제 6 장 — 학습 구성
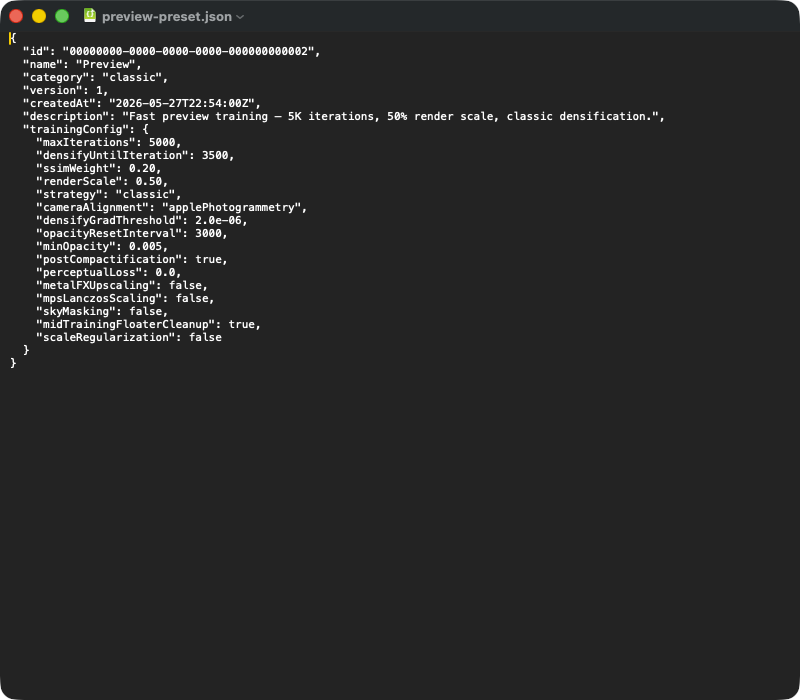
일반적인 프리셋 JSON 내보내기입니다. 최상위 필드: id (UUID), name, 카테고리 (classic | mcmc | sceneClass | custom), 버전 (스키마 버전), createdAt (타임스탬프), description (자유 텍스트). 중첩된 trainingConfig 객체는 재현성에 결정적인 매개변수를 포함합니다 — 가져오기 시 전체 블록이 TrainingConfig 구조로 역직렬화되고 앱 버전의 기본값이 JSON에 없는 필드를 채웁니다 (예: 앱 업데이트 후). 다른 Mac에 프리셋을 전달하려는 사람은 단순히 이 JSON 파일을 보내면 됩니다.
TrainingConfig 구조는 RadianceKit의 모든 학습 실행의 핵심입니다. 학습에 영향을 미치는 모든 매개변수를 모아 둡니다 — 최대 반복 수에서 여덟 학습률, MCMC, Mip-Splatting, Curriculum, 장면 인식 Cap 로직의 특수 필드까지. Training Configuration 섹션 (Expert View) 의 사이드바에서 편집하고, 프리셋으로 저장하거나 JSON 내보내기로 다른 Mac에 전달합니다. 학습 시 정확히 이 객체가 동결되어 GPU 백엔드에 전달됩니다.
이 장은 파워 유저와 스크립트 작성자를 위한 참조 자료입니다. 81개의 모든 공개 필드, 9개의 정적 프리셋, 그리고 하나의 공개 메서드를 나열합니다. 소스 파일은 TrainingConfig.swift입니다 — 의심이 있다면 거기에 저장된 Doc Comment와 이니셜라이저 기본값이 Source-of-Truth 입니다.
목차:
+ Iteration (T1–T2) + Learning Rates (T3–T10) + Densification — Classic (T11–T16) + Loss (T17–T20) + SH-Degree-Progression (T21) + Performance (T22–T25) + 진단과 점 구름 준비 (T26–T30) + 정규화 (T31–T37) + Refinement (T38–T44) + Sky-Dome (T45–T48) + Adam + LR 스케줄 (T49–T55) + Post-Processing + Apple AI (T56–T60) + MCMC Densification (T61–T73) + Mip-Splatting (Q1.5) (T74–T76) + Adaptive Densification (Q5) (T77–T79) + Curriculum (Q6) (T80–T81) + 정적 프리셋 (TP1–TP9) + 메서드: resolveMcmcMaxGaussians + 어느 필드를 무엇을 위해? (치트 시트) + 위험한 필드
Iteration (T1–T2)
T1maxIterations
세부 정보
기본값: 30 000 (이니셜라이저), 35 000 (.full), 200 000 (.fullMCMC) 범위: 1 000 – 500 000 (UI 슬라이더), 로직에 하드 상한 없음 정의 위치: TrainingConfig.swift
기술적 설명
백엔드가 통과하는 총 학습 반복 수. 한 반복은 단일 학습 카메라의 Forward Render, 모든 Loss 구성 요소 (L1 + SSIM + 선택적 정규화 + Sky Mask) 에 대한 Backward Pass, 그리고 하나의 Adam 옵티마이저 단계를 의미합니다. 이 숫자는 다른 스케줄에 직접 영향을 줍니다: Position 학습률은 0에서 T1 자체 또는 T49 positionLRScheduleEndIteration까지의 Cosine Annealing 곡선을 따르고, Densification은 T2 densifyUntilIteration에서 멈추며, MCMC 노이즈 감쇠는 T69 mcmcNoiseDecayEnd에서 종료되고, SH-Degree 업그레이드는 T21에 정의된 세 표시에서 발생합니다. 고전적 Densification의 경우 경험적으로 결정된 스위트 스폿은 20 000–35 000 반복 (Sessions 1–32, V546 테스트), MCMC는 60 000–200 000 (V534) 입니다. 프리셋에 저장된 값을 훨씬 초과하여 극단적으로 늘리면 추가 품질이 거의 나오지 않습니다 — Adam Momentum이 포화되고, LR Decay 종료 없이는 Loss가 정체됩니다. 반대로 ~5 000 미만으로 떨어지면 완전히 수렴되지 않은 형상으로 이어집니다 (Density Control이 클론/스플릿할 시간이 너무 적음).
T2densifyUntilIteration
세부 정보
기본값: 15 000 (이니셜라이저), 5 000 (.full), 160 000 (.fullMCMC) 범위: 0 – maxIterations 정의 위치: TrainingConfig.swift
기술적 설명
Densification이 중지되는 반복. 이때까지 Gaussian은 T11–T16 (Classic) 또는 T67–T70 (MCMC) 에 매개변수화된 규칙을 통해 복제, 스플릿, 정리됩니다. 그 후 Gaussian 수는 일정하게 유지되며 위치, 회전, 스케일, Opacity, SH 계수만 최적화됩니다 (Refinement 단계). 3DGS 원본 논문에서는 값이 T1의 50%이지만 RadianceKit의 .full 프리셋에서는 약 14% (35 000 중 5 000) — V310/V338 실험의 결과로, 5 000 반복 후 추가 Densification이 결과를 악화시키는 경향이 있음을 보여 주었습니다 (더 많은 플로터, 더 많은 메모리 사용량, 품질 이득 없음). 반면 MCMC는 Relocation을 T1의 80%까지 실행합니다 (V504b). MCMC는 해로운 플로터를 생성하지 않기 때문입니다. T2를 너무 작게 (< 1 000) 선택하면 너무 적은 Gaussian이 생성됩니다. Classic에서 너무 크면 (> T1의 50%) Overgrowth와 RGB-Saturation 아웃라이어로 이어집니다 (Outdoor Overtraining Findings 참고).
Learning Rates (T3–T10)
T3positionLearningRate
세부 정보
기본값: 0.00016 범위: 1e-7 – 1e-3 (권장) 정의 위치: TrainingConfig.swift
기술적 설명
학습 시작 시 (Iteration 0) 각 Gaussian의 XYZ 위치에 대한 Adam 학습률. Cosine Annealing 곡선을 따르고 학습 진행 과정에서 T4 positionLearningRateFinal로 감소합니다. 기본값 0.00016은 3DGS 원본 논문 (Kerbl 외 2023) 에서 가져왔으며 이미지 해상도를 늘려도 RadianceKit에서 스케일링할 필요가 없습니다 — 위치는 픽셀 공간이 아닌 세계 좌표계에서 움직입니다. 상당히 높이면 (> 0.0005) Gaussian이 긴 거리에 걸쳐 점프하고 Loss가 불안정해집니다. 훨씬 낮은 값 (< 0.00005) 은 잘못 초기화된 점 구름이 자리를 찾지 못하게 합니다. V414는 Init 값의 두 배를 테스트했습니다 → 16.8% 더 나쁜 L1 Loss. V544a 튜닝은 논문 기본값을 최적으로 확인했습니다. 참고: .fullMCMC에서는 의도적으로 이 값을 기본값으로 둡니다 — MCMC는 Relocation 로직에 일정한 학습률이 필요하므로 여기서 튜닝해도 가져오는 것이 없습니다.
T4positionLearningRateFinal
세부 정보
기본값: 0.0000016 (이니셜라이저 + 논문), 0.000016 (.full, .fullMCMC — 10배 더 높음) 범위: 0 – positionLearningRate 정의 위치: TrainingConfig.swift
기술적 설명
Position LR Cosine Annealing 곡선의 최종 값. T1 maxIterations 또는 설정된 경우 T49 positionLRScheduleEndIteration에서 도달합니다. RadianceKit .full 프리셋은 0.000016을 사용합니다 — 논문 기본값 0.0000016보다 10배 더 높습니다. V420 실험에서는 최종 값의 0.5배 (0.000008) 가 Loss를 6.4% 악화시킨다는 것을 보여 주었고, V414는 Init 값의 2배가 Loss를 16.8% 악화시킨다는 것을 보여 주었습니다. 높은 최종 값은 트레이드오프가 아니라 의식적인 선택입니다: Decay가 너무 강하면 Gaussian이 Refinement 단계 동안 새로 추가된 Densification 후보에 적응하는 능력을 잃습니다. V431/V433 확장을 통해 스케줄 단계를 단축할 수 있어 (T49 < T1), T4가 학습 종료 전에 이미 도달하고 학습의 나머지가 일정한 미니 LR로 실행됩니다 — 일반적인 구성: T49 = 20 000, T1 = 35 000, 따라서 Refinement는 15 000 반복 동안 0.000016에서.
T5shDCLearningRate
세부 정보
기본값: 0.0025 (이니셜라이저 + 논문), 0.005 (.full과 모든 MCMC 프리셋 — 2배) 범위: 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
Spherical Harmonic 색상의 DC 부분 (degree 0, 즉 일정한 Albedo) 에 대한 Adam 학습률. SH-DC는 Gaussian의 방향 독립적 기본 톤에 해당하며, 어떻게 보면 "기본 색상"입니다. V176 및 V188 실험에서 논문 기본값보다 2배 더 높은 것이 최적임을 발견했습니다 — 더 빠른 색상 수렴, 특히 짧은 학습 (예: 5 000 반복) 에서는 그렇지 않으면 SH-DC가 정상으로 들어오지 않기 때문입니다. 기하학적 LR과 달리 SH-DC는 Decay가 없습니다. 학습률은 모든 반복에 걸쳐 일정하게 유지됩니다 (또는 T51의 선택적 Extended Phase Decay만 따름). V416은 4배 0.01로 증가를 테스트했습니다 → beta2=0.99 Adam에서 6.4% 더 나쁜 Loss.
T6shRestLearningRate
세부 정보
기본값: 0.000125 (이니셜라이저 + 논문), 0.00025 (.full과 MCMC — 2배) 범위: 0.000001 – 0.005 정의 위치: TrainingConfig.swift
기술적 설명
더 높은 차수의 SH 계수 (Degree 1, 2, 3 — 즉 하이라이트, 반사, 부드러운 음영을 담당하는 View Direction 의존 색상 구성 요소) 에 대한 Adam 학습률. 논문 규약에 따라 T5보다 20배 작습니다. 이 계수가 수에서 이차적으로 증가하기 때문입니다 (Degree 1의 경우 3, Degree 2의 경우 5, Degree 3의 경우 7 → Gaussian당 총 15 Float) 더 작은 학습률 없이는 이미지가 과포화될 것입니다. 두 단계로 잠금 해제됩니다 — T21 shDegreeUpgradeIterations의 첫 번째 마크까지는 Degree 0만 활성 (즉 T5만), 그 후 1, 그 다음 2, 마지막으로 3. 디퓨즈 조명이 많은 장면에서 여기에 낮은 값이 특히 중요합니다. 매우 광택이 있는 표면 (자동차 페인트, 물) 에서는 조정해도 가치가 없습니다 — SH 표현 자체가 제한적입니다.
T7opacityLearningRate
세부 정보
기본값: 0.05 (이니셜라이저 + 논문), 0.1 (.full, MCMC — 2배) 범위: 0.001 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
각 Gaussian의 logit Opacity에 대한 Adam 학습률. 앱은 Opacity를 제한되지 않은 Float 값으로 저장하고 Sigmoid로 [0, 1] 로 변환합니다. LR은 Logit Space에서 작용합니다. V50 테스트 (Best Single-Run L1 0.1664) 후 논문 기본값 0.05가 복원되었습니다. V71은 V67의 0.025를 revert했습니다. V188의 0.1로의 두 배는 Pruning을 더 효율적으로 만듭니다 — 죽은 Gaussian이 T14 pruneOpacityThreshold 아래로 더 빨리 떨어집니다. V418은 다음을 보여 주었습니다: beta2=0.99 Adam의 0.05는 0.1보다 7.1% 나쁩니다 — Adam 구성과의 상호작용은 사소하지 않습니다. 낮은 값 (< 0.01) 은 "죽은" Gaussian이 영원히 주위에 누워 있고 메모리를 소비하게 합니다. 너무 높은 값 (> 0.5) 은 Opacity 폭발로 이어질 수 있으므로 Logit 값이 옵티마이저에서 [-15, 3] 으로 클램프됩니다 (CLAUDE.md의 "Opacity Explosion Prevention" 참고).
T8opacityLearningRateFinal
세부 정보
기본값: 0.0 (= "Decay 없음") 범위: 0 또는 0.001 – opacityLearningRate 정의 위치: TrainingConfig.swift
기술적 설명
Opacity LR의 선택적 Cosine Decay 최종 값 (V427). 0.0이면 Decay가 비활성화되고 Opacity LR이 전체 학습에 걸쳐 T7에서 일정하게 유지됩니다. V427은 Decay 0.1 → 0.01을 테스트했습니다 — 결과 11.5% 나쁜 Loss. revert되었으므로 기본값은 "꺼짐". 필드 뒤의 가설: Refinement 단계에서 일정한 Opacity LR이 진동으로 이어질 수 있어, 이미 올바른 투명도 수준에 도달한 Splat이 무작위 그래디언트 변동에 의해 다시 이동될 수 있다는 것. 경험적으로 확인되지 않습니다 — Logit 클램핑 로직이 어쨌든 이를 잡습니다. 필드는 향후 실험을 위해 사용 가능한 채로 유지됩니다. 매우 긴 MCMC 실행 (> 500K 반복) 도 이로부터 혜택을 받을 수 있습니다.
T9scaleLearningRate
세부 정보
기본값: 0.005 (이니셜라이저 + 논문), 0.01 (.full, MCMC — 2배) 범위: 0.0001 – 0.1 정의 위치: TrainingConfig.swift
기술적 설명
Log Space의 각 Gaussian의 세 스케일 구성 요소에 대한 Adam 학습률 (RadianceKit은 스케일이 양수로 유지되도록 log(scale) 을 저장합니다). 논문 기본값 0.005, RadianceKit에서는 최적화된 학습률 구성에서 더 나은 스케일 수렴을 위해 0.01로 두 배. V423 실험: beta2=0.99 Adam의 0.005 → 18.7% 더 나쁜 Loss와 눈에 띄게 너무 적은 Gaussian (Density Control이 클론할 수 없었음, 스케일 업데이트가 너무 느렸기 때문에). 스케일은 각 Gaussian의 확장을 제어합니다 — 너무 빠른 학습은 "Needle" Gaussian (극도로 길고 얇은 Splat, T34 scaleRatioPruneThreshold 참고) 으로 이어지고, 너무 느린 학습은 Splat이 너무 콤팩트하게 유지되어 Density Control이 너무 자주 스플릿해야 합니다.
T10rotationLearningRate
세부 정보
기본값: 0.001 (이니셜라이저 + 논문), 0.002 (.full, MCMC — 2배) 범위: 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
각 Gaussian의 네 쿼터니언 구성 요소에 대한 Adam 학습률. 쿼터니언은 각 옵티마이저 단계에서 Adam 업데이트 후 다시 정규화됩니다 (L2 Norm = 1) — 그렇지 않으면 공분산 행렬이 퇴화될 것입니다. RadianceKit은 Quality 프리셋에서 논문 기본값을 두 배로 늘립니다. 스케일/위치에 비해 회전이 더 작은 절대 그래디언트 크기를 가지기 때문 (단위 구체에서 각 단계가 짧게 유지됨) 이고 2배 없이는 회전이 35 000 반복 윈도우에서 상당히 under-converged 될 것이기 때문입니다. V188에 문서화되어 있습니다. NeRF Blender 장면 (Lego, Chair) 에서는 회전이 특히 영향을 미칩니다 — 객체의 가장자리는 5 000–10 000 반복 후에야 올바르게 정렬됩니다.
Densification — Classic (T11–T16)
T11densifyGradThreshold
세부 정보
기본값: 0.000002 (이니셜라이저, 0.5배 해상도용으로 보정), 0.0000011 (.full, 1.0배용으로 보정), 0.000004 (.quickTest, 0.25배용으로 보정), 2e-7 (.fullClassicPaper) 범위: 1e-8 – 1e-3 (해상도 의존) 정의 위치: TrainingConfig.swift
기술적 설명
Screen Space에 투영된 그래디언트 dMean2D의 L2 Norm 임곗값. 이를 초과하면 Gaussian이 클론 또는 스플릿용으로 표시됩니다. 절대값은 학습 해상도에 직접 의존합니다 — dMean2D는 대략 1/해상도² 처럼 스케일됩니다 (더 많은 픽셀 = 더 작은 픽셀당 그래디언트). 따라서 각 T22 trainingRenderScale 단계는 보정된 임곗값을 필요로 합니다: 0.25× → 4e-6, 0.5× → 2e-6, 1.0× → 5e-8 … 1.1e-6 (.full). 논문 기본값 0.0002는 NDC 정규화되어 있고 RadianceKit의 세계 공간 파이프라인에서 직접 비교할 수 없습니다. V440에서 활성화된 T52 adaptiveDensifyThreshold 플래그를 사용하면 값을 현재 그래디언트 분포의 p98에서 런타임에 계산할 수 있지만 — V440은 실제 장면에서 이를 테스트하고 63 K Gaussian을 생성했습니다 (재앙적인 Pruning 손실). 플래그는 꺼진 채로 유지됩니다. Q5 (T77–T79) 는 Rolling Median을 통한 대체 Adaptive 로직을 제공합니다. 이 필드는 위험합니다 — 절반으로 줄이면 2–4배 더 많은 Gaussian이 생성됩니다 (메모리 압력, OOM 위험). 두 배로 늘리면 장면이 under-densify될 수 있습니다.
T12densifyFromIteration
세부 정보
기본값: 500 범위: 100 – 5 000 정의 위치: TrainingConfig.swift
기술적 설명
Densification이 활성화되는 첫 번째 반복. 그 전에는 초기 SfM 점 구름에서 "벗은" 학습만 발생하고 새 Gaussian이 생성되지 않습니다. 기본값 500은 3DGS 논문에서 왔으며 초기화에 안정화될 시간을 제공합니다 — Iteration 0부터 이미 Densification이 시작되면 잘못 배치된 SfM 점이 올바른 위치를 찾기 전에 여러 번 복제됩니다. V349는 1000을 테스트했습니다 → 약간 더 나쁜 Loss. 기본값이 최적입니다.
T13densifyInterval
세부 정보
기본값: 100 (이니셜라이저, MCMC), 200 (.full) 범위: 50 – 1 000 정의 위치: TrainingConfig.swift
기술적 설명
두 Densification 단계 사이의 반복 수. 논문 기본값 100 — 매 100회 반복마다 Densify 후보 목록이 평가되어 클론/스플릿되고 동시에 Prune 후보 목록 (sigmoid(opacity) < T14 pruneOpacityThreshold) 이 제거됩니다. V112 테스트는 .full의 경우 200이 최적임을 발견했습니다 — 더 적은 재구성 패스가 실행되므로 GPU 부하가 줄어들고, 각 Gaussian에게 Clone 작업 후 안정화할 더 많은 시간을 제공합니다. V417은 beta2=0.99에서 100을 테스트했습니다 → 5.8% 더 나쁨 (957 K Gaussian, 과 Densification). MCMC에서는 동일한 필드가 Relocation Interval로 해석됩니다. MCMC 특정 로직은 T67 mcmcRelocationInterval을 참고하십시오.
T14pruneOpacityThreshold
세부 정보
기본값: 0.005 (이니셜라이저, 논문, MCMC), 0.001 (.full) 범위: 0.0001 – 0.1 정의 위치: TrainingConfig.swift
기술적 설명
다음 Densification 단계에서 Gaussian이 삭제되는 Sigmoid Opacity 임곗값. T7 opacityLearningRate 및 옵티마이저의 Logit Clamp 로직과 함께 작용합니다. V393은 .full에서 기본값을 0.005에서 0.001로 낮추었습니다 — 결과: 이국적인 시점에서만 역할을 하는 Splat이 더 오래 보존되고 SH 세부 정보에 기여합니다. V394는 0.0001을 테스트했습니다 → 약간 더 나쁨 (너무 적게 정리됨, 메모리 낭비). 중요: Density Control은 항상 정리해야 합니다. 다른 조치로 버퍼 용량이 이미 가득 차 있더라도 ("Density Control Must Always Prune" 참고 CLAUDE.md) — 그렇지 않으면 죽은 Gaussian이 누적되고 카운트가 멈춥니다.
T15opacityResetInterval
세부 정보
기본값: 3 000 (이니셜라이저 + 논문), 100 000 (.full = 효과적으로 비활성화), 200 000 (.fullMCMC = 비활성화) 범위: 1 000 – 100 000+ 정의 위치: TrainingConfig.swift
기술적 설명
모든 Gaussian의 Opacity가 낮은 값 (~0.01) 으로 재설정되는 간격 (반복 수) — "동결된" Splat을 재평가하기 위한 3DGS 논문의 조치. V194는 RadianceKit의 Warmup + 확률적 학습 설정 + 2배 학습률에서 Opacity Reset이 5.5% 품질이 들고 Logit Clamp가 이미 Reset 기능을 다룬다는 것을 보여 주었습니다. 따라서 .full에서는 실질적으로 비활성화됩니다 (100 000 > 35 000 = 절대 트리거되지 않음). V421은 beta2=0.99로 3 000마다 Reset을 테스트했습니다 → 4.9% 더 나쁨. revert됨. .fullClassicPaper (Q1.5-A, 논문 충실 테스트) 에서는 의도적으로 다시 3 000으로 설정되어 있습니다 — 논문 규모 Gaussian 예산을 달성하기 위한 레버 중 하나였습니다.
T16maxScreenSize
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 (off) 또는 > 0 정의 위치: TrainingConfig.swift
기술적 설명
Gaussian이 강제로 스플릿되기 전에 도달할 수 있는 Screen Space 최대 크기 (투영된 픽셀 단위). 값은 0으로 설정됩니다 (V48 테스트 및 revert) — RadianceKit의 Density Control은 대신 dMean2D 로직의 세계 공간 스케일 임곗값을 사용합니다. 향후 Mip-Splatting (T74–T76) 이나 장면별 Splatting 전략 실험이 이로부터 혜택을 받을 수 있기 때문에 필드 카탈로그에 남아 있습니다. 활성화 (값 > 0, 예: 20) 는 매우 커진 Splat이 화면에서 강제로 분할되도록 합니다 — 단일 거대 Splat이 너무 적은 세부 정보를 제공하는 크고 매끄러운 벽 표면에 관련이 있습니다.
Loss (T17–T20)
T17ssimWeight
세부 정보
기본값: 0.2 (이니셜라이저 + 논문 + .full), 0.05 (모든 MCMC 프리셋) 범위: 0.0 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
결합된 Loss 함수에서 D-SSIM 부분의 가중치 loss = (1 - λ) * L1 + λ * D-SSIM, 여기서 λ = T17. 3DGS 논문 기본값 0.2는 Classic Densification에 최적입니다 — V383은 0.3을 테스트했습니다 → 28.9% 더 나쁨. V373b는 0.2를 스위트 스폿으로 확인했습니다. MCMC의 경우 V521b/V534에서 독립적으로 0.05가 최적임이 밝혀졌습니다. MCMC가 확률적 탐색을 통해 더 강한 L1 신호 부분을 필요로 하기 때문입니다 — 더 높은 SSIM 가중치는 Relocation 결정을 희석할 것입니다. SSIM은 L1보다 계산 비용이 훨씬 비쌉니다 (전체 이미지에 걸친 로컬 11×11 윈도우). RadianceKit은 1080p 이미지당 1 ms 미만으로 유지되는 MPS 가속 구현을 사용합니다. Q7-BayesOpt Sweep은 0.05 (.outdoorPreset: 0.082) 와 0.171 (.indoorPreset) 사이의 장면별 최적값을 발견했습니다.
T18ssimWeightRefinement
세부 정보
기본값: 0.0 (= "전환 없음, ssimWeight 유지") 범위: 0 또는 0 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
T2 densifyUntilIteration 후 Refinement 단계의 선택적 SSIM 값. V428은 Refinement에서 0.2 → 0.3을 테스트했습니다 → 16% 더 나쁜 Loss (L1과 SSIM 모두 악화). revert됨, 따라서 기본값 0.0. 필드 뒤의 가설은 Densification 후 — 더 이상 새 Gaussian이 생성되지 않을 때 — 더 강한 SSIM 부분이 구조적 선명도를 최대화할 것이라는 것이었습니다. 경험적으로 잘못됨: SSIM 가중치를 늘리는 것은 간접적으로 L1 가중치를 낮추는 것을 의미하고, L1은 최종 Refinement 단계에서 훨씬 더 의미 있는 신호입니다. 필드는 Perceptual Loss (T60) 또는 Edge Loss (T19) 의 향후 실험을 위해 사용 가능한 채로 유지되며, 거기서는 Refinement 특정 Loss 구성이 의미가 있을 수 있습니다.
T19edgeLossWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.001 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
V437 실험적 Loss: L1+SSIM에 추가로 이미지 가장자리를 직접 비교하는 Sobel Gradient Domain L1 Loss의 가중치 (Ground Truth Sobel vs Render Sobel). 가설: 가장자리 정보가 이미지 품질의 인식적 초석이며 명시적 항이 Gaussian이 가장자리를 더 잘 맞추도록 장려해야 합니다. 테스트 결과: 가중치 0.1 → 11% 더 나쁜 Loss, 0.01 → 품질 중립이지만 10% 더 느림. Sobel 패스는 Ground Truth와 Render에 추가 MPS Forward 비용이 듭니다. 따라서 영구 비활성화. 향후 사용 사례: 단단한 인공 가장자리 (건축, 가구, 렌더링) 가 있는 장면이 혜택을 받을 수 있습니다 — Q7-Scene-Class 프리셋은 이를 선택하지 않고 대신 SSIM 가중치를 스케일 조정했습니다.
T20skyMaskingEnabled
세부 정보
기본값: false (이니셜라이저와 모든 프리셋) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
Sky Masking을 켭니다. 각 이미지에서 Apple Vision 프레임워크 (VNGenerateForegroundInstanceMaskRequest) 를 통해 하늘 영역이 마스크되고 이 영역의 Loss가 0으로 설정됩니다. 의의: 야외 장면은 종종 파란색/회색/흰색 하늘 픽셀이 앱이 정확히 거기에 Gaussian을 배치하도록 하는 것으로 고통받습니다 — 이는 "플로터"로 인식됩니다. Sky Mask 없이는 이 영역의 Loss가 절대 0이 되지 않을 것입니다. 이미지의 하늘이 약간 변하고 앱이 Splat으로 영원히 다시 만들려고 시도하기 때문입니다. Vision 마스크는 학습 전에 카메라당 한 번 계산되어 RAM에 보관됩니다. 일반적으로 T45 skyDomeEnabled와 함께 활성화됩니다 (Settings View의 UI 로직). 실내 장면이나 합성 렌더링에서는 비활성화 상태로 두십시오 — 마스크가 거기서 잘못 천장이나 벽을 "Sky"로 인식할 것입니다.
SH Degree Progression (T21)
T21shDegreeUpgradeIterations
세부 정보
기본값: [1_000, 2_000, 3_000] (이니셜라이저), [2_000, 5_000, 8_000] (.full, MCMC), [1_000, 2_000] (.preview — Degree 3 건너뜀) 범위: [Int], 각 값이 [0, maxIterations] 안에, 단조 증가 정의 위치: TrainingConfig.swift
기술적 설명
활성 SH Degree가 0→1, 1→2, 2→3으로 업그레이드되는 반복. 첫 마크 전에는 DC 구성 요소만 활성 (즉 T5 shDCLearningRate), 첫 마크 후 DC + 3 Degree-1 계수, 두 번째 마크 후 + 5 Degree-2 계수, 세 번째 마크 후 모든 15 계수. Gaussian당 메모리 요구량이 단계로 증가합니다 — 4 Float → 16 Float → 36 Float → 64 Float. Quality 프리셋은 이니셜라이저 기본값에 비해 업그레이드를 지연합니다 (V228). 색상 디테일이 더 높은 주파수로 추가되기 전에 형상이 먼저 안정화되어야 하기 때문입니다. V384는 .full에 대해 [1K, 2K, 3K]를 테스트했습니다 → 9.3% 더 나쁨 — 지연을 확인합니다. .preview는 Degree 2에서 자릅니다. Degree 3은 5 000 반복에서 수렴하지 않고 옵티마이저 용량만 소비하기 때문입니다. Q6 (T80–T81) 는 이 목록을 동적으로 재정의하는 대체 Curriculum 로직을 제공합니다.
Performance (T22–T25)
T22trainingRenderScale
세부 정보
기본값: 1.0 (이니셜라이저, .full, MCMC, Scene-Class), 0.5 (.preview), 0.25 (.quickTest) 범위: 0.05 – 2.0 (일반적으로 0.25, 0.5, 1.0) 정의 위치: TrainingConfig.swift
기술적 설명
학습 이미지의 원본 해상도에 상대적인 학습 시 렌더 해상도. 0.5에서 각 이미지가 50% 폭 × 50% 높이 (즉 픽셀의 25%) 로 다운샘플링되고 Gaussian 렌더링이 이 더 작은 해상도에서 발생합니다. 메모리와 계산 오버헤드를 모두 이차적으로 줄입니다. 중요: T11 densifyGradThreshold가 선택된 해상도와 일치해야 합니다 — 그래디언트 크기가 1/해상도²로 스케일되므로 .quickTest (0.25×) 는 .full (1.0×, 1.1e-6) 보다 훨씬 더 높은 임곗값 (4e-6) 을 가집니다. RadianceKit은 매우 큰 이미지에 경고하고 자동으로 조정합니다 — 3 MP 목표 해상도. 극단적인 4K 입력 이미지에서는 0.5 또는 심지어 0.25가 의미가 있습니다. 그렇지 않으면 모든 Mac이 CPU Compaction에서 실행됩니다.
T23resolutionWarmupScale
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.1 – trainingRenderScale 정의 위치: TrainingConfig.swift
기술적 설명
V133 최적화: Refinement 단계보다 낮은 해상도에서 Densification 단계 (Iter 0에서 T2까지) 를 학습합니다. V308은 .full을 다시 비활성화했습니다. T22 = 1.0과 Cosine Annealing에서 Time-Win이 미미하고 품질이 최소로 들었기 때문입니다. 4K 입력과 긴 학습 실행에서 다시 의미가 있을 수 있기 때문에 필드 카탈로그에 유지됩니다 — Q6 Curriculum (T80) 이 비슷한 로직을 채택했고 거기서는 LR 스케줄과 결합되어 있습니다. 활성화되고 T80 curriculumResolutionRamp도 true이면 Q6가 우선하고 이 값을 덮어씁니다.
T24tileSize
세부 정보
기본값: 16 범위: 8, 16, 32 정의 위치: TrainingConfig.swift
기술적 설명
픽셀 단위의 래스터화 타일 크기. Gaussian Splatting 렌더링은 타일 기반입니다: 이미지가 16×16 픽셀 타일로 분해되고 각 타일이 관련 Gaussian을 모아 깊이별로 정렬한 다음 블렌딩합니다. 16은 실질적으로 모든 3DGS 구현이 사용하는 표준이며 RadianceKit Metal 커널에서 하드코딩되어 있습니다. 이 값을 변경하면 셰이더의 재컴파일이 필요하며 현재 상태에서는 효과적이지 않습니다. 향후 엔진 버전이 Tile Size를 동적으로 지원할 경우를 위해 필드로 남아 있습니다.
T25throttleDelayMs
세부 정보
기본값: 0 (이니셜라이저, .full, MCMC, Scene-Class), 0 (.preview) 범위: 0 – 100 정의 위치: TrainingConfig.swift
기술적 설명
학습 반복 사이의 인위적인 지연 (밀리초). 0 = 풀 스피드 (표준). 더 높은 값은 GPU/CPU가 정기적으로 호흡할 휴식을 받게 하여 학습 중 Mac을 "사용 가능"하게 만듭니다 — 다른 앱의 사용성은 증가하지만 학습 시간은 Delay와 선형적으로 증가합니다. 일반적인 값: 1–2 ms ("가벼운" Throttling, +5% 학습 시간, Mac이 더 반응적으로 느껴짐), 5 ms ("중간", +15% 학습 시간), 10+ ms ("Eco", 잠재적으로 두 배 학습 시간). Inspector의 "Performance"에서 제공되지만 표준 보기에는 없습니다 — dev_ux-backlog.md를 참고하십시오. 잘못 이해되면 학습 시간을 극적으로 연장하기 때문에 Expert View에서 제거하자고 제안합니다.
진단과 점 구름 준비 (T26–T30)
T26depthDistortionWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
V366 실험적: Depth Distortion 정규화 Loss의 가중치. 렌더 광선을 따라 깊게 배치되어 있지만 개념적으로 같은 표면에 속하는 Gaussian을 처벌합니다 — 집중된 깊이 분포를 장려하고 플로터를 줄입니다. 테스트: 0.01 → 4.5% 더 나쁨, 0.001 → 8.1% 더 나쁨. 이론적 이점 — Multi-View 일관성을 개선 — 은 L1 Loss에 반영되지 않습니다. 가설이 SfM 형상이 올바르다고 암묵적으로 가정하고 Gaussian이 단지 "쌓일" 필요가 있기 때문입니다. 실제로는 SfM 점 구름이 일반적으로 가장 약한 구성 요소이지 적재가 아닙니다. 특히 깨끗한 포즈가 있는 Multi-View 데이터셋 (합성, Ground Truth가 있는 Mip-NeRF 360) 에 사용 가능한 채로 유지됩니다.
T27singleViewOverfit
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
진단 플래그: true인 경우 각 학습 반복에서 카메라 풀에서 무작위로 선택되는 대신 카메라 인덱스 0이 강제로 사용됩니다. 의의: 모델이 단일 뷰조차 Overfit할 수 없다면 (즉 View 0의 Loss가 10 000 반복 후에도 0에 가까이 가지 않으면) Forward/Backward Pass에 근본적인 버그가 있는 것입니다. 이 스위치는 Metal 셰이더와 Differentiable Rasterizer 커널의 개발 중에 집중적으로 사용되었습니다 — V42–V47 단계. 오늘날은 누군가 백엔드 코드를 수정했고 회귀 테스트를 하고 싶을 때 Sanity Check로만 사용 가능합니다. CLI에서는 –single-view.
T28maxCameras
세부 정보
기본값: 0 (= "모든 카메라 사용") 범위: 0 또는 1 – N 정의 위치: TrainingConfig.swift
기술적 설명
V43의 진단 한도: 처음 N개의 카메라로만 학습하고 나머지는 무시합니다. 원래 의의: 너무 많은 카메라가 그래디언트 충돌을 생성한다는 가설을 테스트 (같은 Gaussian에 대한 너무 많은 모순적 Loss 신호). 테스트 결과: 인위적 제한에서 체계적 이점 없음 — 더 많은 프레임은 실질적으로 항상 더 많은 품질을 가져옵니다. 대상 실험을 위한 CLI 플래그 (–max-cameras N) 로 유지됩니다 (예: "1 500 이미지 드론 비행의 처음 100 이미지에서 학습이 작동합니까?"). UI에는 노출되지 않습니다.
T29maxInitialPoints
세부 정보
기본값: 0 (= "모든 SfM 점 사용") 범위: 0 또는 1 000 – 200 000+ 정의 위치: TrainingConfig.swift
기술적 설명
V54 보호: 학습이 시작되는 초기 SfM 점의 수를 제한합니다. 조밀한 COLMAP 재구성은 > 60 000 점을 생산할 수 있으며 큰 초기 스케일에서 픽셀 오버랩당 200–300 Gaussian으로 이어집니다 — 학습이 수렴하지 않는 "안개 필드"를 만듭니다. ~16 000 점으로 서브샘플링 (학습 엔진의 Hard Cap 로직) 은 초기 밀도를 참조 3DGS가 사용하는 수준으로 가져오고 오버랩을 극적으로 줄입니다. 매우 조밀한 SfM에서 자동으로 설정됩니다. CLI에서는 –max-points N.
T30cameraClusterOutlierMultiplier
세부 정보
기본값: 10.0 (모든 프리셋 — 절대 덮어쓰지 않음) 범위: 1.0 – 100.0 정의 위치: TrainingConfig.swift
기술적 설명
Phase 3.10 A.1에서 도입된 카메라 클러스터 아웃라이어 필터의 승수. 학습 전 학습 엔진은 모든 카메라 위치의 중심과 카메라의 중심으로부터의 최대 거리를 계산합니다. 중심으로부터의 거리가 multiplier × maxCameraDistance를 초과하는 SfM 점은 아웃라이어로 폐기됩니다. 기본값 10×는 Phase 3.10 이전의 동작을 보존합니다. 미묘한 버그: 더 타이트한 SfM (카메라가 더 가깝게) → 더 작은 maxCameraDistance → 더 작은 임곗값 → 더 많은 점이 아웃라이어로 폐기됨. 더 느슨한 SfM → 더 큰 임곗값 → 더 적은 점이 폐기. 이는 Phase 3.9 Funnel vs Training 반상관관계의 원인 중 하나입니다: 더 나은 SfM이 다운스트림에서 더 나쁜 학습으로 이어질 수 있습니다. 너무 많은 초기 점이 죽기 때문입니다. 필드는 A.3 Sweep을 위해 CLI 재정의 (–camera-cluster-outlier-multiplier) 로 있습니다. UI에는 노출되지 않습니다. 5 미만의 값은 일반적으로 너무 제한적이고, 20 이상은 효과가 없습니다.
정규화 (T31–T37)
T31coarseToFineBlurRadius
세부 정보
기본값: 0 (= 비활성화) 범위: 0 또는 1 – 10 정의 위치: TrainingConfig.swift
기술적 설명
V369 실험적: Densification 단계 시작 시 Ground Truth 이미지에 적용되고 Densification 종료 (T2) 까지 0으로 선형 감소되는 Box Blur 반경. 가설: Coarse-to-Fine 학습 — 먼저 거친 구조를 학습한 다음 세부 정보 — 이 더 안정적인 형상을 제공해야 합니다. 테스트: r=3 → 9.6% 더 나쁨, r=1 → 5.1% 더 나쁨. 실패 이유: Densification은 이미지 도메인 그래디언트를 기반으로 결정하며, 블러는 "여기서 클론해야 함"에 중요한 신호를 정확히 줄입니다. 다른 Density Control 스킴으로 향후 테스트를 위해 필드 카탈로그에 남아 있습니다.
T32scaleRegWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
V370 실험적: 세계 공간 스케일에 대한 L1 정규화. 너무 커지는 Gaussian을 처벌합니다 — 전체 벽 표면을 하나의 Gaussian으로 덮는 "Mega Splat"을 방지합니다. 테스트: 0.01 → 200% 더 나쁜 Loss (2 M Gaussian, 완전한 폭발), 0.001 → 214% 더 나쁨. 이유: 스케일 정규화는 Density Control과 충돌합니다 — 더 작은 스케일은 더 많은 Gaussian이 필요하다는 것을 의미합니다. 따라서 Density Control이 더 자주 스플릿하고 이는 더 많은 그래디언트 비용을 의미합니다. 비활성화되었지만 Mip-Splatting 실험 (T74) 을 위해 문서화됨: 이 컨텍스트에서는 스케일 하한이 의미가 있을 수 있습니다.
T33anisotropyRegWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
V445 실험적: max(scale)/min(scale) 비율에 대한 페널티. 플로터로 인식되는 극도로 늘어난 "Needle" Gaussian을 방지해야 합니다. 테스트: 0.01 → 69% 더 나쁨, 0.001 → 15% 더 나쁨. 이유: 정규화가 Splat을 "둥근" 모양 방향으로 강제하는데, 평평한 표면 (벽, 테이블, 바닥) 에서는 정확히 잘못된 것입니다 — 거기서는 평평하고 넓은 Gaussian이 구형보다 더 효율적입니다. 비활성화됨. V549f는 T34 scaleRatioPruneThreshold로 대안적이고 더 표적화된 접근 방식을 제공했고 마찬가지로 revert되었습니다.
T34scaleRatioPruneThreshold
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 5.0 – 100.0 (일반적으로 10.0 – 30.0) 정의 위치: TrainingConfig.swift
기술적 설명
실험적 후 학습 Pruning. 여기서 설정된 선형 임곗값을 초과하는 max(scale)/min(scale) 비율을 가진 각 Gaussian을 삭제합니다. 정규화만으로는 제거할 수 없는 극도로 늘어난 "Needle/Disc" 플로터를 대상으로 합니다. 테스트에서 Pruning이 기대한 대로 플로터를 제거했지만 동시에 벽과 바닥의 의미 있는 평평한 Splat도 제거했습니다 — 이미지가 더 구멍이 났습니다. 따라서 기본적으로 꺼져 있고 CLI 플래그 (–scale-ratio-prune N) 는 표적 실험을 위해 사용 가능한 채로 유지됩니다. 그래도 테스트하려면 권장 값: 30 (매우 보수적, 극단적인 아웃라이어만 제거), 10 (공격적, 세부 정보가 듦).
T35opacityRegWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.0001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
V446 실험적: Opacity를 0 또는 1로 (즉 "반투명"에서 멀리) 끌어당기는 Binary Cross Entropy 페널티. 가설: 더 선명한 Opacity 분포가 이미지 선명도를 개선합니다. T33과 결합 테스트 → 정규화가 품질 비용. 둘 다 비활성화. 비활성화. 주의: 1.4.3 베타에서 이 필드를 기본값 변경 (이니셜라이저 = 0.01) 한 버그가 등장하여 Gaussian Count의 대량 멸종 (한 반복에서 460 K → 5) 으로 이어졌습니다. 1.4.4부터 0.0으로 기본값 고정.
T36opacityDecayFactor
세부 정보
기본값: 0.0 (이니셜라이저 = 비활성화), 0.9995 (.full, .classicBalanced — HTGS 표준) 범위: 0 (off) 또는 0.95 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
HTGS 스킴 (Hierarchical Time-Gating, Eurographics 2025) 의 V546 구현: 매 T37 opacityDecayInterval 반복마다 각 Gaussian의 sigmoid Opacity가 이 인수로 곱해집니다. 0.9995 × 100회 적용은 Densification 단계당 ~95% 잔존을 산출합니다 — 모든 Opacity에 대한 약하지만 꾸준한 하향 압력으로, 약하게 기여하는 Gaussian이 T14 pruneOpacityThreshold에 안정적으로 가라앉도록 합니다. 결과: V438 (Decay 없음) 에 비해 Horse Full에서 14% 더 나은 L1 Loss (3-trial 평균 V546). Densification 단계 동안만 활성 (T2까지), 그 후 학습은 Decay 없이 계속 실행되어 Refinement에서 확립된 Opacity가 안정적으로 유지됩니다. MCMC에서는 사용되지 않습니다 (MCMC는 T67 mcmcRelocationInterval + T68 mcmcDeadOpacityThreshold를 통해 자체 메커니즘이 있음).
T37opacityDecayInterval
세부 정보
기본값: 50 범위: 10 – 500 정의 위치: TrainingConfig.swift
기술적 설명
T36 opacityDecayFactor가 적용되는 반복 간격. HTGS 논문 기본값 50, .full에서 유지. 긴 간격 (>200) 은 효과를 부분적으로 상쇄합니다. 두 적용 사이에 Opacity가 다시 증가할 만큼 충분한 그래디언트 업데이트가 발생하기 때문입니다. 짧은 간격 (<20) 은 Decay를 너무 공격적으로 만듭니다. Densification 단계에서만 활성.
Refinement (T38–T44)
T38gradientAccumulationSteps
세부 정보
기본값: 1 (= "Adam 단계당 하나의 뷰") 범위: 1 – 8 정의 위치: TrainingConfig.swift
기술적 설명
V424 기능: Adam 업데이트가 실행되기 전에 그래디언트가 누적되는 뷰의 수. > 1에서 앱은 그래디언트를 별도의 버퍼에 합하는 별도의 "unfused" Backward Project 경로에서 실행됩니다. 최종 적용은 크기를 일정하게 유지하기 위해 1/N로 스케일됩니다. V424는 2-뷰를 테스트했습니다 → 품질 중립이지만 10% 더 느림 (unfused 경로가 fused 경로보다 비싸기 때문에). .full에 대해 revert되었지만 MCMC에 대해서는 의도적으로 사용 — .fullMCMC는 함께 실행되지만 V544a 테스트는 Classic과의 품질 격차가 11% 대신 5%로 줄어든다는 것을 보여 주었습니다. 이니셜라이저 기본값은 1, 현재 프리셋도 1, CLI 플래그 (–accum-steps N) 로 유지됩니다.
T39testViewIndices
세부 정보
기본값: [] (= 비어 있음, 모든 뷰가 학습에 사용) 범위: Set<Int>, 카메라 인덱스의 임의 하위 집합 정의 위치: TrainingConfig.swift
기술적 설명
V546 기능: 학습에 사용되지 않고 PSNR/SSIM/LPIPS 평가용 Holdout으로 저장되는 카메라 인덱스 집합. –benchmark CLI 플래그가 활성일 때 자동으로 설정됩니다: 그러면 인덱스 0부터 시작하여 매 8번째 뷰 (LLFF 표준, Mip-NeRF 360 및 3DGS 논문 규약과 동일). benchmark 없이는 비어 있음 — 학습이 모든 뷰를 사용합니다. 주의: 인덱스 이해 없이 이 필드를 수동으로 설정하면 벤치마크가 사용 불가능해질 수 있습니다 (예: N-50 뷰만 있는데 모든 인덱스가 N 이상으로 설정됨 → Holdout 없음 → 평가 없음). 자체 프리셋 내보내기 시 testViewIndices는 영구화되지 않습니다. 장면 의존적이며 그렇지 않으면 다른 데이터셋 사이에 무의미한 값을 남길 것이기 때문입니다.
T40refinementPruneInterval
세부 정보
기본값: 0 (= 비활성화) 범위: 0 또는 100 – 5 000 정의 위치: TrainingConfig.swift
기술적 설명
V425 기능: Refinement 단계 (T2 후) 동안 매 N 반복마다 sigmoid(opacity) < T41 refinementPruneOpacityThreshold의 Gaussian을 제거하는 추가 Prune 패스가 실행됩니다. 의의: Densification 동안에는 정기적인 Density Control 호출이 있지만 그 후에는 없습니다 — Opacity가 계속 감소하는 Gaussian은 버퍼에 남습니다. V425는 테스트하고 revert했습니다: 추가 Pruning은 V426 (Two-Phase Densification, 마찬가지로 0 Gaussian 캐스케이드 실패로 중단) 과 상관관계가 있었습니다. 비활성화. 실험을 위한 CLI 플래그 사용 가능. 활성화되면 1 000 또는 2 000이 합리적인 값입니다.
T41refinementPruneOpacityThreshold
세부 정보
기본값: 0.0 (= "T14 사용") 범위: 0 또는 0.001 – 0.1 정의 위치: TrainingConfig.swift
기술적 설명
V425b: Refinement Pruning을 위한 별도의 Opacity 임곗값. Densification 후 대부분의 Gaussian은 상당히 더 높은 Opacity (> 0.001) 에 도달하므로 표준 T14 pruneOpacityThreshold가 너무 느슨합니다. T40이 활성이면 이 필드가 자체 임곗값을 결정합니다. 0.0에서는 T14가 계속 사용됩니다. T40 > 0일 때만 관련이 있습니다.
T42midTrainingCompactificationIterations
세부 정보
기본값: [] (= 비활성화) 범위: [Int], 값이 (densifyUntilIteration, maxIterations) 안에 정의 위치: TrainingConfig.swift
기술적 설명
V549 기능: Refinement 단계 동안 Compactification 패스가 실행되는 명시적 반복 지점 (sigmoid(opacity) < 0.01 + 아웃라이어 스케일 Gaussian을 제거, T56 postTrainingCompactification과 같은 로직). 의의: 긴 Refinement 단계가 SH가 뷰별 아티팩트에 Overfit하는 Confetti/Floater 누적을 보여 줄 수 있습니다. 활성화된 경우 일반적인 구성: 40K Classic용 [10000, 20000, 30000]. 그러나: Family 데이터셋의 V549 A/B 테스트는 모든 구성에서 더 나쁜 L1을 보여 주었습니다: [10K,20K,30K]\@0.01 → −48% Count이지만 +36% L1. [20K,30K]\@0.005 → −44% Count이지만 +45% L1. [20K,30K]\@0.001 → −17% Count이지만 +87% L1. 따라서 비활성화. CLI 플래그 –mid-compact "10000,20000"은 시각적 플로터 트레이드오프 (뷰포트에서 더 적은 Confetti) 를 Loss 회귀보다 선호하는 경우 사용 가능합니다.
T43frustumCullEnabled
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V549b 기능: 학습 후 모든 학습 카메라 Frustum의 합집합 밖에 있는 모든 Gaussian이 제거됩니다. 이러한 Gaussian은 Loss 신호에 의해 결코 제약되지 않았으며 항상 플로터입니다. Novel View가 카메라 경로 뒤나 옆에 있는 장면 (예: 선형 드론 비행의 뒷면) 에 특히 효과적입니다 — 거기의 플로터는 학습 단계에서 결코 보이지 않지만 나중에 3D 뷰어에서 움직일 때 매우 보입니다. V549b A/B는 드론 비행에서 긍정적인 결과를 보여 주었으므로 Opt-In으로 사용 가능합니다. 기본값은 false. 전체 궤도 커버리지가 있는 객체 캡처에서는 Frustum Union이 전체 장면을 포함하고 기능이 아무것도 제거하지 않기 때문입니다 — Settings의 "Floater Reduction"에서 제공되며 Q9 Outdoor 프리셋에서 T44 frustumCullExpansion을 통해 암묵적으로 테스트됩니다 (Q7-BayesOpt는 이를 활성화하지 않았습니다. Outdoor Sky Dome이 같은 문제를 더 잘 해결하기 때문에).
T44frustumCullExpansion
세부 정보
기본값: 1.1 범위: 1.0 – 2.0 정의 위치: TrainingConfig.swift
기술적 설명
T43 frustumCullEnabled에 대한 NDC 마진. 1.0은 이미지 가장자리에서 정확히 잘릴 것입니다. 이는 가장자리의 흔들리는 Splat을 너무 많이 자를 것입니다. 1.1 = 정확한 카메라 프레임을 넘어 10% 패딩 — 약간 오프셋된 Novel View에서 보일 수 있는 가장자리 픽셀에 대한 약간의 허용 오차를 제공합니다. > 1.2 값은 Cull을 실질적으로 비효과적으로 만듭니다. 확장된 Frustum이 훨씬 더 많은 공간을 포함하기 때문입니다.
Sky-Dome (T45–T48)
T45skyDomeEnabled
세부 정보
기본값: false (이니셜라이저 + P9 Outdoor를 제외한 모든 프리셋) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V549e 기능: 학습 시작 전에 구형 점 구름이 생성되고 (T46 샘플 포인트가 있는 Fibonacci Sphere), 장면 중심 주위에 T47 skyDomeRadiusMultiplier × scene_extent 반경으로 배치되며, 모든 학습 카메라의 Sky Masked 픽셀의 색상으로 초기화됩니다 (T20 skyMaskingEnabled 참고). 이 Sky Dome Gaussian은 Gaussian 버퍼의 시작에 삽입되고 학습 중 "동결"됩니다 (Position/Scale/Rotation Gradient = 0, SH와 Opacity만 최적화 가능). 효과: 멀리 있는 검은 "Confetti" 영역 대신 사용자가 Novel View에서 실제 하늘을 봅니다. V549e MVP는 드론 및 풍경 장면에서 매우 잘 작동합니다. P9 Outdoor 프리셋에서 기본적으로 켜져 있습니다. 실내 장면에서는 꺼 두십시오 — 구체가 무의미하게 방 밖에 매달릴 것입니다.
T46skyDomeSampleCount
세부 정보
기본값: 5 000 범위: 1 000 – 50 000 (일반적으로 2 000 – 10 000) 정의 위치: TrainingConfig.swift
기술적 설명
Sky Dome 구체의 Fibonacci Sphere 샘플 포인트 수. 더 높은 값 → 더 조밀한 Sky Dome (큰 해상도와 많이 보이는 하늘에 더 좋음), 그러나 더 많은 메모리 요구량. 5 000은 4K 렌더링용 스위트 스폿입니다. 더 낮은 해상도에서는 2 000–3 000으로 충분합니다. 점은 해당 Sky Masked 픽셀로 각 학습 카메라 View 벡터에 대한 Cosine Distance에 따라 초기화됩니다 — View Cone에 카메라가 보이지 않는 샘플 포인트는 낮은 Opacity 초기값으로 뒤에 남지만 학습에서 변경되지 않습니다 (동결).
T47skyDomeRadiusMultiplier
세부 정보
기본값: 30.0 (이니셜라이저 + 대부분의 프리셋), 59.0 (P9 Outdoor, Q7 BayesOpt 최적) 범위: 5.0 – 200.0 정의 위치: TrainingConfig.swift
기술적 설명
장면 범위 (= 카메라 위치 사이의 평균 거리) 에 상대적인 Sky Dome 구체 반경. 30 = 구체가 카메라 클라우드의 30배 직경을 가집니다. 너무 작음 (< 5) → Sky Dome이 장면 자체와 간섭 (예: Sky Dome Splat이 전경에 떨어짐). 너무 큼 (> 100) → Sky Dome 위치의 float32 정밀도 손실로 거리에서 렌더 글리치 트리거. Q7 BayesOpt는 Bicycle (Mip-NeRF 360) 에서 야외용 장면별 최적값으로 59.0을 발견했습니다 — 이는 표준 30.0이 깊은 풍경에 너무 작고 Sky Dome 픽셀이 이미지 가장자리 영역에서 "벽"으로 보이게 렌더링됨을 시사합니다.
T48frozenGaussianCount
세부 정보
기본값: 0 (= 동결된 Gaussian 없음) 범위: 0 또는 1 – T46 정의 위치: TrainingConfig.swift
기술적 설명
옵티마이저에서 Position/Scale/Rotation Gradient가 0으로 설정되는 버퍼 시작 부분의 Gaussian 수 — 전체 학습에 걸쳐 공간적으로 경직된 상태로 유지됩니다. Density Control은 이를 클론, 스플릿 또는 Prune해서는 안 됩니다. Sky Dome Injection에 사용됩니다 (T45 참고): Sky Dome이 켜져 있으면 이 필드가 자동으로 T46 skyDomeSampleCount로 설정됩니다. 수동 설정이 가능합니다 (예: LiDAR 스캔의 사전 배치된 점 구름을 동결하기 위해) 만 UI에서 직접 액세스할 수 없습니다. 중요: 버퍼의 처음 N Gaussian은 항상 동결됩니다 — 명시적 인덱스가 아니라 버퍼의 순서가 결정합니다.
Adam + LR 스케줄 (T49–T55)
T49adamResetIteration
세부 정보
기본값: 0 (= 비활성화) 범위: 0 또는 100 – maxIterations 정의 위치: TrainingConfig.swift
기술적 설명
V430 기능: Adam 옵티마이저 Momentum Accumulator (m1, m2) 가 0으로 재설정되는 반복. 그 후 Bias 보정은 iter 대신 (iter - adamResetIteration)로 실행됩니다. V430은 5 000에서 Reset을 테스트했습니다 (Densification 종료 후) → 12.8% 더 나쁜 Loss. 이유: Densification 동안 구축된 Adam Momentum이 일반적인 그래디언트 크기에 대한 정보를 가지고 있고 Refinement 단계를 가속화합니다. 이를 버리면 Refinement의 처음 ~500 반복의 수렴 비용이 듭니다. 비활성화. 연구 실험을 위한 CLI 플래그.
T50positionLRScheduleEndIteration
세부 정보
기본값: 0 (이니셜라이저 = "maxIterations 사용"), 20 000 (.full — maxIter=35K에도 불구하고 Cosine이 20K에서 종료), 30 000 (.fullClassicPaper) 범위: 0 또는 1 000 – maxIterations 정의 위치: TrainingConfig.swift
기술적 설명
V431 기능: Position LR Cosine Annealing 곡선이 최솟값에 도달하는 반복. 0이면 T1 maxIterations와 동일합니다. > 0이면 스케줄이 이 값까지 실행되고 그 후 T4 positionLearningRateFinal에서 일정하게 유지됩니다. 이는 최소이지만 일정한 학습률로 "확장된 Refinement 단계"를 허용합니다 — 새 Decay 없이 위치를 천천히 정제합니다. .full은 이를 수행합니다 (스케줄 종료가 20K, 학습이 35K까지 실행). V434c/V434d는 다음을 확인했습니다: 15K와 25K가 거의 같음, 20K가 미세하게 최적. 확장 단계에서 비 Position LR도 수정하기 위해 T51과 함께 사용됩니다.
T51extendedPhaseLRDecay
세부 정보
기본값: 0.0 (= 비활성화, 일정한 LR) 범위: 0 또는 0.01 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
V433 기능: "확장 단계"에서 비 Position LR (스케일, 회전, Opacity, SH) 의 최소 승수 — 즉: T50이 도달되어 Position LR이 이미 T4에 있은 후. 0.1이면 스케일/회전/Opacity/SH가 1.0 (= 표준 LR) 에서 표준의 0.1×로 cosine-decay됩니다. 0.0 (기본값) 이면 일정하게 유지됩니다. V457은 전체 Decay (0.0 = 0까지 Decay) 를 no-decay에 대해 테스트했고 다음을 발견했습니다: 평균 0.0400 (2 Run) = Decay 없는 V438과 같은 Loss. Decay로 동작이 더 깨끗하지만 측정 가능하게 더 나음은 아닙니다. 따라서 비활성화. CLI에 –nonpos-lr-scale F로 유지됩니다.
T52adaptiveDensifyThreshold
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V440 실험적: true인 경우 앱은 각 Densification 단계에서 현재 그래디언트 분포의 p98을 계산하고 동적 임곗값으로 사용합니다 (구성된 T11 값의 최소 0.5×에 클램프되어 너무 많이 벗어나지 않도록 함). 가설: 현재 장면 단계에 대한 자동 적응이 Density Control을 더 강건하게 만들 것 — 예: 처음에는 더 엄격한 Pruning, 나중에는 더 느슨하게 또는 그 반대. V440은 테스트하고 revert했습니다: 63 K Gaussian으로의 재앙적 하락 (Mass Pruning, 처음 반복에서 p98이 극도로 높고 그 다음 거의 아무것도 임곗값을 초과하지 않기 때문에). 고정된 임곗값이 이미 잘 보정되어 있고 동적 적응이 도움이 되기보다 해를 끼칩니다. Q5 (T77) 는 Rolling Median을 통한 대체 Adaptive 로직을 제공하여 문제를 우회합니다.
T53mergeAfterDensification
세부 정보
기본값: false (이니셜라이저), true (.full, .classicBalanced, .fullClassicPaper) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V438 기능: Densification 단계 종료 시 (Iter T2) 유사한 스케일과 색상으로 가까이 있는 Gaussian을 결합하는 일회성 Merge 패스가 수행됩니다. 가시적 품질 손실 없이 Gaussian 수를 일반적으로 5–15% 줄입니다. 의의: 강한 Clone 후 거의 동일한 Gaussian 클러스터가 발생하며 이는 새로운 것을 기여하지 않습니다 — Merging은 다른 영역에 옵티마이저 용량을 해제합니다. Classic Quality 프리셋의 표준. MCMC에서는 사용되지 않습니다. MCMC가 Relocation 로직을 통해 이러한 클러스터가 처음부터 발생하지 않게 하기 때문입니다.
T54densifyPhase2FromIteration
세부 정보
기본값: 0 (= 비활성화) 범위: 0 또는 T2 – T1 정의 위치: TrainingConfig.swift
기술적 설명
V426 실험적: Refinement 일시 정지 후 이 반복에서 시작하여 T55까지 실행되는 두 번째 Densification 단계를 가능하게 합니다. 가설: Refinement 단계 후 그래디언트 Accumulator가 더 안정적인 크기를 가지고 추가 Gaussian이 필요한 영역을 더 정확하게 말할 수 있을 것입니다. V426은 테스트하고 revert했습니다: Two-Phase Densification이 0 Gaussian 캐스케이드 실패에 빠짐 (V425 Refinement Pruning과 결합하여 버퍼를 파괴함). 비활성화. 실험을 위한 CLI 플래그 사용 가능.
T55densifyPhase2UntilIteration
세부 정보
기본값: 0 범위: 0 또는 T54 – T1 정의 위치: TrainingConfig.swift
기술적 설명
V426 Two-Phase Densification의 종료. T54 > 0일 때만 관련 있음. 두 필드 모두 비활성화.
Post-Processing + Apple AI (T56–T60)
T56postTrainingCompactification
세부 정보
기본값: true (모든 Production 프리셋), false (.quickTest, .preview) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V443 기능: 학습 종료 후 sigmoid(opacity) < 0.01의 Gaussian이 하드 제거됩니다 (실질적으로 더 이상 이미지에 기여하지 않음). 가시적 품질 손실 없이 Gaussian Count를 일반적으로 58%, 내보내기 파일 크기를 55% 줄입니다. Production 프리셋에서 표준으로 활성 — 최종 결과를 가능한 한 콤팩트하게 제공해야 합니다. .quickTest에서는 꺼짐. 진단 실행이 어쨌든 내보내지지 않기 때문입니다. T42 midTrainingCompactificationIterations (V549) 와 달리 Compactification은 끝에서만 발생합니다 — Refinement는 그때까지 모든 Gaussian을 사용할 수 있습니다.
T57metalFXUpscaling
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V444 기능: 3D Viewer 출력에서 Bilinear Interpolation 대신 Apple의 MetalFX Spatial Upscaler를 활성화합니다. 학습 해상도 < 뷰포트 크기 (예: 0.5× 학습, 전체 해상도 뷰포트 표시) 인 경우 MetalFX는 훨씬 더 선명한 이미지를 제공할 수 있습니다. 뷰포트에서 실시간으로 변경됩니다. 재학습 필요 없음. T58 mpsLanczosScaling과 상호 배타적 — MetalFX가 우선합니다. 권장: 이미지가 예상 세부 정보에 비해 뷰어에서 "흐릿"하게 나타나면 켜십시오.
T58mpsLanczosScaling
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
V444 기능: Bilinear Interpolation 대신 뷰포트 스케일링용 MPSImageLanczosScale. Lanczos는 Bilinear보다 훨씬 더 선명한 결과를 최소한의 오버헤드로 제공하는 고전적 Sinc 기반 재샘플링 절차입니다. 실시간 토글. 둘 다 켜져 있으면 T57에 의해 덮어쓰여집니다.
T59livePreviewInterval
세부 정보
기본값: 50 (이니셜라이저와 대부분의 프리셋) 범위: 0 (off) 또는 10 – 5 000 정의 위치: TrainingConfig.swift
기술적 설명
학습 중 3D Viewer가 현재 Gaussian으로 업데이트되는 빈도. 50 = 50회 반복마다 Viewer에 새 Render — 학습을 느리게 하지 않고 진행을 관찰하기에 충분히 좋음. 0 = Viewer가 전혀 업데이트되지 않음 (백그라운드 학습, 최대 속도). 일반적인 조정: .quickTest에서 10으로 낮춤 (모든 단계를 보고 싶음), 긴 MCMC 실행에서 500–2000으로 높임 (Update 오버헤드가 합계로 눈에 띔).
T60perceptualLossWeight
세부 정보
기본값: 0.0 (= 비활성화) 범위: 0 또는 0.001 – 0.5 정의 위치: TrainingConfig.swift
기술적 설명
V444 미래 기능: MPSGraph (VGG와 비슷한 작은 네트워크) 를 통한 Perceptual Loss 항의 가중치. L1+SSIM보다 더 높은 의미 수준에서 구조적 및 텍스처 유사성을 포착할 것입니다 — "Pixel-Perfect"가 "사실적으로 보임"보다 덜 중요한 연구 파이프라인에서 일반적입니다. 구현은 아직 보류 중 (Code Stub 존재하지만 Forward Pass는 구현되지 않음). 기본값 0.0. 향후 활성화를 위해 필드 카탈로그에 유지됩니다. CLI 플래그 –percep-weight F 예약.
MCMC Densification (T61–T73)
T61densificationStrategy
세부 정보
기본값: .classic (이니셜라이저 + Classic 프리셋), .mcmc (모든 MCMC 프리셋 + Scene-Class) 범위: .classic 또는 .mcmc 정의 위치: TrainingConfig.swift
기술적 설명
Classic Densification (Clone/Split/Prune, Kerbl 외 2023) 과 MCMC Densification (Relocation을 사용한 Stochastic Gradient Langevin Dynamics, Kheradmand 외 NeurIPS 2024) 사이의 선택. .classic에서는 T11–T16이 평가되고, .mcmc에서는 T62–T73이 평가됩니다. 전환 시 주의: Classic 기본값과 MCMC 기본값은 완전히 다르게 보정되어 있습니다 — Expert View의 선택기를 Flip하는 사람이 적절한 프리셋을 로드하지 않으면 1.4.3 버그 스타일 대량 멸종 (한 반복에서 460 K → 5) 의 위험이 있습니다. MCMC OpacityReg 0.01이 Classic Opacity를 죽이기 때문에. 따라서 MCMC Init 기본값은 의도적으로 "부드럽게" (모든 Reg 값 0.0).
T62mcmcMaxGaussians
세부 정보
기본값: 150 000 (이니셜라이저 + .fullMCMC + .mcmcBalanced), 100 000 (.mcmcPreview), 1 500 000 (.fullMCMCMip — 10× 예산이 있는 Mip-Splatting 변형), 1.19 M (.renderPreset), 1.25 M (.outdoorPreset), 670 K (.indoorPreset) 범위: 0 (= "버퍼 용량 사용") 또는 10 000 – 5 000 000 정의 위치: TrainingConfig.swift
기술적 설명
MCMC 전략에서 Gaussian 수의 하드 상한. 수는 이 Cap까지 Relocation 단계당 T70 mcmcGrowthRate (일반적으로 5%) 로 점진적으로 증가합니다. V473/V531은 150 K를 스위트 스폿으로 발견했습니다 — 200 K 이상에서는 Splat 품질이 희석됩니다 (너무 많은 작은, 중복된 Gaussian). 100 K 미만에서는 장면이 under-densify 상태로 유지됩니다. 매우 큰 장면 (예: 158 K SfM 초기화의 1 545 사진 드론 비행) 에서는 150 K가 너무 낮습니다 — 따라서 1.4.5 확장 T72 mcmcCapMultiplier + T73 mcmcAutoScaleByScene. Q7 BayesOpt는 670 K (Indoor) 에서 1.25 M (Outdoor) 사이의 장면별 최적값을 발견했습니다. 값 0에서 엔진은 전체 버퍼 용량을 Cap으로 사용합니다.
T63mcmcNoiseScale
세부 정보
기본값: 0.00005 (5e-5 = 논문 기본값) 범위: 1e-6 – 1e-3 정의 위치: TrainingConfig.swift
기술적 설명
각 MCMC 반복에서 각 Gaussian의 위치에 추가되는 Gaussian 노이즈의 승수 (SGLD 로직). 더 높음 = 더 많은 탐색 (Gaussian이 더 많이 방황, 잠재적으로 더 나은 자리를 찾음), 더 낮음 = 더 많은 이용 (Gaussian이 이미 좋은 곳에 머무름). V467과 V536은 5e-5를 최적으로 확인했습니다 — 1e-5/2e-5는 너무 적은 탐색, 1e-4는 너무 많음 (Splat이 흩어짐). 학습 시간에 걸쳐 T69 mcmcNoiseDecayEnd까지 cosine-decay됩니다 — Decay 범위 종료 시 노이즈가 효과적으로 0이고 Gaussian이 수렴합니다.
T64mcmcOpacityRegWeight
세부 정보
기본값: 0.0 (= RadianceKit 기본값에서 비활성화, 논문: 0.01) 범위: 0 또는 0.001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
Opacity에 대한 MCMC 특정 L1 페널티. 논문 기본값 0.01 (사용되지 않은 Gaussian을 0으로 누르고, Relocation에 사용할 수 있게 만듭니다). 그러나 V464b는 RadianceKit에서 Reg 없이 측정 가능하게 더 나음을 보여 주었습니다 (Session 28 확인). 이유: T68 mcmcDeadOpacityThreshold로 정의된 Pruning 기준만으로 충분합니다 — 추가 L1 페널티는 가치 있는, 낮은 Opacity Gaussian도 죽도록 강제합니다. 따라서 기본값 0. 주의: 1.4.3 베타 빌드에서 이니셜라이저 기본값이 잘못 0.01이었고 대량 멸종 버그를 초래했습니다 (T61 설명 참고). 1.4.4부터 0.0으로 고정.
T65mcmcScaleRegWeight
세부 정보
기본값: 0.0 (= 비활성화, 논문: 0.01) 범위: 0 또는 0.001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
스케일 고유값에 대한 MCMC 특정 L1 페널티. 논문 기본값 0.01. V464b: Reg 없이 더 나음, T64와 같은 이유. 모든 RadianceKit MCMC 프리셋에서 비활성화. T64와 같은 주의: 1.4.3 버그.
T66mcmcRelocationInterval
세부 정보
기본값: 100 (이니셜라이저 + 모든 MCMC 프리셋, 논문 표준), 155 (P9 Outdoor — Q7 BayesOpt 최적) 범위: 50 – 500 정의 위치: TrainingConfig.swift
기술적 설명
MCMC가 죽은 Gaussian (sigmoid(opacity) < T68 mcmcDeadOpacityThreshold) 을 새 위치로 재배치하는 반복 간격. V537은 50을 테스트했고 (너무 파괴적, Loss 변동) 200을 테스트했습니다 (미세하게 더 나쁨, MCMC가 반응성을 잃음). 100이 최적입니다. Q7 BayesOpt는 Bicycle에서 야외용 장면별 최적값으로 155를 발견했습니다 — 약간 더 긴 간격은 Adam이 다음 Reloc 이벤트가 압력을 가하기 전에 새로 배치된 Gaussian을 통합할 더 많은 시간을 줍니다.
T67mcmcWarmupIterations
세부 정보
기본값: 500 범위: 100 – 5 000 정의 위치: TrainingConfig.swift
기술적 설명
아직 MCMC Relocation이 발생하지 않는 초기 반복 수. 이 Warmup 후에만 Reloc 로직이 시작됩니다. 의의: 처음 반복에서 Opacity 값이 아직 안정화되지 않았습니다 — Reloc로 바로 시작되면 Gaussian이 잘못된 위치에 배치되어 바로 다시 이동되어야 하며 이는 Adam Momentum을 파괴합니다. 논문 기본값 500. RadianceKit은 V464b가 강건함을 보여 주었기 때문에 이 값을 채택합니다.
T68mcmcDeadOpacityThreshold
세부 정보
기본값: 0.005 (이니셜라이저, 논문 표준), 0.01 (.fullMCMC 와 모든 MCMC 프리셋 — V535 최적) 범위: 0.001 – 0.05 정의 위치: TrainingConfig.swift
기술적 설명
sigmoid(Opacity) 임곗값. 이 아래에서 Gaussian이 "죽음"으로 간주되어 Relocation 대상이 됩니다. V535는 0.01을 최적으로 발견했습니다 (0.005는 미미함, 0.02는 더 나쁨). 더 높음 = 더 공격적인 Reloc (더 많은 Gaussian이 이동됨), 더 낮음 = 더 신중함. 0.01은 대략 "0.5% 시각적 가시성"에 해당합니다. P10 Indoor는 Q7 BayesOpt를 통해 0.0142를 최적으로 사용합니다.
T69mcmcNoiseDecayEnd
세부 정보
기본값: 0 (이니셜라이저 = "Decay 없음"), 160 000 (.fullMCMC = 200K의 80%), 96 000 (.mcmcBalanced = 120K의 80%), 40 000 (.mcmcPreview) 범위: 0 또는 1 000 – maxIterations 정의 위치: TrainingConfig.swift
기술적 설명
T63 mcmcNoiseScale 노이즈가 완전히 0으로 감쇠되는 반복 (Iter 0부터 여기까지 Cosine Decay). V497c/V502는 maxIterations의 80%를 최적으로 발견했습니다 — MCMC에 충분한 탐색 시간을 주지만 마지막 20%를 노이즈 없이 수렴에 남깁니다. 0 = 모든 반복에 걸쳐 일정한 노이즈 (거의 의미가 없음, MCMC가 수렴할 수 없음).
T70mcmcGrowthRate
세부 정보
기본값: 0.05 (논문 표준 = 5%) 범위: 0.01 – 0.2 정의 위치: TrainingConfig.swift
기술적 설명
Relocation 단계당 MCMC 인구 대상의 성장률. 로직: 각 Reloc 이벤트에서 대상 인구 크기가 (1 + growthRate)만큼 증가하여 T62 mcmcMaxGaussians (또는 T72/T73을 통해 스케일된 변형) 에 도달합니다. V512/V522는 0.05를 최적으로 발견했습니다 — 더 높은 값은 너무 빠른 성장으로 이어집니다 (Adam Momentum이 통합할 수 있기 전에 Gaussian이 삽입됨), 더 낮은 값은 종료 시 under-densified 장면으로 이어집니다.
T71mcmcSigmoidK
세부 정보
기본값: 100.0 범위: 10.0 – 500.0 정의 위치: TrainingConfig.swift
기술적 설명
MCMC 노이즈 감쇠를 위한 Sigmoid Sharpness 매개변수. SGLD 단계에서 Gaussian당 노이즈는 sigmoid(K × logit_opacity) 로 감쇠됩니다 — 높은 Opacity Gaussian (Logit이 양수) 은 낮은 Opacity보다 기하급수적으로 적은 노이즈를 받습니다. K = 100은 선명하며, 즉 Opacity 0.5 주위에서 "풀 노이즈"에서 "노이즈 없음"으로의 전환이 매우 빠르게 발생합니다. V484–V487은 K = 100을 최적으로 발견했습니다 — 더 작은 값 (10–50) 은 높은 Opacity Gaussian도 흔들리게 합니다 (수렴된 Gaussian 파괴), 더 큰 값 (> 500) 은 전환을 인위적으로 단단하게 만들고 죽은 Gaussian이 전혀 이동되지 않습니다.
T72mcmcCapMultiplier
세부 정보
기본값: 3.0 (이니셜라이저 + .fullMCMC), 2.0 (.mcmcPreview), 2.5 (.mcmcBalanced), 2.98 (P8 Render), 5.32 (P9 Outdoor), 1.76 (P10 Indoor) 범위: 0 (= 비활성화) 또는 1.0 – 10.0 정의 위치: TrainingConfig.swift
기술적 설명
1.4.5 기능: 장면 적응 Cap 스케일링. T73 mcmcAutoScaleByScene이 true이면 효과적 Cap이 max(T62, initialPointCount × T72) 로 계산됩니다 (버퍼 용량에 클램프). 배경: 큰 장면에서 (예: 1 545 사진 드론 비행 → 158 K SfM 초기화) T62 = 150 000은 너무 낮습니다 — Density Control이 전혀 성장할 수 없을 것입니다. Multiplier 3.0으로 이 예에서 Cap이 474 K로 스케일됩니다 (158 K × 3.0). Q7 BayesOpt는 장면별 최적값을 발견했습니다: Outdoor는 높은 Multiplier (5.32 → 156 K bicycle 초기화에서 ~830 K Cap) 로부터 혜택, Indoor는 1.76으로 만족 (벽이 어쨌든 더 빨리 포화). Cap의 전체 해상도는 resolveMcmcMaxGaussians 메서드 참고.
T73mcmcAutoScaleByScene
세부 정보
기본값: true (이니셜라이저 + 모든 MCMC 프리셋) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
1.4.5 기능: 장면 인식 Cap 로직의 마스터 스위치 (T72 + resolveMcmcMaxGaussians 참고). false이면 T62 mcmcMaxGaussians만 Cap으로 사용됩니다 (1.4.4 동작으로 되돌림). 1.4.3의 큰 장면에서 대량 멸종 문제가 그렇지 않으면 반복되기 때문에 기본적으로 켜져 있습니다. 명시적으로 하드 Cap을 설정하려는 경우에만 수동으로 비활성화 — 예: 종료 크기가 계획 가능한 150 K 변형을 학습하기 위해.
Mip-Splatting (Q1.5) (T74–T76)
상태: Q1.5는 14번의 자율 반복 + Overnight 1.5M Confidence Check 후 2026-05-25에 "closed no-win"으로 폐기되었습니다 (max Δ@2× = +0.27 dB, 원래 Gate는 0.5×/2×에 대해 평균 ≥ +1.5 dB을 요구했는데 0/11 Pair Scene에서 FAIL). 필드는 연구 실험을 위해 opt-in으로 유지됩니다. 모든 Production 프리셋은 useMipSplatting = false입니다. Verdict 참고:
docs/plans/2026-05-25-phase-q1.5-final-verdict.md.
T74useMipSplatting
세부 정보
기본값: false (모든 Production 프리셋), true (.fullMCMCMip — 연구 형제) 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
Mip-Splatting (Yu 외 CVPR 2024) 을 활성화합니다: 가장 조밀한 학습 카메라 샘플링 비율의 Nyquist 한계로 Gaussian당 주파수를 제한하는 3D Smoothing 필터 + 2D 필터 + α 보상. 이론적 목표: 학습 외 스케일 (0.5× 또는 2× 학습 해상도) 에서의 렌더링 시 Aliasing 제거. Preprocess 및 Backward Projection 셰이더에서 활성화되었으며 Q1.5-D 테스트에서 기능적으로 정확하다고 검증됨. 그러나: 원래 수용 Gate (Δ@1× ≥ +0.3 dB 그리고 avg(Δ@0.5×, Δ@2×) ≥ +1.5 dB) 가 11개의 Pair Scene 중 어느 것에서도 달성되지 않았습니다. 최대 관찰: family 750K classic Δ@2× = +0.270 dB. 야외 장면 (Truck, Flowers) 은 1×와 0.5×에서 악화를 보였습니다. 가설: 3D Smoothing이 high-Gs에서 MCMC Relocation과 경쟁합니다. 필드는 올바른 Mip-NeRF-360 방법론을 사용한 향후 Multi-Scale 재평가를 위해 유지됩니다 (벤치마크 경로의 O3 백로그 참고).
T75mipSmoothing3DScale
세부 정보
기본값: 0.2 (논문 기본값) 범위: 0.05 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
3D Smoothing 스케일 매개변수 (Yu 외 §3.3, 논문 기본값 0.2). 더 큼 = Gaussian당 더 많은 세계 공간 평활화 (= 더 많은 Anti-Aliasing, 그러나 기본 스케일에서 더 많은 흐림), 더 작음 = 더 선명하지만 Aliasing에 더 취약. T74 useMipSplatting = true일 때만 참조됩니다. Q1.5 테스트에서 더 이상 최적화되지 않았습니다 — A/B Gate가 이미 논문 기본값 0.2로 졌습니다, 추가 Sweep은 무의미할 것입니다.
T76mipFilter2DVariance
세부 정보
기본값: 0.3 (= 정확히 V242 Legacy 동작) 범위: 0.1 – 1.0 정의 위치: TrainingConfig.swift
기술적 설명
Σ_2D 대각선에 추가되는 2D Mip 필터 분산 (분산 직접, 제곱 아님). 0.3은 Mip-Splatting 전 커널에 하드코딩되어 있던 정확히 V242 Legacy 값입니다. T74 useMipSplatting = false이면 커널이 이 값을 완전히 무시하고 하드코딩된 0.3을 작성합니다 — 따라서 Baseline이 회귀할 수 없습니다 (Codex Round 1 S3-1 보증). useMipSplatting = true이면 여기서 설정된 값이 사용됩니다. Mip Sweep을 위해 필드 카탈로그에 유지됩니다.
Adaptive Densification (Q5) (T77–T79)
T77adaptiveDensification
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
Q5 기능: 고정 T11 densifyGradThreshold의 대안으로 Rolling Median 추적기. true이면 각 Densify 단계에서 현재 임곗값이 median(last N avgGrad samples) × T79 adaptiveDensifyMultiplier로 덮어쓰여집니다. N = T78 adaptiveWindow. V440 p98 (재앙적 63 K Pruning 함정) 보다 엄격함, 중앙값 + 2×는 Steady State에서 그래디언트 분포의 p70–p80에 앉습니다. Q5 테스트: 독립적으로 FAIL 0/3 장면, 그러나 Q6 (T80/T81 참고) 와 함께 PASS 1/3 장면 — Q5+Q6 번들은 2026-05-25에 opt-in으로 통과되었으며 CLI –adaptive-densify를 통해 활성화할 수 있습니다. 거기서 Q6가 품질 이득의 "Carrier"이고 Q5는 안정성에 기여합니다.
T78adaptiveWindow
세부 정보
기본값: 1 000 범위: 100 – 10 000 정의 위치: TrainingConfig.swift
기술적 설명
Densification 이벤트의 Rolling Median 윈도우 (반복이 아님 — 각 T13 densifyInterval 단계가 하나의 샘플을 제공). 기본값 1 000 — densifyInterval = 100에서 이는 마지막 100 000 학습 반복이 중앙값에 기여한다는 의미이며 일반적으로 여기까지의 전체 학습 기록입니다. 초기 단계 (T78 샘플 전): 추적기는 nil 반환 → 고정 임곗값 T11로 대체. adaptiveDensification = true일 때만 관련 있음.
T79adaptiveDensifyMultiplier
세부 정보
기본값: 2.0 범위: 1.0 – 4.0 정의 위치: TrainingConfig.swift
기술적 설명
적응 임곗값에 대한 Rolling Median 승수. 기본값 2.0은 대략 일반적인 그래디언트 분포의 p70–p80에 해당합니다. 더 낮음: 더 공격적인 성장 (더 많은 클론), 더 높음: 더 엄격함 (더 적은 클론). Q5 테스트는 1.5–3.0 범위에서 — 2.0 최고 기본값. adaptiveDensification = true일 때만 관련 있음.
Curriculum (Q6) (T80–T81)
T80curriculumResolutionRamp
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
Q6 기능: 학습 해상도가 0.5×에서 시작하여 T50 positionLRScheduleEndIteration / 2 (T50이 설정되지 않은 경우 또는 T1 maxIterations / 2) 에서 T22 trainingRenderScale로 전환됩니다. Q1.5.1 에서 개발된 resize/restoreImageBuffers 인프라를 사용합니다. 활성화되면 T23 resolutionWarmupScale을 덮어씁니다. Q6는 Q5+Q6 번들에서 "품질 이득의 Carrier"로 통과되었습니다 (T77 참고) — 단계별 해상도 증가는 앱에 미세한 세부 작업으로 전환하기 전에 더 낮은 해상도에서 거친 형상을 찾을 시간을 줍니다. CLI를 통해: –curriculum-resolution.
T81curriculumSHProgression
세부 정보
기본값: false 범위: boolean 정의 위치: TrainingConfig.swift
기술적 설명
Q6 기능: T21 shDegreeUpgradeIterations를 [maxIter/4, maxIter/2, maxIter*3/4]로 덮어씁니다. 즉 SH 업그레이드를 Front Load 대신 학습 시간에 걸쳐 균등하게 분배합니다. 가설: 안정적인 형상은 색상 세부 정보 폭발 전에 확립되며, 이는 View Direction 의존 광택 효과를 더 정확하게 위치시킵니다. Q5+Q6 함께 PASS 1/3 장면, Q6가 이득의 Carrier (Q5 단독 FAIL). CLI를 통해: –curriculum-sh.
정적 프리셋 (TP1–TP9)
여기서는 이니셜라이저 기본값과의 구조적 차이만. 10개 UI 프리셋 P1–P10의 전체 마케팅 설명은 제 7 장에서 찾을 수 있습니다.
TP1.preview
세부 정보
≥ 10 GB RAM 시스템용 진단/미리보기 프리셋. 이니셜라이저에 대한 재정의: - maxIterations 30 000 → 5 000 - densifyUntilIteration 15 000 → 3 500 (maxIter의 70%) - positionLearningRateFinal 1.6e-6 → 1.6e-5 (10배 더 높음, 덜 공격적인 Decay) - shDC/shRest/opacity/scale/rotation LRs 각 2배 (V176) - opacityResetInterval 3 000 → 100 000 (효과적으로 꺼짐, V172: Reset이 짧은 학습 파괴) - shDegreeUpgradeIterations [1K, 2K, 3K] → [1K, 2K] (V182: Degree 3이 2K Iter에서 수렴하지 않음) - trainingRenderScale 1.0 → 0.5
TP2.full
세부 정보
Production-Quality Classic. 재정의: - maxIterations 30 000 → 35 000 (V550: 40K 테스트 Truck 과학습 +10.7% Gs에 -1.3% L1) - densifyUntilIteration 15 000 → 5 000 (V310 스위트 스폿, V338 7K 더 나쁨) - 모든 LR 2배 (V188) - positionLearningRateFinal 1.6e-6 → 1.6e-5 (V45 10배) - densifyGradThreshold 2e-6 → 1.1e-6 (V335) - densifyInterval 100 → 200 (V112) - pruneOpacityThreshold 0.005 → 0.001 (V393) - opacityResetInterval 3 000 → 100 000 (V194 비활성화, V421 확인) - shDegreeUpgradeIterations [1K, 2K, 3K] → [2K, 5K, 8K] (V228 지연) - opacityDecayFactor 0.0 → 0.9995 (V546 HTGS, 14% 개선) - opacityDecayInterval 50 (변경되지 않음, V546) - mergeAfterDensification false → true (V438) - positionLRScheduleEndIteration 0 → 20 000 (V431) - postTrainingCompactification true (V443, .full에 대해 이미 이니셜라이저 기본값)
TP3.fullClassicPaper
세부 정보
TP2의 Q1.5-A 테스트 형제, 논문 충실 Classic. TP2에 대한 재정의: - maxIterations 35 000 → 30 000 (논문 표준) - densifyUntilIteration 5 000 → 15 000 (논문: maxIter의 50%) - positionLearningRateFinal 1.6e-5 → 1.6e-6 (논문 기본값) - opacity/scale/rotation LR 논문 기본값으로 복귀 (0.05, 0.005, 0.001) - densifyGradThreshold 1.1e-6 → 2e-7 (Bicycle에서 ~1-2M Gs용으로 보정) - densifyInterval 200 → 100 (논문) - pruneOpacityThreshold 0.001 → 0.005 (논문 기본값) - opacityResetInterval 100 000 → 3 000 (논문 §5.2, 위험 — V194 회귀를 트리거할 수 있음) - opacityDecayFactor 0.9995 → 0.0 (논문에 Decay 없음) - positionLRScheduleEndIteration 20 000 → 30 000 (Cosine이 maxIter의 100%에서 실행)
TP4.fullMCMC
세부 정보
Production-Quality MCMC. 이니셜라이저에 대한 재정의: - maxIterations 30 000 → 200 000 (V534, MCMC가 Classic보다 5배 더 많은 Iter 필요) - densifyUntilIteration 15 000 → 160 000 (V504b maxIter의 80%) - positionLearningRateFinal 1.6e-6 → 1.6e-5 - LR 스케줄 TP2처럼 (모두 2배) - ssimWeight 0.2 → 0.05 (V521b/V534: MCMC에 더 강한 L1 신호 필요) - shDegreeUpgradeIterations [1K, 2K, 3K] → [2K, 5K, 8K] - densificationStrategy .classic → .mcmc - mcmcMaxGaussians 150 000 (이니셜라이저에 이미 있음, 프리셋에서 확인) - mcmcNoiseScale 5e-5 (V467/V536 최적) - mcmcDeadOpacityThreshold 0.005 → 0.01 (V535 최적) - mcmcNoiseDecayEnd 0 → 160 000 (maxIter의 80%, V497c/V502) - mcmcCapMultiplier 3.0 (이니셜라이저에 이미 있음) - mcmcAutoScaleByScene true (이니셜라이저에 이미 있음) - opacityResetInterval 3 000 → 200 000 (효과적으로 꺼짐, MCMC는 Reset 대신 Reloc 사용)
TP5.fullMCMCMip
세부 정보
Mip-Splatting + 논문 규모 MCMC 예산이 있는 TP4의 Q1.5-D 테스트 형제. TP4에 대한 재정의: - mcmcMaxGaussians 150 000 → 1 500 000 (10배, 논문 규모) - useMipSplatting false → true (Mip 켜짐)
TP6.classicBalanced
세부 정보
Mid-Tier Classic. TP2에 대한 재정의: - maxIterations 35 000 → 20 000 (V149: 20K = 30K, 33% 적은 시간으로) - positionLRScheduleEndIteration 20 000 → 0 (Cosine이 maxIter = 20K에서 실행, 확장 단계 없음)
TP7.mcmcPreview
세부 정보
MCMC 진단. TP4에 대한 재정의: - maxIterations 200 000 → 60 000 (V494b) - densifyUntilIteration 160 000 → 48 000 (80%) - mcmcMaxGaussians 150 000 → 100 000 (V473b) - mcmcNoiseDecayEnd 160 000 → 40 000 (V494b) - mcmcCapMultiplier 3.0 → 2.0 (1.4.5: Preview = 가벼운 스케일링)
TP8.mcmcBalanced
세부 정보
Mid-Tier MCMC. TP4에 대한 재정의: - maxIterations 200 000 → 120 000 (V518) - densifyUntilIteration 160 000 → 96 000 (80%) - mcmcNoiseDecayEnd 160 000 → 96 000 (80%) - mcmcCapMultiplier 3.0 → 2.5 (Preview 2.0과 Full 3.0 사이)
TP9.quickTest
세부 정보
순수 기능 테스트. 이니셜라이저에 대한 재정의: - maxIterations 30 000 → 1 000 - densifyUntilIteration 15 000 → 500 - densifyGradThreshold 2e-6 → 4e-6 (0.25배 해상도용으로 보정) - densifyInterval 100 → 50 - opacityResetInterval 3 000 → 100 000 (꺼짐, 너무 짧기 때문에) - trainingRenderScale 1.0 → 0.25
메서드: resolveMcmcMaxGaussians
시그니처: public func resolveMcmcMaxGaussians(initialPointCount: Int, bufferCapacity: Int) -> Int 정의 위치: TrainingConfig.swift
"MCMC가 최대 얼마나 많은 Gaussian으로 성장하도록 허용해야 하는가?"라는 질문에 대한 유일한 Source-of-Truth. 세 입력에서 계산됩니다: 구성된 T62 mcmcMaxGaussians (0이면 대량 멸종 Floor 150 000), initialPointCount (SfM 초기화 점의 수), bufferCapacity (사전 할당된 Gaussian 버퍼 크기). 로직:
+ base = T62 > 0 ? T62 : 150_000 (대량 멸종 Floor가 1.4.3 대량 멸종 사건 같은 이니셜라이저 기본값 버그로부터 보호) + 만약 T73 mcmcAutoScaleByScene && initialPointCount > 0 && T72 mcmcCapMultiplier > 0: - scaled = max(base, ceil(initialPointCount × T72)) 그렇지 않으면 scaled = base + 만약 bufferCapacity > 0: return min(scaled, bufferCapacity) + 그렇지 않으면 return scaled
예: Bicycle (Mip-NeRF 360, 194 사진 프레임) → SfM 초기화 ~156 K 점, T62 = 150 000, T72 = 5.32, 버퍼 용량 8 M. Resolved Cap = min(8M, max(150K, ceil(156K × 5.32))) = min(8M, 830K) = 830 K. 이는 MCMC Relocation 로직이 준수하는 효과적인 성장 Cap입니다.
MCMC에서 실제 최대 Splat 수를 계산합니다. 설정 (mcmcMaxGaussians) 을 가져오고, 장면이 초기에 몇 개의 점을 가지고 있는지 살펴보고, 자동 적응이 켜져 있는 경우 Multiplier로 스케일합니다. 따라서 Cap이 장면에 적응하며, 작은 장면과 거대한 장면에 같은 값을 강제하는 대신. 메서드를 직접 호출할 필요가 없습니다 — 학습이 내부적으로 사용합니다.
어느 필드를 무엇을 위해? (치트 시트)
| 목표 | 조정할 필드 |
|---|---|
| 거리에 더 많은 세부 정보 | T62 mcmcMaxGaussians 높음, T72 mcmcCapMultiplier 5+ |
| 일반적으로 더 많은 세부 정보 (Classic) | T1 maxIterations 높음 (≤ 40K), T2 densifyUntilIteration T1의 ≤ 14% |
| 드론 비행에서 플로터 감소 | T43 frustumCullEnabled 켜짐, T20 skyMaskingEnabled 켜짐, T45 skyDomeEnabled 켜짐 |
| 야외 장면에서 멋진 하늘 | T45 skyDomeEnabled 켜짐, T47 skyDomeRadiusMultiplier 30–60 |
| 더 작은 내보내기 파일 | 전략 .mcmc (T61), T56 postTrainingCompactification 켜짐, T62 mcmcMaxGaussians ≤ 200K |
| 더 빠른 학습 | T22 trainingRenderScale 0.5, T1 maxIterations 절반 — 그러나 둘 다는 아님! |
| 더 나은 하이라이트 | T21 shDegreeUpgradeIterations를 [2K, 5K, 8K]로 (Early Front Load 없음), MCMC + 200K iter |
| Mac 반응적 유지 | T25 throttleDelayMs 5–10 (~15% 학습 시간 비용) |
| 실시간 미리보기 더 자주 | T59 livePreviewInterval 10–20으로 낮춤 |
| 그림자의 더 부드러운 전환 | T17 ssimWeight 약간 높음 (0.15–0.25), 그러나 0.3 이상은 아님 |
| 실내 콤팩트하게 유지 | P10 Indoor 프리셋 (mcmcMaxGaussians = 670 K, T72 = 1.76) |
위험한 필드
이러한 필드는 잘못된 구성 시 OOM, 앱 충돌, Gaussian의 대량 멸종 또는 사용 불가능한 벤치마크 데이터로 이어질 수 있습니다. 주의해서 다루십시오:
- T11 densifyGradThreshold — 절반으로 줄이면 2–4배 더 많은 Gaussian이 생성되어 GPU 메모리를 빠르게 폭발시킵니다. 또한 주의: T22 trainingRenderScale과 일치해야 합니다 (1.0× → 1e-6, 0.5× → 2e-6, 0.25× → 4e-6). - T72 mcmcCapMultiplier — > 200 K SfM 초기화 점이 있는 큰 장면과 Multiplier > 5에서 수백만 Gaussian의 Resolved Cap이 생성됩니다. 36GB RAM Mac에서 OOM 가능. Outdoor 프리셋 5.32는 Mip-NeRF 360 Bicycle이 156 K init 점을 가지기 때문에만 작동합니다 → 830 K Cap. - T39 testViewIndices — 수동 설정은 벤치마크를 사용 불가능하게 만들 수 있습니다 (모든 인덱스 > N → Holdout 없음). –benchmark 플래그가 이를 설정하도록 두십시오. - T64 mcmcOpacityRegWeight와 T65 mcmcScaleRegWeight — 1.4.3 베타에서 0.01로 설정되어 대량 멸종으로 이어졌습니다 (한 반복에서 460 K → 5 Gaussian). 1.4.4부터 0.0으로 고정되었지만 수동 증가는 문제를 재현할 수 있습니다. - T15 opacityResetInterval — 100 000+ (효과적으로 꺼짐) 이 아니고 학습이 10 000 반복 미만이면 Reset이 수렴을 파괴합니다. .preview가 maxIterations = 5 000에도 불구하고 100 000인 이유입니다. - T54/T55 densifyPhase2* — Two-Phase Densification은 테스트에서 0 Gaussian 캐스케이드에서 중단되었습니다. 둘 다 0으로 두십시오. - T74 useMipSplatting — Q1.5 closed-no-win 2026-05-25, 일부 야외 장면에서는 PSNR을 악화시킬 수도 있습니다. 기본값 off, 연구용 opt-in.
이 목록에 있는 필드를 변경하려면 먼저 현재 프리셋의 백업 (JSON으로 내보내기) 을 만들고 결과를 재현 가능하게 측정할 수 있는지 고려하십시오 — 그렇지 않으면 나중에 개선을 가져왔는지 악화시켰는지 알 수 없습니다.