on Bicycle (Mip-NeRF 360) は屋外用のシーン固有最適化として 59.0 を見つけました — これは標準 30.0 が深い風景に小さすぎ、Sky-Dome ピクセルが画像境界領域で「壁」 として見えるようにレンダリングされることを示唆しています。
T48frozenGaussianCount
詳細
デフォルト: 0 (= 凍結された Gaussian なし) 範囲: 0 または 1 – T46 定義場所:
技術詳細
Optimizer で Position/Scale/Rotation 勾配がゼロに設定される、バッファの 先頭にある Gaussian の数 — 全トレーニングにわたって空間的に固定されたままです。 Density Control はそれらをクローン、分割、または Prune してはいけません。 Sky-Dome 注入用 (T45 参照): Sky-Dome がオンの場合、このフィールドは自動的に T46 skyDomeSampleCount に設定されます。手動設定は可能 (例えば LiDAR スキャンから 事前配置された点群を凍結) ですが、UI から直接アクセスできません。重要: バッファの 最初の N Gaussian は常に frozen — バッファ内の順序が決定し、明示的なインデックスでは ありません。
Adam + LR スケジュール (T49〜T55)
T49adamResetIteration
詳細
デフォルト: 0 (= 無効化) 範囲: 0 または 100 – 定義場所:
技術詳細
V430 機能: Adam Optimizer Momentum アキュムレータ (m1、m2) がゼロにリセット される反復。その後のバイアス修正は iter の代わりに (iter - adamResetIteration) で実行されます。V430 は 5 000 (Densification 終了 後) でリセットをテスト → 12.8% 悪い Loss。理由: Densification 中に蓄積された Adam Momentum は典型的な勾配マグニチュードに関する情報を運び、Refinement フェーズを 加速します。それを捨てることは Refinement の最初の ~500 反復の収束をコストします。 無効化。研究実験用 CLI フラグとして残ります。
T50positionLRScheduleEndIteration
詳細
デフォルト: 0 (Initializer = 「maxIterations を使用」)、20 000 (.full — Cosine が maxIter=35K にもかかわらず 20K で終了)、30 000 (.fullClassicPaper) 範囲: 0 または 1 000 – 定義場所:
技術詳細
V431 機能: Position LR の Cosine Annealing 曲線が最小に達する反復。0 の 場合、T1 maxIterations と同じです。> 0 の場合、スケジュールはこの値まで実行され、 その後 T4 positionLearningRateFinal で一定のままです。これにより、最小だが 一定の学習率を持つ「拡張された Refinement フェーズ」が可能になり、新しい Decay なしで位置をゆっくり洗練します。.full はこれを行います (Schedule End at 20K、 Training runs until 35K)、V434c/V434d は確認しました: 15K と 25K の両方が約等しく、 20K がわずかに最適。T51 と組み合わせて使用され、拡張フェーズの非位置 LR も 修正します。
T51extendedPhaseLRDecay
詳細
デフォルト: 0.0 (= 無効化、一定の LR) 範囲: 0 または 0.01 – 1.0 定義場所:
技術詳細
V433 機能: 「拡張フェーズ」での非 Position LR (スケール、回転、Opacity、 SH) の最小乗数 — つまり: T50 に達した後、Position LR がすでに T4 の場合。 0.1 の場合、スケール/回転/Opacity/SH は、それぞれ 1.0 (= 標準 LR) からその標準の 0.1× に Cosine Decay されます。0.0 (デフォルト) では、それらは一定のままです。 V457 は完全な Decay (0.0 = ゼロへの Decay) を no-Decay に対してテストし、見つけました: 平均 0.0400 (2 実行) = V438 と同じ Loss、Decay なし。Decay でよりクリーンな 動作ですが、測定可能により良くありません。したがって無効化。CLI に –nonpos-lr-scale F として残ります。
T52adaptiveDensifyThreshold
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
V440 実験: true の場合、アプリは各 Densification ステップで現在の勾配 分布の p98 を計算し、それを動的閾値として使用します (T11 の設定値の少なくとも 0.5× にクランプ、あまり外れないように)。仮説: 現在のシーンフェーズへの自動調整は、 Density Control をより堅牢にします — 例えば最初は厳密な Pruning、後で緩い、 または逆。V440 はテストして元に戻しました: 63 K Gaussian (Mass-Pruning) への 壊滅的なドロップ、最初の反復で p98 が非常に高く、その後ほとんど何も閾値を超えない ためです。固定閾値はすでによくキャリブレートされており、動的調整は害よりも害が 多いです。Q5 (T77) は問題を回避する rolling median 経由の代替適応ロジックを 提供します。
T53mergeAfterDensification
詳細
デフォルト: false (Initializer)、true (.full、 .classicBalanced、.fullClassicPaper) 範囲: boolean 定義場所:
技術詳細
V438 機能: Densification フェーズの終わり (Iter T2) で、類似の スケールと色を持つ近接 Gaussian を結合する 1 回限りの Merge パスが実行されます。 Gaussian 数を視覚的品質損失なしで通常 5〜15% 削減します。意味: 集中的なクローニング後、 何も新しいものを寄与しない準同一の Gaussian のクラスタが形成されます — マージは 他の領域のための Optimizer 容量を解放します。Classic Quality プリセットで標準。 MCMC では使用されません。MCMC は Relocation ロジックを通じてそのようなクラスタを 最初から形成させないためです。
T54densifyPhase2FromIteration
詳細
デフォルト: 0 (= 無効化) 範囲: 0 または T2 – T1 定義場所:
技術詳細
V426 実験: Refinement 休止後にこの反復から開始し、T55 まで実行する 2 番目の Densification フェーズを有効にします。仮説: Refinement フェーズ後、勾配 アキュムレータはより安定したマグニチュードを持ち、どの領域がまだ追加の Gaussian を 必要とするかをより正確に伝えることができます。V426 はテストして元に戻しました: Two-Phase Densification は 0 Gaussian カスケード失敗に陥りました (V425 Refinement Pruning と組み合わせるとバッファを破壊)。無効化。実験用 CLI フラグ利用可能。
T55densifyPhase2UntilIteration
詳細
デフォルト: 0 範囲: 0 または T54 – T1 定義場所:
技術詳細
V426 Two-Phase Densification の終了。T54 > 0 の場合のみ関連。両フィールド 一緒に無効化。
ポスト処理 + Apple AI (T56〜T60)
T56postTrainingCompactification
詳細
デフォルト: true (すべての Production プリセット)、false (.quickTest、.preview) 範囲: boolean 定義場所:
技術詳細
V443 機能: トレーニング終了後、sigmoid(opacity) < 0.01 の Gaussian が ハード除去されます (実質的に画像にもう寄与しません)。Gaussian カウントを通常 58%、 エクスポートファイルサイズを 55% 視覚的品質損失なしで削減します。Production プリセットでデフォルトアクティブ — 最終結果はできるだけコンパクトに配信できる べきです。.quickTest ではオフ、診断実行はとにかくエクスポートされないためです。 T42 midTrainingCompactificationIterations (V549) とは異なり、Compactification は 終了時のみ行われます — Refinement はそれまですべての Gaussian を使用できます。
T57metalFXUpscaling
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
V444 機能: 3D ビューア出力のバイリニア補間の代わりに Apple の MetalFX Spatial Upscaler を有効化します。トレーニング解像度 < Viewport サイズ (例えば 0.5× でトレーニング、フル解像度で Viewport 表示) の場合、MetalFX は著しく鮮明な 画像を提供できます。Viewport でライブに変更され、再トレーニング不要。 T58 mpsLanczosScaling と相互排他 — MetalFX が優先。推奨: 期待される ディテールと比較して Viewer の画像が「ぼやけて」見える場合は、オンにします。
T58mpsLanczosScaling
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
V444 機能: Viewport スケーリング用のバイリニア補間の代わりに MPSImageLanczosScale。Lanczos は古典的な Sinc ベースのリサンプリング手順で、 バイリニアより著しく鮮明な結果を最小オーバーヘッドで提供します。ライブトグル。 両方がオンの場合、T57 で上書きされます。
T59livePreviewInterval
詳細
デフォルト: 50 (Initializer とほとんどのプリセット) 範囲: 0 (オフ) または 10 – 5 000 定義場所:
技術詳細
トレーニング中に 3D Viewer が現在の Gaussian で更新される頻度。50 = 50 反復ごとに Viewer の新しいレンダリング — 進行を観察するのに十分良く、トレーニング を遅くしません。0 = Viewer はまったく更新されません (バックグラウンドトレーニング、 最大速度)。典型的な調整: .quickTest で 10 まで下げる (各ステップを見たい)、長い MCMC 実行で 500〜2000 まで上げる (合計の更新オーバーヘッドが顕著)。
T60perceptualLossWeight
詳細
デフォルト: 0.0 (= 無効化) 範囲: 0 または 0.001 – 0.5 定義場所:
技術詳細
V444 将来機能: MPSGraph 経由の知覚 Loss 項の重み (VGG ライクな小さな ネットワーク)。L1+SSIM より高いセマンティックレベルで構造的およびテクスチャ 類似性をキャプチャします — 通常、研究パイプラインで、「ピクセルパーフェクト」が 「リアルに見える」より重要でない場合。実装はまだ保留中 (コードスタブは存在しますが、 順方向パスは実装されていません)。デフォルト 0.0。将来のアクティベーション用に フィールドカタログに残ります。CLI フラグ –percep-weight F 予約。
MCMC Densification (T61〜T73)
T61densificationStrategy
詳細
デフォルト: .classic (Initializer + Classic プリセット)、 .mcmc (すべての MCMC プリセット + Scene-Class) 範囲: .classic または .mcmc 定義場所:
技術詳細
Classic Densification (Clone/Split/Prune、Kerbl et al. 2023) と MCMC Densification (Stochastic Gradient Langevin Dynamics with Relocation、 Kheradmand et al. NeurIPS 2024) の間で選択します。.classic では T11〜T16 が 評価され、.mcmc では T62〜T73 が評価されます。切り替え時の注意: Classic デフォルトと MCMC デフォルトは完全に異なってキャリブレートされています — Expert View でピッカーをフリップして、適切なプリセットをロードしない場合、 1.4.3 バグスタイルの Mass-Extinction を冒険します (1 反復で 460 K → 5、 MCMC OpacityReg 0.01 が Classic Opacity を殺すため)。したがって、MCMC Init デフォルトは意図的に「ソフト化」されています (すべての Reg 値 0.0)。
T62mcmcMaxGaussians
詳細
デフォルト: 150 000 (Initializer + .fullMCMC + .mcmcBalanced)、 100 000 (.mcmcPreview)、1 500 000 (.fullMCMCMip — Mip-Splatting バリアント with 10× バジェット)、1.19 M (.renderPreset)、1.25 M (.outdoorPreset)、 670 K (.indoorPreset) 範囲: 0 (= 「バッファ容量を使用」) または 10 000 – 5 000 000 定義場所:
技術詳細
MCMC 戦略での Gaussian 数のハード上限。数はキャップに達するまで Relocation ステップごとに T70 mcmcGrowthRate (通常 5%) で徐々に増加します。V473/V531 は 150 K をスイートスポットと見つけました — 200 K を超えると Splat 品質が薄まり (小さく冗長な Gaussian が多すぎる)、100 K 未満ではシーンが過小 Densify されたまま。 非常に大きなシーン (例えば 1 545 枚のドローン飛行で 158 K SfM-init) では 150 K が 低すぎる — したがって 1.4.5 拡張 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene。Q7 BayesOpt はシーン固有最適化を 670 K (Indoor) から 1.25 M (Outdoor) の間で見つけました。値 0 では、エンジンは完全なバッファ容量を キャップとして使用します。
T63mcmcNoiseScale
詳細
デフォルト: 0.00005 (5e-5 = Paper デフォルト) 範囲: 1e-6 – 1e-3 定義場所:
技術詳細
各 MCMC 反復で各 Gaussian の位置に追加されるガウスノイズの乗数 (SGLD ロジック)。高い = より多くの探索 (Gaussian がより放浪し、潜在的により良い場所を 見つける)、低い = より多くの活用 (Gaussian がすでに良い場所に留まる)。V467 と V536 は 5e-5 を最適と確認 — 1e-5/2e-5 探索が少なすぎ、1e-4 多すぎ (Splat が 流れる)。トレーニング時間にわたって T69 mcmcNoiseDecayEnd まで Cosine Decay されます — Decay 範囲の終わりでノイズは事実上 0 で、Gaussian は収束します。
T64mcmcOpacityRegWeight
詳細
デフォルト: 0.0 (= RadianceKit デフォルトで無効化、Paper: 0.01) 範囲: 0 または 0.001 – 0.05 定義場所:
技術詳細
Opacity 用の MCMC 固有 L1 ペナルティ。Paper デフォルト 0.01 (未使用の Gaussian をゼロに押し、Relocation 用に利用可能にします)。しかし V464b は示しました: Reg なしでは RadianceKit で測定可能により良い (Session 28 確認)。理由: T68 mcmcDeadOpacityThreshold で定義された Pruning 基準は単独で十分 — 追加の L1 ペナルティは、貴重で低 Opacity の Gaussian も死亡させます。したがってデフォルト 0。注意: 1.4.3 ベータビルドでは Initializer デフォルトが誤って 0.01 で、 Mass-Extinction バグが発生しました (T61 説明参照)。1.4.4 以降 0.0 に固定。
T65mcmcScaleRegWeight
詳細
デフォルト: 0.0 (= 無効化、Paper: 0.01) 範囲: 0 または 0.001 – 0.05 定義場所:
技術詳細
スケール固有値用の MCMC 固有 L1 ペナルティ。Paper デフォルト 0.01。V464b: Reg なしでより良い、T64 と同じ理由。すべての RadianceKit MCMC プリセットで無効化。 T64 と同様の注意: 1.4.3 バグ。
T66mcmcRelocationInterval
詳細
デフォルト: 100 (Initializer + すべての MCMC プリセット、Paper 標準)、155 (P9 Outdoor — Q7 BayesOpt 最適化) 範囲: 50 – 500 定義場所:
技術詳細
MCMC が死んだ Gaussian (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) を 新しい位置に再配置する反復間隔。V537 は 50 (混乱しすぎ、Loss 変動) と 200 (わずかに 悪い、MCMC が反応性を失う) をテスト。100 が最適。Q7 BayesOpt on Bicycle はシーン 固有最適化として 155 を見つけました — やや長い間隔は、次の Reloc イベントが それらを圧力下に置く前に、Adam に新しく配置された Gaussian を統合する時間をより 多く与えます。
T67mcmcWarmupIterations
詳細
デフォルト: 500 範囲: 100 – 5 000 定義場所:
技術詳細
MCMC Relocation がまだ発生しない初期反復の数。この Warmup 後、Reloc ロジックが開始されます。意味: 最初の反復では、Opacity 値はまだ落ち着いていません — すぐに Reloc で開始されると、Gaussian は間違った場所に配置され、すぐに再び移動 される必要があり、Adam Momentum を破壊します。Paper デフォルト 500。RadianceKit は この値を引き継ぎます、V464b がそれが堅牢であることを示したためです。
T68mcmcDeadOpacityThreshold
詳細
デフォルト: 0.005 (Initializer、Paper 標準)、0.01 (.fullMCMC と すべての MCMC プリセット — V535 最適化) 範囲: 0.001 – 0.05 定義場所:
技術詳細
Gaussian が「死んだ」とみなされ Relocation の対象となる sigmoid(Opacity) 閾値。V535 は 0.01 を最適と発見 (0.005 わずか、0.02 悪い)。高い = より積極的な Reloc (より多くの Gaussian が移動)、低い = より慎重。0.01 はおおよそ「0.5% 視覚的 可視性」に相当します。P10 Indoor は Q7 BayesOpt 経由で 0.0142 を最適として使用 します。
T69mcmcNoiseDecayEnd
詳細
デフォルト: 0 (Initializer = 「Decay なし」)、160 000 (.fullMCMC = 200K の 80%)、96 000 (.mcmcBalanced = 120K の 80%)、40 000 (.mcmcPreview) 範囲: 0 または 1 000 – 定義場所:
技術詳細
T63 mcmcNoiseScale ノイズが完全にゼロに減衰される反復 (Iter 0 から ここまでの Cosine Decay)。V497c/V502 は maxIterations の 80% を最適と発見 — MCMC に十分な探索時間を与え、最後の 20% をノイズなしでの収束に残します。0 = すべての 反復にわたって一定のノイズ (まれに意味があり、MCMC は収束できません)。
T70mcmcGrowthRate
詳細
デフォルト: 0.05 (Paper 標準 = 5%) 範囲: 0.01 – 0.2 定義場所:
技術詳細
Relocation ステップごとの MCMC 人口ターゲットの成長率。ロジック: 各 Reloc イベントで、ターゲット人口サイズが T62 mcmcMaxGaussians (または T72/T73 経由で スケールされたバリアント) に達するまで (1 + growthRate) で増加されます。V512/V522 は 0.05 を最適と発見 — 高い値は速すぎる成長になります (Adam Momentum が統合する前に Gaussian が挿入される)、低い値は終了時にシーンが過小 Densify されたままに なります。
T71mcmcSigmoidK
詳細
デフォルト: 100.0 範囲: 10.0 – 500.0 定義場所:
技術詳細
MCMC Noise 減衰用の Sigmoid Sharpness パラメータ。SGLD ステップでは、 Gaussian あたりのノイズが で減衰されます — 高 Opacity Gaussian (Logit が正) は、 低 Opacity よりも指数的に少ないノイズを受け取ります。K = 100 は鋭く、つまり 「フルノイズ」から「ノイズなし」への遷移は Opacity 0.5 周辺で非常に速く発生します。 V484〜V487 は K = 100 を最適と発見 — 小さい値 (10〜50) は高 Opacity Gaussian も 揺らがせます (収束した Gaussian を破壊)、大きい (> 500) は遷移を人工的に硬くし、 死んだ Gaussian がもう移動されません。
T72mcmcCapMultiplier
詳細
デフォルト: 3.0 (Initializer + .fullMCMC)、2.0 (.mcmcPreview)、 2.5 (.mcmcBalanced)、2.98 (P8 Render)、5.32 (P9 Outdoor)、1.76 (P10 Indoor) 範囲: 0 (= 無効化) または 1.0 – 10.0 定義場所:
技術詳細
1.4.5 機能: シーン適応 Cap スケーリング。T73 mcmcAutoScaleByScene が true の場合、実効 Cap は (バッファ容量にクランプ) として計算されます。 背景: 大きなシーン (例えば 1 545 枚のドローン飛行 → 158 K SfM-init) では T62 = 150 000 が低すぎる — Density Control はまったく成長できません。 Multiplier 3.0 で、この例では Cap が 474 K にスケーリングされます (158 K × 3.0)。 Q7 BayesOpt はシーン固有の最適化を見つけました: Outdoor は高 Multiplier (5.32 → ~830 K Cap at 156 K bicycle-init)、Indoor は 1.76 で満足 (壁がより早く飽和)。 完全な Cap 解決はメソッド参照。
T73mcmcAutoScaleByScene
詳細
デフォルト: true (Initializer + すべての MCMC プリセット) 範囲: boolean 定義場所:
技術詳細
1.4.5 機能: scene-aware Cap ロジック (T72 + 参照) のマスタースイッチ。 false の場合、T62 mcmcMaxGaussians のみが Cap として使用されます (1.4.4 動作に 戻る)。デフォルトでオン、1.4.3 から大きなシーンでの Mass-Extinction 問題がそれ なしで再発するためです。明示的にハード Cap を設定したい場合のみ手動で無効化 — 例えば最終サイズが計画可能な 150 K バリアントをトレーニングするため。
Mip-Splatting (Q1.5) (T74〜T76)
ステータス: Q1.5 は 2026-05-25 に、14 の自律反復 + Overnight 1.5M Confidence Check の後、「closed no-win」として破棄されました (max Δ@2× = +0.27 dB、 オリジナルゲートは 0.5×/2× にわたる平均 ≥ +1.5 dB を要求、11 ペアシーンの 0/11 で FAIL)。フィールドは研究実験用に opt-in のままです。すべての Production プリセットは持ちます。判定参照:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md。
T74useMipSplatting
詳細
デフォルト: false (すべての Production プリセット)、true (.fullMCMCMip — 研究兄弟) 範囲: boolean 定義場所:
技術詳細
Mip-Splatting を有効化 (Yu et al. CVPR 2024): 3D Smoothing Filter + 2D Filter + α 補償、Gaussian あたりの周波数を最も密なトレーニングカメラ サンプリングレートの Nyquist 制限に制限します。理論的な目標: トレーニング外 スケール (0.5× または 2× のトレーニング解像度) でのレンダリングでのエイリアシングの 除去。Preprocess と Backward Projection シェーダーで有効化、Q1.5-D テストで機能的に 正しいと検証されました。しかし: オリジナル受け入れゲート (Δ@1× ≥ +0.3 dB かつ avg(Δ@0.5×、Δ@2×) ≥ +1.5 dB) は 11 ペアシーンのどれでも達成されませんでした。 観測された最大値: family 750K classic Δ@2× = +0.270 dB。屋外シーン (Truck、 Flowers) は 1× と 0.5× で悪化さえ示しました。仮説: 3D Smoothing は high-Gs で MCMC Relocation と競合します。フィールドは正しい Mip-NeRF-360 方法論を持つ将来の Multi-Scale Re-Eval のために残ります (Benchmark パスの O3 バックログ参照)。
T75mipSmoothing3DScale
詳細
デフォルト: 0.2 (Paper デフォルト) 範囲: 0.05 – 1.0 定義場所:
技術詳細
3D Smoothing スケールパラメータ (Yu et al. §3.3、Paper デフォルト 0.2)。 大きい = Gaussian あたりの世界空間スムージングが多い (= より多くのアンチエイリアシング、 しかしデフォルトスケールでより多くのブラー)、小さい = より鮮明だがエイリアシングに 影響を受けやすい。T74 useMipSplatting = true の場合のみ参照されます。Q1.5 テストで さらに最適化されませんでした — A/B ゲートはすでに Paper デフォルト 0.2 で失敗、 さらなるスイープは無駄でしょう。
T76mipFilter2DVariance
詳細
デフォルト: 0.3 (= 正確に V242 レガシー動作) 範囲: 0.1 – 1.0 定義場所:
技術詳細
Σ_2D 対角に追加される 2D Mip Filter 分散 (分散直接、平方ではない)。0.3 は Mip-Splatting 前にカーネルにハードコードされていた正確な V242 レガシー値です。 T74 useMipSplatting = false の場合、カーネルはこの値を完全に無視し、ハードコード された 0.3 を書きます — ベースラインが回帰できないように (Codex Round 1 S3-1 保証)。の場合、ここで設定された値が使用されます。Mip スイープ用に フィールドカタログに残ります。
適応 Densification (Q5) (T77〜T79)
T77adaptiveDensification
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
Q5 機能: 固定 T11 densifyGradThreshold への代替としての rolling-median トラッカー。true の場合、各 Densify ステップで現在の閾値が median(last N avgGrad samples) × T79 adaptiveDensifyMultiplier で上書きされます。 N = T78 adaptiveWindow。V440 p98 (壊滅的な 63 K Pruning トラップ) より厳密、 median + 2× は定常状態の勾配分布の約 p70〜p80 に座ります。Q5 テスト: 単独で 3 シーンの 0 FAIL、しかし Q6 (T80/T81 参照) と一緒に 3 シーンの 1 PASS — Q5+Q6 バンドルは 2026-05-25 に opt-in としてパスし、CLI –adaptive-densify 経由で 有効化可能です。Q6 はそこで品質向上の「キャリア」で、Q5 はむしろ安定性に貢献します。
T78adaptiveWindow
詳細
デフォルト: 1 000 範囲: 100 – 10 000 定義場所:
技術詳細
Densification イベント内の Rolling Median Window (反復ではない — 各 T13 densifyInterval ステップが 1 サンプルを提供します)。デフォルト 1 000 — これは、過去 100 000 のトレーニング反復が中央値に寄与することを意味し、つまり 通常ここまでのトレーニング履歴全体。早期フェーズ (T78 サンプル前): トラッカーは nil を返します → 固定閾値 T11 にフォールバック。アクティブな場合のみ関連。
T79adaptiveDensifyMultiplier
詳細
デフォルト: 2.0 範囲: 1.0 – 4.0 定義場所:
技術詳細
適応閾値用の Rolling Median の Multiplier。デフォルト 2.0 はおおよそ 典型的な勾配分布の p70〜p80 に相当します。低い = より積極的な成長 (より多くの クローン)、高い = より厳密 (より少ないクローン)。Q5 テスト範囲 1.5〜3.0 — 2.0 最高デフォルト。アクティブな場合のみ関連。
Curriculum (Q6) (T80〜T81)
T80curriculumResolutionRamp
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
Q6 機能: トレーニング解像度は 0.5× で開始し、 T50 positionLRScheduleEndIteration / 2 (または T50 が設定されていない場合は T1 maxIterations / 2) で T22 trainingRenderScale に切り替わります。Q1.5.1 で 開発された resize/restoreImageBuffers インフラストラクチャを使用します。 有効化された場合、T23 resolutionWarmupScale を上書きします。Q6 は Q5+Q6 バンドル (T77 参照) で「品質向上のキャリア」としてパス — 段階的な解像度増加は、 アプリに低い解像度で粗いジオメトリを見つける時間を与え、その後細かい詳細作業に 移行します。CLI 経由: –curriculum-resolution。
T81curriculumSHProgression
詳細
デフォルト: false 範囲: boolean 定義場所:
技術詳細
Q6 機能: T21 shDegreeUpgradeIterations を [maxIter/4, maxIter/2, maxIter*3/4] で上書き、SH アップグレードを front-load する代わりにトレーニング時間にわたって均等に分散します。仮説: 安定したジオメトリは カラーディテール爆発の前に確立され、View-Direction 依存の光沢効果がより正確に 配置されます。Q5+Q6 一緒に 3 シーンの 1 PASS、Q6 が利益のキャリア (Q5 単独 FAIL)。 CLI 経由: –curriculum-sh。
静的プリセット (TP1〜TP9)
ここでは Initializer デフォルトとの構造的な違いのみ。10 個の UI プリセット P1〜P10 の 完全なマーケティング説明は第 7 章にあります。
TP1.preview
詳細
≥ 10 GB RAM のシステム用の診断/プレビュープリセット。Initializer に対する オーバーライド: - 30 000 → 5 000 - 15 000 → 3 500 (maxIter の 70%) - 1.6e-6 → 1.6e-5 (10× 高い、あまり積極的でない Decay) -、、、、それぞれ 2× (V176) - 3 000 → 100 000 (事実上オフ、V172: Reset が短いトレーニングを破壊) - [1K, 2K, 3K] → [1K, 2K] (V182: Degree 3 が 2K Iter で収束しない) - 1.0 → 0.5
TP2.full
詳細
Production-Quality Classic。オーバーライド: - 30 000 → 35 000 (V550: 40K テスト Truck 過剰トレーニング Gs で +10.7%、L1 で -1.3%) - 15 000 → 5 000 (V310 スイートスポット、V338 7K 悪い) - すべての LR 2× (V188) - 1.6e-6 → 1.6e-5 (V45 10×) - 2e-6 → 1.1e-6 (V335) - 100 → 200 (V112) - 0.005 → 0.001 (V393) - 3 000 → 100 000 (V194 無効化、V421 確認) - [1K, 2K, 3K] → [2K, 5K, 8K] (V228 遅延) - 0.0 → 0.9995 (V546 HTGS、14% 改善) - 50 (変更なし、V546) - false → true (V438) - 0 → 20 000 (V431) - true (V443、すでに .full の Initializer デフォルト)
TP3.fullClassicPaper
詳細
TP2 の Q1.5-A テスト兄弟、paper 忠実な Classic。TP2 に対するオーバーライド: - 35 000 → 30 000 (Paper 標準) - 5 000 → 15 000 (Paper: maxIter の 50%) - 1.6e-5 → 1.6e-6 (Paper デフォルト) -、、 Paper デフォルトに戻す (0.05、0.005、0.001) - 1.1e-6 → 2e-7 (Bicycle で ~1-2M Gs 用にキャリブレート) - 200 → 100 (Paper) - 0.001 → 0.005 (Paper デフォルト) - 100 000 → 3 000 (Paper §5.2、危険 — V194 リグレッションをトリガーする可能性) - 0.9995 → 0.0 (Paper には Decay なし) - 20 000 → 30 000 (cosine は maxIter の 100% で実行)
TP4.fullMCMC
詳細
Production-Quality MCMC。Initializer に対するオーバーライド: - 30 000 → 200 000 (V534、MCMC は Classic より 5× 多くの Iter が必要) - 15 000 → 160 000 (V504b maxIter の 80%) - 1.6e-6 → 1.6e-5 - LR スケジュール TP2 と同じ (すべて 2×) - 0.2 → 0.05 (V521b/V534: MCMC はより強い L1 信号が必要) - [1K, 2K, 3K] → [2K, 5K, 8K] - .classic → .mcmc - 150 000 (Initializer ですでに、プリセットで確認) - 5e-5 (V467/V536 最適) - 0.005 → 0.01 (V535 最適) - 0 → 160 000 (maxIter の 80%、V497c/V502) - 3.0 (Initializer ですでに) - true (Initializer ですでに) - 3 000 → 200 000 (事実上オフ、MCMC は Reset の代わりに Reloc を使用)
TP5.fullMCMCMip
詳細
TP4 の Q1.5-D テスト兄弟、Mip-Splatting + Paper マグニチュード MCMC バジェット付き。TP4 に対するオーバーライド: - mcmcMaxGaussians 150 000 → 1 500 000 (10×、Paper マグニチュード) - useMipSplatting false → true (Mip オン)
TP6.classicBalanced
詳細
Mid-Tier Classic。TP2 に対するオーバーライド: - 35 000 → 20 000 (V149: 20K = 30K で 33% 少ない時間) - 20 000 → 0 (Cosine が maxIter = 20K で実行、 拡張フェーズなし)
TP7.mcmcPreview
詳細
MCMC 診断。TP4 に対するオーバーライド: - 200 000 → 60 000 (V494b) - 160 000 → 48 000 (80%) - 150 000 → 100 000 (V473b) - 160 000 → 40 000 (V494b) - 3.0 → 2.0 (1.4.5: Preview = より軽いスケーリング)
TP8.mcmcBalanced
詳細
Mid-Tier MCMC。TP4 に対するオーバーライド: - 200 000 → 120 000 (V518) - 160 000 → 96 000 (80%) - 160 000 → 96 000 (80%) - 3.0 → 2.5 (Preview 2.0 と Full 3.0 の間)
TP9.quickTest
詳細
純粋な機能テスト。Initializer に対するオーバーライド: - 30 000 → 1 000 - 15 000 → 500 - 2e-6 → 4e-6 (0.25× 解像度用にキャリブレート) - 100 → 50 - 3 000 → 100 000 (オフ、はるかに短すぎるため) - 1.0 → 0.25
メソッド:
シグネチャ: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int 定義場所:
「MCMC が最大どれだけの Gaussian を成長させられるか?」の質問への 唯一の Source-of-Truth。3 つの入力から計算: 構成された T62 mcmcMaxGaussians (0 の場合 Mass-Extinction Floor 150 000 付き)、 (SfM 初期点の数)、 (事前割り当てされた Gaussian バッファサイズ)。ロジック:
+ base = T62 > 0 ? T62: 150_000 (Mass-Extinction Floor は 1.4.3 Mass-Extinction 事故などの Initializer デフォルトバグを防ぎます) + T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0 の 場合: - scaled = max(base, ceil(initialPointCount × T72)) そうでなければ + bufferCapacity > 0 の場合: return min(scaled, bufferCapacity) + そうでなければ return scaled
例: Bicycle (Mip-NeRF 360、194 写真フレーム) → SfM-init ~156 K 点、 T62 = 150 000、T72 = 5.32、、バッファ容量 8 M。Resolved Cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K。これが MCMC Relocation ロジックが従う実効成長 Cap です。
MCMC での実際の最大 Splat 数を計算します。設定を取り、シーンが最初にどれだけの点を持つかを見て、 自動調整がオンの場合は Multiplier でスケーリングします。これにより、小さなシーンと 巨大なシーンに同じ値を強制する代わりに、Cap がシーンに適応します。メソッドを自分で 呼び出す必要はありません — トレーニングが内部で使用します。
どのフィールドが何のためか? (チートシート)
| 目的 | 調整するフィールド |
|---|---|
| 遠くでより多くのディテール | T62 mcmcMaxGaussians 高、 T72 mcmcCapMultiplier 5+ |
| 一般的により多くのディテール (Classic) | T1 maxIterations 高 (≤ 40K)、 T2 densifyUntilIteration T1 の ≤ 14% |
| ドローン飛行で Floater を削減 | T43 frustumCullEnabled オン、 T20 skyMaskingEnabled オン、T45 skyDomeEnabled オン |
| 屋外シーンの美しい空 | T45 skyDomeEnabled オン、 T47 skyDomeRadiusMultiplier 30〜60 |
| 小さいエクスポートファイル | 戦略 .mcmc (T61)、 T56 postTrainingCompactification オン、T62 mcmcMaxGaussians ≤ 200K |
| より速いトレーニング | T22 trainingRenderScale 0.5、 T1 maxIterations 半分 — ただし両方ではない! |
| より良いハイライト | T21 shDegreeUpgradeIterations を [2K, 5K, 8K] (early-front-load なし)、MCMC + 200K iter |
| Mac を応答可能に保つ | T25 throttleDelayMs 5〜10 (~15% のトレーニング時間をコスト) |
| より頻繁なライブプレビュー | T59 livePreviewInterval 10〜20 に下げる |
| シャドウでより柔らかい遷移 | T17 ssimWeight 少し高く (0.15〜0.25)、ただし 0.3 を超えない |
| 室内をコンパクトに保つ | P10 Indoor プリセット (、 T72 = 1.76) |
危険なフィールド
これらのフィールドは、誤って構成された場合、OOM、アプリクラッシュ、Gaussian の Mass-Extinction、または使用できないベンチマークデータにつながる可能性があります。 慎重に扱ってください:
- T11 densifyGradThreshold — 半分にすると 2〜4× の Gaussian を生成し、 GPU メモリを急速に圧迫する可能性があります。また注意: T22 trainingRenderScale に 一致する必要があります (1.0× → 1e-6、0.5× → 2e-6、0.25× → 4e-6)。 - T72 mcmcCapMultiplier — > 200 K の SfM-init 点と Multiplier > 5 を持つ大きなシーンでは、数百万の Gaussian の Resolved Cap が形成されます。 36 GB RAM Mac では OOM の可能性。Outdoor プリセット 5.32 は Mip-NeRF-360-Bicycle が 156 K init 点を持つためにのみ機能 → 830 K Cap。 - T39 testViewIndices — 手動設定はベンチマークを使用不可にする可能性 があります (すべてのインデックス > N → Holdout なし)。–benchmark フラグに 設定させてください。 - T64 mcmcOpacityRegWeight および T65 mcmcScaleRegWeight — 1.4.3 ベータでは 0.01 に設定され、Mass-Extinction (1 反復で 460 K → 5 Gaussian) に つながりました。1.4.4 以降 0.0 に固定されていますが、手動で増加させると問題を 再現できます。 - T15 opacityResetInterval — 100 000+ (事実上オフ) でなく、トレーニング が 10 000 反復より短い場合、Reset が収束を破壊します。.preview は maxIterations = 5 000 にもかかわらず、そのため 100 000 を持ちます。 - T54/T55 densifyPhase2* — Two-Phase Densification はテストで 0 Gaussian カスケードで中止されました。両方を 0 のままにします。 - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25、一部の屋外 シーンで PSNR を悪化させることさえあります。デフォルトオフ、研究のみの opt-in。
このリストにあるフィールドを変更したい場合は、事前に現在のプリセットのバックアップを 作成 (JSON としてエクスポート) し、結果を再現可能に測定できるかを検討してください — そうしないと、後で改善または悪化を取得したかどうかわかりません。